Conformer ASR详解
Conformer: Convolution-augmented Transformer for Speech Recognition
论文地址:https://arxiv.org/abs/2005.08100
Conformer编码器
Conformer编码器的结构如下图左侧所示,其中每个Conformer块包含四个模块:分别是前馈模块,多头自注意力模块、卷积模块和另一个前馈模块。与右侧的Transformer编码器的结构相比,Conformer块的改变主要体现在两处:1.增加了卷积模块;2.将前馈模块分成了两半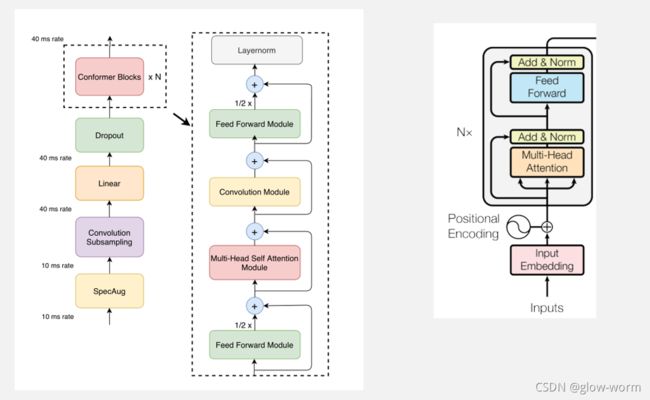
Multi-Headed Self-Attention Module
1.多头注意力结合了Transformer-XL中的相对位置编码
2.使用了带有dropout的pre-norm残差单元,有助于训练和正则化更深层次的模型

相对位置编码
参考
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
论文地址:https://arxiv.org/abs/1901.02860
在标准的Transformer中,序列的顺序信息由一组位置编码提供,表示为 U ∈ R L m a x × d U \in R^{L_{max}} \times d U∈RLmax×d ,其中第i行 U i U_i Ui 对应segment内的第 i 个绝对位置, L m a x L_{max} Lmax规定了要建模的最大长度。Transformer的实际输入是词嵌入和位置编码的加和。
同一个segment内的query向量 q i q_i qi和key向量 k j k_j kj之间的注意力分数可以表示为:
( E x i + U i ) W q T W k ( E x j + U j ) (E_{x_i} +U_i) W^T_q W_k (E_{x_j}+U_j) (Exi+Ui)WqTWk(Exj+Uj)
分解后:
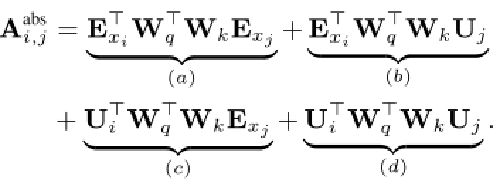
而利用Transformer-XL中的相对位置编码得到的注意力分数为:

这当中作了三处调整:
1.用相对位置编码 R i − j R_{i-j} Ri−j替换b项和d项中的绝对位置编码 U j U_j Uj,其中 i 表示query向量的位置,j 表示key向量的位置。
2.用可训练的参数 u 和 v 替换 c 项和d项中的 U i W q T U_i W^T_q UiWqT ,由于所有query位置的查询向量都是相同的,无论query的位置如何,注意力影响都是一致的,因此可以忽略query的位置。
3.将两个权重矩阵 W k , E W_{k,E} Wk,E和 W k , R W_{k,R} Wk,R分开,以分别产生基于内容的key向量和基于位置的key向量。
R采用正弦函数生成,不是通过学习得到的。好处是在预测时可以使用比训练更长距离的位置向量。相对位置编码使自注意力模块对不同的输入长度有更好的泛化,得到的编码器对语音长度的变化有更好的鲁棒性。
pre-norm
参考
Learning Deep Transformer Models for Machine Translation
论文地址:https://arxiv.org/abs/1906.01787
为了加深Transformer编码器,研究layer normalization的位置对深层Transformer的影响。在Transformer中,子层的叠加会阻碍信息在网络中的有效流动,可能导致训练失败。residual connections和layer norm用来解决这一问题。layer norm用来降低子层输出的方差,加快收敛。
残差单元可以定义为:
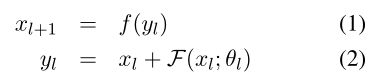
其中, x l x_l xl和 x l + 1 x_{l+1} xl+1表示子层的输入和输出,y_l是中间输出,f()是后处理函数。
在残差连接中引入layer norm有两种方法:
Post-Norm : ------Transformer
Pre-Norm: --在每个子层的输入上
在基于6层编码器的系统上性能相当,但在层数更多时情况大不相同。
Convolution Module

Pointwise Conv & Depthwise Conv——主要目的是用来降低参数量和计算量

将常规卷积拆成两步:
depthwise 只改变feature map的大小,不改变通道数。
pointwise只改变通道数,不改变feature map大小。
depthwise卷积:一个卷积核只负责一个通道,一个通道只被一个卷积核卷积,特征图的数量与输入通道数相同,但是没有利用不同通道在相同空间的位置信息。
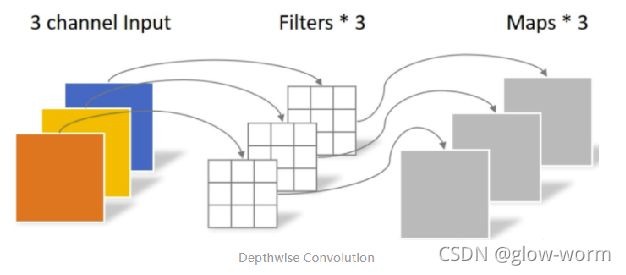
pointwise 卷积:卷积核的尺寸为11输入通道数,相当在深度方向上加权求和,可以指定输出通道数。

GLU 激活
参考
Language Modeling with Gated Convolutional Networks——论文地址:https://arxiv.org/abs/1612.08083v3
门控机制控制信息在网络中的流动,在LSTM中由输入门、遗忘门和输出门,它通过输入门和遗忘门来控制的CELL实现长期记忆,使得信息即使通过很多时间步也能畅通的流动,否则,信息很容易在经过较长时间步后消失。CNN不会有这种梯度消失,所以这里只设置了一个输出门。

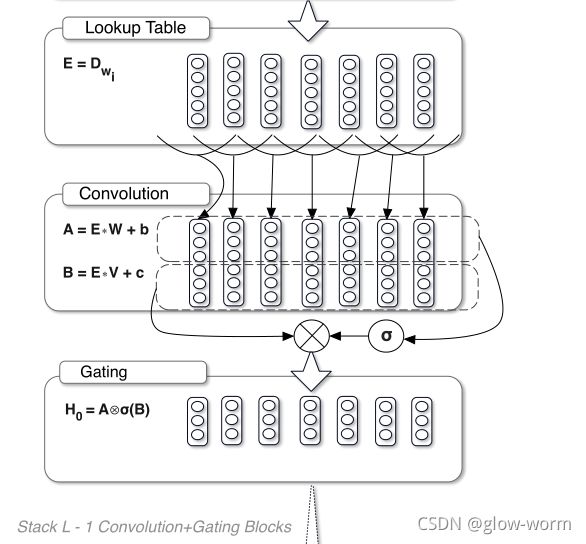
SWISH 激活函数:
参考
SWISH: A SELF-GATED ACTIVATION FUNCTION
论文地址:https://arxiv.org/pdf/1710.05941v1.pdf
SEARCHING FOR ACTIVATION FUNCTIONS
https://arxiv.org/pdf/1710.05941.pdf
Swish:f(x) = x · sigmoid(x)
在许多数据集上的实验表明,Swish在更深的模型上往往比ReLU工作得更好。
ReLU:f(x) = max(x,0)
与ReLU相同的是,Swish是无上界、有下界的。
与ReLU不同的是,Swish是平滑的且非单调的。
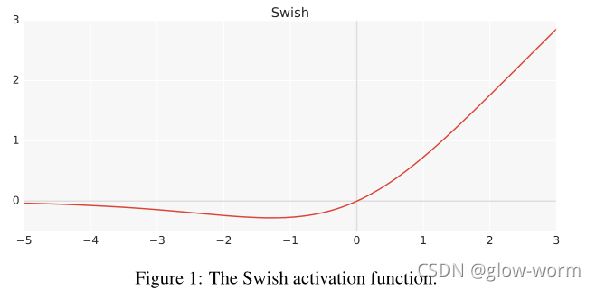
带参数的SWISH函数:
Swish:f(x) = x · sigmoid(βx)
β=0,
β→∞, Swish变得像ReLU函数。
这表明Swish可以被视为一个平滑函数,在线性函数和ReLU函数之间进行非线性插值。将β设置为可训练参数,模型可以控制插值的程度。
Feed Forward Module

Conformer Block
Conformer块包含两个Feed Forward模块,夹着Multi-Headed Self-Attention模块和Convolution模块。
这种三明治结构的灵感来自于Macaron-Net,它提出将Transformer块中原有的feed-forward层替换为两个半步feed-forward层,一个在attention层之前,一个在attention层之后。对Conformer块 i 输入xi,输出yi为:


实验
通过对网络深度、模型维度、注意力头数量的不同组合进行梳理,并在模型参数大小约束下选择性能最佳模型,确定了小、中、大三种模型,分别具有10M、30M和118M的参数。
在所有的模型中都使用一个单独的LSTM层解码器。


Conformer Block vs. Transformer Block
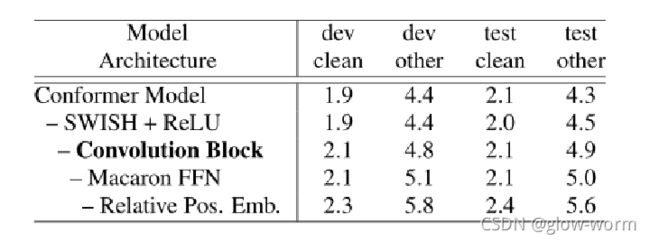
Combinations of Convolution and Transformer Modules
