Hadoop:Hive操作(二):数据表操作,复杂数据类型,Sampling采样,虚拟列
数据表操作
上接:
Hadoop:YARN、MapReduce、Hive操作_独憩的博客-CSDN博客
分桶表
分桶表创建
分区的作用可以把数据分成n个文件夹单独存放,而分桶表则可以把一个表的数据放在一个文件夹下,但是分成n个文件存放
分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。
分桶和分区可以一起使用: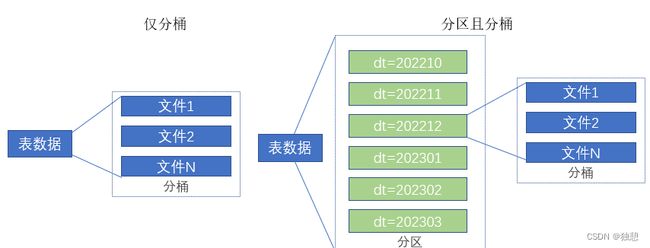
开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
set hive.enforce.bucketing=true;
创建分桶表
create table course (c_id string,c_name string,t_id string)
clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
这个地方在创建表的时候需要使用clustered by确定分桶的依据,然后使用into n buckets确定分成n个桶
数据的划分是根据 分桶依据值进行hash取模来决定的
分桶表数据加载
桶表的数据加载,由于桶表的数据加载通过load data无法执行,只能通过insert select,这是因为分桶的操作需要进行hash取模,也就是调用mapreduce,所有load data无法完成这个操作
1、创建一个临时表,向里面记载数据
create table temp_table(id int,name string)
row format delimited fields terminated by '\t';
load data local inpath '/export/server/hive/date/test1.txt' into table temp_table ;2、通过insert 向 分桶表传入数据
insert into fentong select * from temp_table cluster by (id)修改表操作
修改表的属性
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
如:ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL"="TRUE"); 修改内外部表属性
如:ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment); 修改表注释
其余属性可参见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties
添加分区
ALTER TABLE tablename ADD PARTITION (month='201101');
修改分区值
修改元数据记录,HDFS实体的文件夹不会改名字,只是在元数据记录中改名了
也就是说查看数据,分区值改变了,但是文件夹没有变化
ALTER TABLE tablename PARTITION (month='202005')
RENAME TO PARTITION (month='201105');
删除分区
也是只是在元数据记录中删除了,查看数据也发现这部分数据不见了
但是从文件的角度看,实体文件还在
ALTER TABLE tablename DROP PARTITION (month='201105');
其他的可以参照
MySQL基础(三)增删改查、数据类型、约束_独憩的博客-CSDN博客
数据类型array数组
在hive中也可以设置array类型的数据
首先准备一分数据文件:
1 changsha,shanghai,beijin,hangzhou
2 guangzhou,shenzhen,xiamen然后创建一个表,这个表里面有一列定义为array,使用collection items terminated by ','方法定义以 , 为分隔符,定义方法为:
create table array_test (id int,locations array)
row format delimited fields terminated by '\t'
collection items terminated by ','
然后把数据load就行了

这里数组的调用跟其他语音是一样的
select id,locations[0] from array_test也可以在where中运用,比如要查询loactions里面有changsha的人,需要用到特点函数:
select id,locations
from array_test
where array_contains(locations,'changsha')或者查询数组大小:
select id,size(locations) from array_test数据类型map映射
准备数据:
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guanyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
构建map列
create table map_test(id int,name string,
member map,
age int)
row format delimited fields terminated by ','
collection items terminated by '#'
map keys terminated by ':' collection items terminated by '#' 每个键值对的分隔符
map keys terminated by ':' 键与值的分隔符

键值对的调用也是跟其他语言差不多的
select name,member['father']
from map_test调取全部的key和value
select map_keys(member),map_values(member)
from map_test数据类型struct结构体
准备数据
1#周杰轮:11
2#林均杰:16
3#刘德滑:21
4#张学油:26
5#蔡依临:23
创建struct:
create table struct_test(
id int,
info struct
)
row format delimited fields terminated by '#'
collection items terminated by ':' 
可以使用info.name查询
select info.name from struct_testSampling采样
可以快速从大量数据中随机抽样一些数据显示,进行随机抽样,本质上就是用TABLESAMPLE函数
1、基于随机分桶抽样
SELECT ... FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(colname | rand()))
• y 表示将表数据随机划分成 y 份( y 个桶)• x 表示从 y 里面随机抽取 x 份数据作为取样• colname 表示随机的依据基于某个列的值• rand() 表示随机的依据基于整行
2、基于数据块抽样
这个就是按照顺序取,不存在随机性
SELECT ... FROM tbl TABLESAMPLE(num ROWS | num PERCENT | num(K|M|G));
• num ROWS 表示抽样 num 条数据• num PERCENT 表示抽样 num 百分百比例的数据• num(K|M|G) 表示抽取 num 大小的数据,单位可以是 K 、 M 、 G 表示 KB 、 MB 、 GB
Virtual Columns虚拟列
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
Hive目前可用3个虚拟列:
• INPUT__FILE__NAME,显示数据行所在的具体文件• BLOCK__OFFSET__INSIDE__FILE,显示数据行所在文件的偏移量• ROW__OFFSET__INSIDE__BLOCK,显示数据所在 HDFS 块的偏移量• 此 虚拟列 需要设置: SET hive.exec.rowoffset=true 才可使用
