【操作系统】xv6文件系统分析报告(含超全超详细代码注释)
目录:
- 故事的开头总是极尽温柔,故事会一直温柔……
-
- 前言:xv6文件系统
- 1 xv6文件系统架构
-
- 1.1 概述
- 1.2 磁盘划分
- 1.3 逻辑结构与物理结构
- 1.4 文件描述符、file结构体、索引节点inode和盘块关系
- 1.5 block块管理
- 1.6 inode保存数据的结构(使用两层的结构进行数据存储)
- 2 文件系统具体代码
-
- 2.1 fs.h
- 2.2 fcntl.h
- 2.3 buf.h
- 2.4 bio.c
- 2.5 fs.c
-
- 2.5.1 Block(盘块操作部分):
- 2.5.2 Inodes(inode操作部分):
- 2.5.3 Directories(目录部分):
- 2.6 stat.h
- 2.7 file.h
- 2.8 file.c
- 2.9 sysfile.c
- 2.10 log.c
- 2.11 pipe.c
- 3 学习总结与展望
- ❤️❤️❤️忙碌的敲代码也不要忘了浪漫鸭!
故事的开头总是极尽温柔,故事会一直温柔……
✨你好啊,我是“ 怪& ”,是一名在校大学生哦。
主页链接:怪&的个人博客主页
☀️博文主更方向为:课程学习知识、作业题解、期末备考。随着专业的深入会越来越广哦…一起期待。
❤️一个“不想让我曾没有做好的也成为你的遗憾”的博主。
很高兴与你相遇,一起加油!
前言:xv6文件系统
文件系统的目的是组织和存储数据,典型的文件系统支持用户和程序间的数据共享,并提供数据持久化的支持(即重启之后数据仍然可用)。
xv6 的文件系统中使用了类似 Unix 的文件,文件描述符,目录和路经名,并且把数据存储到一块 IDE 磁盘上。这个文件系统解决了几大难题:
- 该文件系统需要磁盘上数据结构来表示目录树和文件,记录每个文件用于存储数据的块,以及磁盘上哪些区域是空闲的。
- 该文件系统必须支持崩溃恢复,也就是说,如果系统崩溃了(比如掉电了),文件系统必须保证在重启后仍能正常工作。问题在于一次系统崩溃可能打断一连串的更新操作,从而使得磁盘上的数据结构变得不一致(例如:有的块同时被标记为使用中和空闲)。
- 不同的进程可能同时操作文件系统,要保证这种并行不会破坏文件系统的正常工作。
- 访问磁盘比访问内存要慢几个数量级,所以文件系统必须要维护一个内存内的 cache 用于缓存常被访问的块。
1 xv6文件系统架构
1.1 概述
xv6文件系统实现分为七层。
-
Disk层读取和写入virtio硬盘上的块。
-
Buffer cache层将磁盘块缓存在内存中并同步对它们的访问,确保每次只有一个内核进程可以修改存储在任何特定块中的数据。
-
logging层允许更高层把对于多个块的更新包装成一次事务(transaction),并确保在遇到崩溃时自动保持这些块的一致性(即,所有块都已更新或无更新)。
-
Inode层提供单独的文件,每个文件表示为一个索引结点,其中包含唯一的索引号(i-number)和一些保存文件数据的块。
-
Directorie层将每个目录实现为一种特殊的索引结点,其内容是一系列目录项,每个目录项包含一个文件名和inode num。
-
Pathname层提供了分层路径名,如/usr/rtm/xv6/fs.c,并通过递归查找来解析它们。
-
File descriptor层使用文件系统接口抽象了许多Unix资源(例如,管道、设备、文件等),简化了应用程序员的工作。

1.2 磁盘划分
文件系统必须有将索引节点和内容块存储在磁盘上哪些位置的方案。为此,xv6将磁盘划分为几个部分。文件系统不使用块0(它保存引导扇区)。块1称为超级块:它包含有关整个文件系统的元数据以及文件系统的layout(文件系统大小(以块为单位)、数据块数、索引节点数和日志中的块数)。从2开始的块保存日志。日志之后是索引节点,每个磁盘块中有多个inode。然后是位图块,跟踪正在使用的数据块。其余的块是数据块:每个都要么在位图块中标记为空闲,要么保存文件或目录的内容。超级块由一个名为mkfs的单独的程序填充,该程序构建初始文件系统。
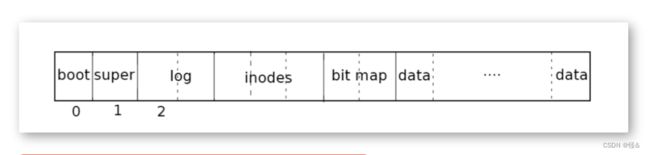
1.3 逻辑结构与物理结构
1.4 文件描述符、file结构体、索引节点inode和盘块关系
1.5 block块管理
1.6 inode保存数据的结构(使用两层的结构进行数据存储)
2 文件系统具体代码
2.1 fs.h
fs.h主要定义了超级块superblock、索引节点 dinode 和目录项 dirent。其次是声明几个文件系统中的常量,IPB(inode per block)是每个盘块上可以记录的inode 数量,IBLOCK(I, sb)用来计算第i个inode 位于哪个盘块,BPB(bitmap bits petblock)是一个盘块的位数,BBI.OCK(b,sb)用于计算第了个数据盘块所对应的位图位所在的盘块号,DIRSIZ(directory size)是目录项中文件名字符串的大小。
// On-disk file system format.
// Both the kernel and user programs use this header file.
// fs.h主要定义了超级块superblock、索引节点dinode和⽬录项dirent。 // 磁盘⽂件系统格式。
// 内核和⽤户程序都使⽤此头⽂件。
#define ROOTINO 1 // root i-number 根节点
#define BSIZE 512 // block size 块
// Disk layout:
// [ boot block | super block | log | inode blocks |
// free bit map | data blocks]
//
//MKFS计算超级块并构建初始文件系统。super block描述磁盘布局:
struct superblock {//超级块记录文件系统的元信息
uint size; //文件系统的大小,以块为单位
uint nblocks; // 数据块的数量
uint ninodes; // inode结点数量
uint nlog; // 日志块数量
uint logstart; // 第一个日志块的块号
uint inodestart; // 第一个i结点所在的块号
uint bmapstart; // 第一个位图块块号
};
#define NDIRECT 12
#define NINDIRECT (BSIZE / sizeof(uint))
#define MAXFILE (NDIRECT + NINDIRECT)
// On-disk inode structure
struct dinode {
short type; // 文件类型,为0代表该indoe空闲
short major; // 主盘数量(只能是T_DEV)
short minor; // 从盘数量(只能是T_DEV)
short nlink; // 文件系统中到inode的链接数
uint size; // 文件大小
uint addrs[NDIRECT+1]; // 实际存放的数据块号
};
// 每个盘块上记录的inode数量
#define IPB (BSIZE / sizeof(struct dinode))
// i ⽤来记录哪个盘块记录第 i个inode
#define IBLOCK(i, sb) ((i) / IPB + sb.inodestart)
//表示⼀个盘块的位数
#define BPB (BSIZE*8)
// ⽤于计算第b个数据盘块所对应的位图位所在的盘块号
#define BBLOCK(b, sb) (b/BPB + sb.bmapstart)
// 目录是一个包含一系列不同结构的文件。
#define DIRSIZ 14
struct dirent {//目录项结构
ushort inum;//inode编号
char name[DIRSIZ];//目录名字
};
2.2 fcntl.h
fcntl.h中定义了打开文件时的访问模式(不是文件自身的可访问权限)。其包括:读模式、写模式、读写模式、创建模式。
#define O_RDONLY 0x000 //读
#define O_WRONLY 0x001 //写
#define O_RDWR 0x002 //读写
#define O_CREATE 0x200 //创建
2.3 buf.h
单个块缓冲区用buf结构体来记录,
单个块缓冲区使用代码buf结构体来记录。其中的盘块数据记录在 buf.data[ BSIZE] (512 字节)成员中,所缓存的盘块号为 blockno,所在的设备由 dev 指出,prex和next用于和其他块缓存一起构建 LRU 链表,最后,如果块缓存是脏的,将通过qnext 挂人到磁盘I/O调度队列。

struct buf {
int flags;//磁盘标志状态,表示该块是否脏是否有效
uint dev; //缓存块所在设备
uint blockno;//对应的盘块号
struct sleeplock lock;//休眠锁
uint refcnt;
struct buf *prev; // LRU cache list前向指针
struct buf *next; //后向指针
struct buf *qnext;//所在磁盘I/O调度队列
uchar data[BSIZE];//缓冲块数据大小
};
#define B_VALID 0x2 // 已从磁盘读取缓冲区
#define B_DIRTY 0x4 // 缓冲区需要写入磁盘
2.4 bio.c
块缓冲有两个任务:
(1)同步对磁盘的访问,使得对于每一个块,同一时间只有一份拷贝放在内存中并且只有一个内核线程使用这份拷贝;
(2)缓存常用的块以提升性能。
块缓冲提供的的主要接口是 bread 和 bwrite;前者从磁盘中取出一块放入缓冲区,后者把缓冲区中的一块写到磁盘上正确的地方。当内核处理完一个缓冲块之后,需要调用 brelse 释放它。
块缓冲仅允许最多一个内核线程引用它,以此来同步对磁盘的访问,如果一个内核线程引用了一个缓冲块,但还没有释放它,那么其他调用 bread 的进程就会阻塞。文件系统的更高几层正是依赖块缓冲层的同步机制来保证其正确性。
块缓冲有固定数量的缓冲区,这意味着如果文件系统请求一个不在缓冲中的块,必须换出一个已经使用的缓冲区。这里的置换策略是 LRU,因为我们假设假设最近未使用的块近期内最不可能再被使用。
Xv6中Buffer Cache的实现在bio.c中,Buffer Cache的数据结构如下(rev11版本)
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// head.next is most recently used.
struct buf head;
} bcache;
此数据结构在固定长度的数组上维护了一个由struct buf组成的双向链表,并且用一个锁来保护对Buffer Cache链表结构的访问。值得注意的是,对链表结构的访问和对一个struct buf结构的访问需要的是不同的锁。
在缓存初始化时,系统调用binit()对缓存进行初始化。binit()函数对缓存内每个元素初始化了睡眠锁,并从后往前连接成一个双向链表。一开始的时候,缓存内所有的块都是空的。
上层文件系统使用bread()和bwrite()对缓存中的磁盘块进行读写。关于缓存的全部操作是在bread()与bwrite()中自动完成的,不需要上层文件系统的参与。
bread()会首先调用bget()函数,bget()函数会检查请求的磁盘块是否在缓存中。如果在缓存中,那么直接返回缓存中对应的磁盘块即可。如果不在缓存中,那么需要先使用最底层的iderw()函数先将此磁盘块从磁盘加载进缓存中,再返回此磁盘块。
-
bget()函数的实现有一些Tricky。搜索缓存块的代码非常直接,但是在其中必须仔细考虑多进程同时访问磁盘块时的同步机制。在Xv6 rev7版本中由于没有实现睡眠锁,为了避免等待的缓冲区在等待的过程中改变了内容,必须在从锁中醒来时重新扫描磁盘缓冲区寻找合适的磁盘块,但是在rev11版本中由于实现了睡眠锁,在找到对应的缓存块时,只需释放对Buffer Cache的锁并拿到与当前缓存块有关的睡眠锁即可。 -
bwrite()函数直接将缓存中的数据写入磁盘。Buffer Cache层不会尝试执行任何延迟写入的操作,何时调用bwrite()写入磁盘是由上层的文件系统控制的。 -
上层文件系统调用
brelse()函数来释放一块不再使用的冲区。brelse()函数中主要涉及的是对双向链表的操作。
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
// buffer cache是一个buf结构的链表磁盘块内容的缓存副本。缓存磁盘块减少磁盘读取的数量,并且还提供多个进程使用的磁盘块的同步点。
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
//接口:
// *为特定的磁盘块获取缓冲区,调用bread。
// *更改缓冲区数据后,调用bwrite将其写入磁盘。
// *当使用完缓冲区时,调用brelse。
// *调用brelse后不使用缓冲区。
// *每次只能有一个进程使用缓冲区
//所以不要保留它们超过必要的时间。
// The implementation uses two state flags internally:
// * B_VALID: the buffer data has been read from the disk.
// * B_DIRTY: the buffer data has been modified
// and needs to be written to disk.
//实现在内部使用两个状态标志:
// * B_VALID:缓冲区数据已从磁盘读取。
// * B_DIRTY:缓冲区数据已被修改
//需要写入磁盘。
#include "types.h"
#include "defs.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "fs.h"
#include "buf.h"
struct {
struct spinlock lock;//互斥锁
struct buf buf[NBUF];//块缓存(内存区)
// Linked list of all buffers, through prev/next. 通过上⼀个/下⼀个链接所有缓冲区的列表。
// head.next is most recently used. 下⼀个指针更常⽤
struct buf head;//块缓存链表头
} bcache;
void
binit(void)//头插法将N个缓存块串起来
{
struct buf *b;
initlock(&bcache.lock, "bcache");//初始化缓存块锁
//PAGEBREAK!
// Create linked list of buffers
bcache.head.prev = &bcache.head;//将全部buf构成双向链表
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){//将NBUF个块缓存挂入链表
b->next = bcache.head.next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
//查看设备dev上的block:如果没有找到,分配一个缓冲区。否则,返回锁定的缓冲区。
static struct buf*
bget(uint dev, uint blockno)//查找指定盘块的块缓存
{
struct buf *b;
acquire(&bcache.lock);//获取bcache的锁
// Is the block already cached?//要获取的盘块已经缓存
for(b = bcache.head.next; b != &bcache.head; b = b->next){//双向循环链表,从前往后扫描
if(b->dev == dev && b->blockno == blockno){//找到匹配的块缓存,设备和块号都匹配
b->refcnt++;//块的引用+1
release(&bcache.lock);//释放bcache的锁
acquiresleep(&b->lock);//获得sleep锁
return b;//返回该块
}
}
// Not cached; recycle an unused buffer.没找到匹配的块缓存
// Even if refcnt==0, B_DIRTY indicates a buffer is in use//无法直接回收使用
// because log.c has modified it but not yet committed it.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){//该磁盘块没有缓存,从后往前扫描
if(b->refcnt == 0 && (b->flags & B_DIRTY) == 0) {//找一个引用为0,且脏位也为0的空闲缓存块
b->dev = dev;//设备
b->blockno = blockno;//块号
b->flags = 0;/只是将磁盘块所属设备和块号赋给了刚分配的缓存块,但是数据还没有传到缓存块,这需要磁盘请求,所以为0表示缓存块里面的数据无效。
b->refcnt = 1;//引用数为1
release(&bcache.lock);//释放bcache的锁
acquiresleep(&b->lock);//给该块加锁
return b;//将这个块缓存到b
}
}
panic("bget: no buffers");//既没缓存该块,也没得空闲缓存块了
}
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)//读入一个盘块返回它的块缓存
{
struct buf *b;
b = bget(dev, blockno);//找到或者分配一个块缓存
if((b->flags & B_VALID) == 0) {//如果该块是临时分配的数据无效
iderw(b);//通过IDE设备驱动程序Iiderw()读入
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)//将缓存块写到相应磁盘块
{
if(!holdingsleep(&b->lock)) 判断其是否获得其sleep锁
panic("bwrite");
b->flags |= B_DIRTY;//设置脏位
iderw(b);//通过IDE设备驱动程序iderw ()写⼊
}
// Release a locked buffer.
// Move to the head of the MRU list.
void
brelse(struct buf *b)//用完后释放,并挂到LRU链表头处
{
if(!holdingsleep(&b->lock)) //判读是否正在使⽤
panic("brelse");
releasesleep(&b->lock); //释放睡眠锁
acquire(&bcache.lock);//获得锁
b->refcnt--;
if (b->refcnt == 0) {/没有地方再引用这个块,将块链接到缓存区链头
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head.next;
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
}
release(&bcache.lock); //释放锁
}
//PAGEBREAK!
// Blank page.
2.5 fs.c
文件系统实现包括五层:
- Blocks:裸磁盘块的分配器。
- 日志:多步更新的崩溃恢复。
- 文件:inode分配器,读写,元数据。
- 目录:包含特殊内容的inode(其他inode的列表!)
- 名称:例如/usr/rtm/xv6/fs.c,便于命名。
2.5.1 Block(盘块操作部分):
盘块的读写操作是文件系统最基本的操作,后面的访问素引节点和目录等操作,都依赖于盘块的读写。
// File system implementation. Five layers:
// + Blocks: allocator for raw disk blocks.
// + Log: crash recovery for multi-step updates.
// + Files: inode allocator, reading, writing, metadata.
// + Directories: inode with special contents (list of other inodes!)
// + Names: paths like /usr/rtm/xv6/fs.c for convenient naming.
//
// This file contains the low-level file system manipulation
// routines. The (higher-level) system call implementations
// are in sysfile.c.
//文件系统实现。五层:
// + Blocks:裸磁盘块的分配器。
// +日志:多步更新的崩溃恢复。
// +文件:inode分配器,读写,元数据。
// +目录:包含特殊内容的inode(其他inode的列表!)
// +名称:例如/usr/rtm/xv6/fs.c,便于命名。
//
//该文件包含低级文件系统操作
//例程。(高级)系统调用实现
//在sysfile.c。
#include "types.h"
#include "defs.h"
#include "param.h"
#include "stat.h"
#include "mmu.h"
#include "proc.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "fs.h"
#include "buf.h"
#include "file.h"
#define min(a, b) ((a) < (b) ? (a) : (b))
static void itrunc(struct inode*);
// there should be one superblock per disk device, but we run with
// only one device
struct superblock sb;
// Read the super block.
//读入超级块
void
readsb(int dev, struct superblock *sb)
{
struct buf *bp;//指向超级块
bp = bread(dev, 1);//超级块编号为1
memmove(sb, bp->data, sizeof(*sb));//将超级块中的数据读取到内存中
brelse(bp);//释放资源
}
// Zero a block.
//将dev设备上的bno号盘块清0
static void
bzero(int dev, int bno)
{
struct buf *bp;
bp = bread(dev, bno);//读取bno号盘块中的内容
memset(bp->data, 0, BSIZE);//将bp指向的盘块中的数据清0
log_write(bp);//修改日志中的内容
brelse(bp);//释放资源
}
// Blocks.
// Allocate a zeroed disk block.
static uint
balloc(uint dev)//分配一个未使用的盘块
{
int b, bi, m;
struct buf *bp;
bp = 0;
for(b = 0; b < sb.size; b += BPB){//遍历所有盘块,每次处理BPB个(1bmap块)
bp = bread(dev, BBLOCK(b, sb));//读入一个bmap快
for(bi = 0; bi < BPB && b + bi < sb.size; bi++){/遍历bmap块的所有盘块
m = 1 << (bi % 8);
if((bp->data[bi/8] & m) == 0){ // Is block free? 检查盘块是否空闲
bp->data[bi/8] |= m; // Mark block in use. 则标记为使用
log_write(bp);//写入
brelse(bp);
bzero(dev, b + bi);//清空
return b + bi;
}
}
brelse(bp); //释放
}
panic("balloc: out of blocks"); //打印没有盘块
}
// Free a disk block.释放dev设备上的b号盘块
static void
bfree(int dev, uint b)
{
struct buf *bp;
int bi, m;
bp = bread(dev, BBLOCK(b, sb));//读取磁盘上的b号盘块
// b是块号,BPB是一个块的字节数乘以8,即一个位图块能保存多少个包的使用状态
bi = b % BPB; // b%BPB,则可以得到是该位图块的哪个bit保存了这个块的信息
// bi就是该bit在该位图块中的index
// bi/8,该块哪一字节保存此块信息
// bi%8,该块哪一bit保存此块信息
m = 1 << (bi % 8);
// 位图块的组织方式和inode不一样,它的data部分保存的就是bit map bit
// 位图块对应的字节,如果&mask后为0,说明本来就是空闲,那么属于refree。否则,就是用mask进行释放
if((bp->data[bi/8] & m) == 0) //
panic("freeing free block");
bp->data[bi/8] &= ~m;
log_write(bp);//修改日志内容
brelse(bp);
}
2.5.2 Inodes(inode操作部分):
对于Inode节点的基本操作如下
| 函数名 | 功能 |
|---|---|
iinit() |
读取Superblock,初始化inode相关的锁 |
ialloc() |
在磁盘上分配一个inode |
iupdate() |
将内存里的一个inode写入磁盘 |
iget() |
获取指定inode,更新缓存 |
iput() |
对内存内一个Inode引用减1,引用为0则释放inode |
ilock() |
获取指定inode的锁 |
iunlock() |
释放指定inode的锁 |
readi() |
往inode读数据 |
writei() |
往inode写数据 |
bmap() |
返回inode的第n个数据块的磁盘地址 |
// Inodes.
//
// An inode describes a single unnamed file.
// The inode disk structure holds metadata: the file's type,
// its size, the number of links referring to it, and the
// list of blocks holding the file's content.
//
// The inodes are laid out sequentially on disk at
// sb.startinode. Each inode has a number, indicating its
// position on the disk.
//
// The kernel keeps a cache of in-use inodes in memory
// to provide a place for synchronizing access
// to inodes used by multiple processes. The cached
// inodes include book-keeping information that is
// not stored on disk: ip->ref and ip->valid.
//
// An inode and its in-memory representation go through a
// sequence of states before they can be used by the
// rest of the file system code.
//
// * Allocation: an inode is allocated if its type (on disk)
// is non-zero. ialloc() allocates, and iput() frees if
// the reference and link counts have fallen to zero.
//
// * Referencing in cache: an entry in the inode cache
// is free if ip->ref is zero. Otherwise ip->ref tracks
// the number of in-memory pointers to the entry (open
// files and current directories). iget() finds or
// creates a cache entry and increments its ref; iput()
// decrements ref.
//
// * Valid: the information (type, size, &c) in an inode
// cache entry is only correct when ip->valid is 1.
// ilock() reads the inode from
// the disk and sets ip->valid, while iput() clears
// ip->valid if ip->ref has fallen to zero.
//
// * Locked: file system code may only examine and modify
// the information in an inode and its content if it
// has first locked the inode.
//
// Thus a typical sequence is:
// ip = iget(dev, inum)
// ilock(ip)
// ... examine and modify ip->xxx ...
// iunlock(ip)
// iput(ip)
//
// ilock() is separate from iget() so that system calls can
// get a long-term reference to an inode (as for an open file)
// and only lock it for short periods (e.g., in read()).
// The separation also helps avoid deadlock and races during
// pathname lookup. iget() increments ip->ref so that the inode
// stays cached and pointers to it remain valid.
//
// Many internal file system functions expect the caller to
// have locked the inodes involved; this lets callers create
// multi-step atomic operations.
//
// The icache.lock spin-lock protects the allocation of icache
// entries. Since ip->ref indicates whether an entry is free,
// and ip->dev and ip->inum indicate which i-node an entry
// holds, one must hold icache.lock while using any of those fields.
//
// An ip->lock sleep-lock protects all ip-> fields other than ref,
// dev, and inum. One must hold ip->lock in order to
// read or write that inode's ip->valid, ip->size, ip->type, &c.
// inode。
//一个inode描述了一个单独的未命名文件。
// inode磁盘结构包含元数据:文件类型,大小,引用它的链接数量,以及包含文件内容的块列表。这些inode在sb.startinode的磁盘上按顺序排列。每个inode都有一个编号,表示它在磁盘上的位置。
//内核在内存中保留了一个正在使用的inode的缓存,以提供一个地方来同步多个进程使用的inode的访问。缓存的inodes包括未存储在磁盘上的簿记信息:ip->ref和ip->valid。
//在文件系统代码的其余部分使用inode和它在内存中的表示形式之前,它们会经历一个状态序列。
// *分配:如果inode的类型(在磁盘上)非零,则分配inode。Ialloc()分配,iput()释放,如果引用和链接计数已降为零。
// *在缓存中引用:如果ip->ref为零,inode缓存中的条目是空闲的。否则,ip->ref跟踪内存中指向条目(打开文件和当前目录)的指针的数量。Iget()查找或创建一个缓存条目并增加其ref;iput() decments ref.
// * Valid:当ip-> Valid为1时,inode缓存条目中的信息(type, size, &c)才是正确的。ilock()从磁盘读取inode并设置ip->valid,而iput()在ip->ref为零时清除 ip->valid。
* Locked:文件系统代码只能检查和修改inode中的信息及其内容,如果它已经锁定了inode。
//因此,一个典型的序列是: ip = iget(dev, inum) ilock(ip)…检查和修改ip->xxx…iunlock(ip) iput(ip)
// ilock()与iget()是分开的,因此系统调用可以获得对inode的长期引用(例如打开的文件)并且只在短时间内锁定它(例如在read()中)。在查找路径名时,分隔可以避免死锁和争速。Iget()增加ip->ref,这样inode将保持缓存,指向它的指针仍然有效。
//许多内部文件系统函数期望调用者已经锁定了相关的inode;这允许调用者创建多步原子操作。
// icache。Lock spin-lock保护icache表项的分配。由于ip->ref表示条目是否空闲,和ip->dev和ip->inum表示条目持有哪个i-node,因此必须持有icache。在使用这些字段时锁定。
//一个ip->锁定睡眠锁定保护所有ip->除ref、 dev和inum外的其他字段。必须持有ip->lock,以便读写inode的ip->valid, ip->size, ip->type, &c。
struct {//缓存结构体
struct spinlock lock;//锁
struct inode inode[NINODE];//inode
} icache;
void
iinit(int dev)//初始化indoe相关锁,读取超级块
{
int i = 0;
initlock(&icache.lock, "icache");//初始化锁
for(i = 0; i < NINODE; i++) {
initsleeplock(&icache.inode[i].lock, "inode");//初始化休眠锁
}
readsb(dev, &sb);//字节读取磁盘中文件
//输出结点的相关信息
cprintf("sb: size %d nblocks %d ninodes %d nlog %d logstart %d\
inodestart %d bmap start %d\n", sb.size, sb.nblocks,
sb.ninodes, sb.nlog, sb.logstart, sb.inodestart,
sb.bmapstart);
}
static struct inode* iget(uint dev, uint inum);//获取对应的inode,更新缓存
//Pagebreak
//Allocate an inode on device dev
//Mark it as allocated by giving it type
//Returns an unlocked but allocated and referenced inode
// Pagebreak
//在设备dev上分配一个inode,将其标记为已分配类型,返回一个未锁定但已分配并引用的inode
struct inode* //
ialloc(uint dev, short type) //在磁盘中找到空闲的i节点,返回对应的在内核中的i节点
{
int inum; //用于磁盘节点计数
struct buf *bp;
struct dinode *dip;
for(inum = 1; inum < sb.ninodes; inum++){ //遍历磁盘节点
bp = bread(dev, IBLOCK(inum, sb));//读取到第inum个i节点所在的位置
dip = (struct dinode*)bp->data + inum%IPB;//得到这个i结点的地址
if(dip->type == 0){ // a free inode //找到了空闲节点
memset(dip, 0, sizeof(*dip));//初始化磁盘节点的内存空间
dip->type = type;//指向一个type类型的文件
log_write(bp); //在磁盘上进行标记已经分配(并未真正写到磁盘,标记缓存数据为脏)
brelse(bp);//释放缓存块
return iget(dev, inum); //用内存中的i节点缓存磁盘中i节点的数据
}
brelse(bp);//释放换存块
panic("ialloc: no inodes");//磁盘中没有空闲节点
}
// Copy a modified in-memory inode to disk.
// Must be called after every change to an ip->xxx field
// that lives on disk, since i-node cache is write-through.
// Caller must hold ip->lock.
//将修改后的inode拷贝到磁盘。每次更改ip->xxx字段后必须调用,存在于磁盘上,因为i-node缓存是透写的。调用者必须持有ip->
Void//读取inode在磁盘中的块,并更新内容写入磁盘
iupdate(struct inode *ip)
{
struct buf *bp;
struct dinode *dip;
bp = bread(ip->dev, IBLOCK(ip->inum, sb));//获得inode所在的块缓存
dip = (struct dinode*)bp->data + ip->inum%IPB;//定位inode的位置
dip->type = ip->type;//将inode内容更新至dinode中
dip->major = ip->major;
dip->minor = ip->minor;
dip->nlink = ip->nlink;
dip->size = ip->size;
memmove(dip->addrs, ip->addrs, sizeof(ip->addrs));
log_write(bp);//写入日志
brelse(bp);
}
// Find the inode with number inum on device dev
// and return the in-memory copy. Does not lock
// the inode and does not read it from disk.
static struct inode*
//在设备dev上查找编号为inum的inode,并返回内存中的副本。不锁定不从磁盘读取inode。
静态结构inode*
iget(uint dev, uint inum)
{
struct inode *ip, *empty;
acquire(&icache.lock);
// Is the inode already cached?
empty = 0;
for(ip = &icache.inode[0]; ip < &icache.inode[NINODE]; ip++){//遍历缓存
if(ip->ref > 0 && ip->dev == dev && ip->inum == inum){//找到对应的缓存块
ip->ref++;//引用计数+1
release(&icache.lock);
return ip;//返回匹配的inode
}
if(empty == 0 && ip->ref == 0) // Remember empty slot.
empty = ip;//记录第一个空闲的inode
}
// Recycle an inode cache entry. 回收inode缓存项。
if(empty == 0)//没有匹配的inode
panic("iget: no inodes");//输出信息
ip = empty;//回收inode缓存项。
ip->dev = dev;
ip->inum = inum;
ip->ref = 1;
ip->valid = 0;
release(&icache.lock);
return ip;
}
// Increment reference count for ip.
// Returns ip to enable ip = idup(ip1) idiom.
//增加ip的引用计数。返回ip以确保ip = idup(ip1) idiom.
struct inode*//inode结点在内存中的引用次数++
idup(struct inode *ip)
{
acquire(&icache.lock);
ip->ref++;//引用次数+1
release(&icache.lock);
return ip;
}
// Lock the given inode.
// Reads the inode from disk if necessary.
//锁定给定inode。如果需要从磁盘读取inode。
Void//修改inode结点之前需要上锁
ilock(struct inode *ip)
{
struct buf *bp;
struct dinode *dip;
if(ip == 0 || ip->ref < 1)//空指针或者引用次数小于1
panic("ilock");
acquiresleep(&ip->lock);
if(ip->valid == 0){//有效位为0,从磁盘中读入数据
bp = bread(ip->dev, IBLOCK(ip->inum, sb));//从磁盘块中读取
dip = (struct dinode*)bp->data + ip->inum%IPB;
ip->type = dip->type;
ip->major = dip->major;
ip->minor = dip->minor;
ip->nlink = dip->nlink;
ip->size = dip->size;
memmove(ip->addrs, dip->addrs, sizeof(ip->addrs));//更新后的内容写回磁盘
brelse(bp);
ip->valid = 1;
if(ip->type == 0)
panic("ilock: no type");
}
}
// Unlock the given inode.
Void//inode结点释放锁
iunlock(struct inode *ip)
{
if(ip == 0 || !holdingsleep(&ip->lock) || ip->ref < 1)
panic("iunlock");
releasesleep(&ip->lock);
}
// Drop a reference to an in-memory inode.
// If that was the last reference, the inode cache entry can
// be recycled.
// If that was the last reference and the inode has no links
// to it, free the inode (and its content) on disk.
// All calls to iput() must be inside a transaction in
// case it has to free the inode.
//删除对内存中inode的引用。
//如果这是最后一个引用,inode缓存项可以被回收。
//如果这是最后一个引用,并且inode没有链接,释放磁盘上的inode(及其内容)。
//所有对iput()的调用必须在in的事务中如果它必须释放inode。
Void
iput(struct inode *ip)
{
acquiresleep(&ip->lock);
if(ip->valid && ip->nlink == 0){
acquire(&icache.lock); //获得锁
int r = ip->ref;//获取inode结点的引用数
release(&icache.lock);
if(r == 1){//引用数为1,说明只有本身
// inode has no links and no other references: truncate and free.
itrunc(ip);//那么就释放inode所指向的数据块全部释放,也就相当于删除文件了
ip->type = 0;//没有指向结点
iupdate(ip);//更新结点内容
ip->valid = 0;
}
}
releasesleep(&ip->lock);
acquire(&icache.lock);
ip->ref--;//引用数减一
release(&icache.lock);
}
// Common idiom: unlock, then put.
void
iunlockput(struct inode *ip)
{
iunlock(ip);
iput(ip);
}
//PAGEBREAK!
// Inode content
//
// The content (data) associated with each inode is stored
// in blocks on the disk. The first NDIRECT block numbers
// are listed in ip->addrs[]. The next NINDIRECT blocks are
// listed in block ip->addrs[NDIRECT].
// Return the disk block address of the nth block in inode ip.
// If there is no such block, bmap allocates one.
static uint//inode的索引部分用来指向数据块
bmap(struct inode *ip, uint bn)//将文件偏移量转换成盘块号
{
uint addr, *a;
struct buf *bp;
if(bn < NDIRECT){//盘块号小于NDIRECT,直接盘块
if((addr = ip->addrs[bn]) == 0)//直接查找获得盘块号
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
if(bn < NINDIRECT){//一次间接盘块
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0)//如果间接索引盘块还未分配
ip->addrs[NDIRECT] = addr = balloc(ip->dev);//分配一个盘块用于间接索引
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){//如果没有建立间接索引
a[bn] = addr = balloc(ip->dev);//则分配一个数据盘块
log_write(bp);
}
brelse(bp);//返回bn所映射的盘块
return addr;
}
panic("bmap: out of range");
}
// Truncate inode (discard contents).
// Only called when the inode has no links
// to it (no directory entries referring to it)
// and has no in-memory reference to it (is
// not an open file or current directory).
//截断inode(丢弃内容)只在inode没有链接时调用指向它(没有指向它的目录条目)没有内存中对它的引用不是打开的文件或当前目录)。
static void//将inode结点指向的数据块全部释放,即删除文件
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
for(i = 0; i < NDIRECT; i++){//逐个判断索引是否有效,有效就用bfree释放,然后置为无效
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){//同上是二级索引
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
ip->size = 0;
iupdate(ip);//更新结点内容
}
// Copy stat information from inode.
// Caller must hold ip->lock.
void
stati(struct inode *ip, struct stat *st)//获取inode结点的信息
{
st->dev = ip->dev;
st->ino = ip->inum;
st->type = ip->type;
st->nlink = ip->nlink;
st->size = ip->size;
}
//PAGEBREAK!
// Read data from inode.
// Caller must hold ip->lock.
int
readi(struct inode *ip, char *dst, uint off, uint n)
{
uint tot, m;
struct buf *bp;
if(ip->type == T_DEV){//如果是设备文件
if(ip->major < 0 || ip->major >= NDEV || !devsw[ip->major].read)
return -1;
return devsw[ip->major].read(ip, dst, n);//使用设备文件自己的read操作函数进行读取
}
//以下是磁盘文件的读操作
if(off > ip->size || off + n < off)//检查读入起点是否越界
return -1;
if(off + n > ip->size)//检查读入终点是否越界
n = ip->size - off;//提供文件的有效数据
for(tot=0; tot<n; tot+=m, off+=m, dst+=m){//逐个盘块读入
bp = bread(ip->dev, bmap(ip, off/BSIZE));//读入
m = min(n - tot, BSIZE - off%BSIZE);//调整偏移量的增量
memmove(dst, bp->data + off%BSIZE, m);//写回磁盘
brelse(bp);
}
return n;
}
// PAGEBREAK!
// Write data to inode.
// Caller must hold ip->lock.
int
writei(struct inode *ip, char *src, uint off, uint n)
{
uint tot, m;
struct buf *bp;
if(ip->type == T_DEV){//如果是设备文件
if(ip->major < 0 || ip->major >= NDEV || !devsw[ip->major].write)
return -1;
return devsw[ip->major].write(ip, src, n);//使用设备自己的write函数
}
//磁盘文件读操作
if(off > ip->size || off + n < off)//检查起点是否越界
return -1;
if(off + n > MAXFILE*BSIZE)
return -1;
for(tot=0; tot<n; tot+=m, off+=m, src+=m){//遍历盘块
bp = bread(ip->dev, bmap(ip, off/BSIZE));//读入块缓存
m = min(n - tot, BSIZE - off%BSIZE);//调整偏移量增量
memmove(bp->data + off%BSIZE, src, m);//写入到块缓存
log_write(bp);//由日志系统写出
brelse(bp);
}
if(n > 0 && off > ip->size){//写入数据后,文件长度扩展了
ip->size = off;//修改文件长度
iupdate(ip);//更新磁盘inode
}
return n;
}
2.5.3 Directories(目录部分):
//PAGEBREAK!
// Directories
Int//比较目录名称
namecmp(const char *s, const char *t)
{
return strncmp(s, t, DIRSIZ);
}
// Look for a directory entry in a directory.
// If found, set *poff to byte offset of entry.
struct inode*
dirlookup(struct inode *dp, char *name, uint *poff)
{
uint off, inum;
struct dirent de;
if(dp->type != T_DIR) //此inode必须是目录
panic("dirlookup not DIR");
for(off = 0; off < dp->size; off += sizeof(de)){//逐个目录项处理
if(readi(dp, (char*)&de, off, sizeof(de)) != sizeof(de))//读入当前目录项
panic("dirlookup read");
if(de.inum == 0)//无效目录
continue;
if(namecmp(name, de.name) == 0){//找到名字匹配的目录项
// entry matches path element
if(poff)
*poff = off;//将目录项偏移值通过*poff返回
inum = de.inum;//确定索引结点号
return iget(dp->dev, inum);//建立inode缓存
}
}
return 0;
}
// Write a new directory entry (name, inum) into the directory dp.
int
dirlink(struct inode *dp, char *name, uint inum)
{
int off;
struct dirent de;
struct inode *ip;
// Check that name is not present.
if((ip = dirlookup(dp, name, 0)) != 0){//不能和同目录下其他文件重名
iput(ip);
return -1;
}
// Look for an empty dirent.
for(off = 0; off < dp->size; off += sizeof(de)){//找到一个空的目录项
if(readi(dp, (char*)&de, off, sizeof(de)) != sizeof(de))
panic("dirlink read");
if(de.inum == 0)
break;
}
strncpy(de.name, name, DIRSIZ);//目录项中写入文件名字字符串
de.inum = inum;//目录项中记录对应的inode
if(writei(dp, (char*)&de, off, sizeof(de)) != sizeof(de))//写出到磁盘
panic("dirlink");
return 0;
}
//PAGEBREAK!
// Paths
// Copy the next path element from path into name.
// Return a pointer to the element following the copied one.
// The returned path has no leading slashes,
// so the caller can check *path=='\0' to see if the name is the last one.
// If no name to remove, return 0.
//
// Examples:
// skipelem("a/bb/c", name) = "bb/c", setting name = "a"
// skipelem("///a//bb", name) = "bb", setting name = "a"
// skipelem("a", name) = "", setting name = "a"
// skipelem("", name) = skipelem("", name) = 0
//
static char*//解析路获得文件名,1:x/x/x/ 2:/x/x/x
skipelem(char *path, char *name)
{
char *s;
int len;
while(*path == '/')
path++;
if(*path == 0)
return 0;
s = path;
while(*path != '/' && *path != 0)
path++;
len = path - s;
if(len >= DIRSIZ)
memmove(name, s, DIRSIZ);
else {
memmove(name, s, len);
name[len] = 0;
}
while(*path == '/')
path++;
return path;
}
// Look up and return the inode for a path name.
// If parent != 0, return the inode for the parent and copy the final
// path element into name, which must have room for DIRSIZ bytes.
// Must be called inside a transaction since it calls iput().
//查找并返回路径名的inode。如果parent != 0,返回父节点的inode,并复制final路径元素到name中,必须有DIRSIZ字节的空间。必须在事务内部调用,因为它调用iput()。
static struct inode*
namex(char *path, int nameiparent, char *name)
{
struct inode *ip, *next;
if(*path == '/')//绝对路径
ip = iget(ROOTDEV, ROOTINO);//根目录
else
ip = idup(myproc()->cwd);//相对路径
while((path = skipelem(path, name)) != 0){//逐级目录处理
ilock(ip);
if(ip->type != T_DIR){//每一级都应该是目录
iunlockput(ip);
return 0;
}
if(nameiparent && *path == '\0'){//如果需要的是父目录,并且剩下的路径已经为空,则当前结点就是i结点直接返回
// Stop one level early.
iunlock(ip);
return ip;
}
if((next = dirlookup(ip, name, 0)) == 0){//此目录未查到,查询下一个目录
iunlockput(ip);
return 0;
}
iunlockput(ip);
ip = next;//获得next
}
if(nameiparent){
iput(ip);
return 0;
}
return ip;
}
struct inode*
namei(char *path)//返回当前目录inode
{
char name[DIRSIZ];
return namex(path, 0, name);
}
struct inode*
nameiparent(char *path, char *name)//返回父目录的inode
{
return namex(path, 1, name);
}
2.6 stat.h
文件系统中最核心的对象就是索引节点,虽然 inode 没有文件名(文件名是目录的功能),但它代表并管理着文件在磁盘上的数据。目录操作也是建立在素引节点的操作之上。用户进行文件读写操作时,使用的是文件逻辑偏移,而磁盘读写使用的是盘块号和盘块内偏移。即只有索引节点才真正知道数据存储在哪个盘块上,即知道文件的物理结构。
-
索引节点的操作分为两类:
-
对素引节点管理文件数据的读写;
-
对素引节点自身的分配、州除和修改。
-
索引节点有三种类型,通过成员 type可以表示普通文件、目录文件或设备文件。
-
// 声明文件或者目录属性数据结构
#define T_DIR 1 // 目录文件
#define T_FILE 2 // 普通文件
#define T_DEV 3 // 设备文件
struct stat {
short type; // 文件类型
int dev; // 文件系统磁盘设备
uint ino; // 索引结点
short nlink; // 链结点数
uint size; // 文件大小
};
2.7 file.h
文件file特指磁盘文件的一次动态打开,是动态概念。而索引节点 inode代表的磁盘文件则是静态概念。每一次打开的文件都是用file结构体)描述,主要记录该文件的类型,进程文件描述符引用的次数,是否可读、是否可写的方式打开等。其ip指向内存中的 inode(是磁盘 inode 在内存的动态存在),off用于记录当前读写位置,通常称作文件的游标。如果打开的是管道,则由 pipe 成员指向管道数据。
struct file {// 分为管道文件,设备文件,普通文件
enum { FD_NONE, FD_PIPE, FD_INODE } type;
int ref; //文件的引用数量
char readable;//表明是否可读
char writable;//是否可写
struct pipe *pipe;//pipe类
struct inode *ip; //inode类
uint off; //偏移量
};
// in-memory copy of an inode
struct inode {//i结点备份
uint dev; // 设备编号
uint inum; // Inode number//i结点的数量
int ref; // 引用数量
struct sleeplock lock; // sleepock,保护下面的一切
int valid; // inod是否从磁盘读取
short type; // 磁盘节点的副本
short major;//主盘
short minor;//从盘
short nlink;//链接数
uint size;//文件大小
uint addrs[NDIRECT+1];//实际存放的数据块号
};
// table mapping major device number to
// device functions
struct devsw {
int (*read)(struct inode*, char*, int);//读
int (*write)(struct inode*, char*, int);//写
};
extern struct devsw devsw[]; //devsw数组记录给出的读写操作函数,⽤设备号来索引
#define CONSOLE 1
2.8 file.c
file.c 涉及文件系统中关于file层面的操作,上接系统调用代码的接口层面的代码,向下衔接inode操作层面的操作代码。
// File descriptors
//
// 导包
#include "types.h"
#include "defs.h"
#include "param.h"
#include "fs.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "file.h"
struct devsw devsw[NDEV]; devsw数组记录给出的读写操作函数,用设备号来索引
struct {
struct spinlock lock;
struct file file[NFILE];
} ftable; //系统打开的文件列表
void
fileinit(void) //文件初始化
{
initlock(&ftable.lock, "ftable"); // 初始化锁
}
// Allocate a file structure. //分配文件结构。
struct file*
filealloc(void) //分配一个空闲的file文件
{
struct file *f;
acquire(&ftable.lock); // 获得锁
for(f = ftable.file; f < ftable.file + NFILE; f++){//遍历
if(f->ref == 0){ //如果该文件结构体的引用数为0则说明空闲可分配
f->ref = 1; // ref=1,新分配的,引用数为1(本身)
release(&ftable.lock); // 释放锁
return f; // 返回file指针
}
}
release(&ftable.lock); //释放锁
return 0; // 无空闲块,返回0
}
// Increment ref count for file f.
// 文件f的增量引用计数。当用于进程对某个文件描述符进行复制时,将引起对应的file对象引用次数增加1
struct file*
filedup(struct file *f)
{
acquire(&ftable.lock); // 获得锁
if(f->ref < 1) //文件没有引用
panic("filedup");
f->ref++; // 引用数+1
release(&ftable.lock); //释放锁
return f;
}
// Close file f. (Decrement ref count, close when reaches 0.) 关闭文件f.(减少ref计数,当达到0时关闭。)
void
fileclose(struct file *f) //文件的关闭
{
struct file ff;
acquire(&ftable.lock); // 获得锁
if(f->ref < 1) //无进程使用
panic("fileclose");
if(--f->ref > 0){ //如果ref--之后,任然大于0,则直接返回
release(&ftable.lock); //释放锁
return;
}
// ref=0了,inode的ref不一定为0,所以还需要iput(暂时不考虑inode之外的//情况
// 真正的关闭操作
ff = *f;
f->ref = 0; // 引用数置0
f->type = FD_NONE;
release(&ftable.lock);
if(ff.type == FD_PIPE) //判断文件的类型
pipeclose(ff.pipe, ff.writable); //PIPE管道,使用pipeclose()关闭
else if(ff.type == FD_INODE){ //其他类型
begin_op();
iput(ff.ip); //通过iput()释放相应的索引节点
end_op();
}
}
// Get metadata about file f.
int
filestat(struct file *f, struct stat *st) //读取文件的元数据
{
if(f->type == FD_INODE){
ilock(f->ip); //上锁
stati(f->ip, st); //使用stati函数将元数据管理信息填写到stat结构体
iunlock(f->ip); // 解锁
return 0;
}
return -1;
}
// Read from file f.
int
fileread(struct file *f, char *addr, int n) //通用的文件读操作函数
{
int r;
if(f->readable == 0) //判断是否可以读
return -1;
if(f->type == FD_PIPE) //如果文件类型为FD_PIPE
return piperead(f->pipe, addr, n); //使用piperead函数读取文件
if(f->type == FD_INODE){ //如果文件类型为FD_INODE
ilock(f->ip); //上锁
if((r = readi(f->ip, addr, f->off, n)) > 0) //使用readi函数,需要计算数据偏移
//所对应的磁盘盘块所在的位置
f->off += r; //调整偏移
iunlock(f->ip); //解锁
return r;
}
panic("fileread");
}
//PAGEBREAK!
// Write to file f.
int
filewrite(struct file *f, char *addr, int n) //通用的文件写操作函数
{
int r;
if(f->writable == 0) //判断是否可以写
return -1;
if(f->type == FD_PIPE) //若文件类型为FD_PIPE
return pipewrite(f->pipe, addr, n); //调用pipewrite()函数写
if(f->type == FD_INODE){
// write a few blocks at a time to avoid exceeding
// the maximum log transaction size, including
// i-node, indirect block, allocation blocks,
// and 2 blocks of slop for non-aligned writes.
// this really belongs lower down, since writei()
// might be writing a device like the console.
int max = ((MAXOPBLOCKS-1-1-2) / 2) * 512; //定义一次最多写入字节
// 为了防止写入的数据超过日志系统的上限
int i = 0;
while(i < n){ //循环多次写入
int n1 = n - i;
if(n1 > max) //每次写入不能超过max个字节
n1 = max;
begin_op(); //等待日志系统
ilock(f->ip); //上锁
if ((r = writei(f->ip, addr + i, f->off, n1)) > 0) //调用wirtei函数写入,
// 计算磁盘对应位置
f->off += r; //调整游标
iunlock(f->ip); //解锁
end_op(); //减少未完成事务,并按条件提交事务
if(r < 0)
break; //写入完成
if(r != n1) // 非最大值写入
panic("short filewrite");
i += r;
}
return i == n ? n : -1; //是否写完
}
panic("filewrite");
}
2.9 sysfile.c
| 名称 | 功能 |
|---|---|
sys_link() |
为已有的inode创建一个新的名字 |
sys_unlink() |
为已有的inode移除一个名字,可能会移除这个inode |
sys_open() |
打开一个指定的文件描述符 |
sys_mkdir() |
创建一个新目录 |
sys_mknod() |
创建一个新文件 |
sys_chdir() |
改变进程当前目录 |
sys_fstat() |
改变文件统计信息 |
sys_read() |
读文件描述符 |
sys_write() |
写文件描述符 |
sys_dup() |
增加文件描述符的引用 |
//定义与文件相关的系统调用
// File-system system calls.
// Mostly argument checking, since we don't trust
// user code, and calls into file.c and fs.c.
//
#include "types.h"
#include "defs.h"
#include "param.h"
#include "stat.h"
#include "mmu.h"
#include "proc.h"
#include "fs.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "file.h"
#include "fcntl.h"
// Fetch the nth word-sized system call argument as a file descriptor
// and return both the descriptor and the corresponding struct file.
static int
argfd(int n, int *pfd, struct file **pf)//根据参数位置获取参数文件描述符,再根据文件描述符获取文件指针
{
int fd;
struct file *f; // argxx 类底层都是调⽤的argraw,使⽤p->tf->ax,即使⽤寄存器传递参数
//xv6 的系统调用使用 INT 64 指令来实现的,触发一个 64 号中断陷入内核,根据向量号 64 去获取执行中断服务程序。在执行系统调用之前传入了系统调用号,在中断服务程序中根据系统调用号获取执行内核功能函数。
//执行内核功能函数需要取参数,xv6 系统调用的参数传递方法是压栈,压的是用户栈,所以要去用户栈去参数
if(argint(n, &fd) < 0)//从用户栈中获取第n个参数
return -1;
if(fd < 0 || fd >= NOFILE || (f=myproc()->ofile[fd]) == 0)//如果文件大小溢出或者为空
return -1;
if(pfd) // ⽤指针参数设置返回值,该fd和关联的⽂件
*pfd = fd;
if(pf)
*pf = f;
return 0;
}
// Allocate a file descriptor for the given file.
// Takes over file reference from caller on success.
static int
fdalloc(struct file *f)//获取本进程的一个空闲fd文件描述符
{
int fd;
struct proc *curproc = myproc();//当前进程控制块的地址
for(fd = 0; fd < NOFILE; fd++){//从前到后寻找空闲的文件描述符
if(curproc->ofile[fd] == 0){//如果该描述符对应的元素为0则空闲可分配
curproc->ofile[fd] = f;//将该文件描述符和传入的file关联起来,填写文件结构体地址
return fd;//返回文件描述符
}
}
return -1; //没有则返回 -1
}
int
sys_dup(void) //sys_dup将本进程中指定的⼀个⽂件扫描符复制⼀份
{
struct file *f;
int fd;
if(argfd(0, 0, &f) < 0)//根据参数文件描述获取文件指针
return -1;
if((fd=fdalloc(f)) < 0)/分配文件描述符,使分配的描述符指向文件结构体f
return -1;
filedup(f);//文件结构体引用数+1
return fd;//返回分配的文件描述符
}
Int
sys_read(void) //读
{
struct file *f;
int n;
char *p;
// 获取参数:⽂件,⽬的地址,读取字节数,并检查参数是否正确
if(argfd(0, 0, &f) < 0 || argint(2, &n) < 0 || argptr(1, &p, n) < 0)//同上,到用户栈中获取参数
return -1;
return fileread(f, p, n);//调用fileread进行真正的读取操作
}
int
sys_write(void) //写
{
struct file *f;
int n;
char *p;
// 获取参数:⽂件,源地址,写字节数,并检查参数是否正确
if(argfd(0, 0, &f) < 0 || argint(2, &n) < 0 || argptr(1, &p, n) < 0)//同上,到用户栈中获取参数
return -1;
return filewrite(f, p, n);///调用filewrite进行真正的写入操作
}
int
sys_close(void) //关闭
{
int fd;
struct file *f;
if(argfd(0, &fd, &f) < 0)//获取参数
return -1;
myproc()->ofile[fd] = 0;//清除文件描述符的内容
fileclose(f);//执行文件关闭操作
return 0;
}
int
sys_fstat(void) //获取文件基本信息
{
struct file *f;
struct stat *st;
if(argfd(0, 0, &f) < 0 || argptr(1, (void*)&st, sizeof(*st)) < 0)//获取参数并检查
return -1;
return filestat(f, st);//调用filestat填充stat结构体
}
// Create the path new as a link to the same inode as old.
int
sys_link(void)
{
char name[DIRSIZ], *new, *old; // 获取两个字符串参数:新路径,⽼路径;新路径作为⼀个连接指向⽼路径
struct inode *dp, *ip;
//获取参数文件名,link系统调用需要两个参数路径,这两个参数在执行系统调用之前被压到了用户栈,所以这里先得取到
if(argstr(0, &old) < 0 || argstr(1, &new) < 0)
return -1;
begin_op();
if((ip = namei(old)) == 0){//获取到old文件的inode,如果不存在返回
end_op();
return -1;
}
ilock(ip);//锁上inode,保证操作的原子性,使其数据有效
if(ip->type == T_DIR){//如果是目录
iunlockput(ip);//解锁
end_op();
return -1;
}
ip->nlink++;//old文件连接数+1
iupdate(ip);//更新inode,写到磁盘日志
iunlock(ip);
// 获取new path对应⽂件的⽂件夹的inode,将name设置为对应⽂件,即路径中的最后⼀个元素
if((dp = nameiparent(new, name)) == 0)//寻找新文件的父目录inode
goto bad;
ilock(dp);
//在父目录下填写new的名字,old的inode编号,两者链接在一起了使用同一个inode表同一个文件
if(dp->dev != ip->dev || dirlink(dp, name, ip->inum) < 0){
iunlockput(dp);
goto bad;
}
iunlockput(dp);//解锁
iput(ip);//减少计数
end_op();
return 0;
bad://中途出错
ilock(ip);//上锁
ip->nlink--;//因为前面nlink+1,出错需要还原
iupdate(ip);//更新
iunlockput(ip);//解锁
end_op();//日志结束
return -1;
}
// Is the directory dp empty except for "." and ".." ?
static int
isdirempty(struct inode *dp)//判断⽬录dp除“ .”和“ ..”外是否为空?
{
int off;
struct dirent de;
for(off=2*sizeof(de); off<dp->size; off+=sizeof(de)){//跳过.和..的目录
if(readi(dp, (char*)&de, off, sizeof(de)) != sizeof(de))
panic("isdirempty: readi");
if(de.inum != 0)
return 0;
}
return 1;
}
//PAGEBREAK!
int
sys_unlink(void) //删除⽬录项对索引节点的引⽤
{
struct inode *ip, *dp;
struct dirent de;
char name[DIRSIZ], *path;//文件名称路径
uint off;
if(argstr(0, &path) < 0)//待删除的文件名
return -1;
begin_op();//记录日志
// 获取该⽂件所在⽂件夹的inode,设置name为该⽂件的⽂件名path中最后⼀个元素
if((dp = nameiparent(path, name)) == 0){//dp记录文件的上一级目录
end_op();
return -1;
}
ilock(dp);
// Cannot unlink "." or "..".,unlink文件是.或者..
if(namecmp(name, ".") == 0 || namecmp(name, "..") == 0)
goto bad;
if((ip = dirlookup(dp, name, &off)) == 0)//在父目录中查找该文件
goto bad;
ilock(ip);
if(ip->nlink < 1)
panic("unlink: nlink < 1");
if(ip->type == T_DIR && !isdirempty(ip)){//不能对非空目录进行删除
iunlockput(ip);
goto bad;
}
memset(&de, 0, sizeof(de)); //在原来dirent的位置写⼀个空的dirent
if(writei(dp, (char*)&de, off, sizeof(de)) != sizeof(de)//)如果某个目录下有除开.和..目录项说明不为空,就不应该unlink
panic("unlink: writei");
if(ip->type == T_DIR){//如果要unlink目录文件
dp->nlink--;//链接数减一
iupdate(dp);//更新
}
iunlockput(dp);
ip->nlink--;//文件inode引用计数减一
iupdate(ip);
iunlockput(ip);//iput时如果发现ip-nlink==0,则会回收索引结点
end_op();
return 0;
bad://出错的情况
iunlockput(dp); //iput时如果发现ip-nlink==0,则会回收索引结点
end_op();
return -1;
}
static struct inode*
create(char *path, short type, short major, short minor)
{
struct inode *ip, *dp;
char name[DIRSIZ];
if((dp = nameiparent(path, name)) == 0)//完成路径和文件名的分离
return 0;
ilock(dp);
if((ip = dirlookup(dp, name, 0)) != 0){//在父目录中查找本文件名
iunlockput(dp);
ilock(ip);
if(type == T_FILE && ip->type == T_FILE)//如果类型是普通文件,找到则返回其inode
return ip;
iunlockput(ip);
return 0;
}
if((ip = ialloc(dp->dev, type)) == 0)//否则创建,分配一个inode
panic("create: ialloc");
ilock(ip);
ip->major = major;
ip->minor = minor;
ip->nlink = 1;//只有父目录下一个目录项指向该文件
iupdate(ip);
if(type == T_DIR){ // Create . and .. entries.//如果是创建目录文件,那么必须创建父目录和当前目录的目录项
dp->nlink++; // for ".."//关于父目录的目录项,父目录的链接加1
iupdate(dp);
// No ip->nlink++ for ".": avoid cyclic ref count.
if(dirlink(ip, ".", ip->inum) < 0 || dirlink(ip, "..", dp->inum) < 0)
panic("create dots");//每个目录内部都应该有两个默认目录项“.”和“..”
}
if(dirlink(dp, name, ip->inum) < 0)//在父目录下添加当前文件的目录项
panic("create: dirlink");
iunlockput(dp);
return ip;
}
int
sys_open(void) //打开⽂件通⽤函数
{
char *path;
int fd, omode;
struct file *f;
struct inode *ip;
if(argstr(0, &path) < 0 || argint(1, &omode) < 0)//获取参数路径和模式
return -1;
begin_op();
if(omode & O_CREATE){//如果是创建一个文件
ip = create(path, T_FILE, 0, 0);//初始化文件
if(ip == 0){
end_op();
return -1;
}
} else {//如果该文件存在
if((ip = namei(path)) == 0){//解析路径,获取文件inode
end_op(); //查询不到,直接返回
return -1;
}
ilock(ip);//上锁,(使得inode数据有效)
if(ip->type == T_DIR && omode != O_RDONLY){/如果文件类型是目录且打开方式不是只读
iunlockput(ip);
end_op();
return -1;
}
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){//分配一个文件结构体和文件描述符
if(f)
fileclose(f); //失败返回
iunlockput(ip);
end_op();
return -1;
}
iunlock(ip);
end_op();
//正常分配初始化文件结构体信息
f->type = FD_INODE;//可以使用inode方式操作文件
f->ip = ip;
f->off = 0;//偏移量初始为0
f->readable = !(omode & O_WRONLY);//根据omode参数设置读写权限
f->writable = (omode & O_WRONLY) || (omode & O_RDWR);
return fd;
}
int
sys_mkdir(void)//创建目录文件
{
char *path;
struct inode *ip;
begin_op();
if(argstr(0, &path) < 0 || (ip = create(path, T_DIR, 0, 0)) == 0){//获取参数路径,调用create创建目录,类型为T_DIR
end_op(); //有错直接返回
return -1;
}
iunlockput(ip);
end_op(); //创建完毕后返回
return 0;
}
int
sys_mknod(void)//创建设备文件
{
struct inode *ip;
char *path;
int major, minor;
begin_op();
if((argstr(0, &path)) < 0 ||//文件路径,主盘从盘
argint(1, &major) < 0 ||
argint(2, &minor) < 0 ||
(ip = create(path, T_DEV, major, minor)) == 0){
end_op();
return -1;
}
iunlockput(ip); //创建成功后返回
end_op();
return 0;
}
int
sys_chdir(void) // 改变进程的当前⽬录
{
char *path;
struct inode *ip;
struct proc *curproc = myproc(); // 获取当前进程
begin_op();
if(argstr(0, &path) < 0 || (ip = namei(path)) == 0){//获取参数路径,以及路径中最后一个文件的inode
end_op();
return -1;
}
ilock(ip);
if(ip->type != T_DIR){//如果类型不是目录文件
iunlockput(ip); //返回
end_op();
return -1;
}
iunlock(ip);
iput(curproc->cwd);//放下进程原路径的inode
end_op();
curproc->cwd = ip;//进程路径切换到当前新路径
return 0;
}
int
sys_exec(void) // 利⽤指定可执⾏⽂件更换当前进程的进程映像,需要和磁盘交互
{
char *path, *argv[MAXARG];
int i;
uint uargv, uarg;
if(argstr(0, &path) < 0 || argint(1, (int*)&uargv) < 0){//获取参数路径和首地址
return -1;
}
memset(argv, 0, sizeof(argv));//将argv指向的盘块清0
for(i=0;; i++){
if(i >= NELEM(argv))
return -1;
if(fetchint(uargv+4*i, (int*)&uarg) < 0) // uargv是参数数组的⾸地址,这⾥将参数⼀个个取出来放在uarg⾥
return -1;
if(uarg == 0){
argv[i] = 0;
break;
}
if(fetchstr(uarg, &argv[i]) < 0) // 为参数数组⾥的元素每个分配⼀个⻚,然后取到对应的参数字符串
return -1;
}
return exec(path, argv); // 调⽤ exec实现进程映像的替换重建
}
int
sys_pipe(void) // ⽤作输⼊和输出两个⽂件描述符。
{
int *fd;
struct file *rf, *wf;
int fd0, fd1;//管道的文件句柄
if(argptr(0, (void*)&fd, 2*sizeof(fd[0])) < 0)//用户栈取参数
return -1;
if(pipealloc(&rf, &wf) < 0)//分配管道
return -1;
fd0 = -1;//初始化为-1
if((fd0 = fdalloc(rf)) < 0 || (fd1 = fdalloc(wf)) < 0){/分配文件描述符
if(fd0 >= 0)//如果分配失败
myproc()->ofile[fd0] = 0;//回收文件描述符
fileclose(rf);//回收文件结构体
fileclose(wf);
return -1;
}
fd[0] = fd0;
fd[1] = fd1;
return 0;
}
2.10 log.c
上层文件系统在使用log层时,必须首先调用begin_op()函数。begin_op()函数会记录一个新的transaction信息。在使用完log层后,上层系统必须调用end_op()函数。只有当没有transaction在执行时,log才会执行真正的磁盘写入。真正的磁盘写入操作在commit()函数中,可以看到commit()函数只有在end_op()结束,log.outstanding==0时才会被调用(以及开机的时刻)。commit()函数会先调用write_log()函数将缓存里的磁盘块写到磁盘上的Log区域里,并将Log Header写入到磁盘区域。只有当磁盘里存在Log Header的区域数据更新了,这一次Log更新才算完成。在Log区域更新后,commit()函数调用install_trans()完成真正的磁盘写入步骤,在这之后调用write_head()函数清空当前的Log数据。
#include "types.h"
#include "defs.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "fs.h"
#include "buf.h"
// Simple logging that allows concurrent FS system calls.
//
// A log transaction contains the updates of multiple FS system
// calls. The logging system only commits when there are
// no FS system calls active. Thus there is never
// any reasoning required about whether a commit might
// write an uncommitted system call's updates to disk.
//
// A system call should call begin_op()/end_op() to mark
// its start and end. Usually begin_op() just increments
// the count of in-progress FS system calls and returns.
// But if it thinks the log is close to running out, it
// sleeps until the last outstanding end_op() commits.
//
// The log is a physical re-do log containing disk blocks.
// The on-disk log format:
// header block, containing block #s for block A, B, C, ...
// block A
// block B
// block C
// ...
// Log appends are synchronous.
// Contents of the header block, used for both the on-disk header block
// and to keep track in memory of logged block# before commit.
//允许并发FS系统调用的简单日志记录。
//
//一个日志事务包含多个FS系统的更新调用。日志系统仅在存在时提交没有FS系统调用active。因此从来没有关于提交是否可能的任何推理将未提交的系统调用的更新写入磁盘。
//
//系统调用应该调用begin_op()/end_op()来标记它的开始和结束。通常begin_op()只是递增/正在进行的FS系统调用和返回的次数。但是如果它认为日志快要用完,它会休眠直到最后一个未完成的end_op()提交。
//
//物理重做日志,包含磁盘块。
//磁盘日志格式:头区块,包含区块A, B, C,…
// block A
// block B
// block C
/ /……
//日志追加是同步的。
//报头块的内容,用于磁盘上的报头块
//和在提交之前在内存中跟踪记录的block。
struct logheader {//log区头区块,位于磁盘LOG区第一个BLOCK块上,记录保存在LOG区的block块的数目以及索引值
int n; // 表示⽇志数据区共由多少个数据块需要写回到真正的数据区
int block[LOGSIZE]; // 使⽤block[]最⼤可以记录30个⽇志,
};
struct log {
struct spinlock lock; //锁
int start;/ /log信息在磁盘上的位置(开始的block块的索引号)
int size;// log区的总的block块的数目。
int outstanding; // how many FS sys calls are executing./ 当前正在使用LOG机制的文件系统调用数目(目的是别超过了LOG系统总容量)
int committing; // in commit(), please wait./ /当前是不是正处于LOG的提交中,也就是正在写LOG进入磁盘呢
int dev;
struct logheader lh;// 磁盘logheader在内存中的一份映射
};
struct log log;
static void recover_from_log(void);//日志恢复
static void commit();//日志提交
Void//读磁盘上的超级块,载入log区的信息,包含大小、起始block、logheader信息
如果存在log缓存,说明发生过crash,进行数据恢复。
initlog(int dev) // 初始化log
{
if (sizeof(struct logheader) >= BSIZE)//区块头大小不能超过最大值,
panic("initlog: too big logheader");
struct superblock sb;//超级块
initlock(&log.lock, "log");//初始化日志的锁
readsb(dev, &sb);//读取超级块中的内容
log.start = sb.logstart;//第一个日志块块号
log.size = sb.nlog;//日志块的块数
log.dev = dev;//日志所在的设备
recover_from_log();//将数据从日志中恢复
}
// Copy committed blocks from log to their home location
static void
install_trans(void) // 将⽇志头表中记录的写盘事务重新执⾏⼀次
{
int tail;
//这里是直接使用的in-memory log header,没有先从磁盘上读log header,这个跟install_trans被调用的时机有关:总共两次,commit和recover_from_log;在前这种,in-memory log header中保存的是最新的内容,是需要将in-memory写回到磁盘上后一次,在调用install之前,已经调用了read_head,即将log header从磁盘块上读到log[dev].lh中
for (tail = 0; tail < log.lh.n; tail++) {
// log[dev].start+tail+1对应了log block
struct buf *lbuf = bread(log.dev, log.start+tail+1); // read log block,读取日志块,
// log[dev].lh.block[tail]对应了要写入的文件块磁盘块号
struct buf *dbuf = bread(log.dev, log.lh.block[tail]); // read dst//读取日志块中数据本身所在的磁盘块
memmove(dbuf->data, lbuf->data, BSIZE); // copy block to dst//将数据复制到目的地址
bwrite(dbuf); // write dst to disk//把缓存块中数据同步到磁盘
brelse(lbuf);//释放Lbuf和dbuf
brelse(dbuf);
}
}
// Read the log header from disk into the in-memory log header
static void
read_head(void) //从磁盘⽇志区读⼊⽇志信息
{
struct buf *buf = bread(log.dev, log.start);读出header所在的块
struct logheader *lh = (struct logheader *) (buf->data);//将buf->data转型为log header
int i;
log.lh.n = lh->n;
for (i = 0; i < log.lh.n; i++) { //从磁盘上的header对应的buffer读取log header
log.lh.block[i] = lh->block[i];
}
brelse(buf);//释放buf
}
// Write in-memory log header to disk.
// This is the true point at which the
// current transaction commits.
static void
write_head(void) // 将内存中的logheader信息写⼊磁盘的⽇志区的第⼀个盘块
{
struct buf *buf = bread(log.dev, log.start);//读出header所在的块
struct logheader *hb = (struct logheader *) (buf->data);//将buf->data转型为log header
int i;
hb->n = log.lh.n;
//将缓存的log header写入到磁盘上的header对应的buffer
for (i = 0; i < log.lh.n; i++) {
hb->block[i] = log.lh.block[i];
}
bwrite(buf);
brelse(buf);
}
static void
recover_from_log(void) // 恢复⽇志数据区数据到真正的数据区
{
read_head();//从磁盘的log区域读取日志
install_trans(); // if committed, copy from log to disk//如果日志已经提交,就把日志复制到磁盘区域
log.lh.n = 0;//写入完成,清除日志
write_head(); // 将⽇志清空,从⽽准备好⽂件系统初始的运⾏状态
}
// called at the start of each FS system call.
void
begin_op(void) 同步控制, begin_op的主要⼯作就是将log.outstanding加1
{
acquire(&log.lock);//尝试访问之前先获取相关锁
while(1){
if(log.committing){//检查有没有其他线程在执行commit操作
sleep(&log, &log.lock);//有就进入sleep状态
} else if(log.lh.n + (log.outstanding+1)*MAXOPBLOCKS > LOGSIZE){
//og.lh.n 代表当前已被占用的 logged blocks 的数量,MAXOPBLOCKS 代表一个系统调用能够记录的最大文件系统块数,LOGSIZE 就是日志的大小最大值。如果当前操作会使日志溢出就SLEEP等待别的内核线程commit后清空日志记录
sleep(&log, &log.lock);
} else {//如果满足commit相关条件就写入日志,释放锁
log.outstanding += 1;//文件系统调用数目+1
release(&log.lock);//释放锁
break;
}
}
}
// called at the end of each FS system call.
// commits if this was the last outstanding operation.
//表示系统调用结束,将outstranding减1.如果为0,表示当前没有文件系统调用在进行,则可以提交事务,设置commiting和do_commmit属性为1.如果不为0,则唤醒休眠在log上的进程。前面的begin_op()会因为日志空间可能不够休眠,在这儿被唤醒。
void
end_op(void) //同步控制
{
int do_commit = 0;
acquire(&log.lock);//获取日志锁
log.outstanding -= 1;//进程结束,文件系统调用减一
if(log.committing)//正在提交
panic("log.committing");
if(log.outstanding == 0){//如果没有正在执行的文件系统调用,进行提交
do_commit = 1;
log.committing = 1;
} else {
// begin_op() may be waiting for log space,
// and decrementing log.outstanding has decreased
// the amount of reserved space.
// begin_op()可能正在等待日志空间,和递减日志。拖欠金额减少预留空间的数量。
wakeup(&log);//唤醒因为日志空间不够而休眠的进程
}
release(&log.lock);//释放锁
if(do_commit){//如果可以进行事务提交
// call commit w/o holding locks, since not allowed
// to sleep with locks.
commit();//提交
acquire(&log.lock);
log.committing = 0;//提交完修改状态未没有处于提交状态
wakeup(&log);//此时日志空间重置,唤醒因为正在提交和空间不够而休眠的进程
release(&log.lock);
}
}
// Copy modified blocks from cache to log.
static void
write_log(void) //⽤于将数据从块缓存写⼊到磁盘的⽇志区
{
int tail;
for (tail = 0; tail < log.lh.n; tail++) {
// 下面这个+1,就是指的header,log block在log header之后
struct buf *to = bread(log.dev, log.start+tail+1); // log block 用bread读一个buffer,此时buffer已经有了磁盘上对应块的内容
struct buf *from = bread(log.dev, log.lh.block[tail]); // cache block
memmove(to->data, from->data, BSIZE);// 将真正数据区buffer cache中的数据复制到log数据区buffer cache中
bwrite(to); // 把日志写入磁盘
brelse(from);//释放缓存块
brelse(to);
}
}
static void
commit() //提交
{
if (log.lh.n > 0) { //处理数据块数>0
write_log(); //把log.lh.block中记录的块号对应块的内容存到磁盘中log数据块中(>=log.start+1)
write_head(); // 把刚才写入log的数据所在块的块号(即log.lh.block)写到磁盘中log header里(log.start)
install_trans(); // 获取数据进行转移
log.lh.n = 0;
write_head(); // 因为lh.n=0了,所以这里相当于清空了磁盘中log header
}
}
// Caller has modified b->data and is done with the buffer.
// Record the block number and pin in the cache with B_DIRTY.
// commit()/write_log() will do the disk write.
//
//调用者已经修改了b->data并完成了缓冲区的操作。
//用B_DIRTY在缓存中记录块号和引脚commit()/write_log()将执行磁盘写操作。
//
// log_write() replaces bwrite(); a typical use is:
// bp = bread(...)
// modify bp->data[]
// log_write(bp)
// brelse(bp)
Void
//修改log在内存中的缓存(即log数组),判断修改完的这个buffer是否已经记录在缓存里了,如果记录了,那么log absorbtion,不需要在缓存里新开一个位置(block数组)去记录它
如果没有记录,说明这个buffer的改动没有记录在log数组中,那么增加对其的记录
logheader.block就是记录那些改动过的buffer的块号
log_write(struct buf *b) //修改并将要写的buffer信息记录在内存中的log头部
{
int i;
if (log.lh.n >= LOGSIZE || log.lh.n >= log.size - 1)
panic("too big a transaction");
if (log.outstanding < 1)
panic("log_write outside of trans");
acquire(&log.lock);//获取相关日志的锁
for (i = 0; i < log.lh.n; i++) { // log_write⾸先检查在已有的log数据块中是否有和要写的buffer cache相同的数据块
if (log.lh.block[i] == b->blockno) // log absorbtion
break;
}
log.lh.block[i] = b->blockno;//记录buf对应的log block
if (i == log.lh.n) //如果是一个新的block被添加,增加其引用计数,避免被buf被回收
log.lh.n++;
b->flags |= B_DIRTY; // prevent eviction//保证在commit之前所有文件系统操作都在内存的日志中
release(&log.lock);//释放锁
}
2.11 pipe.c
管道可以看到双端队列,一头读,一头写,如下图所示:

在xv6系统中,使用一块内存缓存块实现管道机制:

#include "types.h"
#include "defs.h"
#include "param.h"
#include "mmu.h"
#include "proc.h"
#include "fs.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "file.h"
#define PIPESIZE 512
struct pipe {
struct spinlock lock;//锁
char data[PIPESIZE];//存放数据的内存区域
uint nread; // 已经读取的字节数
uint nwrite; // 已经写入的字节数
int readopen; // 是否可读
int writeopen; // 是否可写
};
Int//实现了pipe的创建,并将pipe关联到两个文件上f0, f1。如果创建成功,返回0;否则返回-1
pipealloc(struct file **f0, struct file **f1)
{
struct pipe *p;//指向管道文件
p = 0;//初始化管道文件
*f0 = *f1 = 0;//初始化两个文件结构体指针,其中f0指向读端文件结构体,f1指向写端
if((*f0 = filealloc()) == 0 || (*f1 = filealloc()) == 0)//分配两个文件结构体
goto bad;
if((p = (struct pipe*)kalloc()) == 0)//给管道分配内存
goto bad;
p->readopen = 1;//表示管道可读
p->writeopen = 1;//管道可写
p->nwrite = 0;//没有写入字节
p->nread = 0;//没有读字节
initlock(&p->lock, "pipe");//初始化管道锁
(*f0)->type = FD_PIPE;//文件类型是管道
(*f0)->readable = 1;//文件可读
(*f0)->writable = 0;//文件可写
(*f0)->pipe = p;//文件的管道指针
(*f1)->type = FD_PIPE;//文件类型为管道
(*f1)->readable = 0;//文件不可读
(*f1)->writable = 1;//文件可写
(*f1)->pipe = p;//该文件的管道指针
return 0;//表示正确
//PAGEBREAK: 20
bad://发生错误,释放掉已经分配的资源
if(p)
kfree((char*)p);//如果是P发生错误,释放掉分配给P的资源
if(*f0)
fileclose(*f0);//关闭f0
if(*f1)
fileclose(*f1);//关闭f1
return -1;
}
void
pipeclose(struct pipe *p, int writable) // 实现pipe的关闭处理
{
acquire(&p->lock);/// 获取管道锁,避免在关闭的同时进行读写操作
if(writable){/ 判断是否有未被读取的数据
p->writeopen = 0; // 如果存在,则唤醒pipe的读进程;否则唤醒写进程
wakeup(&p->nread);//唤醒读进程
} else {
p->readopen = 0;//关闭读端
wakeup(&p->nwrite);//唤醒写进程
}
/ /当pipe的读写都已结束时,释放资源;否则释放pipe锁
if(p->readopen == 0 && p->writeopen == 0){//写端和读端都关闭
release(&p->lock);//释放锁
kfree((char*)p);//释放分配给p的资源
} else
release(&p->lock);
}
//PAGEBREAK: 40
int
pipewrite(struct pipe *p, char *addr, int n) //管道的写操作
{
int i;//用来标记字节数
acquire(&p->lock);//获取管道锁
for(i = 0; i < n; i++){// 逐字节写入
while(p->nwrite == p->nread + PIPESIZE){ //DOC: pipewrite-full管道已经写满了需要读
/ /唤醒读进程,写进程进入睡眠,并返回-1
if(p->readopen == 0 || myproc()->killed){//读端被关闭或者进程被杀
release(&p->lock);//释放锁
return -1;//返回-1表示错误
}
wakeup(&p->nread);//唤醒读进程
sleep(&p->nwrite, &p->lock); //DOC: pipewrite-sleep//让写进程进入睡眠
}
p->data[p->nwrite++ % PIPESIZE] = addr[i];//数据放入缓存区
}
wakeup(&p->nread); //DOC: pipewrite-wakeup1//写完了之后唤醒读进程
release(&p->lock);//释放锁
return n;//返回写了多少字节
}
int
piperead(struct pipe *p, char *addr, int n) //读pipe
{
int i;
acquire(&p->lock);//获取管道锁
// 如果pipe已经读空,并且正在写入,则进入睡眠状态
while(p->nread == p->nwrite && p->writeopen){ //DOC: pipe-empty//说明管道为空,并且可写
if(myproc()->killed){//如果进程被杀
release(&p->lock);//释放锁
return -1;//表示错误
}
sleep(&p->nread, &p->lock); //DOC: piperead-sleep//让读进程进入休眠
}
for(i = 0; i < n; i++){ //DOC: piperead-copy//一直读数据
if(p->nread == p->nwrite)//表示数据已经读完,管道空了
break;
addr[i] = p->data[p->nread++ % PIPESIZE];//读操作。把数据写入缓存区
}
// 读取完毕,唤醒写进程
wakeup(&p->nwrite); //DOC: piperead-wakeup
release(&p->lock);//释放锁
return i;// 返回读取的字节长度
}
3 学习总结与展望
xv6中文件系统的代码量较大,在分析的过程中屡屡遇到难题,但在无数次返回查看文件系统架构,回顾先前已分析过的代码,联系前后调用代码,最终完成了对文件系统代码的分析,虽然过程坎坷艰难,但在完成任务后,回看分析的代码、加入的注释、在学习过程中所做的每一点努力,我倍感欣悦,成就感十足!通过对文件系统的分析,我对计算机的底层技术认知更进一步,我为我的进步而感到快乐!
在摸索学习的过程中,我深入理解了文件系统所解决的几大难题:
- 该文件系统需要磁盘上数据结构来表示目录树和文件,记录每个文件用于存储数据的块,以及磁盘上哪些区域是空闲的。
- 该文件系统必须支持崩溃恢复,也就是说,如果系统崩溃了(比如掉电了),文件系统必须保证在重启后仍能正常工作。问题在于一次系统崩溃可能打断一连串的更新操作,从而使得磁盘上的数据结构变得不一致(例如:有的块同时被标记为使用中和空闲)。
- 不同的进程可能同时操作文件系统,要保证这种并行不会破坏文件系统的正常工作。
- 访问磁盘比访问内存要慢几个数量级,所以文件系统必须要维护一个内存内的 cache 用于缓存常被访问的块。
也对xv6文件系统的七层也有了自己的认知:
-
Disk层读取和写入virtio硬盘上的块。
-
Buffer cache层将磁盘块缓存在内存中并同步对它们的访问,确保每次只有一个内核进程可以修改存储在任何特定块中的数据。
-
logging层允许更高层把对于多个块的更新包装成一次事务(transaction),并确保在遇到崩溃时自动保持这些块的一致性(即,所有块都已更新或无更新)。
-
Inode层提供单独的文件,每个文件表示为一个索引结点,其中包含唯一的索引号(i-number)和一些保存文件数据的块。
-
Directorie层将每个目录实现为一种特殊的索引结点,其内容是一系列目录项,每个目录项包含一个文件名和inode num。
-
Pathname层提供了分层路径名,如/usr/rtm/xv6/fs.c,并通过递归查找来解析它们。
-
File descriptor层使用文件系统接口抽象了许多Unix资源(例如,管道、设备、文件等),简化了应用程序员的工作。
从最初的系统架构到系统各子部分的划分,再到各子部分的细化,最后以代码实现,通过在课堂上老师的理论讲授,以及为代码加注释并梳理总结,我对xv6的认知更加清晰。
操作系统课程结束了,但在操作系统领域的学习还在继续,我会继续深入钻研分析xv6,紧跟老师步伐向前走!老师在课堂上所教授关于操作系统的知识,极大的夯实了我的专业基础,先前仅听说过操作系统,以及在之前的课程中有略微了解,但对其运行机制并不清楚。在老师的教授下,我对操作系统知识有了清楚的认识,老师对于xv6系统的讲授也很大程度上弥补了我对于操作系统相关知识的迷茫与疑惑。在后续的专业学习中,我会不断积累知识、提升自我、提高自身的专业素养和能力,争取在操作系统相关领域有所探索与提升!
❤️❤️❤️忙碌的敲代码也不要忘了浪漫鸭!
好久不见,亦断更了许久……
️ 今天也是许久☁️后的☀️
晴天,是如此的浪漫。
Today is a unique and romantic day!
✨ most reliable
永恒.

