CMT:卷积与Transformers的高效结合

来源:DeepHub IMBA
本文约1400字,建议阅读5分钟本文介绍构建一系列模型cmt,它在准确性和效率方面有更好的权衡。论文提出了一种基于卷积和VIT的混合网络,利用Transformers捕获远程依赖关系,利用cnn提取局部信息。构建了一系列模型cmt,它在准确性和效率方面有更好的权衡。

CMT:体系结构

CMT块由一个局部感知单元(LPU)、一个轻量级多头自注意模块(LMHSA)和一个反向残差前馈网络(IRFFN)组成。
1、局部感知单元(LPU)
在以前的transformer中使用的绝对位置编码是为了利用标记的顺序而设计的,它破坏了平移不变性。
为了缓解局限性,LPU使用卷积(MobileNetV1)提取局部信息,其定义为:
![]()
2、轻量级多头自我注意(LMHSA)
在原注意力模块中,自注意力模块为:
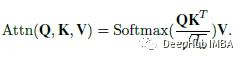
为了减少计算开销,在注意力操作之前,使用k × k步长为k的深度卷积(MobileNetV1)来减小k和V的空间大小。在每个自注意力模块中添加一个相对位置偏差B(类似于Shaw NAACL ' 18):

这里的h个是与ViT类似的注意力头。
3、反向残差前馈网络(IRFFN)
原始FFN使用两个线性层,中间是GELU:
![]()
IRFFN由扩展层(MobileNetV1)和卷积(投影层)组成。为了更好的性能,还修改了残差连接的位置:
![]()
使用深度卷积(MobileNetV1)提取局部信息,而额外的计算成本可以忽略不计。
4、CMT块
有了上述三个组成部分,CMT块可以表述为:

上式中,Yi和Zi分别表示LPU和LMHSA模块对第i块的输出特征。LN表示层归一化。
CMT变体
1、模型的复杂性
Transformer 的计算复杂度(FLOPs)可计算为:

式中,r为FFN的展开比,dk和dv分别为key和value的维度。ViT设d = dk = dv, r = 4,则计算可简化为:
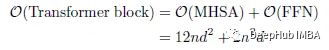
CMT块的FLOPs:

其中k≥1为LMHSA的还原比。
可以看到,与标准Transformer块相比,CMT块对计算成本更友好,并且在更高分辨率(较大n)下更容易处理特征映射。
2、扩展策略
受EfficientNet的启发,使用复合系数φ来均匀缩放层数(深度)、维度和输入分辨率:
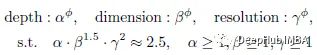
增加了α·β^(1.5) ·γ²≈2.5的约束,因此对于给定的新φ,总FLOPS将大约增加2.5^ φ。根据测试,默认为α=1.2, β=1.3, γ=1.15。
3、CMT变体

在CMT-S的基础上,根据提出的缩放策略构建了CMT-Ti、CMT-XS和CMT-B。四种模型的输入分辨率分别为160、192、224和256。
结果
1、消融研究
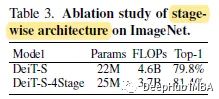
ViT/DeiT只能生成单尺度的特征图,丢失了大量的多尺度信息,但是这部分信息对密集预测至关重要。
DeiT与CMT-S一样具有4级stage,即DeiT- s - 4stage,可以实现改进。
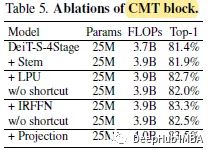
所有的增量改进都表明,stem、LPU和IRFFN对性能的提高也有重要的贡献。CMT在LMHSA和IRFFN之前使用LN,在卷积层之后插入BN。如果将所有的LN都替换为BN,则模型在训练过程中无法收敛。
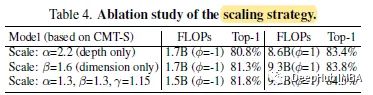
2、ImageNet

CMTS以4.0B FLOPs达到83.5%的top-1精度,比基线模型DeiT-S高3.7%,比CPVT高2.0%,表明CMT块在捕获局部和全局信息方面的优势。
值得注意的是,之前所有基于transformer的模型仍然不如通过彻底的架构搜索获得的EfficientNet,但是CMT-S比EfficientNet- b4高0.6%,计算成本更低,这也证明了所提出的混合结构的有效性。
3、下游任务

对于以RetinaNet为基本框架的目标检测,CMT-S优于twin - pcpvt - s (mAP为1.3%)和twin - svt - s (mAP为2.0%)。
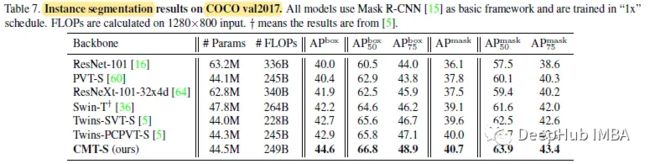
以Mask R-CNN为基本框架的分割,CMT-S以1.7%的AP超过了Twins-PCPVTS,以1.9%的AP超过了Twins-SVT-S。
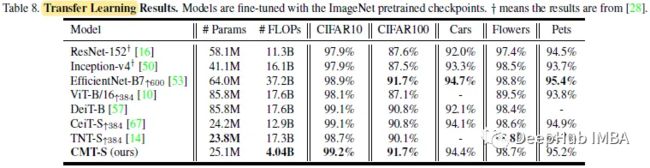
CMT- s在所有数据集中以更少的FLOPs优于其他基于transformer的模型,并在FLOPs减少9倍的情况下与EfficientNet-B7达到相当的性能,这证明了CMT架构的优越性。
论文地址:
https://openaccess.thecvf.com/content/CVPR2022/papers/Guo_CMT_Convolutional_Neural_Networks_Meet_Vision_Transformers_CVPR_2022_paper.pdf
MORE
编辑:黄继彦
