基于语义分割的相机外参标定
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达简介
单目相机对于机器人和自动驾驶辅助是至关重要,也在交通控制基础设施中大量使用。然而,校准单目摄像机非常耗时,通常需要大量手动干预。在这项工作中,我们提出了一种摄像机外参标定方法,该方法通过利用图像和点云的语义分割信息来自动估计参数,该方法依赖于摄像机姿态的粗略初始估计,并基于安装在具有高精度定位的车辆上的激光雷达传感器来捕获环境的点云信息,然后,通过对语义分割的传感器数据执行激光雷达到摄像机的配准,获得摄像机和世界坐标空间之间的映射关系,在模拟和真实数据上评估了我们的方法,以证明校准结果中的低误差测量,该方法适用于基础设施中传感器和车辆传感器,且不需要摄像机平台的运动。
主要贡献
本文提出了一种单目相机机标定方法,用于对语义分割的单目相机的图像和相机所在环境的语义标记三维模型进行跨域配准,图1给出了该方法的概述。
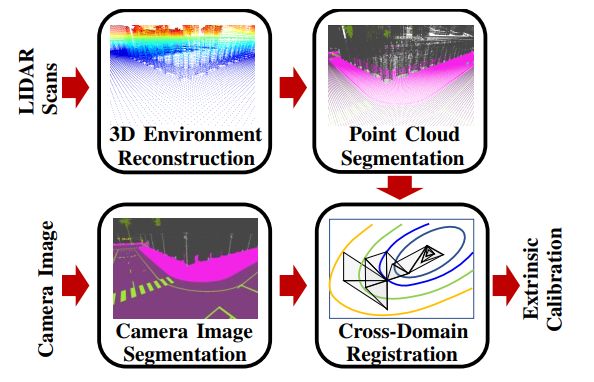
图1.方法概述,左侧是来自两个域的数据输入到流程中,对于激光雷达数据,使用多次扫描重建3D环境,之后,两个域都在语义上进行标记,在最后一步,执行提出的优化以配准两个域数据以优化得到外参校准数据
通过使用相机和点云域的语义表示,引入了语义标签,可以在跨域之间进行匹配校准,此外,使用语义标签代替原始RGB和RGBD相机数据使配准更加稳健,并减少配准算法错误的可能性。
该方法包括数据预处理步骤以及执行跨域配准的优化步骤,在预处理步骤中,重建三维环境模型,然后使用神经网络进行语义标记,并对目标摄像机的图像进行语义分割处理,然后,调用优化算法以将3D模型的渲染视图的视觉外观和投影与分割的摄像机视图相匹配。该优化产生非本征相机校准。最后,使用 CARLA模拟器和KITTI数据集进行的实验表明,该方法达到了适用于静态和动态相机平台的自动驾驶应用的精度水平。本文的贡献有两点:
(1)从实用的角度来看,该方法允许在世界坐标系中对单目摄像机进行低成本、高度自动化的校准,而不需要目标传感器平台的运动。
(2)从方法论的角度来看,据我们所知,这是第一个使用语义分割作为视觉特征集来指导所需参数优化的工作。该方法的源代码是公开的:https://github.com/Tuxacker/semantic_calibration.git(源码还未上传)
主要内容
A、 问题表述和约束
已知透视相机模型
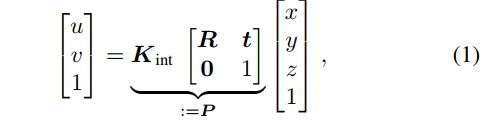
等式左边为图像坐标,右边为点云信息,目标是恢复相机的外参矩阵P的参数,即旋转矩阵R3×3和平移向量T,同时,假设表示从摄像机坐标系中的3D坐标到2D像素坐标的映射的内在参数K(R3×4)是已知的,提出了一种新的标定方法来估计相机的外参数据。
B、 三维环境重建
假设配备有激光雷达传感器和高精度定位的车辆,以构建3D环境模型M,一些激光雷达扫描数据被记录为点云,并在世界坐标系中表示,从激光雷达传感器坐标到世界坐标的转换需要已知的激光雷达参信息,由于道路颠簸和不准确的方向测量,传感器远场中的点的位置误差会增加,从而导致具有许多异常值的噪声3D点云,因此,我们过滤出距离车辆激光雷达传感器超过最大距离dmax的点,在实践中,dmax选择在50米和75米之间,这是Velodyne传感器的标准截止值。接下来,依赖于所有扫描数据之间的多路迭代最近点(ICP)配准算法,该算法部分补偿了随时间累积的定位误差,为了加快配准,不是将每个扫描与其他扫描进行配准,而是按捕获时间对所有扫描数据进行排序,并递归配准和合并三个相邻扫描的组,当所有组合并到单个点云M中时,递归结束。最后,在每个递归步骤中对点云进行下采样,以降低ICP计算要求,如果通过其他建图算法或从不同源获得3D环境模型,则可以跳过重建的步骤。
C、 点云语义分割
这一步将语义标签分配给重建后的点云,以获得语义分割点云,该点云图包含模型中每个点的颜色标签,对于这项任务,我们依赖预训练的深度神经网络来执行语义分割,即Cylinder3D,它支持SemanticKITTI中定义的类的分割。此外,分割还用于过滤出汽车和行人等动态对象类,这使得建筑物、地面点、植被、围栏、电线杆和交通标志类别留下来进行配准,因此,校准方法不需要激光雷达扫描点云和相机图像之间的精确时间同步,因为属于动态对象的点可以很容易地通过其标签过滤掉。
D、 图像语义分割
在标记环境点云之后,从相机图像中提取语义分割图,与点云分割类似,我们依赖预训练的深度神经网络来提取城市景观数据集中可用的语义标签,例如OCRNet,选择使用Cityscapes标签,因为它们共享SemanticKITTI中可用的大多数类,因此可以在域之间直接匹配类标签,再次从分割图中移除动态对象类类别,例如汽车或行人。对于其余的对象类别,通过忽略具有该域唯一标签的点和像素,在点云和图像分割模型之间执行类别对齐,应该注意的是,移除动态对象会导致生成的贴图中出现孔洞,尤其是在拥挤的场景中,为了尽量减少其影响,在后面的章节的配准步骤中引入了归一化因子β,图像分割也可以半自动地进行,以提高校准质量。在这种情况下,手动编辑得到的分割以修复不正确标记的区域,以提高数据质量,从而减少整体校准误差。
E、 跨源配准
我们的目标是估计旋转矩阵R和平移向量t,我们将此估计问题表述为优化问题,最小化旋转和平移的损失与误差,由于Nelder-Mead方法不需要梯度信息,它允许将广泛的数据变换应用于模型点云数据,这包括渲染变换,可用于获得模型的特定透视图的光栅化图像,因此,将模型的渲染函数f定义为
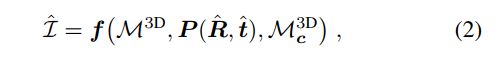
其中,M3D_c是分割的颜色编码,R^,^t是R和t的估计,该渲染函数用于将具有颜色标签模型点云转换为具有由透视相机矩阵P(R^;^t)定义的视点的图像I^,然后,通过计算两幅图像之间的距离度量并将结果解释为损失值,可以将I^与先前获得的图像分割进行视觉匹配,通过调整R^和^ t以最小化这些图像之间的视觉差异,从而最小化损失值,可以确定最佳摄像机参数。Nelder-Mead方法的优点在于它使用简单的形式来定义初始搜索空间,然后向函数最小值移动和收缩,通过根据初始猜测的预期测量方差缩放初始边界,这样就可以很容易地定义初始覆盖的合理搜索空间,也可以使用其他无梯度方法。
a) 初始化:为了构建优化函数,Nelder-Mead方法需要初始参数集,算法的收敛速度及其找到最优解的能力取决于初始参数集和搜索空间,因此,需要对摄像机位置和方向进行初始猜测,此外,我们将俯仰角和偏航角的搜索空间限制为±5◦, 而我们将横滚角设置为零,当然也希望我们的方法也适用于non-vanishing的滚动角度,但在我们的使用情况下,不需要摄像机滚动,可以通过适当的安装来实现,这是一个合理的简化,在大多数实际情况下,可以很容易地获得具有这种精度的初始猜测,并足以获得外参优化问题的良好的解决方案。
b) 循环优化:调用Nelder-Mead方法,直到两个步骤之间的损失距离低于10−4以估计R^和t,优化的损失目标定义为:
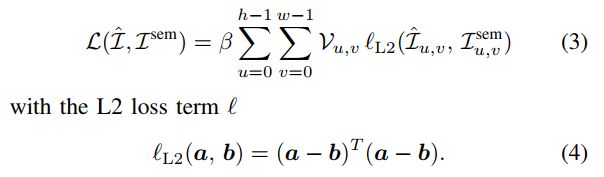
c) 外观匹配和掩码:在优化相机姿态之前,我们希望将渲染图像的总体外观与目标图像进行紧密的匹配,并减少渲染伪影,出于这个原因,首先致力于最小化由于3D模型中点的稀疏性而导致的背景像素的出现。这是通过计算模型中每个点到摄像机位置的距离d来实现的,将3D模型中的每个点渲染为半径为ri=λ的圆,其中λ是一个缩放因子,取决于点云密度,可以通过渲染侧视图并增加λ来经验确定,直到渲染视图的外观与目标分割图像大致匹配。
这种自适应点大小方法还增加了限制不同激光雷达模型之间不同线数的影响的好处,因为通过增加λ,线数较少的激光雷达仍然可以密集渲染。其次,由于点云稀疏性等原因,仍然无法为其分配与静态对象对应的语义标签的像素最终被分类为无效像素,以便这些像素在估计R^和^t时不会造成损失。
d) 结果验证:在执行优化步骤后,最终获得初始校准结果,然而,由于损失函数相对于校准参数是非凸的,该结果可能表示局部最小值,为了避免局部极小值,使用前一个结果作为新的开始值重新启动优化两次,同时在最后的优化步骤期间将收敛阈值从10降低−4至10−6,选择导致最低损耗的参数集。为了检查得到的参数是否确实是最优的,在初始猜测中添加一个小的附加噪声,以便退出可能找到的损失的局部最小值,附加噪声的尺度可以基于初始测量的相机姿态的测量精度,然后,可以使用具有噪声初始值的重复优化来丢弃具有高最终损失值的次优参数集,这是由损失函数的非凸性引起的。
实验
通过使用 CARLA模拟器观察虚拟交叉口环境,以及基于kitti数据集的真实环境,来评估我们在基础设施场景中的方法,评估描述了外参估计的准确性,包括用于基准测试的场景处理,最后给出了我们的结果。

图2.CARLA模拟器样本结果。(a) 描述了摄像机传感器的理想语义图像分割。(b) 显示语义分割点云的渲染视图。
CARLA评估时,点云视图以天空背景呈现,如图2b所示,为了仅匹配两幅图像之间的共同天空区域,渲染视图中与目标中的天空区域不匹配的天空区域被屏蔽,因为这些像素是由点云稀疏引起的,另一种有效的措施是仅使用图像的下半部分进行配准,如在KITTI lidar数据中,在高维度上裁剪点云,导致场景的修剪视图,这在图像的上半部分引入了高度差异。这可以在图3c中清楚地看到,最后,在KITTI评估的情况下,将点云裁剪到初始位置周围75米的半径,以减少内存占用,激光雷达分割视图是用Pytorch3D绘制的。

图3.KITTI数据集结果,我们可以看到分割图像和渲染的点云之间存在明显的视觉差异,这是由点云稀疏性以及不正确的标签造成的,但是,它们仍然具有足够的共同标签特征,实现可靠匹配。
表1总结了我们的评估结果和检查的损失函数,对于CARLA评估,两个场景的平移误差都低于7厘米,而旋转误差最多为0.11◦. 我们观察到误差主要来源于点云稀疏性。还应注意,由于图像的光栅化表示,我们无法区分单个像素以下的图像平移,因此在渲染视图中可能看不到摄像机平移小于1cm和摄像机旋转0.01°的微小变化。现实世界中的kitti场景也表现得很好,虽然点云标签和图像分割都包含不正确的标签,并且在点云的情况下,包含不正确测量的数据点,但最终校准质量仍然非常高,尤其是用于基础设施传感器校准时。此外,我们通过不手动校正图像分割来测试完全自动标记的KITTI场景,这些场景中的性能仅略有下降,甚至保持在相同的范围内,因此与半自动用例相当。
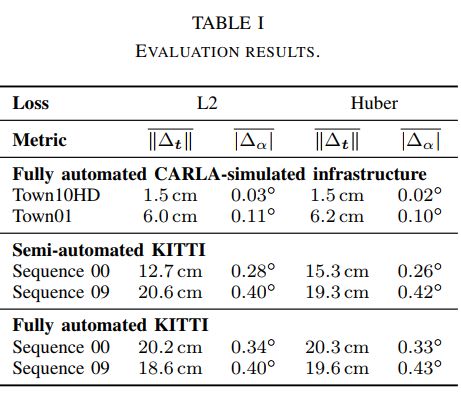
然而,应当注意,这种性能高度依赖于传感器数据的质量和用于训练分割网络的数据集,比较两种损失类型,我们只能看到细微差异,这可以通过随机初始化和测试方法来解释。因此,这两种损耗同样适用于该任务。
总结
本文提出了一种用于基础设施和智能驾驶车辆中相机的外参校准方法,在我们的方法中,在获得了lidar数据和相机数据的语义分割后,通过使用循环优化将语义的分割图像与分割的激光雷达数据的渲染视图相匹配,使用该分割数据来找到最佳校准参数,从而有效地执行跨域配准,该算法已在CARLA模拟场景和来自KITTI数据集的真实传感器数据上进行了评估,以显示其在实际应用中的可行性,显示出与现有方法相同或更好的结果。
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~