【强化学习-01】强化学习基本概念
强化学习基本概念
- 概率基本概念
-
- 概率密度函数
-
- 随机抽样
- 强化学习基本概念
-
- State, action
- Policy π \pi π
- Reward
- State transition
- Agent environment interaction
- 强化学习中的随机性
- Play the game using AI
- Rewards and returns
- Value functions
-
- Action-Value function
- Optimal action-Value function
- State-Value function
- Understanding the value functions
- Using AI to play games
-
- How does AI controls the agent
- 例子
- 总结
- 经典论文
本笔记整理自 (作者: Shusen Wang):
https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
概率基本概念
概率密度函数
probability density function
continuous distribution

Discrete distribution

概率密度加和为1

概率分布的期望

随机抽样


这里的
random sampling在强化学习中使用的非常频繁。比如在选择下一个action的时候以及下一阶段的state的时候,就会经常用到random sampling.
强化学习基本概念
State, action
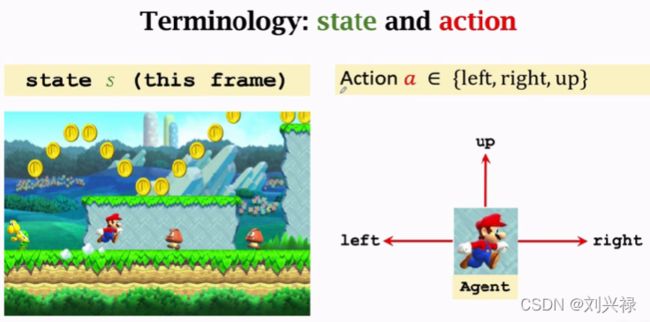
State s s s: 当前所处的状态,上图中就是这一帧的画面(
frame),包括马里奥的位置,金币的位置,敌人的位置等
Action a a a:agent(智能体)可以选择的动作。action∈ { left, right, up } \in \{\text{left, right, up}\} ∈{left, right, up},其实这里还应该有个stay,stay也是一个动作
Agent:发出动作的主体,动作是由谁做的谁就是agent
Policy π \pi π
policy的意思就是根据观测到的状态。做出决策来控制agent运动
在数学上,Policy π \pi π是一个概率密度函数 ,满足
- π ( s , a ) ∈ [ 0 , 1 ] \pi(s, a) \in [0,1] π(s,a)∈[0,1]
- π ( a ∣ s ) = P ( A = a ∣ S = s ) \pi(a|s) = \mathbb{P}(A=a|S=s) π(a∣s)=P(A=a∣S=s)
注意:
大写表示是随机变量(random variable),小写表示观测值(observation)
给定状态 S = s S=s S=s,下一步的具体动作 a a a是随机抽样得到的,要有随机性

Reward
reward通常需要我们自己来定义,reward定义的好坏非常影响强化学习的结果
注意,针对马里奥的游戏:尽量要把打赢游戏的奖励给的高一些,这样就不会总是吃金币。

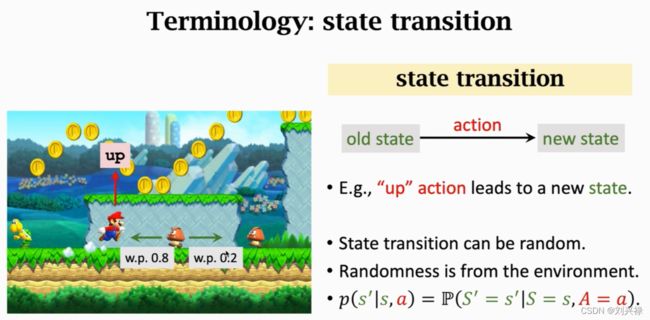
State transition
状态转移:当前状态下,mario采取一个动作,游戏就会给一个新的状态。比如mario跳一下,游戏的下一个状态就不一样了
状态转移可以是确定的,也可以是随机的
状态转移的随机性是从环境(environment)中来的。
下图:goomba的移动概率是向左0.8,往右移动的概率为0.2
但是对于玩家而言,我们不知道goomba向左或者向右的概率,这个概率只有系统知道。
状态转移函数
p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a ) \begin{aligned} p(s'|s,a) = \mathbb{P}(S'=s'|S=s, A=a) \end{aligned} p(s′∣s,a)=P(S′=s′∣S=s,A=a)
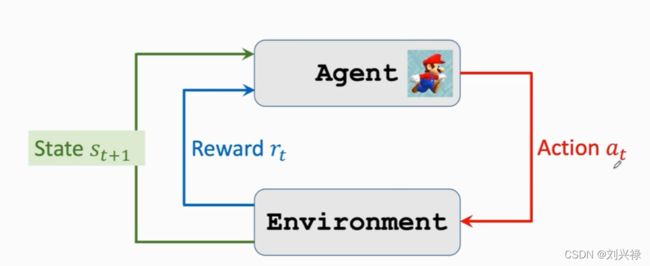
Agent environment interaction
这里的environment就是游戏
State就是环境告诉我们的,可以看成是当前的游戏画面

agent在状态 s t s_t st的情况下,做出动作 a t a_t at (left, right, up),然后environment给出下一时刻的状态 s t + 1 s_{t+1} st+1,并且给出相应的reward r t r_t rt.
强化学习中的随机性
- Action的随机性:给定状态 s s s,下一个阶段的动作,是根据Policy π \pi π (这是一个概率密度函数)抽样得来的。

- 状态转移的随机性:环境根据当前状态 s s s和可选的action,用状态转移函数 p p p计算出每个动作的概率,然后用随机抽样来决定下一步的action。

Play the game using AI

Rewards and returns



U t U_t Ut跟未来的所有action和state都有关,因此是随机的。
Value functions
Action-Value function
Action-Value function:
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] Q_{\pi}(s_t, a_t)=\mathbb{E}[U_t|S_t = s_t, A_t = a_t] Qπ(st,at)=E[Ut∣St=st,At=at]
Q π ( s t , a t ) Q_{\pi}(s_t, a_t) Qπ(st,at)是跟策略函数 π \pi π以及状态 s s s和动作 s s s有关的,给定Policy π \pi π,State s s s, Action a a a,我们可以进行积分,获得 Q π ( s t , a t ) Q_{\pi}(s_t, a_t) Qπ(st,at)。这里需要注意,实际上 Q π ( s t , a t ) Q_{\pi}(s_t, a_t) Qπ(st,at)也是跟 s t + 1 , s t + 2 , ⋯ s_{t+1}, s_{t+2}, \cdots st+1,st+2,⋯以及 a t + 1 , a t + 2 , ⋯ a_{t+1}, a_{t+2}, \cdots at+1,at+2,⋯ 有关的,这个可以根据 U t U_t Ut的定义可得。但是由于积分将这些全部消除,就只剩下了观测值 s t s_t st和 a t a_t at。如果 π \pi π不一样,积分得到的 Q π ( s t , a t ) Q_{\pi}(s_t, a_t) Qπ(st,at)也不一样。

Optimal action-Value function
最优动作价值函数,Optimal action-Value function与 π \pi π无关,因为 π \pi π已经被 max \max max给消除了。
Optimal action-Value function Q ∗ ( s t , a t ) Q^{*}(s_t, a_t) Q∗(st,at)可以用来对动作作评价。
有了 Q ∗ ( s t , a t ) Q^{*}(s_t, a_t) Q∗(st,at),agent就可以利用 Q ∗ ( s t , a t ) Q^{*}(s_t, a_t) Q∗(st,at)来做动作了。
另外,Q值是对未来奖励总和的期望。

State-Value function
V π ( s t ) = E A [ Q π ( s t , A ) ] V_{\pi}(s_t) = \mathbb{E}_{A}[Q_{\pi}(s_t, A)] Vπ(st)=EA[Qπ(st,A)]: 在given state s t s_t st之后,将下一步可以做的动作 A A A作为随机变量,对 A A A求积分,将 A A A消掉

上面对 A A A求期望,也就是 E A [ Q π ( s t , A ) ] \mathbb{E}_{A}[Q_{\pi}(s_t, A)] EA[Qπ(st,A)]的式子中,随机变量 A A A是服从分布 A ∼ π ( ⋅ ∣ s t ) A\sim \pi(\cdot|s_t) A∼π(⋅∣st)的,也就是given state s t s_t st。如果 a a a是离散的,则可以将期望写成连加的形式

如说是连续的action,则需要进行积分。

Understanding the value functions
Action-value function: Q π ( s t , a t ) Q_{\pi}(s_t, a_t) Qπ(st,at)是给动作 a t a_t at进行打分,也就是agent在状态 s t s_t st的时候做出动作 a t a_t at是否明智State-value funcrion:

Using AI to play games
How does AI controls the agent
Policy based learning: 第一种方法是学习policy。已知policy π ( a ∣ s ) \pi(a|s) π(a∣s),我们就可以given state,然后根据概率分布,对action a a a进行随机抽样,得到 a t a_t at,最后agent执行动作 a t a_t at。Value based learning:另外一种方法是学习最优动作价值函数 Q ∗ ( s t , a t ) Q^{*}(s_t, a_t) Q∗(st,at)。然后agent可以根据 a t = argmax a Q ∗ ( s t , a ) a_t = \text{argmax}_a Q^{*}(s_t, a) at=argmaxaQ∗(st,a),执行下一步的动作,因为 Q Q Q值是对未来奖励的期望。

以上两种方法都可行,也就是强化学习中也么是学习 π ( ⋅ ∣ s t ) \pi(\cdot|s_t) π(⋅∣st)函数或者 Q ∗ ( s t , a t ) Q^{*}(s_t, a_t) Q∗(st,at)函数,只要学到两者之一即可。
例子


总结



这里总结一下
Value based learning:算法temporal differencePolicy based learning:算法policy gradient
经典论文
Q-learning:
@article{watkins1992q,
title={Q-learning},
author={Watkins, Christopher JCH and Dayan, Peter},
journal={Machine learning},
volume={8},
number={3-4},
pages={279–292},
year={1992},
publisher={Springer}
}