【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器
【论文阅读】MARS:用于自动驾驶的实例感知、模块化和现实模拟器
- Abstract
- 1 Introduction
- 2 Method
-
- 2.1 Scene Representation
- 2.3 Towards Realistic Rendering
- 2.4 Optimization
- 3.1 Photorealistic Rendering
- 3.2 Instance-wise Editing
- 3.3 The blessing of moduler design
- 3.4 Ablation Results
- 4 Conclusion

paper code
Abstract
如今,自动驾驶汽车可以在普通情况下平稳行驶,人们普遍认识到,真实的传感器模拟将在通过模拟解决剩余的极端情况方面发挥关键作用。为此,我们提出了一种基于神经辐射场(NeRF)的自动驾驶模拟器。与现有作品相比,我们的作品具有三个显着特点:
(1)实例感知。我们的模拟器使用独立的网络分别对前景实例和背景环境进行建模,以便可以单独控制实例的静态(例如大小和外观)和动态(例如轨迹)属性。
(2)模块化。我们的模拟器允许在不同的现代 NeRF 相关主干、采样策略、输入模式等之间灵活切换。我们期望这种模块化设计能够促进基于 NeRF 的自动驾驶模拟的学术进步和工业部署。
(3)真实性。考虑到最佳的模块选择,我们的模拟器设置了新的最先进的照片级真实感结果。我们的模拟器将开源,而大多数同类模拟器都不开源。项目页面:https://open-air-sun.github.io/mars/。
1 Introduction
自动驾驶 [11,13,33,16,24,14] 可以说是现代 3D 场景理解 [5,25] 技术最重要的应用。如今,Robotaxis可以在拥有最新高清地图的大城市中运行,顺利应对日常驾驶场景。然而,一旦道路上意外发生自动驾驶算法分布之外的极端情况,乘客的生命就会受到威胁。困境在于,虽然我们需要更多关于极端情况的训练数据,但在现实世界中收集它们通常意味着危险和高昂的费用。为此,社区认为真实感模拟[17,6,29,10]是一条极具潜力的技术路径。如果算法能够在模拟器中经历大量的极端情况,并且模拟与真实的差距很小,那么当前自动驾驶算法的性能瓶颈就有可能得到解决。
现有的自动驾驶仿真方法有其自身的局限性。 CARLA [8] 是一种广泛使用的基于传统图形引擎的传感器模拟器,其真实性受到资产建模和渲染质量的限制。 AADS [17] 也利用传统的图形引擎,但使用精心策划的资源展示了令人印象深刻的照片级真实感。另一方面,GeoSim [6] 引入了一种通过学习图像增强网络来进行真实模拟的数据驱动方案。灵活的资产生成和渲染可以通过具有良好几何形状和逼真外观的图像合成来实现。
在本文中,我们利用 NeRF 的真实渲染能力进行自动驾驶仿真。从现实环境中捕获的训练数据保证了模拟与真实之间的微小差距。一些作品还利用 NeRF 来模拟室外环境中的汽车 [20] 和静态背景 [10]。然而,无法对由移动物体和静态环境组成的复杂动态场景进行建模,限制了它们在现实世界传感器模拟中的实际应用。最近,神经场景图(NSG)[21]将动态场景分解为学习场景图,并学习类别级对象的潜在表示。然而,其基于多平面的背景建模表示无法在大视点变化下合成图像。
具体来说,我们的核心贡献是第一个基于 NeRF 的开源模块化框架,用于逼真的自动驾驶模拟。所提出的管道以分解的方式对前景实例和后景环境进行建模。不同的 NeRF 主干架构和采样方法以统一的方式合并,并支持多模态输入。所提出的框架的最佳模块组合在公共基准上实现了最先进的渲染性能,并具有较大的裕度,表明了逼真的模拟结果。
2 Method

图 1. 管道。左:我们首先计算所查询的射线 r 和所有可见实例边界框 { B i j } \{\mathcal{B}_{ij}\} {Bij}的射线-盒交集。对于背景节点,我们直接使用选定的场景表示模型和选定的采样器来推断逐点属性,就像传统 NeRF 中一样。对于前景节点,光线首先被转换为实例框架 r o r_o ro,然后通过前景节点表示进行处理(第 2.1 节)。右:所有样本都被组合并渲染为 RGB 图像、深度图和语义(第 2.2 节)。
Overview.
如图1所示,我们的目标是提供一个用于构建组合神经辐射场的模块化框架,其中可以针对户外驾驶场景进行真实的传感器模拟。考虑到具有大量动态对象的大型无界室外环境。
系统的输入包括一组 RGB 图像 { L i } N \{\mathcal{L}_i\}^N {Li}N (由车辆端或路边传感器捕获)、传感器姿态 { T i } N \{\mathcal{T}_i\}^N {Ti}N (使用 IMU/GPS 信号计算)和对象轨迹(包括 3D 边界)框 { B i j } N × M \{\mathcal{B}_{ij}\}^{N \times M} {Bij}N×M 、类别 { t y p e i j } N × M \{type_{ij}\}^{N \times M} {typeij}N×M 和实例 ID { i d x i j } N × M \{idx_{ij}\}^{N \times M} {idxij}N×M)。 N 是输入帧的数量,M 是整个序列中跟踪实例 { O i } M \{\mathcal{O}_i\}^M {Oi}M的数量。训练期间还可以采用一组可选的深度图 { D i } N \{\mathcal{D}_i\}^N {Di}N 和语义分割掩模 { S i } N \{\mathcal{S}_i\}^N {Si}N 作为额外的监督信号。通过构建组合神经场,所提出的框架可以在给定的传感器姿势下模拟真实的传感器感知信号(包括 RGB 图像、深度图、语义分割掩模等)。还支持对对象轨迹和外观进行实例编辑。
Pipeline.
我们的框架对每个前景实例和后景节点进行组合建模。如图 1 所示,当查询给定射线 r 的属性(RGB、深度、语义等)时,我们首先计算其与所有可见对象的 3D 边界框的交集,以获得进入和离开的距离 [ t i n , t o u t ] [t_{in}, t_{out}] [tin,tout]。然后,查询背景节点(图 1 左上)和前景对象节点(图 1 左下),其中每个节点对一组 3D 点进行采样,并使用其特定的神经表示网络来获取点属性(RGB、密度、语义等)。具体来说,为了查询前景节点,我们根据对象轨迹将光线原点和方向从世界空间转换为实例帧。最后,来自背景和前景节点的所有光线样本被组合并进行体积渲染,以产生逐像素渲染结果(图 1 右侧,第 2.2 节)。
我们观察到背景节点(通常是无界的大规模场景)的性质与以对象为中心的前景节点不同,而传感器模拟中的当前工作[15,21]使用统一的 NeRF 模型。我们的框架提供了一个灵活的开源框架,支持背景和前景节点场景表示的不同设计选择,并且可以轻松地结合静态场景重建和以对象为中心的重建的新的最先进的方法。
2.1 Scene Representation
我们将场景分解为一个大规模的无界 NeRF(作为背景节点)和多个以对象为中心的 NeRF(作为独立的前景节点)。传统上,神经辐射场将给定的 3D 点坐标 x = (x, y, z) 和 2D 观察方向 d 映射到其辐射率 c 和体积密度 σ,如方程式 1 所示。 1. 基于这种开创性的表示,针对不同目的提出了许多变体,因此我们采用模块化设计。
![]()
对无界背景场景进行逼真建模的挑战在于准确表示远区,因此我们利用无界场景扭曲 [2] 来收缩远区。对于前景节点,我们支持代码条件表示 f (x, d, z) = (c, σ) (z 表示实例级潜在代码)和传统的表示,解释如下。
Architectures.
在我们的模块化框架中,我们支持各种 NeRF 主干,这些主干可以大致分为两个超类:基于 MLP 的方法 [18,1,2],或基于网格的方法,在其哈希网格体素中存储空间变化的特征顶点[19,23]。尽管这些架构在细节上彼此不同,但它们遵循相同的高级公式1 并封装在 MARS 中统一接口下的模块中。
虽然基于 MLP 的表示在数学形式上很简单,但我们给出了基于网格的方法的正式阐述。多分辨率特征网格 { G θ l } l = 1 L \{\mathcal{G}_{\theta}^{l}\}^{L}_{l=1} {Gθl}l=1L 的具体实现具有逐层分辨率 R l : = ⌊ R m i n ⋅ b l ⌋ , b = e x p ( l n R m a x − l n R m i n L − 1 ) R_l := ⌊R_{min} · b^l⌋, b = exp(\frac{ln R_{max} − ln R_{min}}{ L−1}) Rl:=⌊Rmin⋅bl⌋,b=exp(L−1lnRmax−lnRmin) ,其中 R m i n 、 R m a x R_{min}、R_{max} Rmin、Rmax 是最粗和最细的分辨率[31,19]。坐标 x 首先缩放到每个分辨率,然后通过向上和向下操作处理为 ⌈ x ⋅ R l ⌉ 、 ⌊ x ⋅ R l ⌋ ⌈x · R_l⌉、⌊x · R_l⌋ ⌈x⋅Rl⌉、⌊x⋅Rl⌋ 并进行散列以获得表索引 [19]。然后对提取的特征向量进行三线性插值并通过浅 MLP 进行解码。
![]()
Sampling.
我们支持各种采样策略,包括最近提出的提案网络 [2],它从无辐射 NeRF 模型中提取密度场以生成射线样本以及其他采样方案,例如从粗到细采样 [18] 或均匀采样 [9]。
Foreground Nodes.
为了渲染前景实例,我们首先将投影光线转换到每个实例的坐标空间,然后推断每个实例规范空间中的以对象为中心的 NeRF。我们框架的默认设置使用代码条件模型,该模型利用潜在代码对实例特征进行编码,并使用共享类别级解码器对类先验进行编码,从而允许对许多具有紧凑内存使用的长轨迹进行建模。同时,我们的框架也支持传统的无代码条件的。我们在补充材料中详细介绍了修改后的前景表示(在第 3 节中表示为“Ours")。
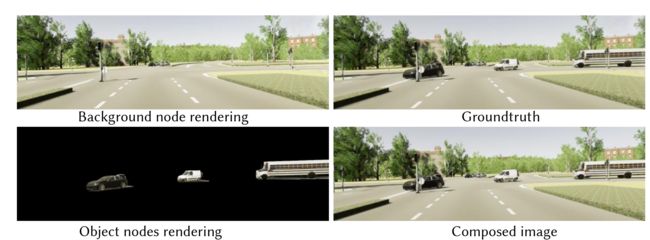
图 2. 构图渲染图。远处区域中的一些静态车辆被视为背景物体。
2.2 Compositional Rendering
图 2 展示了合成渲染结果。为了以给定的相机姿态 T i \mathcal{T}_{i} Ti 渲染图像,我们在每个渲染像素处投射一条光线 r = o + t d r = o + td r=o+td 。对于每条射线 r,我们首先计算与所有可见前景节点 O i j \mathcal{O}_{ij} Oij 的交集间隔 [ t i n , t o u t ] [t_{in}, t_{out}] [tin,tout](图 3),并将样本 { P k o b j − j } \{\mathcal{P}_{k}^{obj-j}\} {Pkobj−j}沿射线从世界空间变换到每个前景规范空间。我们还沿光线采样一组 3D 点 { P k g b } \{\mathcal{P}_{k}^{gb}\} {Pkgb}作为背景样本。所有节点中的样本首先通过其相应的网络来获取逐点颜色 { c k b g , o b j } \{c_{k}^{bg,obj}\} {ckbg,obj}、密度 { σ k b g , o b j } \{σ_{k}^{bg,obj}\} {σkbg,obj} 和前景语义逻辑 { s k b g } \{s_{k}^{bg}\} {skbg}。考虑到前景样本的语义属性实际上是它们的类别标签,我们创建一个 one-hot 向量:

为了聚合逐点属性,我们按世界空间中的光线距离对所有样本进行排序,并使用标准体积渲染过程来渲染逐像素属性:

2.3 Towards Realistic Rendering
Sky Modeling.
在我们的框架中,我们支持使用天空模型来处理无限距离处的外观,其中利用基于 MLP 的球形环境贴图 [22] 来对永远不会与不透明表面相交的无限远区域进行建模:
![]()
然而,天真地将天空颜色 c s k y c_{sky} csky 与背景和前景渲染(等式 4)混合会导致潜在的不一致。因此,我们引入 BCE 语义正则化来缓解这个问题:
![]()
Resolving Conflict Samples.

图 3. 我们的无冲突采样过程的视觉演示。我们在所有节点中使用均匀采样来进行说明。
Resolving Conflict Samples.
由于我们的背景和前景采样是独立完成的,因此背景样本有可能落入前景边界框内(图 3 背景截断样本)。合成渲染可能会错误地将前景样本分类为背景(稍后称为背景-前景模糊性)。因此,在移除前景实例后,背景区域将出现伪影(图 4)。理想情况下,有了足够的多视图监督信号,系统可以在训练过程中自动学习区分前景和背景。然而,对于数据驱动的模拟器来说,随着车辆在道路上快速移动,获取丰富且高质量的多视图图像对用户来说是一个挑战。 NSG [21] 中没有观察到这种模糊性,因为 NSG 仅对光线平面交叉点上的几个点进行采样,并且不太可能有太多背景截断样本。

图 4。我们表明,在没有进行正则化的情况下,背景截断样本会导致背景-前景模糊。
为了解决这个问题,我们设计了一个正则化项,可以最小化背景截断样本的密度和,以最小化它们在渲染过程中的影响:
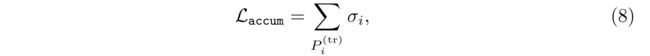
其中 { P i ( t r ) } \{P^{(tr)}_ i \} {Pi(tr)} 表示背景截断样本。
2.4 Optimization
为了优化我们的系统,我们最小化以下目标函数:
![]()
其中 λ 1 − 5 λ_{1−5} λ1−5 是加权参数。 L s k y L_{sky} Lsky 和 L a c c u m L_{accum} Laccum 在方程式中进行了解释。 7和8。
Color Loss:
我们采用标准 MSE 损失来最小化光度测量误差:
![]()
Depth Loss:
我们引入深度损失来解决无纹理区域和从稀疏视点观察到的区域。我们设计了两种监督几何形状的策略。给定深度数据,我们利用从[7]导出的光线分布损失。另一方面,如果深度数据不可用,我们利用单深度网络并应用以下[31]的单深度损失。

Semantic Losses:
我们遵循 SemanticNeRF [34] 并使用交叉熵语义损失 ![]()
3 Experiments
在本节中,我们提供了大量的实验结果来演示所提出的用于自动驾驶的实例感知、模块化和真实的模拟器。我们在 KITTI [11] 数据集和虚拟 KITTI-2 (V-KITTI) [3] 数据集的场景上评估我们的方法。在下文中,我们使用“我们的默认设置”来表示带有提案采样器的基于网格的 NeRF 用于背景节点,以及我们修改后的类别级表示以及用于前景节点的从粗到细的采样器。

表 1. 图像重建任务的定量结果以及与基线方法的设置比较。用于评估的数据集是KITTI。
3.1 Photorealistic Rendering
我们通过评估图像重建和新视图合成(NVS)来验证模拟器的真实感渲染性能[21,26]。

表 2. 新视图合成的定量结果
Baselines.
我们与其他最先进的方法进行定性和定量比较:NeRF [18]、带时间戳输入的 NeRF(表示为 NeRF+Time)、NSG [21]、PNF [15] 和 SUDS [26]。请注意,它们都没有同时满足表1 中提到的所有三个标准。
Implementation Details.
我们的模型使用 RAdam 作为优化器,经过 200,000 次迭代训练,每批 4096 条光线。背景节点的学习率被指定为 1 ∗ 1 0 − 3 1 * 10^{−3} 1∗10−3,衰减到 1 ∗ 1 0 − 5 1 * 10^{−5} 1∗10−5,而对象节点的学习率被分配为 5 ∗ 1 0 − 3 5 * 10^{−3} 5∗10−3,衰减到 1 ∗ 1 0 − 5 1 * 10^{−5} 1∗10−5。

图 5. KITTI 数据集上的定性图像重建结果。
Experiment Settings.
图像重建设置中的训练和测试图像集是相同的,而在 NVS 任务中,我们渲染不包含在训练数据中的帧。具体来说,我们每隔 4 帧、每 2 帧和 4 帧进行一次训练,并且每 4 帧中只有 1 帧进行训练,即 25%、50% 和 75%。
我们遵循图像合成中的标准评估协议,并报告定量评估默认设置的峰值信噪比(PSNR)、结构相似性(SSIM)和学习感知图像块相似性(LPIPS)[32]。图像重建的结果如表 1 所示,NVS 的结果如表 2 所示,这表明我们的方法在两种设置下都优于基线方法。我们使用 75% 的训练数据在 V-KITTI 上可以达到 29.79 PSNR,而之前发布的最佳结果是 23.87。
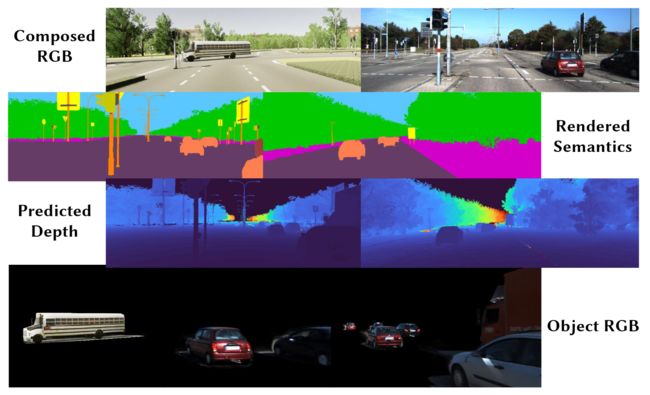 图 6. 不同渲染通道的图库。
图 6. 不同渲染通道的图库。
3.2 Instance-wise Editing
我们的框架分别对背景和前景节点进行建模,这使我们能够以实例感知的方式编辑场景。我们定性地展示了删除实例、添加新实例和编辑车辆轨迹的能力。在图 7 中,我们展示了一些旋转和平移车辆的编辑示例,但可以在我们的视频剪辑中找到更多结果。

3.3 The blessing of moduler design
我们使用后景和前景节点、采样器和监督信号的不同组合进行评估,这归功于我们的模块化设计。
请注意,文献中的一些基线方法实际上对应于该表中的消融条目。例如,PNF [15] 使用 NeRF 作为背景节点表示,使用实例化 NeRF 作为具有语义损失的前景节点表示。 NSG [21] 使用 NeRF 作为背景节点表示,使用类别级 NeRF 作为前景表示,但采用多平面采样策略。我们的默认设置使用基于网格的背景节点表示,以及我们提出的前景节点表示的类别级方法。
3.4 Ablation Results
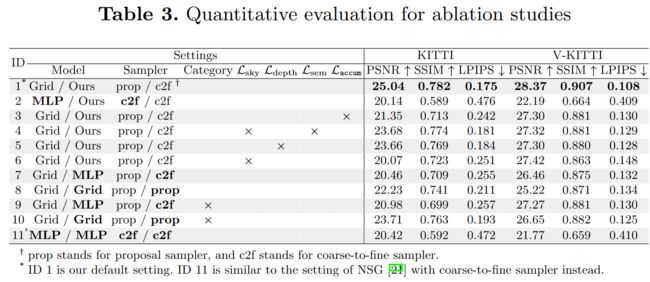
在本节中,我们分析不同的实验设置,验证我们设计的必要性。我们揭示了不同设计选择对背景节点表示、前景节点表示等的影响。具体来说,我们展示了 50,000 次迭代的所有实验。与之前的工作 [26,15,21] 在 90 张图像的短序列上评估他们的方法不同,我们使用数据集中的完整序列进行所有评估。由于它们不是开源的,并且不知道它们的确切评估序列,我们希望我们的新基准测试能够标准化这个重要领域。定量评价见表3。
对于背景和前景节点,我们用基于 MLP 和基于网格的模型替换默认模型(表 3 中的 ID 1),并在第 2 行、第 7-12 行列出它们的指标。在第 3-6 行中,我们展示了模型组件的有效性。对于模型和采样器,背景和前景节点的选定模块分别在斜杠之前和之后注明。
4 Conclusion
在本文中,我们提出了一个基于 NeRF 的逼真自动驾驶模拟模块化框架。我们的开源框架由一个后景节点和多个前景节点组成,可以对复杂的动态场景进行建模。我们通过大量的实验证明了我们框架的有效性。所提出的管道在公共基准上实现了最先进的渲染性能。我们还支持场景表示和采样策略的不同设计选择,从而在模拟过程中提供灵活性和多功能性。
Limitations.
我们的方法需要数小时的训练,并且无法实时渲染。此外,我们的方法未能考虑玻璃或其他反射材料上的动态镜面反射效应,这可能会导致渲染图像中的伪影。提高模拟效率和视图相关效果将是我们未来的工作。
抛砖:
- NeRF在自动驾驶领域的有效应用,效果很棒。
- 这个模块化挺好,可以自由组合各个小模块,可以针对不同场景较方便地切换模块与优化。
- 这份工作结合的NeRF在渲染方向的优势,似乎在NeRF重建方向由于效率等原因,很少看到相关应用,目前来看,可能NeRF重建还是后处理方面比较有优势(比如重建街景?)。