贪心(区间问题 Huffman树 排序不等式 绝对值不等式 推公式)
目录
- 区间问题
-
- 常用排序操作
- 区间选点
-
- 实现思路
- 代码实现
- 最大不相交区间数量
-
- 代码实现
- 区间分组
-
- 实现思路
- 代码实现
- 扩展:Dilworth定理
-
- 代码实现
- 接受交点情况
- 区间覆盖
-
- 实现思路思路
- 代码实现
- Huffman树
-
- 合并果子
-
- 算法思路
- 代码实现
- 排序不等式
-
- 排队打水
-
- 算法思路
- 代码实现
- 绝对值不等式
-
- 货仓选址
-
- 算法思路
- 代码实现
- 推公式
-
- 国王游戏
-
- 算法思路
- 代码实现
- 耍杂技的牛
-
- 算法思路
- 代码实现
区间问题
常用排序操作
- 按左端点排序
- 按右端点排序
- 双关键字排序(先按右端点,再按左端点)
区间选点
题目描述:
给定 N N N 个闭区间 [ a i , b i ] [a_i,b_i] [ai,bi],请你在数轴上 选择尽量少的点,使得每个区间内至少包含一个选出的点。
输出选择的点的最小数量。
位于区间端点上的点也算作区间内。
输入格式:
第一行包含整数 N N N,表示区间数。
接下来 N N N 行,每行包含两个整数 a i , b i a_i,b_i ai,bi,表示一个区间的两个端点。
输出格式:
输出一个整数,表示所需的点的最小数量。
数据范围:
1 ≤ N ≤ 1 0 5 1≤N≤10^5 1≤N≤105
− 1 0 9 ≤ a i ≤ b i ≤ 1 0 9 −10^9≤a_i≤b_i≤10^9 −109≤ai≤bi≤109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
实现思路

以右端点排序(全凭感觉),因为右端点更容易被后面的区间覆盖,而所有被这个点覆盖的区间不用再考虑。而在其之后出现的第一个没有覆盖的区间,又回到之前的问题,这个区间一定要被点覆盖,而最优点在右端点处。

代码实现
#define _CRT_SECURE_NO_WARNINGS
#include最大不相交区间数量
题目描述:
给定 N N N 个闭区间 [ a i , b i ] [a_i,b_i] [ai,bi],请你在数轴上选择若干区间,使得选中的区间之间互不相交(包括端点)。
输出可选取区间的最大数量。
输入格式:
第一行包含整数 N N N,表示区间数。
接下来 N N N 行,每行包含两个整数 a i , b i a_i,b_i ai,bi,表示一个区间的两个端点。
输出格式:
输出一个整数,表示可选取区间的最大数量。
数据范围:
1 ≤ N ≤ 1 0 5 1≤N≤10^5 1≤N≤105
− 1 0 9 ≤ a i ≤ b i ≤ 1 0 9 −10^9≤a_i≤b_i≤10^9 −109≤ai≤bi≤109
输入样例:
4
1 3
2 6
5 7
9 10
输出样例:
3
代码实现
#define _CRT_SECURE_NO_WARNINGS
#include区间分组
题目描述:
给定 N N N 个闭区间 [ a i , b i ] [a_i,b_i] [ai,bi],请你将这些区间分成若干组,使得每组内部的区间两两之间(包括端点)没有交集,并使得 组数尽可能小。
输出最小组数。
输入格式:
第一行包含整数 N N N,表示区间数。
接下来 N N N 行,每行包含两个整数 a i , b i a_i,b_i ai,bi,表示一个区间的两个端点。
输出格式:
输出一个整数,表示最小组数。
数据范围:
1 ≤ N ≤ 1 0 5 1≤N≤10^5 1≤N≤105
− 1 0 9 ≤ a i ≤ b i ≤ 1 0 9 −10^9≤a_i≤b_i≤10^9 −109≤ai≤bi≤109
输入样例:
3
-1 1
2 4
3 5
输出样例:
2
实现思路
首先按照按左端点进行排序。
使用小根堆的数据结构存储区间的右端点。
若当前遍历到的区间左端点大于等于当前小根堆所储存的最小的右端点,即可视为可以加入为统一分组,此时去除当前小根堆所储存的最小的右端点,并将目标区间的右端点加入小根堆中,视为更新了当前分组的右端点的范围。
若当前遍历到的区间左端点小于当前小根堆所储存的最小的右端点,即视为现存所有分组不满足加入该目标区间的条件,即要新开一个分组来存储当前的区间,此时直接加入目标区间的右端点,不去除小根堆的其他数据。
代码实现
#define _CRT_SECURE_NO_WARNINGS
#include扩展:Dilworth定理
Dilworth定理:最小不相交分组数等于最大相交组的元素个数
运用定理可以把最小区间分组个数问题转化为求最大相交组的元素个数问题。(即求取最大区间厚度)
最大区间厚度的思考方法:
求 最大区间厚度 的问题,可以把这个问题想象成活动安排问题。
有若干个活动,第 i i i 个活动开始时间和结束时间是 [ S i , E i ] [Si,Ei] [Si,Ei],同一个教室安排的活动之间不能交叠,求要安排所有活动,至少需要几个教室?
有时间冲突的活动不能安排在同一间教室,与该问题的限制条件相同,最小需要的教室个数即为答案。
解法:
把所有开始时间和结束时间排序,遇到开始时间就把需要的教室加 1 1 1,遇到结束时间就把需要的教室减 1 1 1,在一系列需要的教室个数变化的过程中,峰值就是多同时进行的活动数,也是我们至少需要的教室数。
代码实现
通过 左端点 × 2 与 右端点 × 2 + 1 将整个区间信息存储在一个数组当中,然后再对整个数组进行排序,而后对整个数组进行遍历。如果碰到偶数,即一个区间的左端点,代表一个活动的开始。如果碰到奇数,即一个区间的右端点,代表一个活动的结束。
注意:若是存在交点情况,即 [ 1 , 3 ] [1,3] [1,3] [ 3 , 9 ] [3,9] [3,9],由于右端点被分配为奇数,所以默认比左端点大,因此会被视为一种冲突情况,即两区间相交。
#define _CRT_SECURE_NO_WARNINGS
#include接受交点情况
上面的代码是不允许存在任何两个结点开始与结束在同一个点的,比如 [ 1 , 3 ] [1,3] [1,3]和 [ 3 , 9 ] [3,9] [3,9],算冲突。如果能区间端点能重合的话,端点标记的 奇数偶数 就需要进行颠倒处理。
#define _CRT_SECURE_NO_WARNINGS
#include区间覆盖
题目描述:
给定 N N N 个闭区间 [ a i , b i ] [a_i,b_i] [ai,bi] 以及一个线段区间 [ s , t ] [s,t] [s,t],请你 选择尽量少的区间,将指定线段区间完全覆盖。
输出最少区间数,如果无法完全覆盖则输出 −1。
输入格式:
第一行包含两个整数 s s s 和 t t t,表示给定线段区间的两个端点。
第二行包含整数 N N N,表示给定区间数。
接下来 N N N 行,每行包含两个整数 a i , b i a_i,b_i ai,bi,表示一个区间的两个端点。
输出格式:
输出一个整数,表示所需最少区间数。
如果无解,则输出 −1。
数据范围:
1 ≤ N ≤ 1 0 5 1≤N≤10^5 1≤N≤105
− 1 0 9 ≤ a i ≤ b i ≤ 1 0 9 −10^9≤a_i≤b_i≤10^9 −109≤ai≤bi≤109
− 1 0 9 ≤ s ≤ t ≤ 1 0 9 −10^9≤s≤t≤10^9 −109≤s≤t≤109
输入样例:
1 5
3
-1 3
2 4
3 5
输出样例:
2
实现思路思路

代码实现
#define _CRT_SECURE_NO_WARNINGS
#includeHuffman树
合并果子
题目描述:
在一个果园里,达达已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。
达达决定把所有的果子合成一堆。
每一次合并,达达可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。
可以看出,所有的果子经过 n − 1 n−1 n−1 次合并之后,就只剩下一堆了。
达达在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以达达在合并果子时要尽可能地节省体力。
假定每个果子重量都为 1 1 1,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使达达耗费的体力最少,并输出这个最小的体力耗费值。
例如有 3 3 3 种果子,数目依次为 1 , 2 , 9 1,2,9 1,2,9。
可以先将 1 、 2 1、2 1、2 堆合并,新堆数目为 3 3 3,耗费体力为 3 3 3。
接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 12 12 12,耗费体力为 12 12 12。
所以 达达总共耗费体力 = 3 + 12 = 15 达达总共耗费体力=3+12=15 达达总共耗费体力=3+12=15。
可以证明 15 15 15 为最小的体力耗费值。
输入格式:
输入包括两行,第一行是一个整数 n n n,表示果子的种类数。
第二行包含 n n n 个整数,用空格分隔,第 i i i 个整数 a i a_i ai 是第 i i i 种果子的数目。
输出格式:
输出包括一行,这一行只包含一个整数,也就是最小的体力耗费值。
输入数据保证这个值小于 2 31 2^{31} 231。
数据范围:
1 ≤ n ≤ 10000 1≤n≤10000 1≤n≤10000
1 ≤ a i ≤ 20000 1≤a_i≤20000 1≤ai≤20000
输入样例:
3
1 2 9
输出样例:
15
算法思路
与区间DP中石子合并的问题很相似,但是石子合并只能 每次只能合并相邻的两堆 导致不能用本题的方法进行求解。

代码实现
#define _CRT_SECURE_NO_WARNINGS
#include排序不等式
排队打水
题目描述:
有 n n n 个人排队到 1 1 1 个水龙头处打水,第 i i i 个人装满水桶所需的时间是 t i t_i ti,请问如何安排他们的打水顺序才能使所有人的等待时间之和最小?
输入格式:
第一行包含整数 n n n。
第二行包含 n n n 个整数,其中第 i i i 个整数表示第 i i i 个人装满水桶所花费的时间 t i t_i ti。
输出格式:
输出一个整数,表示最小的等待时间之和。
数据范围:
1 ≤ n ≤ 1 0 5 1≤n≤10^5 1≤n≤105
1 ≤ t i ≤ 1 0 4 1≤t_i≤10^4 1≤ti≤104
输入样例:
7
3 6 1 4 2 5 7
输出样例:
56
算法思路
s u m = ∑ i = 1 n ( n − i + 1 ) ∗ a [ i ] \large sum=\sum\limits_{i=1}^{n}(n-i+1)*a[i] sum=i=1∑n(n−i+1)∗a[i]
因此每回选择耗时最短的人去打水
代码实现
#define _CRT_SECURE_NO_WARNINGS
#include绝对值不等式
货仓选址
题目描述:
在一条数轴上有 N N N 家商店,它们的坐标分别为 A 1 ∼ A N A_1∼A_N A1∼AN。
现在需要在数轴上建立一家货仓,每天清晨,从货仓到每家商店都要运送一车商品。
为了提高效率,求把货仓建在何处,可以使得 货仓到每家商店的距离之和最小。
输入格式:
第一行输入整数 N N N。
第二行 N N N 个整数 A 1 ∼ A N A_1∼A_N A1∼AN。
输出格式:
输出一个整数,表示距离之和的最小值。
数据范围:
1 ≤ N ≤ 100000 , 0 ≤ A i ≤ 40000 1≤N≤100000,0≤A_i≤40000 1≤N≤100000,0≤Ai≤40000
输入样例:
4
6 2 9 1
输出样例:
12
算法思路

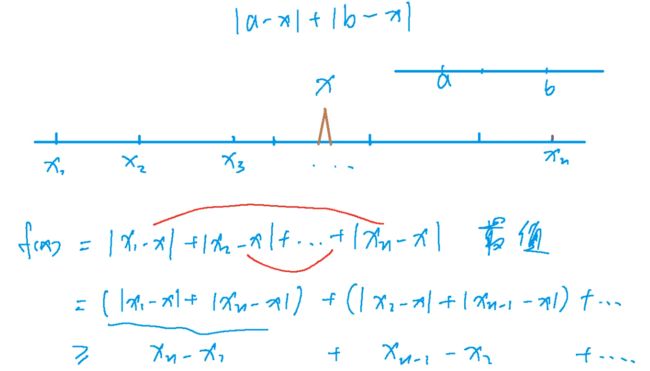
将绝对值函数里的,项数进行重新排列,让如 ∣ x 1 − x ∣ + ∣ x n − x ∣ |x_1 - x| + |x_n - x| ∣x1−x∣+∣xn−x∣ 凑为一项,当 x x x 处于 x 1 x_1 x1 与 x n x_n xn 之间时, x x x 到 x 1 x_1 x1 与 x n x_n xn 的距离最小,以此类推当 x x x 处于整个大区间的中间时候, x x x 到各点的距离最短。
代码实现
#define _CRT_SECURE_NO_WARNINGS
#include推公式
国王游戏
题目描述:
恰逢 H 国国庆,国王邀请 n n n 位大臣来玩一个有奖游戏。首先,他让每个大臣在左、右手上面分别写下一个整数,国王自己也在左、右手上各写一个整数。然后,让这 n n n 位大臣排成一排,国王站在队伍的最前面。排好队后,所有的大臣都会获得国王奖赏的若干金币,每位大臣获得的金币数分别是:排在该大臣前面的所有人的左手上的数的乘积除以他自己右手上的数,然后向下取整得到的结果。
国王不希望某一个大臣获得特别多的奖赏,所以他想请你帮他重新安排一下队伍的顺序,使得获得奖赏最多的大臣,所获奖赏尽可能的少。注意,国王的位置始终在队伍的最前面。
输入格式:
第一行包含一个整数 n n n,表示大臣的人数。
第二行包含两个整数 a a a 和 b b b,之间用一个空格隔开,分别表示国王左手和右手上的整数。
接下来 n n n 行,每行包含两个整数 a a a 和 b b b,之间用一个空格隔开,分别表示每个大臣左手和右手上的整数。
输出格式:
一个整数,表示重新排列后的队伍中获奖赏最多的大臣所获得的金币数。
数据范围:
对于 20 % 20\% 20% 的数据,有 1 ≤ n ≤ 100 < a , b < 8 1≤ n≤ 100 < a,b < 8 1≤n≤100<a,b<8;
对于 40 % 40\% 40% 的数据,有 1 ≤ n ≤ 200 < a , b < 8 1≤ n≤200 < a,b < 8 1≤n≤200<a,b<8;
对于 60 % 60\% 60% 的数据,有 1 ≤ n ≤ 100 1≤ n≤100 1≤n≤100;
对于 60 % 60\% 60% 的数据,保证答案不超过 1 0 9 10^9 109;
对于 100 % 100\% 100% 的数据,有 1 ≤ n ≤ 10000 < a , b < 10000 1 ≤ n ≤10000 < a,b < 10000 1≤n≤10000<a,b<10000。
输入样例:
3
1 1
2 3
7 4
4 6
输出样例:
2
【输入输出样例说明】
按 1 1 1、 2 2 2、 3 3 3 这样排列队伍,获得奖赏最多的大臣所获得金币数为 2 2 2;
按 1 1 1、 3 3 3、 2 2 2 这样排列队伍,获得奖赏最多的大臣所获得金币数为 2 2 2;
按 2 2 2、 1 1 1、 3 3 3 这样排列队伍,获得奖赏最多的大臣所获得金币数为 2 2 2;
按 2 2 2、 3 3 3、 1 1 1 这样排列队伍,获得奖赏最多的大臣所获得金币数为 9 9 9;
按 3 3 3、 1 1 1、 2 2 2 这样排列队伍,获得奖赏最多的大臣所获得金币数为 2 2 2;
按 3 3 3、 2 2 2、 1 1 1 这样排列队伍,获得奖赏最多的大臣所获得金币数为 9 9 9。
因此,奖赏最多的大臣最少获得 2 2 2 个金币,答案输出 2 2 2。
算法思路
考虑两个大臣 p 1 , p 2 p_1,p_2 p1,p2,他们站在国王 p 0 p_0 p0 身后,这时候可以分为两种情况:
情况一:
| 人物 | 左手 | 右手 |
|---|---|---|
| p 0 p_0 p0 | a 0 a_0 a0 | b 0 b_0 b0 |
| p 1 p_1 p1 | a 1 a_1 a1 | b 1 b_1 b1 |
| p 2 p_2 p2 | a 2 a_2 a2 | b 2 b_2 b2 |
情况二:
| 人物 | 左手 | 右手 |
|---|---|---|
| p 0 p_0 p0 | a 0 a_0 a0 | b 0 b_0 b0 |
| p 2 p_2 p2 | a 2 a_2 a2 | b 2 b_2 b2 |
| p 1 p_1 p1 | a 1 a_1 a1 | b 1 b_1 b1 |
对于情况一:
a n s 1 = m a x ( a 0 b 1 , a 0 ∗ a 1 b 2 ) \large ans_1=max(\frac{a_0}{b_1},\frac{a_0*a_1}{b_2}) ans1=max(b1a0,b2a0∗a1)
对于情况二:
a n s 2 = m a x ( a 0 b 2 , a 0 ∗ a 2 b 1 ) \large ans_2=max(\frac{a_0}{b_2},\frac{a_0*a_2}{b_1}) ans2=max(b2a0,b1a0∗a2)
可以发现 a 0 ∗ a 2 b 1 > a 0 b 1 \large \frac{a_0*a_2}{b_1} > \frac{a_0}{b_1} b1a0∗a2>b1a0 和 a 0 ∗ a 1 b 2 > a 0 b 2 \large \frac{a_0*a_1}{b_2} > \frac{a_0}{b_2} b2a0∗a1>b2a0,因此如果要使 a n s 2 > a n s 1 \large ans_2 > ans_1 ans2>ans1 ,要让 a 0 ∗ a 2 b 1 > a 0 ∗ a 1 b 2 \large \frac{a_0*a_2}{b_1} > \frac{a_0*a_1}{b_2} b1a0∗a2>b2a0∗a1。即让 a 0 ∗ a 2 ∗ b 2 > a 0 ∗ a 1 ∗ b 1 \large a_0*a_2*b_2 > a_0*a_1*b_1 a0∗a2∗b2>a0∗a1∗b1,也就是 a 2 ∗ b 2 > a 1 ∗ b 1 \large a_2*b_2 > a_1*b_1 a2∗b2>a1∗b1。
因此可以得出结论, a i ∗ b i > a j ∗ b j \large a_i*b_i > a_j*b_j ai∗bi>aj∗bj 可以得出 a n s i > a n s j \large ans_i > ans_j ansi>ansj。为了使 a n s ans ans 更小,需要将 a i ∗ b i \large a_i∗b_i ai∗bi 较小的放在前面,我们以 a i ∗ b i \large a_i∗b_i ai∗bi 为关键字排序即可。
代码实现
无高精度计算版本:
#define _CRT_SECURE_NO_WARNINGS
#include高精度计算版本:
#define _CRT_SECURE_NO_WARNINGS
#include耍杂技的牛
题目描述:
农民约翰的 N N N 头奶牛(编号为 1.. N 1..N 1..N)计划逃跑并加入马戏团,为此它们决定练习表演杂技。
奶牛们不是非常有创意,只提出了一个杂技表演:
叠罗汉,表演时,奶牛们站在彼此的身上,形成一个高高的垂直堆叠。
奶牛们正在试图找到自己在这个堆叠中应该所处的位置顺序。
这 N N N 头奶牛中的每一头都有着自己的重量 W i W_i Wi 以及自己的强壮程度 S i S_i Si。
一头牛支撑不住的可能性取决于它头上所有牛的总重量(不包括它自己)减去它的身体强壮程度的值,现在称该数值为 风险值,风险值越大,这只牛撑不住的可能性越高。
您的任务是 确定奶牛的排序,使得所有奶牛的风险值中的 最大值 尽可能的小。
输入格式:
第一行输入整数 N N N,表示奶牛数量。
接下来 N N N 行,每行输入两个整数,表示牛的重量和强壮程度,第 i i i 行表示第 i i i 头牛的重量 W i W_i Wi 以及它的强壮程度 S i S_i Si。
输出格式:
输出一个整数,表示最大风险值的最小可能值。
数据范围:
1 ≤ N ≤ 50000 1≤N≤50000 1≤N≤50000
1 ≤ W i ≤ 10000 1≤W_i≤10000 1≤Wi≤10000
1 ≤ S i ≤ 1 0 9 1≤S_i≤10^9 1≤Si≤109
输入样例:
3
10 3
2 5
3 3
输出样例:
2
算法思路
考虑三头牛的情况 n 1 , n 2 , n 3 n_1,n_2,n_3 n1,n2,n3, n 1 n_1 n1在最上面,假设 n 1 n_1 n1 牛不改变仅改变 n 2 n_2 n2和 n 3 n_3 n3牛,这时候可以分为两种情况:
情况一:
| 牛 | 重量 | 强壮程度 |
|---|---|---|
| n 1 n_1 n1 | n 1 n_1 n1 | n 1 n_1 n1 |
| n 1 n_1 n1 | n 1 n_1 n1 | n 1 n_1 n1 |
| n 2 n_2 n2 | n 2 n_2 n2 | n 2 n_2 n2 |
情况二:
| 牛 | 重量 | 强壮程度 |
|---|---|---|
| n 1 n_1 n1 | n 1 n_1 n1 | n 1 n_1 n1 |
| n 3 n_3 n3 | n 3 n_3 n3 | n 3 n_3 n3 |
| n 2 n_2 n2 | n 2 n_2 n2 | n 2 n_2 n2 |
可以推出:
对于情况一:
a n s 1 = m a x ( w 1 − s 2 , w 1 + w 2 − s 3 ) \large ans_1=max(w_1 - s_2,w_1 + w_2 - s_3) ans1=max(w1−s2,w1+w2−s3)
对于情况二:
a n s 2 = m a x ( w 1 − s 3 , w 1 + w 3 − s 2 ) \large ans_2=max(w_1 - s_3,w_1 + w_3 - s_2) ans2=max(w1−s3,w1+w3−s2)
易得, w 1 + w 2 − s 3 > w 1 − s 3 \large w_1 + w_2 - s_3 > w_1 - s_3 w1+w2−s3>w1−s3 和 w 1 + w 3 − s 2 > w 1 − s 2 \large w_1 + w_3 - s_2 > w_1 - s_2 w1+w3−s2>w1−s2,因此假设要判断 a n s 1 > a n s 2 \large ans_1 > \large ans_2 ans1>ans2,只需判断 w 1 + w 2 − s 3 > w 1 + w 3 − s 2 \large w_1 + w_2 - s_3 > w_1 + w_3 - s_2 w1+w2−s3>w1+w3−s2,即 w 2 + s 2 > w 3 + s 3 \large w_2 + s_2 > w_3 + s_3 w2+s2>w3+s3。所以要使 a n s i \large ans_i ansi 尽可能将较小的 w i + s i \large w_i + s_i wi+si 放到上面的位置。
代码实现
#define _CRT_SECURE_NO_WARNINGS
#include