NLP-生成模型-2017-PGNet:Seq2Seq+Attention+Coverage+Copy【Coverage解决解码端重复解码问题;Copy机制解决解码端OOV问题】【抽取式+生成式】
PGNet模型训练注意事项:
- Coverage机制要在训练的最后阶段再加入(约占总训练时间的1%),如果从刚开始训练时就加入则反而影响训练效果;
- Copy机制在源文本的各个单词上的概率分布直接使用Attention机制计算的在源文本的各个单词上的概率分布;
一、概述
随着互联网飞速发展,产生了越来越多的文本数据,文本信息过载问题日益严重,对各类文本进行一个“降 维”处理显得非常必要,文本摘要便是其中一个重要的手段。
文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要。
1、文本摘要模型分类
按照输出类型可分为抽取式摘要和生成式摘要。
- 抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文。
- 生成式摘要根据原文,允许生成新的词语、原文本中没有的短语来组成摘要。
“文本摘要”模型 { 纯抽取式文本摘要: Pointer Network 只使用“输入文本”中的词汇来生成摘要 纯生成式文本摘要: Seq2Seq+Attention 只使用“词典库”中的词汇来生成摘要 综合式文本摘要: Pointer Network+Seq2Seq+Attention 使用“输入文本+词典库”中的词汇 \begin{aligned} “文本摘要”模型 \begin{cases} 纯抽取式文本摘要:\text{Pointer Network\quad 只使用“输入文本”中的词汇来生成摘要}\\[2ex] 纯生成式文本摘要:\text{Seq2Seq+Attention\quad 只使用“词典库”中的词汇来生成摘要}\\[2ex] 综合式文本摘要:\text{Pointer Network+Seq2Seq+Attention \quad 使用“输入文本+词典库”中的词汇} \end{cases} \end{aligned} “文本摘要”模型⎩ ⎨ ⎧纯抽取式文本摘要:Pointer Network只使用“输入文本”中的词汇来生成摘要纯生成式文本摘要:Seq2Seq+Attention只使用“词典库”中的词汇来生成摘要综合式文本摘要:Pointer Network+Seq2Seq+Attention 使用“输入文本+词典库”中的词汇
仅用传统的 Seq2Seq+Attention 模型可以实现生成式摘要,但存在两个问题:
- 可能不准确地再现细节, 无法处理词汇不足(OOV)单词/they are liable to reproduce factual details inaccurately;
- 倾向于重复自己/they tend to repeat themselves。
传统的 Seq2Seq+Attention 模型中 Decoder 输出的目标数量是固定的,例如翻译时 Decoder 预测的目标数量等于字典的大小。这导致 Seq2Seq 不能用于一些组合优化的问题,例如凸包问题,三角剖分,旅行商问题 (TSP) 等。
2、摘要核心
作者想要研究的问题是什么?一一虽然Seq2Seq模型已经在生成任务上取得了一定的效果,但是还是存在几个问题。
- 问题1:无法生成OOV ,只能生成词汇表的词;
- 问题2:自我重复,如German beat German beat German beat
针对上述问题,提出了两种方式进行解决。
- 问题1——使用一种混合的Pointer Generator网络,可以从源端复制,也可以从词表生成
- 问题2——使用coverage机制,能够一定程度缓解生成重复的问题
3、PG-Net(Pointer-Generator Network) 研究意义
后续的许多生成任务都是在此基础上,通过在输出层使用PG-Net来增加模型的性能。
二、Seq2Seq
Sequence-to-Sequence (Seq2Seq)模型旨在构建一个联合的神经网络,以端到端的方式将 一个序列化数据映射成另一个序列化数据。Seq2Seq模型通常基于Encoder-Decoder 框架实现, 可用于各种序列生成任务,如机器翻译、自动文摘、对话生成、语音识别等。
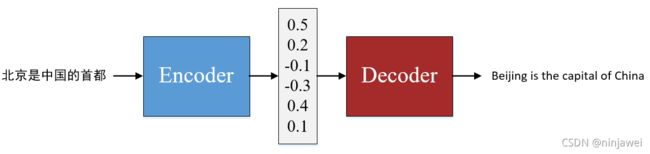
- Encoder:将输入序列转化成中间上下文表示
- Decoder:将中间语义表示转化成输出词序列分布

三、Seq2Seq With “Attention”【Baseline ;用于纯生成式文本摘要】
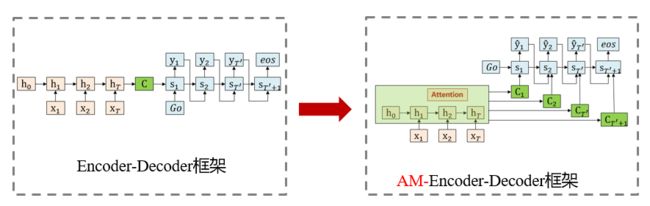
Seq2Seq+Attention架构图如下:

Seq2Seq+Attention模型可以关注原文本中的相关单词以生成新单词进行概括。比如:模型可能注意到原文中的"victorious"和" win"这个两个单词,在摘要"Germany beat Argentina 2-0"中生成了新的单词beat 。Seq2Seq是经典的Encoder-Decoder模型,即先用Encoder将原文本编码成一个中间层的隐藏状态,然后用Decoder来将该隐藏状态解码成为另一个文本。
比如:Seq2Seq在Encoder端是一个双向的LSTM,这个双向的LSTM可以捕捉原文本的长距离依赖关系以及位置信息,编码时单词 w i w^i wi 嵌入经过双向LSTM后得到编码状态 h i h_i hi 。在Decoder端,解码器是一个单向的LSTM,训练阶段时输入参考摘要单词 w j w^j wj (测试阶段时是上一步的生成词), w j w^j wj在时间步 t t t 得到解码状态 z t z^t zt 。使用 h i h_i hi 和 z t z_t zt 的match函数,进一步softmax操作得到该时间步原文第 i i i 个词注意力权重。
- Seq2Seq 模型的预测输出目标的“取值范围(字典库)”的大小是固定的,对于一些输出目标的“取值范围(字典库)”大小会变的情况不适用,例如很多组合优化问题、文章摘要问题。
- 在使用Seq2Seq模型提取文章摘要的过程中,因为文章中会有很多的人名、地名,但是生成模型的字典库(比如字典长度就定n=8000个单词)里并不一定包含这些人名、地名,所以在生成摘要的时候这些关键的人名、地名并不会被生成出来。但是这些人名、地名对于文章的摘要来说有时是非常重要的摘要信息。
- 组合优化问题的输出目标的数量依赖于输入序列的长度,例如旅行商问题中包含5个城市 (1, 2, 3, 4, 5),输出预测的时候目标数量为 5。
传统的 Attention 会根据 Attention 值融合 Encoder 的每一个时刻的输出,然后和 Decoder 当前时刻的输出混在一起再预测输出。如下面的公式所示,e表示 Encoder 的输出,d 表示 Decoder 的输出,W 和 v 都是可以学习的参数。

- Attention 作用:让任务处理系统更专注于找到输入数据中显著的与当前输出相关的有用信息,从而提高输出 的质量。
- Attention 优势:不需要监督信号(Teacher Forcing),可推理多种不同模态数据之间的难以解释、隐蔽性强、复杂映射关系,对于先验认知少的问题,极为有效。
四、Pointer Network(指针网络)【用于纯抽取式文本摘要】
Pointer Network(指针网络)属于纯抽取式摘要模型。
Pointer Network(指针网络) 可以解决传统“Seq2Seq+Attention”模型输出字典大小不可变的问题。
Pointer Network(指针网络)的输出字典大小等于 Encoder 输入序列的长度(即:Decoder部分生成摘要时能使用的单词库就是输入文本本身所包含的所有单词)。
在传统的NLP问题中,采用“Seq2Seq+Attention”模型的方式去解决翻译问题,其输出向量的长度往往是字典的长度,而字典长度是事先已经订好了的(比如英语单词字典就定n=8000个单词)。而在组合优化类问题中,比如TSP问题,输入是城市的坐标序列,输出也是城市的坐标序列,而每次求解的TSP问题城市规模n是不固定的。每次decoder的输出实际上是每个城市这次可能被选择的概率向量,其维度为n,和encoder输入的序列向量长度一致。如何解决输出字典维度可变的问题?
- Pointer Network 改变了传统 Attention 的方式,从而可以用于这些组合优化的问题,Pointer Network 在预测输出时会根据 Attention 的值从 Encoder 的输入中选择一个作为 Decoder 的输出, 得到输入序列中每一个城市的概率 (即输出从输入中选择)。
- Pointer network 的关键点在如下公式:
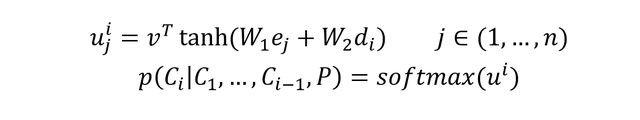
其中 e j e_j ej 是encoder的在时间序列 j j j 次的隐藏层输出, d i d_i di 是decoder在时间序列 i i i 次的隐藏状态输出,这里的 u i = [ u 1 i , u 2 i , . . . , u j i ] u^i=[u^i_1,u^i_2,...,u^i_j] ui=[u1i,u2i,...,uji],其维度为n维和输入保持一致,对 u i u^i ui 直接求softmax就可以得到输出字典的概率向量,其输出的向量维度和输入保持一致。其中 v T , W 1 , W 2 v^T,W_1,W_2 vT,W1,W2 均为固定维度的参数,可被训练出来。
Pointer Network 和 Seq2Seq 的区别如下图所示,图中展示了凸包问题。
- Seq2Seq 的 Decoder 会预测每一个位置的输出 (但是输出目标的数量是固定的),
- Pointer Network 的 Decoder 直接根据 Attention 得到输入序列中每一个位置的概率,取概率最大的输入位置作为当前输出。
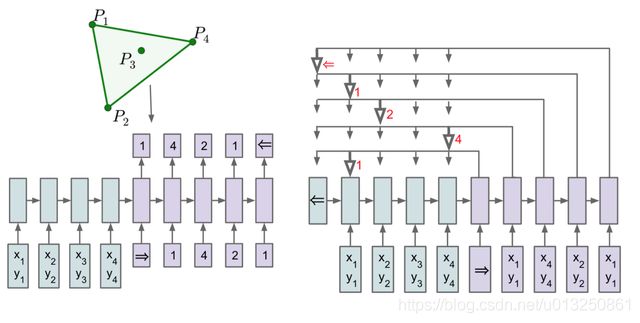
Pointer network 主要用在解决组合优化类问题(TSP, Convex Hull等等),实际上是Sequence to Sequence learning中encoder RNN和decoder RNN的扩展,主要解决的问题是输出的字典长度不固定问题(输出字典的长度等于输入序列的长度)。
Pointer Network 计算输入序列 P P P 的 Attention 值之后不会把 Encoder 的输出融合(即 c = ∑ a ^ 0 h i c=\sum \hat{a}_0h^i c=∑a^0hi),而是将 Attention 作为输入序列 P P P 中每一个位置输出的概率。从这些概率里面取出概率最大值作为Encoder output。Decoder模块的输入完全来自于Encoder模块的输出(Copy)
Decoder模块的输出 = Encoder模块的输出 = Decoder模块的输入

五、Pointer-Generator Network(指针生成网络)【Seq2Seq + “Attention” +“Coverage”+ “Copy”】【综合式文本摘要】
Pointer-Generator Networks 是在Baseline sequence-to-sequence模型的基础上构建的。并从两个方面进行了改进:
- 该网络通过指向(pointer)从源文本中复制单词,有助于准确地复制信息,同时保留通过生成器产生新单词的能力;
- Pointer Net 可分为 Sequence Model 和 Boundary Model 两种模型。
- 序列模型(Sequence Model)【基于词级别;用于机器翻译、文本摘要】:使用Ptr-Net网络,不做连续性假设,预测答案存在于原文的每一个位置;
- 边界模型(Boundary Model)【基于片段选择;用于片段式抽取阅读理解】:直接使用Ptr-Net网络预测答案在原文中起始和结束位置;
- Pointer-Generator Networks 中使用的Pointer机制是序列模型(Sequence Model);
- 使用coverage机制来跟踪已总结的内容,防止重复。
- 注意:指针和覆盖机制向网络引入的附加参数很少:对于词汇量为50k的模型,基线模型具有21,499,600个参数,指针-生成器机制添加了1153个附加参数,覆盖机制增加了512个额外参数
1、Seq2Seq + “Attention” + “Copy”
Pointer-Generator Network的Decoder的输出自于“Encoder的输入” 与 “字典库” 的结合:混合 Baseline Seq2Seq(Seq2Seq + “Attention”)和 Pointer Network 的网络,它具有Seq2Seq + “Attention”的生成能力和 PointerNetwork的Copy能力。该网络的结构如下:
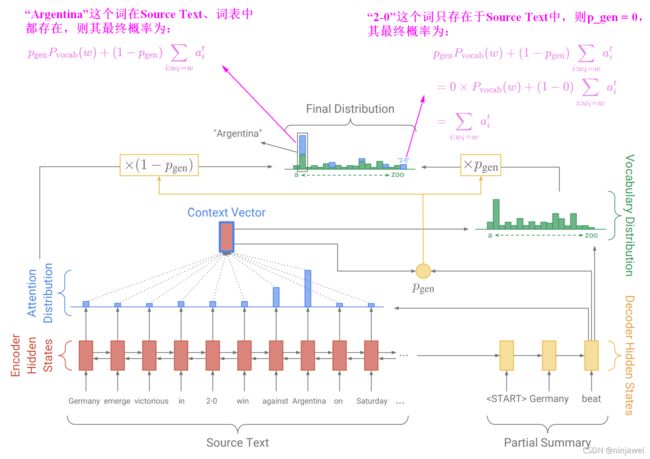
Pointer-Generator Network(Seq2Seq+Attention+Coverage+Pointer)与 BaseLine的 Seq2Seq+Attention 模型的区别在于:
- 不变的:注意力分布权重( a ^ i t \hat{a} _ { i } ^ { t } a^it)的计算、上下文向量(Context vector)的计算不变。
- 变化的:多增加了一个生成概率 p g e n p_{gen} pgen,属于0〜 1。对应图中黄色的圆圈。
如何权衡一个词应该是从字典库生成的还是从Encoder的输入复制的:引入了一个权重 p g e n p_{gen} pgen 。从Baseline Seq2Seq(Seq2Seq + “Attention”)的模型结构中得到了 s t s_t st 和 h t ∗ h_t^∗ ht∗,和解码器输入 x t x_t xt 一起来计算 p g e n p_{gen} pgen :
p g e n = σ ( w h ∗ T h t ∗ + w s T s t + w x T x t + b p t r ) p _ { \mathrm { gen } } = \sigma \left( w _ { h ^ { * } } ^ { T } h _ { t } ^ { * } + w _ { s } ^ { T } s _ { t } + w _ { x } ^ { T } x _ { t } + b _ { \mathrm { ptr } } \right) p