0、前言:
- 这部分内容是对Pandas的回顾,同时也是对Pandas处理异常数据的一些技巧的总结,不一定全面,只是自己在数据处理当中遇到的问题进行的总结。
1、当数据中有重复行的时候需要检测重复行:
- 方法:使用pandas中的duplicated方法,在该方法中有两个参数subset和keep,subset需要提供一个列表,列表中每个元素是一个列名,keep有三个可选项(‘first’,‘last’,False)
- 示例
import pandas as pd
data = {'A': [6, 2, 3, 4, 6], 'B': [11, 10, 9, 10, 11]}
df = pd.DataFrame(data)
display(df)
duplicates = df.duplicated(subset=['A'])
print(duplicates)
print('='*30)
duplicates = df.duplicated(subset=['A'],keep=False)
print(duplicates)
print('='*30)
duplicates = df.duplicated(subset=['A'],keep="first")
print(duplicates)
print('='*30)
duplicates = df.duplicated(subset=['A'],keep='last')
print(duplicates)
print('='*30)
duplicates = df.duplicated(subset=['A','B'])
print(duplicates)
print('='*30)

2、删除重复行:
- 方法用pandas中的duplicated方法加loc索引即可
- 注意:删除重复列就没有比较快捷的方法了,就需要一一比较然后用drop方法删除对应列
data = [[1,2,3,4],[5,6,7,8],[1,2,3,4]]
df = pd.DataFrame(data,columns=list('ABCD'),index=[1,2,3])
display(df)
re = df.duplicated(subset=['A','B','C','D'],keep='first')
display(~re)
df_new = df.loc[~re].copy()
display(df_new)

3、需要替换DataFrame元素中的值:核心思想就是映射,借助python中的字典。
- 替换中主要用到的思路就是映射,映射的含义是创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定,从其含义就可以看出和python中的字典非常像。
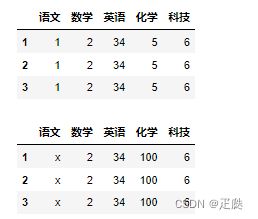
- 方法1:使用replace,特点是可以替换整个DataFrame中的值
df = DataFrame(
data=[[1,2,34,5,6],[1,2,34,5,6],[1,2,34,5,6]],
index=[1,2,3],
columns=['语文','数学','英语','化学','科技']
)
display(df)
a = df.replace({1:'x',5:100}).copy()
display(a)
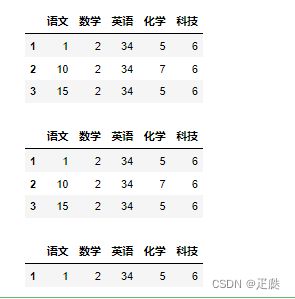
- 方法2:使用map,主要针对DataFrame中的列进行处理,其特点有3,第一可以通过已有列生成一个新列,第二适合处理某一个单独列,第三map函数中可以使用lambda函数或者自定义函数。但有个前提就是map中要处理哪一列,就要给列中所有元素给出对应的映射,不能有的给了,有的没给,没给的会修改为NaN值
df = DataFrame(
data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],
index=[1,2,3],
columns=['语文','数学','英语','化学','科技']
)
display(df)
df['化学改'] = df.loc[:,'化学'].map({5:50,7:90})
display(df)
df['语文改'] = df.loc[:,'语文'].map({1:10,15:10})
display(df)
df['语文2改'] = df.loc[:,'语文'].map({1:10,15:10,10:10})
display(df)
def n(x):
if x > 60:
return '及格'
else:
return "不及格"
df['数学判断'] = df.loc[:,'数学'].map(n)
display(df)
df['化学判断'] = df.loc[:,'化学改'].map(lambda x: '合格' if x>60 else '不合格')
display(df)

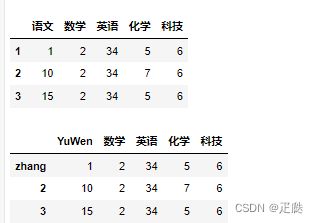
- 方法3:使用rename方法替换DataFrame中的行索引和列索引
df = DataFrame(
data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],
index=[1,2,3],
columns=['语文','数学','英语','化学','科技']
)
display(df)
df1 = df.rename(index={1:'zhang'},columns={'语文':'YuWen'}).copy()
display(df1)
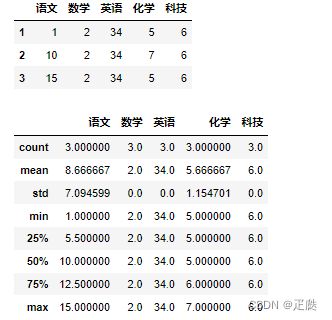
4、异常值筛选:
- 使用describe()函数查看每一列的描述性统计量
df = DataFrame(
data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],
index=[1,2,3],
columns=['语文','数学','英语','化学','科技']
)
display(df)
df.describe()
- 使用std()函数可以求得DataFrame对象每一列的标准差(较为简单不做示例)
- 异常值筛选思路:先确定异常值,然后通过条件判断获取异常值
df = DataFrame(
data={'height': np.random.randint(120,260,size=5),
'weight': np.random.randint(40,150,size=5)
}
)
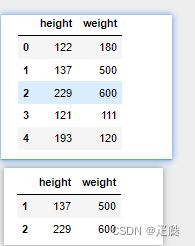
df.loc[:,'weight']=[180,500,600,111,120]
display(df)
pro = df.loc[:,'weight']>180
display(df.loc[:'weight'][pro])
- unique() 方法,可以对某一列或一行数据去重(较为简单不做示例)
- df.query : 按条件查询,可以在DataFrame中以字符串的形式编写表达式来选择或过滤特定的行和列。
df = DataFrame(
data=[[1,2,34,5,6],[10,2,34,7,6],[15,2,34,5,6]],
index=[1,2,3],
columns=['语文','数学','英语','化学','科技']
)
display(df)
a = df.query("数学==2").copy()
display(a)
b = df.query("化学==5 and 语文==1").copy()
display(b)