【论文精读】Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code
- 前言
- Abstract
- 1. Introduction
- 2. Evaluation Framework
-
- 2.1. Functional Correctness
- 2.2. HumanEval: Hand-Written Evaluation Set
- 2.3. Sandbox for Executing Generated Programs
- 3. Code Fine-Tuning
-
- 3.1. Data Collection
- 3.2. Methods
- 3.3. Results
- 3.5. Results on the APPS Dataset
- 4. Supervised Fine-Tuning
-
- 4.1. Problems from Competitive Programming
- 4.2. Problems from Continuous Integration
- 4.3. Filtering Problems
- 4.4. Methods
- 4.5. Results
- 5. Docstring Generation
- 6. Limitations
- 7. Broader Impacts and Hazard Analysis
-
- 7.1. Over-reliance
- 7.2. Misalignment
- 7.3. Bias and representation
- 7.4. Economic and labor market impacts
- 7.5. Security implications
- 7.6. Environmental impacts
- 7.7. Legal implications
- 7.8. Risk mitigation
- 8. Related Work
- 9. Conclusion
- 阅读总结
前言
本篇工作是OpenAI公司出品的Codex,也是GitHub Copilot工具背后的模型原型,其方法简单,但是效果出众,是GPT系列一大重要的落地成果,其对风险的分析也是很多产品落地值得借鉴的地方。
| Paper | https://arxiv.org/pdf/2107.03374.pdf |
|---|---|
| Code | https://github.com/openai/human-eval |
| From | OpenAI |
Abstract
本文提出Codex,基于GPT语言模型,在GitHub代码上进行微调,研究其在Python上的代码能力。此外,作者构建了HumanEval数据集,用于测试模型根据注释生成代码的能力。在实验部分,Codex可以解决28.8%的问题,如果让模型重复执行100次,那么可以解决70.2%的问题。最后,作者提出模型的局限性,探讨其潜在的影响。
1. Introduction
早期的工作表明可扩展的序列预测模型已经成为很多领域的生成和表示学习的通用方法,GPT-3也被证明可以从Python文档注释中生成代码。本文工作专注于从文档注释中生成独立的Python函数的任务,并通过单元测试自动评估代码示例的正确性。作者构建了HumanEval数据集,它由164个包含语言理解、数学、算法等简单的编程问题组成。
本文的Codex模型有多个规模,12B的Codex可以解决28.8%的问题,300M的Codex能够处理13.2%的问题,作为对比,6B的GPT-J只能解决11.4%的问题。为了进一步提升模型的性能,作者在独立的、正确的函数上进一步微调,由此得到的Codex-s可以解决37.7%的问题,下图是部分生成方案。

真实场景下代码都是不断迭代debug的结果,因此作者让模型生成100个解决方案来近似最终结果,Codex-s能够为77.5%的问题生成至少一个正确的函数。如果对解决方案进行排序,那么有44.5%的问题得到了解决。

2. Evaluation Framework
2.1. Functional Correctness
代码生成模型通过样本与参考解决方案进行匹配来进行基准测试。之前的评估指标如BLEU对相似的文本给予更高的分数,但是对于代码来说,相似的代码并不意味着运行准确。因此作者采用pass@k metric,每个问题生成k个代码样本,如果任意样本都能通过单元测试,则认为问题得到解决。但是这样的方式偏差较大,为此,作者为每个任务生成n个样本(本文n=200,k≤100),计算通过单元测试正确的样本数量,并计算无偏样本估计:
pass @ k : = E Problems [ 1 − ( n − c k ) ( n k ) ] \text { pass @ } k:=\underset{\text { Problems }}{\mathbb{E}}\left[1-\frac{\left(\begin{array}{c} n-c \\ k \end{array}\right)}{\left(\begin{array}{l} n \\ k \end{array}\right)}\right] pass @ k:= Problems E 1−(nk)(n−ck)
作者对计算过程做了优化,如下代码所示:

2.2. HumanEval: Hand-Written Evaluation Set
作者在自己构建的HumanEval数据集上进行测试。这些代码问题必须是新设计的,否则会和GitHub中的相似问题重合,无法验证模型真正的泛化性能。
2.3. Sandbox for Executing Generated Programs
由于GitHub上包含恶意的程序,因此作者创造了一个沙盒环境来安全运行这些程序进行单元测试,防止这些程序修改、持久化、访问主机等敏感资源或者窃取数据。
3. Code Fine-Tuning
3.1. Data Collection
作者从GitHub上收集179GB的Python代码,经过简单的过滤操作得到159GB的数据集。
3.2. Methods
可能是微调数据集过大,作者发现基于预训练好的GPT-3模型进行微调对结果没有改进,只不过收敛变快了。为了最大程度利用GPT的文本表示,作者的代码lexer基于GPT-3文本的tokenizer实现。但是由于代码和文本分布不同,tokenizer并不高效,最大的根源来自于空格和空行,为此作者加入了额外的token集用于表示不同长度的空白,这使得作者能够少用30%的token来表示代码。
为了计算pass@k,作者将每个HumanEval问题组装成一个由header、签名和文档token组成的prompt。作者从Codex中采样token,直到遇到停止符,否则继续生成其它函数或者语句。作者采用核采样方法进行采样,p值设为0.95。
3.3. Results
下图作者根据Codex的模型大小绘制了损失变化的曲线。
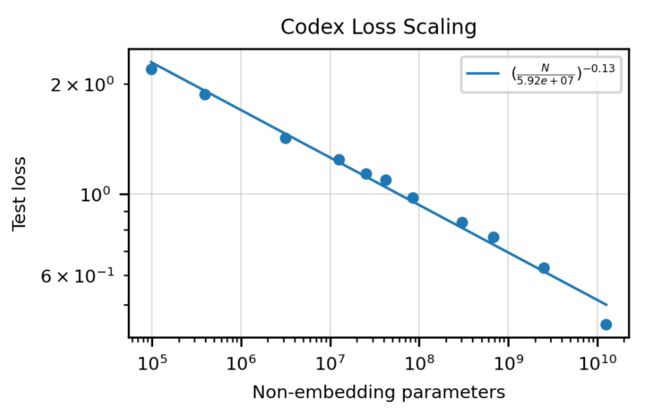
可以看到,模型参数指数增长和测试损失呈现线性的变化。

在评估pass@k时,针对特征的k优化采样温度十分重要。上图绘制了pass@k与样本数量k以及采样温度的关系。作者发现,随着采样次数的增加,更高的温度可以得到更好的评分,因为模型的多样性增加了。

上图展示的是排序算法的性能,即允许模型生成k的答案,只是根据不同的策略和指标挑选最好的结果进行单元测试,Oracle虽然是最好的策略,但是在现实中,你不可能对每个方案都进行一次测试。因此相对比较合理的方案是对任何一个解,去看每个候选token在softmax中的概率取log算均值,将均值最高的选择出来相对性能较好。

上图展示的是BLUE分数指标在code中的判别情况,可以看到正确和错误的分布几乎难以分开,因此采用BLUE分数来判别生成code的性能是不科学的。
3.5. Results on the APPS Dataset
APPS数据集是前人构建的用来衡量语言模型编码能力的数据集,它包含5000个编码问题的训练集和5000个测试集,每个示例都有一组单元测试。本文在测试时只采用严格准确性的指标,即但凡有一个示例不通过也算生成的代码有问题。结果如下:

4. Supervised Fine-Tuning
Codex预训练部分的文件除了独立函数,还包括大量的配置文件、脚本等,与最后评测的注释生成代码的任务无关,为此,作者又收集了和HumanEval类似的数据集,用于Codex的监督微调。
4.1. Problems from Competitive Programming
编程竞赛和面试算法题都是相互独立的,带有良好的问题陈述,并且测试用例覆盖充分。作者从几个流行的编程竞赛和面试网站收集了10000个问题,并组装成类似于HumanEval的编程任务。
4.2. Problems from Continuous Integration
接下来,作者整理了开源项目中的编程问题,利用sys.setprofile,可以跟踪和收集集成测试期间调用函数的输入和输出,并利用该数据为函数创建单元测试。此外,为了防止开源项目中代码可能存在的危害,因此作者构建环境让代码在沙盒中进行集成测试。
4.3. Filtering Problems
由于质量无法保证,因此作者使用Codex-12B为每个问题生成100个样本,如果样本没有通过单元测试,会认为该任务不明确或者过于困难,将其过滤掉。作者多次重新运行此验证,以消除状态或非确定性问题。
4.4. Methods
经过上面的监督微调得到Codex-S,作者进行训练以最小化参考解决方案的对数似然,使用微调Codex的1/10学习率,但遵循相同的学习率变化。
4.5. Results

结果主要体现在上面两张图上,可以看到经过监督微调好,Codex的性能明显提升。
5. Docstring Generation
这里是Codex的一个应用,既然能够通过注释生成代码,能不能根据代码反向生成注释。作者构建了一个代码生成注释的数据集,具体来说,对于每个训练问题,我们通过连接函数签名、参考解决方案和文档字符串来组装训练示例。作者通过最小化注释的负对数似然来训练注释生成模型Codex-D。
但是生成注释的质量不像生成代码那样容易评估。为此作者进行人工的评分,并将Codex-D生成的注释反向生成代码,其结果对比如下:

可以看到Codex-D性能还是有明显的下降。
6. Limitations
模型整体上来看有如下的局限性:
- 模型的训练并不高效,需要上亿行数的代码才能得到当前的性能。
- 随着注释字符串的长度增加,模型的性能呈现指数级别的下降。
- 模型的数学能力不佳。
7. Broader Impacts and Hazard Analysis
Codex虽然在很多方面都具有发挥作用的潜力,但是它的出现也会面临相应的安全挑战。因此本节作者进行了安全分析,希望未来的工作能够更多关注于这些风险。
7.1. Over-reliance
新手程序员可能会过于依赖于Codex帮助他们生成代码,由此造成不安全代码生成的问题,因此需要人工监督和警惕。
7.2. Misalignment
Codex在面对一些问题时,可能有能力解决却给出错误的代码,这就是无法和用户的目标对齐问题,即系统是错位的。这种失调会随着模型的大小和数据的变大而变大,如下图所示:

随着模型能力的增加,这种问题会变得更加危险并难以发现,因为这些代码看起来会更加准确,用户难以识别出错误,可实际上已经做了有害的事情。
7.3. Bias and representation
和基于互联网数据训练的其他语言模型情况相同,Codex会以种族歧视、诽谤和一些有害输出的方式进行提示,需要进行干预。
7.4. Economic and labor market impacts
Codex可以提高程序员的生产力,降低生产软件的成本,此外由于预训练的代码所使用的工具包会造成应用时也使用这些包,导致某些工具包的作者会比其他作者更能受益,需要对代码生成能力的影响和适当的响应进行更多的研究。
7.5. Security implications
Codex可能会被滥用帮助网络犯罪,产生更高级的恶意软件。
7.6. Environmental impacts
训练Codex需要耗费大量的资源,从发展角度来看,这样的训练成本会越来越高。
7.7. Legal implications
人工智能基于互联网上的数据进行训练如果是为了造福社会那么就不会被定性为违法行为。但是代码的生成从本质上还是作品的作者去负责, 但是利用代码模型生成代码的行为,在未来会考虑更多安全性的问题,以便此类系统的用户最终能够充满信心地部署它们。
7.8. Risk mitigation
使用像Codex这样的模型,需要仔细探索其功能,着眼于最大限度地发挥其积极的社会影响,并最大限度地减少其使用可能造成的有意或无意的伤害。
8. Related Work
略。
9. Conclusion
本文通过对GitHub上的代码进行GPT微调,发现其在人类编写的代码问题上表现出强大的性能,并且通过相似问题的监督微调还可以进一步提升模型的性能。此外作者还尝试了代码生成注释的任务,并且在最后讨论了Codex的局限性和风险。
阅读总结
Codex作为GitHub Copilot背后的工具模型,在整个互联网行业掀起了血雨腥风,人们在惊叹其优质的代码生成能力的同时,又惶恐着自己终将被替代的可能。回到模型本身,它并没有特殊的创新点,就是基于GPT-3的模型在Python代码上进行微调,并且在精心构建的相似问题的数据集上进行监督微调,进一步提升性能。其主要的创新点还是在于评估指标的设计和数据集的构建,那么下一篇DeepMind的AlphaCode, 又会带来什么不一样呢?