一文教会你三维网格物体识别
本文由「图普科技」编译自Medium
2017年3月,当时我的老板说自动识别3D物体几乎是不可能的,但大家一致反对。
因此,今天我要解决的问题是:如何输入3D网格物体(原始三角形和顶点),得到分类概率的输出。
我找到了如下几种解决方案:
l 对物体进行缩放并将其分割成体素。将体素给到神经网络中。
l 计算大量描述符,将其放入分类器。
l 从多侧进行物体投射,尝试用单独的分类器进行识别,然后将其放到元分类器中。
在这里我想详细讲述一下一种相对简单有效的方法,即DeepPano方法。
数据准备
如今,图像数据集包含大量样本。但就3D模型数据集而言,并非如此。3D模型数据集中没有成千上万的图像,因此3D模型识别没有得到深入研究,3D模型数据集也不均衡。大多数数据集包含有未进行方向对齐的物体。
ModelNet10是一个相对清晰的3D物体数据集。3D物体在数据集中被存储为包含点线面的.off文件。 .off文件格式不支持显示布料、纹理以及其他材质。
这里是物体种类与样本数量:
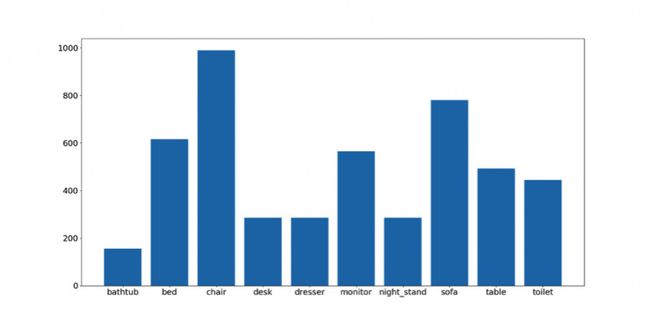
样本总数约为5000。当然这个数据集也非常不均衡。
首先要做的是选择分类器类型。由于如图像、语音等重要数据的技术解决方案都是基于神经网络(或在Kaggle比赛中经常使用的奇特组件),因此训练神经网络是合乎逻辑的。神经网络对数据集的均衡性很敏感。所以第二步需要做的是使数据集更均衡。
我决定使用从3dWarehouse中得到的模型获取更多数据并创建扩展数据集。这些模型是以.skp文件格式存储的,因此必须进行转换。我使用SketchUp C Api创建了.skp - >.off转换器来进行转换。
下一步是数据清理,完全相同的图像已被删除。可以这样分配:
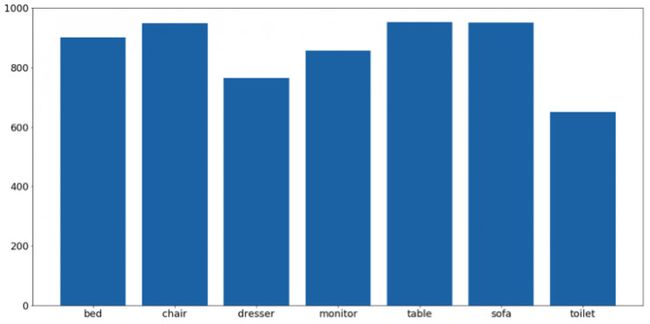
这样数据集看起来就比较均衡了。除马桶外,几乎每个物体类别都包含有近1000个样本。其他物体类型之间的不均衡可通过分类权重进行修正。
数据预处理
在之前的步骤中,我们已经做了几件重要的事情。
l 阐述问题。
l 下载我们将要使用的基本数据集(ModelNet10)。
l 从最初的10类物体中选出了7类。
l 通过创建.skp - > .off转换器来转换3d warehouse.中的模型,数据集变得更加均衡。
现在开始深入了解数据预处理。
在预处理过程中,数据预处理的最终结果是要用一种新的图像来表示3D网格物体。我们将使用圆柱投影来创建图像。

3D网格物体

此物体的转换结果
首先,我们需要读入3D网格物体并进行存储。这可以通过功能强大的trimesh库来完成。它不仅提供读/写功能,而且有大量其他有用的功能,如网格变换,光线追踪等。
第二步是计算圆柱投影。圆柱投影是什么呢?假设一个立方体位于XoY平面的中心,且原点有一条垂直轴。
注意:如果物体的主轴不垂直,则需要在进行物体识别前应用方向对齐算法。这是一个完全不同的领域,因此在这里不对此主题进行探讨。
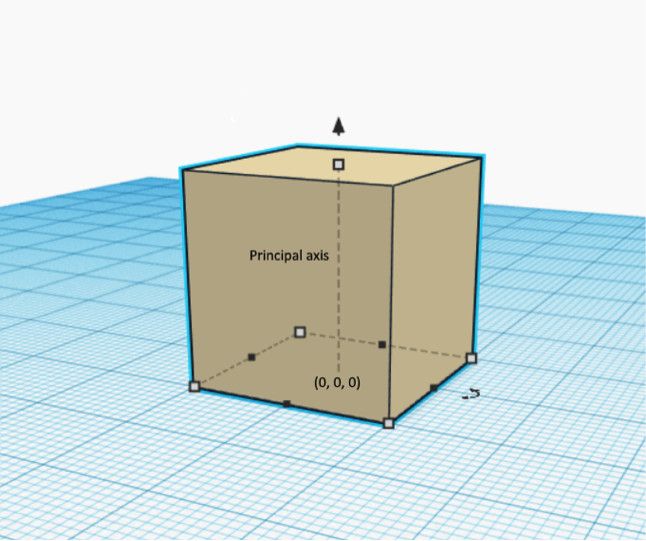
立方体和主轴

现在假设有一个包裹立方体的最小圆柱体。

现在将圆柱体的侧面切割成M×N的网格。

现在将每个网格节点垂直投影到主轴上并获取一组投影点。投影点集合由P表示。投影线集合由S表示。
绿色是主轴,红色是网格,黄色是几何投影线。
现在将S集合中的每段与网格体,即该立方体相交。你将从每条射线获得一个交点。将该点分配给相应的网格节点。
其实这是一个特例。一般情况下,S中的一个投影线可以有多个交点,或者根本没有交点。下面就是一个例子。

因此,通常这个过程的结果是在每个单元中都有一个M×N矩阵,其中可能具有交点数组,也可能是空的。对于立方体,每个单元格将包含具有单个元素的数组。
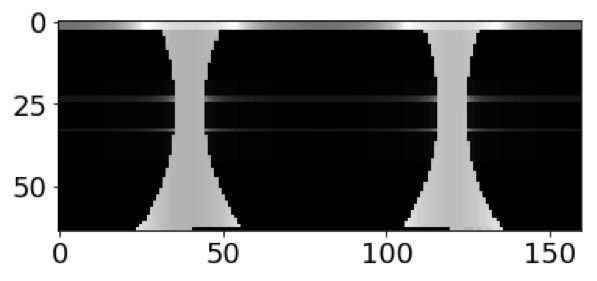
下一步是从每个单元格的交点中选取离对应的M中的点距离最远的点,并将它们之间的距离写入M×N矩阵R。矩阵(或图像)R称为全景图。
我们为什么要选取最远的点?最远的点通常集中于物体的外表面。我们将其用全景图表示,可用于识别模块。当然,有人可能会说:“圆环和高度相同的圆柱体会呈现出完全相同的全景图”或者“中心有一个球形孔的立方体和没有孔的立方体会呈现出完全相同的全景图”,这是正确的。以全景图来呈现3D物体并不完美,但如果是用体素来呈现则没有这样的缺点。幸运的是,像椅子、床、汽车或飞机这些真实存在的物体由于其复杂性,很少有相同的全景图。
最后一步是通过将单元格的值缩放到[0,1]区间,对R矩阵进行归一化。如果单元格没有交点,则该单元格的值为零。
现在我们可以将矩阵R视为灰度图像。这里是所描述过程的python代码和全景图计算的一个例子。



混凝土床、椅子和马桶的全景图。
我们总结一下到目前为止已经完成的步骤。
l 现在我们已经将3D网格物体表示为灰度图像。
l 3D物体必须正确对齐。如果没有正确对齐,那么我们首先需要使用方向对齐算法。
l 两个不同的物体有可能具有相同的全景图,但这种可能性很小。
现在我们准备创建卷积神经网络并解决识别问题。
开始识别!
我们在上一步中做了一件非常重要的事情,即找到一种合适的方法将3D物体转换成图像,我们可以将其提供给神经网络(NN)。
步骤如下所示:
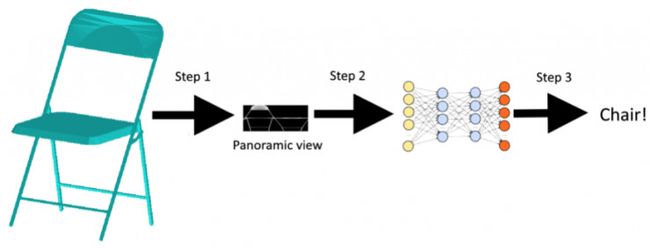
我们之前已经完成了第1步,所以现在我们开始第2步和第3步。
让我们从模型创建开始。
你可以在架构中看到RWMP层。根据DeepPano论文,RWMP层的作用在于, 在3D物体围绕主轴旋转的情况下,保持识别精度不变。从技术上讲,RWMP只是一个行式的MaxPooling。
模型准备就绪并编译完成后,读取数据,然后将其刷新,并通过图像尺寸调节创建ImageDataGenerator。请注意,数据预先按照70:15:15的比例进行了训练、验证和测试。由于图像是合成的,并且代表了3D物体,因此数据无法进行扩增,因为:
l 由于图像是灰度的,所以不能进行颜色增强。
l 由于RWMP的存在,不能进行水平翻转。
l 垂直翻转意味着将物体颠倒。
l 由于图像的合成性质,无法使用ZCA白化。
l 随机旋转会损失宝贵的物体边角信息,我无法确定这会对3D物体转换产生什么影响。
所以我想不出任何可以应用在这里的数据扩增方法。

现在开始训练模型。

让我们看看结果。
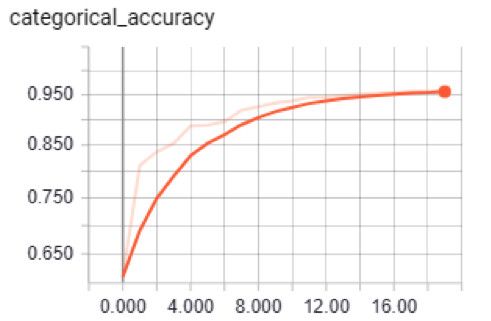
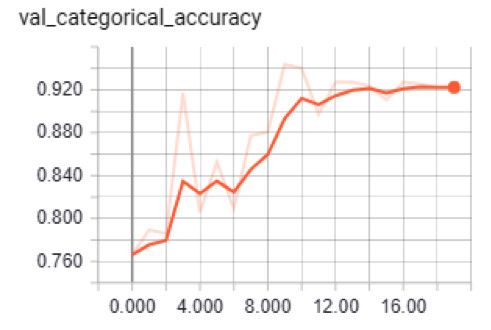
训练绝对准确度和验证绝对准确度
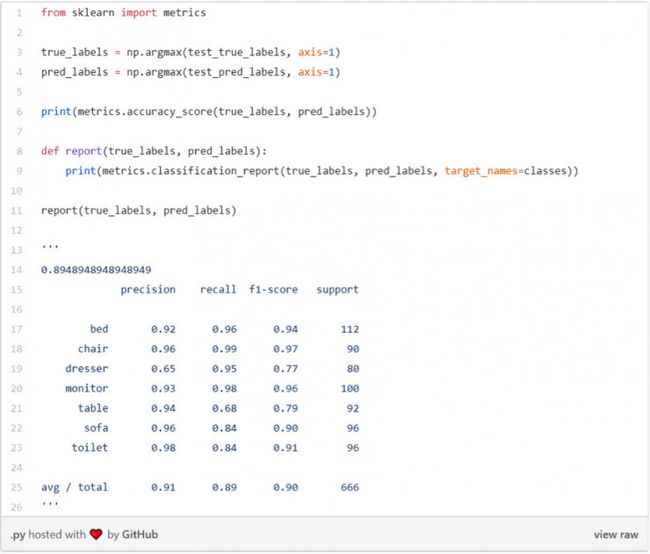
正如你所看到的,该模型验证的准确度达到了92%,训练的准确度达到了95%,所以没有过度拟合。该模型数据集测试的整体准确度度为0.895。
分类报告:
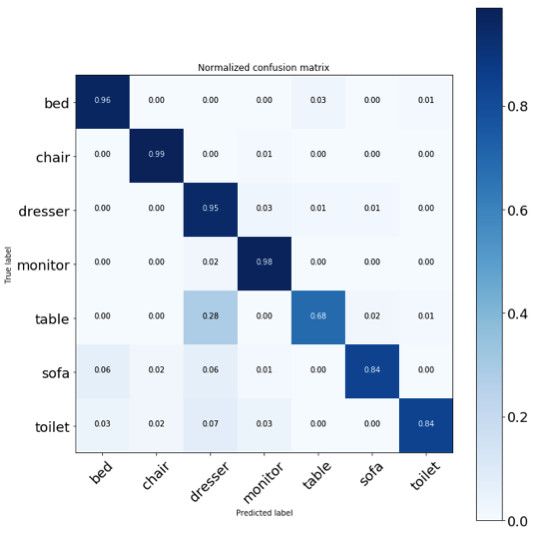
测试数据集的混淆矩阵
我们也可以自行排列这个模型。
来自上面的代码片段
结果看起来不错,一切都进行得都很顺利,只是有些桌子被错误地识别为梳妆台了。我不确定为什么会发生这种情况。这可能是未来需要改进的步骤之一。
让我们列出可能需要改进的地方。
l 识别时要考虑材料、纹理和几何尺寸等因素,否则会形成致无序模型。
l 提高数据集的均衡性或至少使用分类权重。生成模型(例如VAE)可使数据集更均衡。
l 添加更多的物体类别。
l 基于全景图和不同的表示形式创建元模型,例如体素。这可能很昂贵。
到目前为止,所有步骤介绍完毕。
注:本文由「图普科技」编译,您可以关注微信公众号tuputech,体验基于深度学习的「图像识别」应用。