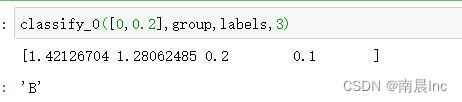
机器学习实战KNN部分代码改写
首先创建测试样例
def createData():
group = array([[1.1,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels原书核心代码
def classify(inX,dataset,labels,k):
datasetsize = dataset.shape[0]
diffmat = tile(inX,(datasetsize,1)) - dataset
#print(diffmat)
sqdiffmat = diffmat**2
#print(sqdiffmat)
sqdistance = sqdiffmat.sum(axis=1)
distances = sqdistance ** 0.5
sorteddist = distances.argsort()
classcount = {}
for i in range(k):
votelabels = labels[sorteddist[i]]
#print(votelabels)
classcount[votelabels] = classcount.get(votelabels,0) + 1
#print(classcount)
sorteddist = sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
return sorteddist[0][0]原函数中使用的大量的numpy方法,本文将用一些较为基础的代码对其中的方法进行简单的改写
一.tile方法改写
tile方法用于重复扩充行列


将其改写为如下(需要控制输入格式,a为矩阵,*args为两个元素的元组):
def tile1(a,*args):
new_a = a
x= args[0][0]
y = args[0][1]
for i in range(y-1):
for j in range(len(a)):
new_a.append(a[j])
new_new = []
for c in range(x):
new_new.append(new_a)
return new_new二.改写array.sum(axis=1)
array.sum用于将矩阵的每一行值相加
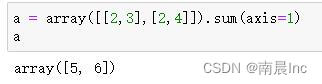
将其改写为
def add_mat(a):
mat = []
for i in range(len(a)):
sum = 0
for j in range(len(a[0])):
sum = sum + a[i][j]
mat.append(sum)
mat = array(mat)
return mat 三.改写numpy.argsort
array.argsort是先排序(默认从小到大),而后返回排序后个元素在原数组的索引
将其改写为
def sorted_1(distances):
sorted_list = []
for i in range(len(distances)):
sort_list = []
sort_list.append(distances[i])
sort_list.append(i)
sorted_list.append(sort_list)
#print(sorted_list)
for i in range(len(sorted_list)):
for i in range(0,len(sorted_list)-i-1):
if(sorted_list[i][0] > sorted_list[i+1][0]):
sorted_list[i],sorted_list[i+1] = sorted_list[i+1],sorted_list[i]
new_list = []
for i in range(len(sorted_list)):
new_list.append(sorted_list[i][1])
new_list = array(new_list)
return new_list四.改写sorted函数
sorted() 作为内置函数之一,其功能是对序列(列表、元组、字典、集合、还包括字符串)进行排序

将其改写为
def sorted_dict(dict_1):
dict_to_list = []
#先将其改写为列表
for key in dict_1:
dict_list = []
dict_list.append(key)
dict_list.append(dict_1[key])
dict_to_list.append(dict_list)
#再对列表进行排序
for i in range(len(dict_to_list)):
for i in range(0,len(dict_to_list)-i-1):
if(dict_to_list[i][0] < dict_to_list[i+1][0]):
dict_to_list[i],dict_to_list[i+1] = dict_to_list[i+1],dict_to_list[i]
return dict_to_list主函数
def classify_0(x,dataset,labels,k):
datasetsize = dataset.shape[0]
diffmat = tile1(x,(datasetsize,1)) - dataset
#print(diffmat)
sqdiffmat = diffmat**2
#print(sqdiffmat)
sqdistance = add_mat(sqdiffmat)
distances = sqdistance ** 0.5
print(distances)
sorteddist = sorted_1(distances)
#print(sorteddist)
#定义字典存储A类和B类的数量
classcount = {}
for i in range(k):
votelabels = labels[sorteddist[i]]
#print(votelabels)
classcount[votelabels] = classcount.get(votelabels,0) + 1
#print(classcount)
sorteddist = sorted_dict(classcount)
return sorteddist[0][0]输出结果为: