Learn Prompt-什么是ChatGPT?
ChatGPT(生成式预训练变换器)是由 OpenAI 在2022年11月推出的聊天机器人。它建立在 OpenAI 的 GPT-3.5 大型语言模型之上,并采用了监督学习和强化学习技术进行了微调。
ChatGPT 是一种聊天机器人,允许用户与基于计算机的代理进行对话。它通过使用机器学习算法分析文本输入并生成旨在模仿人类对话的响应来工作。ChatGPT 可用于各种用途,包括回答问题,提供信息和进行非正式对话。
决定 ChatGPT 对话成功的关键因素之一是用于启动和引导对话的提示的质量。明确定义的提示可以帮助确保对话保持在正确的轨道上并涵盖用户感兴趣的主题。相反,定义不清的提示可能会导致对话支离破碎或缺乏重点,从而导致体验不够引人入胜和信息丰富。
ChatGPT 中,G、P、T 分别是什么意思?
GPT:Generative Pre-Training Transformer
Generative 生成式
Transformer Generative 的语言模型的核心,通俗的说就是「顺口溜」。
当看了足够多的文本以后,发现有一些语言模式是反复出现的。它之所以可以准确的填补「锄禾日当__ 」的空格,不是因为它在自己的大脑子里面重构了一副农民劳动的场景,仅仅是不过脑子,顺口溜出来的。
你问它: 3457 * 43216 = ,它回答 149575912 (这是错的。正确结果是 149397712)。之所以结果的 2 是对的,仅仅因为它读了太多的文字资料以后,隐约感觉到
7 结尾的文字,乘号,6 结尾的文字,和 2 结尾的文字比较「押韵」 从语感上比较像一首诗,所以它就学会了这样的文字,而不是学会了计算。 生成式模型努力解决的问题,就是给定一些字,预测如果是人类会写什么字。
在 BERT 那个年代,为了训练,大家常常把一句话中随机几个单词遮起来,让计算机用现有的模型预测那几个单词,如果预测准了,就继续加强,如果预测错了,就调整模型,直到上百万上亿次训练之后越来越准。只不过 ChatGPT 的 Generative 的部分,不仅仅把文字,还把上下文、intention(意图)也放进去做训练和预测。
Pre-Training 预训练
以前很多的人工智能模型都是为了一个目标训练的。比如给我 1000 张猫的照片,我就很容易的可以训练出来一个模型,判断一个图片是有猫还是没有猫。这些都是专用的模型。
而 Pre-Training 模型不是为了特定的目标训练,而是预先训练一个通用的模型。如果我有特定的需求,我可以在这个基础上进行第二次训练,基于原来已经预训练的模型,进行微调(Fine- Tuning)。
这事儿就像家里请了个阿姨,她已经被劳务公司预训练了整理家务的知识,在此之前已经被小学老师预训练了中文对话,到了我家里面我只要稍微 fine tune 一些我家里特定的要求就好了,而不需要给我一个「空白」的人,让我从教汉语开始把她彻底教一遍才能让她干活。
ChatGPT 的预训练就是给了我们所有人(尤其是创业者,程序员)一个预先训练好的模型。这个模型里面语言是强项,它提供的内容无论多么的胡说八道,至少我们必须承认它的行文通畅程度无可挑剔。这就是他 pre-training 的部分,而回答的内容部分,正是我们需要 fine tuning 的。我们不能买了个 Apache 服务器回来,不灌内容,就说他输出的内容不够呀。
Transformer 转换器
语言的转换器就是把语言的序列作为输入,然后用一个叫做编码器 encoder 的东西变成数字的表现(比如 GPT 就用 1536 个浮点数(也叫 1536 维向量)表示任何的单词,或者句子,段落,篇章等),然后经过转化,变成一串新的序列,最后再用 decoder 把它输出。这个转换器,是这个自然语言处理的核心。
比如如果给 ChatGPT 输入「Apple」这个词,它给你返回
[
0.0077999732,
-0.02301609,
-0.007416143,
-0.027813964,
-0.0045648348,
0.012954261,
.....
0.021905724,
-0.012022103,
-0.013550568,
-0.01565478,
0.006107009]
这 1536 个浮点数字来表示 Apple(其中一个或着多个维度的组合表达了「甜」的含义,另外一堆表达了「圆」的含义,还有一大堆共同表达了「红」等等属性组合,至于具体哪些表达了这些,不得而知)
然后这堆数字,再交给 decoder,并且限定中文的话,它会解码成为「苹果」,限定西班牙语的话,它会解码成「manzana」,限定为 emoji 的话,就输出「」。总之,通过编码,转换,解码,它就完成了从 Apple 到目标输出语言的转化。
ChatGPT 所做的事情远远多于翻译。但核心上,它就是把一个语言序列,转换为了另外一堆语言序列,这个任务完成得如此的好,以至于让人产生了它有思想的错觉。
GPT 生成式预训练转化器
把上面三段话加在一起,GPT 就是
一个预先训练好的,用生成的方式,把输入文字转化成输出文字的翻译
ChatGPT背后的技术
ChatGPT背后的技术InstructGPT,论文标题为 Training language models to follow instructions with human feedback。
语言模型(Language model)的原理是给一段文本,让它去预测后面下面的词是什么。在预训练中它的训练数据是没有标签的,是自监督学习。当我们提出一些问题去问模型,比如说勾股定理是什么的时候,我们希望模型在预训练中就见过相关的数据,所以模型的行为取决于预训练的内容。在现在的大语言模型中,训练的词表是几十几百亿的级别,所以实际里面有什么我们没有办法详细的去看,我们只能大概知道我们获得的文本质量不错,然后经过数据预处理后去喂给模型训练。这种情况下会导致模型的精细度不够,可控性也比较低,同时面临着有效性和安全性问题,比如说如果我让模型做一些任务,但是它在训练文本里没有出现,模型没学会。或者模型输出一些很不好很敏感的内容怎么办?
总的来说,模型并不是越大用户体验就越好,因为它不一定符合用户使用的目标(在工作中我们常用“对齐” aligned这个词来保证公司里各个团队之间的目标保持一致),模型也一样,它没有和用户“对齐”,因此可能会输出让用户觉得不满意、甚至觉得感到冒犯的内容。从学术上来说,模型只要能刷榜刷很高的分数就可以了,但是在实际的商业落地场景中,用户的体验非常重要,如果模型输出敏感性的内容会产生非常大的负面影响。因此需要模型和人类之间“对齐”,于是引出了基于人类反馈的微调(fine-tuning with human feedback)
首先通过OpenAI API收集到的问题,使用标注工具来对这些问题标注了一个数据集,在这个数据集上对GPT3进行微调(监督学习)。
接下来,再收集了一个数据集,这个数据集是给定一些问题,模型会产生不同的输出,对模型的输出进行打分,有了排序之后这个数据集会在后面使用向基于人类反馈的强化学习的方法进行微调,最终的模型就叫InstructGPT。
RLHF
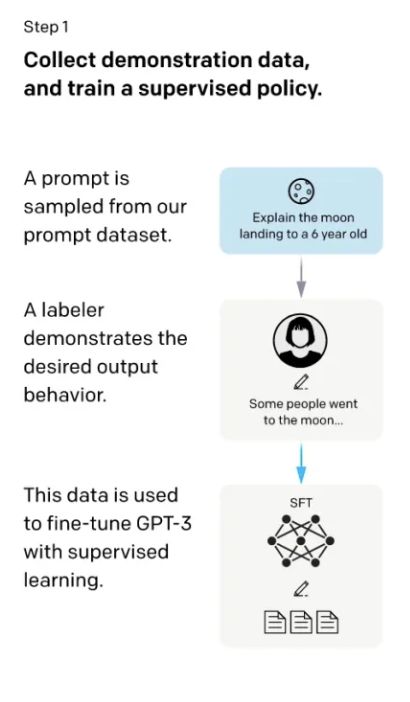
第一步,首先找了些人来标注一个数据集,在数据集里写了各种各样的问题,这些问题在GPT里我们叫做 prompt。这里面的问题就类似于给6岁的小朋友来解释什么是登月,然后标注员对问题写了答案,比如回答登月的这个问题的答案为“一些人去了月球巴拉巴拉的....“。于是就得到了问题和答案,把问题和答案拼接成一段话,然后在这些数据上进行微调GPT3,微调出来的模型叫做SFT(supervised Fine-tune,基于监督学习的微调)。虽然这里标注了数据进行了微调,但是实际上在GPT眼里,它实际上就是给定一些词,让它预测后面的词,这个过程和语言模型预训练的过程没有太多区别。这个过程有个问题就是如果把所有收集到的数据都进行标注成本非常高,于是就有了第二步。
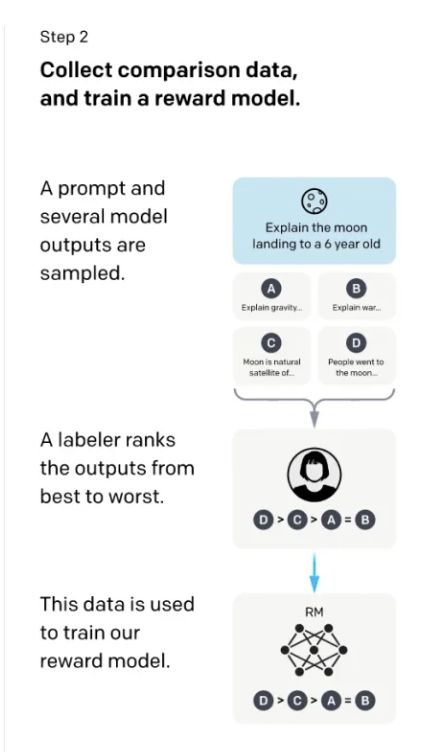
在第二步里,这里的标注会更简单一些。我们给模型问题,比如还是前面的给6岁的小朋友来解释什么是登月,让第一步训练好的SFT这个模型来生成问题的答案,GPT生成的原理是每一次预测一个词的概率,根据这个概率进行采样,可以采样出多个不同的答案,简单来说就是让GPT对每个问题都生成多个不同的答案。然后让人来给模型生成的每个问题的这些答案进行打分。比如上图中,模型生成了A,B,C,D四个答案,然后让人来对这四个答案进行打分排序(D比C好,C比A好,A和B差不多),这个排序就是数据的标注了。有了这些排序之后,训练一个模型,这个模型叫做RM(Reward Model 奖励模型)。这个模型负责的工作是:给一个prompt,给对应的输出,对输出生成一个打分,使得对答案的打分满足标注的数据排序的关系(D>C>A=B)。第二步的目标就是训练一个打分的模型。
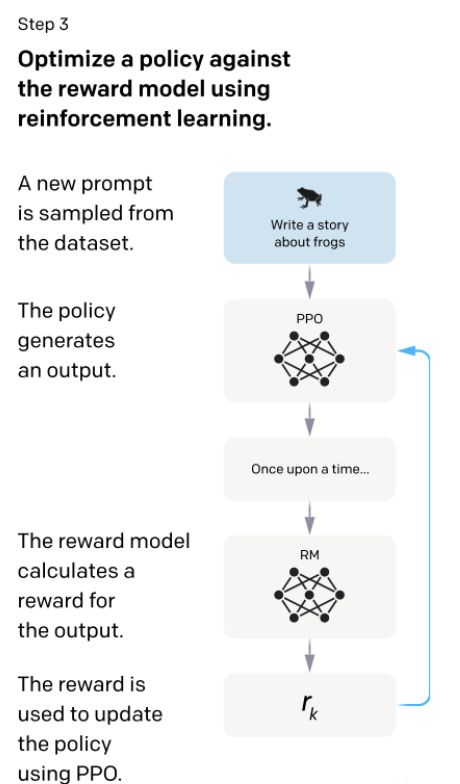
第三步就是继续微调第一步中训练好的SFT模型,生成的答案给第二步的RM模型打分,更新SFT模型的参数使得生成的答案尽可能的得到一个比较高的打分。理论上来说,如果第一步能标注足够多的数据的话,其实后面两步可以忽略可能也是可行的,但是写一个答案属于生成式的任务标注,和给第二步中给答案打分属于判别式的任务标注,判别式的任务标注数据的成本是远低于生成式任务的成本的。因此,第二和第三步可以让在同样标注的成本下能得到更多的数据,使得模型的性能更好。第三步训练完成之后的模型就是InstructGPT。