Flume中 File Channel 的优化
Flume中 File Channel 的优化
文章目录
- Flume中 File Channel 的优化
-
- File Channel 的特点
- File Channel 的优化
-
- 索引
- 索引备份
- Flume官方优化设计
-
- 概述(Overview)
- 设计(Design)
- FileChannel的实现(Implementation)
- 总结(Conclusion)
- 参考

File Channel 的特点
- 速度较
Memory Channel慢 - 可靠性较
Memory Channel高
内存通道与文件通道对比
Memory Channel vs. File Channel
An important decision to make when designing your Flume flow is what type of channel you want to use. At the time of this writing, the two recommended channels are the file channel and the memory channel. The file channel is a durable channel, as it persists all events that are stored in it to disk. So, even if the Java virtual machine is killed, or the operating system crashes or reboots, events that were not successfully transferred to the next agent in the pipeline will still be there when the Flume agent is restarted. The memory channel is a volatile channel, as it buffers events in memory only: if the Java process dies, any events stored in the memory channel are lost. Naturally, the memory channel also exhibits very low put/take latencies compared to the file channel, even for a batch size of 1. Since the number of events that can be stored is limited by available RAM, its ability to buffer events in the case of temporary downstream failure is quite limited. The file channel, on the other hand, has far superior buffering capability due to utilizing cheap, abundant hard disk space.
在设计你的Flume流程时,一个重要的决定是你想使用什么类型的通道。在写这篇文章的时候,推荐的两个通道是文件通道和内存通道。File Channel 是一个持久的通道,因为它将所有存储在其中的事件持久化到磁盘上。因此,即使Java虚拟机被杀死,或者操作系统崩溃或重启,当Flume代理重新启动时,那些没有成功转移到管道中的下一个代理的事件仍然存在。内存通道是一个不稳定的通道,因为它只在内存中缓冲事件:如果Java进程死亡,存储在内存通道的任何事件都会丢失。当然,与文件通道相比,内存通道也表现出非常低的put/take延迟,即使批处理量为1。由于可以存储的事件数量受到可用RAM的限制,在下游临时故障的情况下,它缓冲事件的能力相当有限。另一方面,由于利用了廉价、丰富的硬盘空间,文件通道的缓冲能力要好得多。
File Channel 的优化
索引
File Channel 虽然慢,但有一个优化:索引
索引机制实现了从随机读写 到到达指定位置读写 的功能,读写在内存中,加速了查询。
索引备份
但是在内存中读写同样还是容易丢数据,所以产生了索引备份
但是,索引备份还是可能会丢数据,所以产生了二次索引备份
如果再次丢数据,集群本身有问题
Flume官方优化设计
概述(Overview)
MemoryChannel provides high throughput but loses data in the event of a crash or loss of power. As such the development of a persistent Channel was desired. FileChannel was implemented in FLUME-1085. The goal of FileChannel is to provide a reliable high throughput channel. FileChannel guarantees that when a transaction is committed, no data will be lost due to a subsequent crash or loss of power.
MemoryChannel提供高吞吐量,但在发生崩溃或断电时会丢失数据。因此,需要开发一个持久的channel。文件通道在FLUME-1085中实现。FileChannel的目标是提供可靠的高吞吐量通道。FileChannel保证在提交事务时,不会因后续崩溃或断电而丢失任何数据。
It’s important to note that FileChannel does not do any replication of data itself. As such, it is only as reliable as the underlying disks. Users who use FileChannel because of its durability should take this into account when purchasing and configuring hardware. The underlying disks should be RAID, SAN, or similar.
请务必注意,FileChannel本身不执行任何数据复制。因此,它仅与基础磁盘一样可靠。由于文件的持久性而使用FileChannel的用户在购买和配置硬件时应考虑到这一点。基础磁盘应为 RAID、SAN 或类似磁盘。
Many systems trade a small amount of data loss (fsync from memory to disk every few seconds for example) for higher throughput. The Flume team decided on a different approach with FileChannel. Flume is a transactional system and multiple events can be either Put or Taken in a single transaction. The batch size can be used to control throughput. Using large batch sizes, Flume can move data through a flow with no data loss and high throughput. The batch size is completely controlled by the client. This is an approach users of RDBMS’s will be familiar with.
许多系统会交换少量的数据丢失(例如,每隔几秒钟从内存到磁盘的 fsync)以获得更高的吞吐量。Flume 团队决定采用不同的方法使用文件通道。Flume是一个事务系统,多个事件可以在单个事务中放置或获取。批大小可用于控制吞吐量。使用大批量,Flume 可以在流中移动数据,而不会丢失数据并提高吞吐量。批大小完全由客户端控制。这是RDBMS的用户将熟悉的方法。
A Flume transaction consists of either Puts or Takes, but not both, and either a commit or a rollback. Each transaction implements both a Put and Take method. Sources do Puts onto the channel and Sinks do Takes from the channel.
Flume 事务由 Puts或Takes组成,但不能同时由两者组成,还包括提交或回滚。每个事务都实现一个 Put 和 Take 方法。Source通过Puts到channel上,Sink通过Takes从channel拿。
设计(Design)
FileChannel is based on a write ahead log or WAL in addition to an in-memory queue. Each transaction is written to the WAL based on the transaction type (Take or Put) and the queue is modified accordingly. Each time a transaction is committed, fsync is called on the appropriate file to ensure the data is actually on disk and a pointer to that event is placed on a queue. The queue serves just like any other queue: it manages what is yet to be consumed by the sink. During a take, a pointer is removed from the queue. The event is then read directly from the WAL. Due to the large amount of RAM available today, it’s very common for that read to occur from the operating system file cache.
FileChannel除了一个内存队列外,还基于一个提前写入的日志或WAL。每个事务都根据事务类型(取或放)被写入WAL,队列也相应地被修改。每次事务提交时,在适当的文件上调用fsync以确保数据确实在磁盘上,并将该事件的指针放在队列上。该队列的作用就像其他队列一样:它管理着尚未被水槽消耗的东西。在提取过程中,一个指针被从队列中移除。然后,事件被直接从WAL中读取。由于现在有大量的RAM,从操作系统的文件缓存中读取事件是很常见的。
After a crash, the WAL can be replayed to place the queue in the same state it was immediately preceding the crash such that no committed transactions are lost. Replaying WALs can be time consuming, so the queue itself is written to disk periodically. Writing the queue to disk is called a checkpoint. After a crash, the queue is loaded from disk and then only committed transactions after the queue was saved to disk are replayed, significantly reducing the amount of WAL, which must be read.
崩溃后,可以重放WAL,将队列置于崩溃前的相同状态,这样就不会丢失已提交的事务。重放WAL可能很耗时,所以队列本身会定期写到磁盘上。将队列写入磁盘被称为检查点。在崩溃之后,队列被从磁盘上加载,然后只有在队列被保存到磁盘之后的已提交事务被重放,大大减少了必须被读取的WAL的数量。
For example, a channel that has two events will look like this:
例如,一个有两个事件的通道将看起来像这样。

The WAL contains three important items: the transaction id, sequence number, and event data. Each transaction has a unique transaction id, and each event has a unique sequence number. The transaction id is used simply to group events into a transaction while the sequence number is used when replaying logs. In the above example, the transaction id is 1 and the sequence numbers are 1, 2, and 3.
WAL包含三个重要项目:交易ID、序列号和事件数据。每个交易都有一个唯一的交易ID,而每个事件都有一个唯一的序列号。事务ID只是用来将事件归入一个事务,而序列号则是在重放日志时使用。在上面的例子中,事务ID是1,序列号是1、2、3。
When the queue is saved to disk - a checkpoint - the sequence number is incremented and saved as well. At restart, first the queue from disk is loaded and then any WAL entries with a greater sequence number than the queue, are replayed. During the checkpoint operation the channel is locked so that no Put or Take operations can alter it’s state. Allowing modification of the queue during the checkpoint would result in an inconsistent snapshot of the queue stored on disk.
当队列被保存到磁盘时–一个检查点–序列号也被增加并保存。在重新启动时,首先从磁盘加载队列,然后重新播放任何具有比队列更大序列号的WAL条目。在检查点操作过程中,通道被锁定,因此没有放或取操作可以改变它的状态。在检查点期间允许修改队列会导致存储在磁盘上的队列的快照不一致。
In the example queue above, a checkpoint occurs after the commit of transaction 1 resulting in the queue being saved to disk with both events (“a” and “b”) and a sequence number of 4.
在上面的队列例子中,检查点发生在事务1的提交之后,导致队列以两个事件("a "和 “b”)和一个序列号4保存到磁盘上。
After that point, event a is Taken from the queue in transaction 2:
在那之后,事件a在事务2中被从队列中删除。
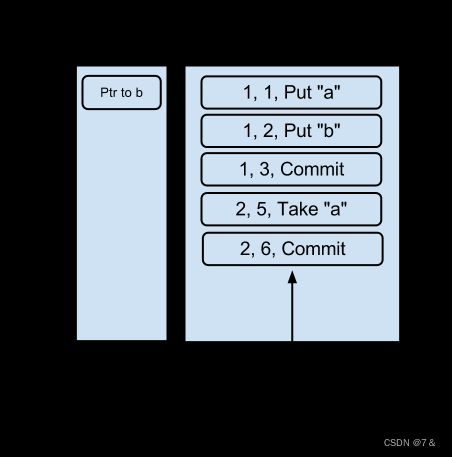
If a crash occurs, the queue checkpoint is read from disk. Note that since the checkpoint occurred before transaction 2, both events a and b currently exist on the queue. Then the WAL is read and any committed transaction with a sequence number greater than 4 is applied resulting in “a” being removed from the queue.
如果发生崩溃,队列的检查点就会从磁盘上读取。请注意,由于检查点发生在事务2之前,所以事件a和b目前都存在于队列中。然后,WAL被读取,任何序列号大于4的已提交事务被应用,导致 "a "被从队列中删除。
Two items are not covered by the design above. Takes and Puts which are in progress at the time the checkpoint occurs are lost. Assume the checkpoint occurred instead after the take of “a”:
上面的设计没有涵盖两个项目。在检查点发生时,正在进行的取和放都会丢失。假设检查点发生在 "a "的获取之后。
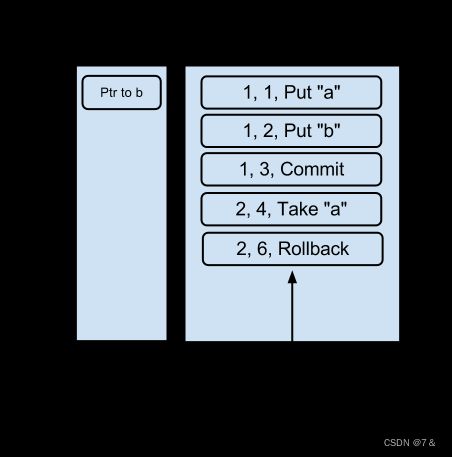
If a crash occurred at this point, under the design described above, event “b” would be on the queue and on replay any WAL entry with a sequence number greater than 5 would be replayed. The Rollback for transaction 2 would be replayed, but the Take for transaction 2 would not be replayed. As such, “a” would not be placed on the queue resulting in data loss. A similar scenario is played out for Puts. For this reason, when a queue checkpoint occurs, transactions which are still in progress are also written out so that this scenario can be handled appropriately.
如果在这一点上发生崩溃,根据上述设计,事件 "b "将在队列中,在重放时,任何序列号大于5的WAL条目将被重放。交易2的Rollback将被重放,但是交易2的Take将不会被重放。因此,"a "将不会被放在队列中,导致数据丢失。类似的情况也发生在Puts上。由于这个原因,当队列检查点发生时,仍在进行中的交易也会被写出来,这样就可以适当地处理这种情况。
FileChannel的实现(Implementation)
FileChannel is stored in the flume-file-channel module of the Flume project and it’s Java package name is org.apache.flume.channel.file. The queue described above is named FlumeEventQueue and the WAL is named Log. The queue itself is a circular array and is backed by a Memory Mapped File while the WAL is a set of files written and read from using the LogFile class and it’s subclasses.
FileChannel存储在Flume项目的flume-file-channel模块中,它的Java包名是org.apache.flume.channel.file。上面描述的队列被命名为FlumeEventQueue,WAL被命名为Log。队列本身是一个循环数组,由一个内存映射文件支持,而WAL是一组使用LogFile类及其子类写入和读取的文件。
总结(Conclusion)
FileChannel provides Flume users with durability in the face of hardware, software, and environmental failures while perserving high throughput. It is the recommended channel for most topologies where both aspects are important.
FileChannel为Flume用户提供了在面对硬件、软件和环境故障时的耐久性,同时保持了高吞吐量。对于这两方面都很重要的大多数拓扑结构「topologies」,它是推荐的通道。
参考
https://blogs.apache.org/flume/