网络爬虫数据解析的四种方式之XPath
文章目录
- 前言
- 四种数据解析方式
- 数据解析之XPath
-
- XPath介绍
- 在浏览器中安装XPath helper插件
- XPath使用方法
- 通过浏览器测试插件是否安装成功
- 通过python代码实现用XPath来解析数据
前言
快期末了,有个数据挖掘的大作业需要用到python的相关知识(这太难为我这个以前主学C++的人了,不过没办法还是得学),下面是我在学习爬虫相关知识的数据解析时总结的一些东西,我对于python不是很熟悉,如果下面的一些知识点有哪里出问题或者有不同理解的,请一定一定要在评论区提出来,让我这个菜鸡学习学习~~/(ㄒoㄒ)/~~
四种数据解析方式
当我们从网站上爬取到全部数据时,我们需要获得我们想要的数据,这就需要用到数据解析了,数据解析的方式有四种
- XPath解析数据
- BeautifulSoup解析数据
- 正则表达式
- pyquery解析数据
本篇博客主要是写XPath的相关知识点
数据解析之XPath
XPath介绍
- XPath
①全称: XML Path Language是一种小型的查询语言
②是一门在XML文档中查找信息的语言 - XPath的优点
①可在XML中查找信息
②支持HTML的查找
③可通过元素和属性进行导航 - Xpath需要依赖lxml库
①安装方式:pip install lxml

在浏览器中安装XPath helper插件
插件下载地址
下载成功
![]()
现在将插件拖入到浏览器中

XPath使用方法
下面这些东西如果不懂也没关系,后面我会提供例子给大家参考
1、XML的树形结构
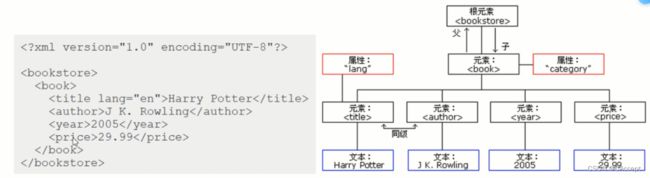
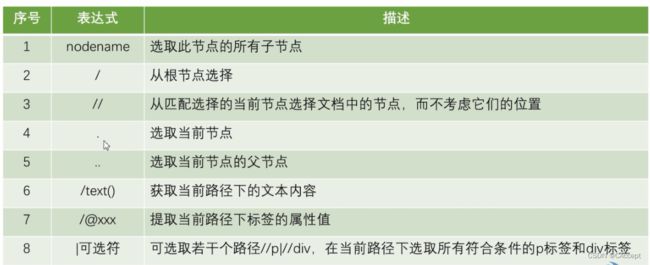
2、使用XPath选取节点

通过浏览器测试插件是否安装成功
1、打开浏览器

2、输入起点中文网的网址传送门

3、观察各个榜单的榜首在那个节点和位置 4.通过黑框来找到网站榜单的各个榜首书名 运行结果:
观察到这个网站榜单的各个榜首书名都是在\
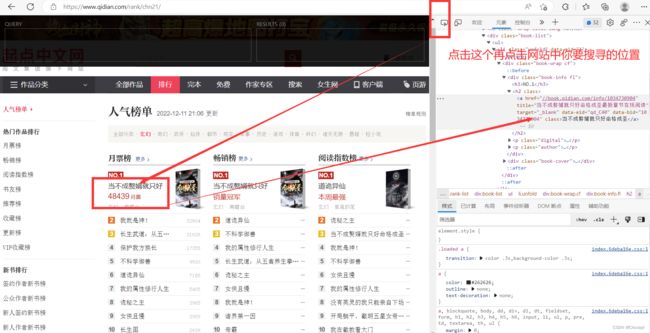

至此说明安装插件成功通过python代码实现用XPath来解析数据
import requests
from lxml import etree
url = "https://www.qidian.com/rank/chn21/"
# 需要添加头部
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46"}
# 发送请求
resp = requests.get(url,header)
e = etree.HTML(resp.text) # 将str类型转为etree.Element类型
# 获取榜首书名
names = e.xpath('//div[@class="book-info fl"]/h2/a/text()')
# 获取榜首作者名
authors = e.xpath('//p[@class="author"]/a[2]/text()')
# 将书名和作责名一起打印
for name,author in zip(names,authors):
print(name,":",author)
