How to get a good embedding?
Word Embedding 选择 和 比较
在做自然语言处理过程中,常常会与word embedding接触,特别是深度学习近几年蓬勃发展。
但是,在使用word embedding时,我们会面临如下两个问题:
1.选择怎样的模型来训练word embedding?
2.如何判定训练出来的word embedding的好坏?
在正式回答,解决以上两个问题之前,我先对word embedding的由来进行简单的介绍
1.word embedding 介绍
中文:词向量,词嵌入。后面统称为词向量
word embedding技术就是将自然语言 处理成 机器能够识别的实数集(向量)。
word embedding就是一种分布式词表征技术,将自然语言处理成向量,同时,能保留原词的语法和句法上的信息。
训练词向量需要一定数量的为标记的语料。
2.Model选择
在构建语言模型时,我们都是基于同一个假设:不同词语在相似上下文中具有相似的语义。
基于这一假设,不同的模型就在如何向量化w(目标词)和c(上下文)的关系上大做文章。
2.1 One-hot encoding
传统的编码方式就是通过基于词袋的one-hot编码,根据词表的大小N,对每个词进行固定维度为N的编码,每个词只有1个非零的维度。
例如:i love deep learning ,词表为4,则对learning的编码为{0,0,0,1},向量的维度为词表的大小。
2.2 word2Vec中CROW模型和Skip-gram模型
2.2.1 CROW(Continuous Bag-of-words)
通过目标词上下文预测目标词
2.2.2 Skip-gram
通过目标词预测目标词的上下文
大家如相对原理进行了解参考https://blog.csdn.net/qq_39832864/article/details/88549643
2.3 Order
Order模型通过将将目标词的前n个词的词向量作为输入,输出
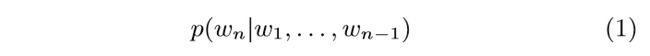
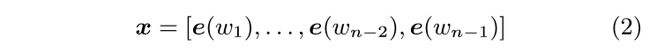
以此预测目标词
2.4 LBL
LBL模型类似于NNLM模型,NNLM的隐层为tanh函数,LBL使用的是对数双线性(log-bilinear)函数
2.5 NNLM
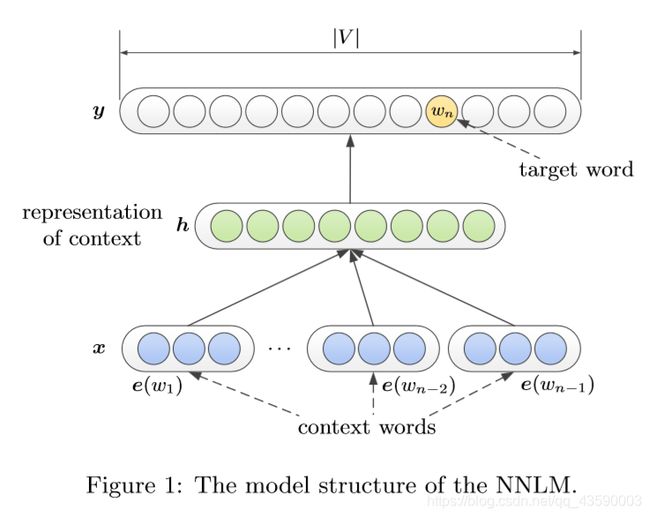
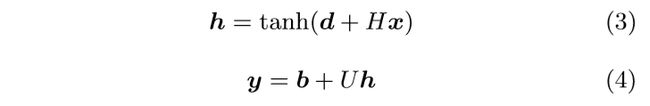
NNLM在Order的基础上加上了一层隐层。
隐层:前馈神经网络
U为转换矩阵,b、d为偏移量
最后,将y加上softmax来获得目标词的可能性
2.6 C&W
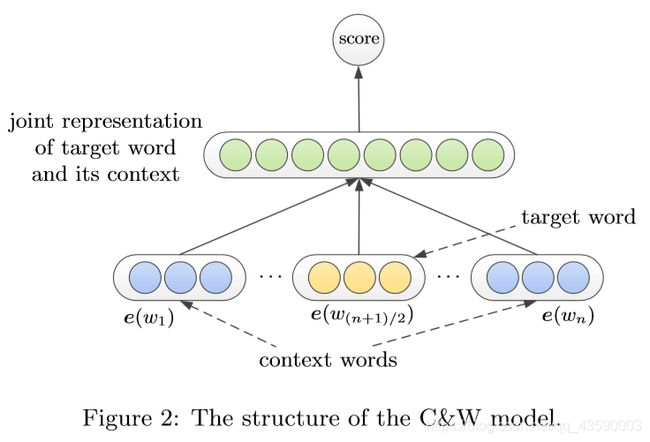
C&W模型只训练词向量,不预测目标词。因此,它直接将上下文和目标词作为输入进行训练,然后进行打分。这里的目标词指的是一个序列的中心词。
2.7 GLoVe
GloVe采用的是词-上下文矩阵,每一行表示的是词,列表示的是上下文。核心思想为词与词的共现。该模型利用的全局(训练集)信息。
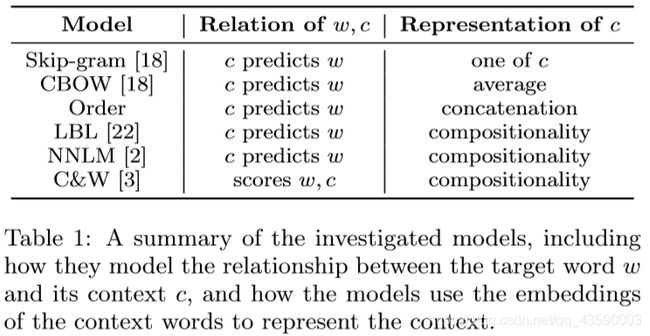
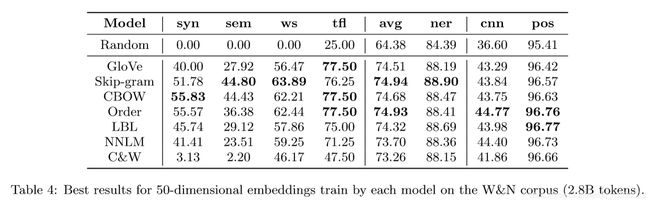
通过以上的词与上下文关系可以看出:
Skip-gram和CROW模型在词嵌入过程中有失去句法的部分关键信息。Order采用词的组成来表示上下文信息,保留了句法的信息。而LBL、NNLM、C&W模型则是再Order模型的基础上加上了一个隐层。因此,这些模型利用了上下文的语义信息。
故由此,我们可以提出如何提高word embeddding第一个方法:
在模型的构建中,越复杂的模型在更大的训练集下的表现优于简单模型。但是绝大多数情况下,简单的模型就足够用了。
3.corpus大小和类型
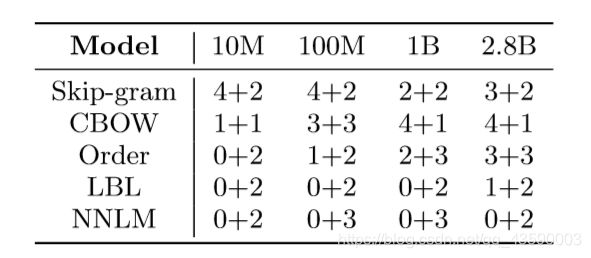
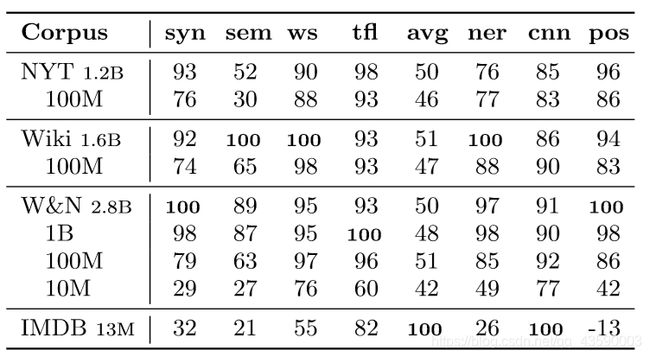
在corpus类型相同的情况下,corpus越大,模型的表现越好。
在特定的task下,in-domain的corpus比out-domain的corpus的模型表现要好得多。
在两个变量下,哪个对模型的影响更大呢。
corpus domain 比 corpus size 更重要。
在都是in-domain corpus下,并不是corpus size 越大越好,corpus size越大,会导致 corpus 中领域知识量相对变少。故,要在扩大corpus size的同时,保证corpus 的纯度。
4.Model参数
4.1 维度
如何决定维度的大小,这个根据特定task进行调参。
4.2 迭代次数
同样,要进行实验进行调参决定。
5.结论
影响word embedding质量主要由三部分组成:
1.model
2.corpus
3.model parameter
这三个影响因素哪个更重要,根据具体的task而定,task分为三类,
1.Embedding’s Semantic Properties
2.Embedding as Features
3.Embedding as the Initialization of NNs
就本人研究方向而言:NER
corpus > model = model parameter
在corpus中 ,corpus domain 大于 corpus size
综上:
在corpus size不大时,尽量选择 simpler model,
corpus domain 根据特定领域,选择领域相关的corpus,且纯度较高。
故,
理想情况下是:足够大却纯度极高的corpus size + 复杂的model + paramter(自己调)= your best word embedding。
这种情况下,调参是一件特别痛苦的经历,因为 这非常 time-consuming.
参考文献
Lai, S., Liu, K., He, S., & Zhao, J. (2016). How to Generate a Good Word Embedding. IEEE Intelligent Systems, 31(6), 5–14. doi:10.1109/mis.2016.45
.