Prometheus服务发现之kubernetes_sd_config
一、为什么要使用Prometheus服务发现
之前我们讲过通过配置prometheus-operator的CRD ServiceMonitor来达到K8S集群相关组件和微服务的监控的目的,可以在ServiceMonitor的配置文件中以手动方式通过match lable和想要监控的Service进行匹配(这里相当于是手动进行服务注册和服务发现的作用,也可以将这种模式称为静态服务发现),以此来完成对想要监控的服务和组件进行监控,但这种方式进行监控配置,只能手工一个一个的增加,如果在k8s集群规模较大的情况下,或者是集群后面又增加了节点或者组件信息,这种方式就会很麻烦也不现实,于是引出了今天的主题-Prometheus动态服务发现机制,下面来让我们了解一下Prometheus是如何动态实现服务发现的。
二、什么是Prometheus服务发现
从上面的介绍大家已经知道,prometheus获取数据源target的方式主要有两种模式,一种是静态配置,一种是动态服务发现配置,promethues的静态服务发现static_configs或者是ServiceMonitor 通过标签匹配Service:每当有一个新的目标实例需要监控,都需要手动修改配置文件配置目标target或者修改ServiceMonitor CRD配置文件.
那么面对现如今动不动就成百上千台节点的集群来说,静态服务发现这种纯手动配置很显然是不切实际的,然而现在的集群往往都有一个很重要的功能叫做服务发现,例如在现在常用的微服务SpringCloud架构的中,Eureka组件作为服务注册和发现的中心,在Kubernetes这类容器管理平台中,Kubernetes也具有服务发现的功能,它们都掌握并管理着所有的容器或者是服务的相关信息,于是Prometheus通过这个中间的代理人(服务发现和注册中心)来获取集群当中监控目标的信息,从而巧妙地实现了prometheus的动态服务发现。
三、Prometheus常用的集几种动态服务发现
prometheus目前支持的动态服务发现有很多种,常用的主要分为以下几种:
1. promethues基于k8s的服务发现kubernetes_sd_configs
2. promethues基于consul的服务发现consul_sd_config
3. promethues基于Eureka的服务发现eureka_sd_config
还有基于DNS等等的就不一一列举。
下面主要讲解promethues基于的k8s服务发现kubernetes_sd_configs
四、详解Prometheus服务发现之kubernetes_sd_configs
目前,在Kubernetes下,Prometheus 通过与 Kubernetes API 集成主要支持5种服务发现模式又叫角色role:Node、Service、Pod、Endpoints、Ingress。不同的服务发现模式适用于不同的场景,例如:node适用于与主机相关的监控资源,如节点中运行的Kubernetes 组件状态、节点上运行的容器状态等;service 和 ingress 适用于通过黑盒监控的场景,如对服务的可用性以及服务质量的监控;endpoints 和 pod 均可用于获取 Pod 实例的监控数据,如监控用户或者管理员部署的支持 Prometheus 的应用。
下面贴出在Prometheus官网对这五种role的详细说明:
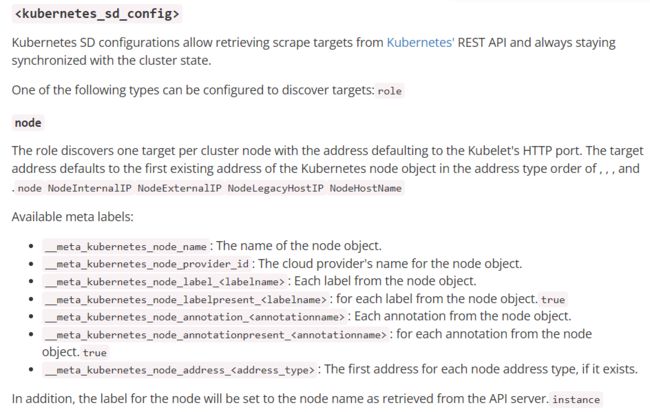
1. node
node角色可以发现集群中每个node节点的地址端口,默认为Kubelet的HTTP端口。目标地址默认为Kubernetes节点对象的第一个现有地址,地址类型顺序为NodeInternalIP、NodeExternalIP、NodeLegacyHostIP和NodeHostName。
作用:监控K8S的node节点的服务器相关的指标数据。
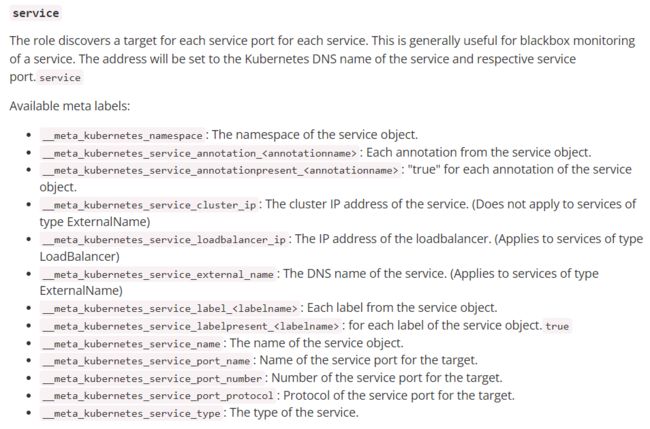
2. service
service角色可以发现每个service的ip和port,将其作为target。这对于黑盒监控(blackbox)很有用。
3. pod
pod角色可以发现所有pod并将其中的pod ip作为target。如果有多个端口或者多个容器,将生成多个target(例如:80,443这两个端口,pod ip为10.0.244.22,则将10.0.244.22:80,10.0.244.22:443分别作为抓取的target)。
如果容器没有指定的端口,则会为每个容器创建一个无端口target,以便通过relabel手动添加端口。

4. endpoints
endpoints角色可以从ep(endpoints)列表中发现所有targets。

- 如果ep是属于service的话,则会附加service角色的所有标签
- 对于ep的后端节点是pod,则会附加pod角色的所有标签(即上边介绍的pod角色可用标签)
比如我么手动创建一个ep,这个ep关联到一个pod,则prometheus的标签中会包含这个pod角色的所有标签
5. ingress
ingress角色发现ingress的每个路径的target。这通常对黑盒监控很有用。该地址将设置为ingress中指定的host。

Prometheus-additional.yaml配置文件规则详解
为解决服务发现的问题,kube-prometheus 为我们提供了一个额外的抓取配置来解决这个问题,我们可以通过添加额外的配置来进行服务发现进行自动监控。我们可以在 kube-prometheus 当中去自动发现并监控具有 prometheus.io/scrape=true 这个 annotations 的 Service。
其中通过 kubernetes_sd_configs 支持监控其各种资源。kubernetes SD 配置允许从 kubernetes REST API 接受搜集指标,且总是和集群保持同步状态,任何一种 role 类型都能够配置来发现我们想要的对象。
规则配置使用 yaml 格式,下面是文件中一级配置项。自动发现 k8s Metrics 接口是通过 scrape_configs 来实现的:
#全局配置
global:
#规则配置主要是配置报警规则
rule_files:
#抓取配置,主要配置抓取客户端相关
scrape_configs:
#报警配置
alerting:
#用于远程存储写配置
remote_write:
#用于远程读配置
remote_read:
举例说明:
# Kubernetes的API SERVER会暴露API服务,Promethues集成了对Kubernetes的自动发现,它有5种模式:Node、Service
# 、Pod、Endpoints、ingress,下面是Prometheus官方给出的对Kubernetes服务发现的实例。这里你会看到大量的relabel_configs,
# 其实你就是把所有的relabel_configs去掉一样可以对kubernetes做服务发现。relabel_configs仅仅是对采集过来的指标做二次处理,比如
# 要什么不要什么以及替换什么等等。而以__meta_开头的这些元数据标签都是实例中包含的,而relabel则是动态的修改、覆盖、添加删除这些标签
# 或者这些标签对应的值。而且以__开头的标签通常是系统内部使用的,因此这些标签不会被写入样本数据中,如果我们要收集这些东西那么则要进行
# relabel操作。当然reabel操作也不仅限于操作__开头的标签。
#
# action的行为:
# replace:默认行为,不配置action的话就采用这种行为,它会根据regex来去匹配source_labels标签上的值,并将并将匹配到的值写入target_label中
# labelmap:它会根据regex去匹配标签名称,并将匹配到的内容作为新标签的名称,其值作为新标签的值
# keep:仅收集匹配到regex的源标签,而会丢弃没有匹配到的所有标签,用于选择
# drop:丢弃匹配到regex的源标签,而会收集没有匹配到的所有标签,用于排除
# labeldrop:使用regex匹配标签,符合regex规则的标签将从target实例中移除,其实也就是不收集不保存
# labelkeep:使用regex匹配标签,仅收集符合regex规则的标签,不符合的不收集
global:
# 间隔时间
scrape_interval: 30s
# 超时时间
scrape_timeout: 10s
# 另一个独立的规则周期,对告警规则做定期计算
evaluation_interval: 30s
# 外部系统标签
external_labels:
prometheus: monitoring/k8s
prometheus_replica: prometheus-k8s-1
# 抓取服务端点,整个这个任务都是用来发现node-exporter和kube-state-metrics-service的,这里用的是endpoints角色,这是通过这两者的service来发现
# 的后端endpoints。另外需要说明的是如果满足采集条件,那么在service、POD中定义的labels也会被采集进去
scrape_configs:
# 定义job名称,是一个拉取单元
- job_name: "kubernetes-endpoints"
# 发现endpoints,它是从列出的服务端点发现目标,这个endpoints来自于Kubernetes中的service,每一个service都有对应的endpoints,这里是一个列表
# 可以是一个IP:PORT也可以是多个,这些IP:PORT就是service通过标签选择器选择的POD的IP和端口。所以endpoints角色就是用来发现server对应的pod的IP的
# kubernetes会有一个默认的service,通过找到这个service的endpoints就找到了api server的IP:PORT,那endpoints有很多,我怎么知道哪个是api server呢
# 这个就靠source_labels指定的标签名称了。
kubernetes_sd_configs:
# 角色为 endpoints
- role: endpoints
relabel_configs:
# 重新打标仅抓取到的具有 "prometheus.io/scrape: true" 的annotation的端点,意思是说如果某个service具有prometheus.io/scrape = true annotation声明则抓取
# annotation本身也是键值结构,所以这里的源标签设置为键,而regex设置值,当值匹配到regex设定的内容时则执行keep动作也就是保留,其余则丢弃.
# node-exporter这个POD的service里面就有一个叫做prometheus.io/scrape = true的annotations所以就找到了node-exporter这个POD
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
# 动作 删除 regex 与串联不匹配的目标 source_labels
action: keep
# 通过正式表达式匹配 true
regex: true
# 重新设置scheme
# 匹配源标签__meta_kubernetes_service_annotation_prometheus_io_scheme也就是prometheus.io/scheme annotation
# 如果源标签的值匹配到regex则把值替换为__scheme__对应的值
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
# 匹配来自 pod annotationname prometheus.io/path 字段
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
# 获取POD的 annotation 中定义的"prometheus.io/path: XXX"定义的值,这个值就是你的程序暴露符合prometheus规范的metrics的地址
# 如果你的metrics的地址不是 /metrics 的话,通过这个标签说,那么这里就会把这个值赋值给 __metrics_path__这个变量,因为prometheus
# 是通过这个变量获取路径然后进行拼接出来一个完整的URL,并通过这个URL来获取metrics值的,因为prometheus默认使用的就是 http(s)://X.X.X.X/metrics
# 这样一个路径来获取的。
action: replace
# 匹配目标指标路径
target_label: __metrics_path__
# 匹配全路径
regex: (.+)
# 匹配出 Pod ip地址和 Port
- source_labels:
[__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::d+)?;(d+)
replacement: $1:$2
# 下面主要是为了给样本添加额外信息
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
# 元标签 服务对象的名称空间
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
# service 对象的名称
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
# pod对象的名称
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
1、创建prometheus-additional.yaml配置文件
新增 prometheus 在 Kubernetes 下的自动服务发现 prometheus-additional.yaml
- job_name: 'dev-kubernetes-endpoints'
scrape_interval: 10s
scrape_timeout: 10s
metrics_path: (.*)/actuator/prometheus
scheme: http
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
kubernetes_sd_configs:
- role: pod
kubeconfig_file: ""
follow_redirects: true
namespaces:
names: []
2、创建Secret 对象
将上面文件直接保存为 prometheus-additional.yaml,然后通过这个文件创建一个对应的 Secret 对象:
$ kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
secret "additional-configs" created
3、创建资源对象
然后我们需要在声明 prometheus 的资源对象文件中通过 additionalScrapeConfigs 属性添加上这个额外的配置:
「prometheus-prometheus.yaml」:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.29.1
prometheus: k8s
name: k8s
namespace: monitoring
spec:
retention: 7d
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.29.1
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.29.1
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleNamespaceSelector: {}
ruleSelector: {}
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.29.1
additionalScrapeConfigs: #以下为新增的配置项
name: prometheus-additional-configs
key: prometheus-additional-config.yaml
添加完成后,直接更新 prometheus 这个 CRD 资源对象即可:
kubectl apply -f prometheus-prometheus.yaml
过一段时间,刷新 promethues 上的 config,将会查看配置已经生效。
自动发现规则配置好后如何让prometheus抓取pod内的metrics指标呢,抓取的路径端口等信息如何指定呢,这就要在應用deployments中的spec.template.metadata.annotations中指定了。配置如下:
annotations:
prometheus.io/path: /actuator/prometheus
prometheus.io/port: "7070"
prometheus.io/scheme: http
prometheus.io/scrape: "true"
定义好后prometheus即可抓取pod内的metrics指标数据了,在prometheus的targets页面即可看到job名称为 dev-kubernetes-endpoints 的target。
4、创建 RBAC 权限
我们切换到 targets 页面下面却并没有发现对应的监控任务,查看 Prometheus 的 Pod 日志,发现很多错误日志出现,都是 xxx is forbidden,这说明是 RBAC 权限的问题。
通过 prometheus 资源对象的配置可以知道 Prometheus 绑定了一个名为 prometheus-k8s 的 ServiceAccount 对象,而这个对象绑定的是一个名为 prometheus-k8s 的 ClusterRole:
创建 prometheus-clusterRole.yaml:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
上面的权限规则中我们可以看到明显没有对 Service 或者 Pod 的 list 权限,所以报错了,要解决这个问题,我们只需要添加上需要的权限即可:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.29.1
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
- /actuator/prometheus
verbs:
- get
更新上面的 ClusterRole 这个资源对象,然后重建下 Prometheus 的所有 Pod,正常就可以看到 targets 页面下面有 dev-kubernetes-endpoints 这个监控任务了。