IMAGEBIND: One Embedding Space To Bind Them All 个人笔记
文章目录
- ImageBind
-
- Background
- 1.Introduction
- 2.Related Work
- 3.Method
-
- 3.1思路:
- 3.2学习方法
- 3.3实现细节
-
- 1.编码方案
- 2.数据集来源
- 4.Experiments
-
- 4.1强大的zero-shot分类能力
- 4.2 少样本分类能力
- 4.3 模态组合的应用
- 5.Ablation Study
-
- 5.1消融实验设置
- 5.2针对图像编码器的尺寸实验
- 5.3针对训练过程的调整实验
-
- 1.不同的温度系数的影响
- 2.不同投影头的影响
- 3.训练epochs大小的影响
- 4.数据增强
- 5.batch size对不同模态的影响
- 6.将ImageBind作为评估预训练模型的工具
- 6. Discussion and Limitations
ImageBind
Background
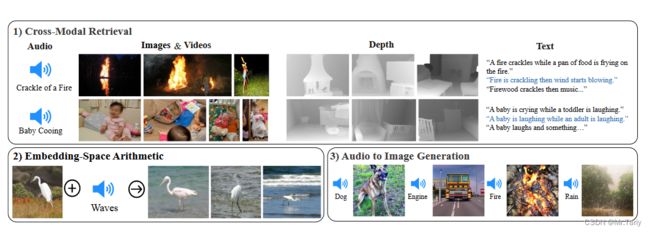
自从CLIP图文多模态模型问世以来,出现了多种不同版本的多模态CLIP模型,如AudioCLIP模型等。这些模型在多模态检索和分类任务上表现出色,特别是在零样本能力方面表现出强大的潜力。然而,在先前的多模态任务研究中,通常只结合了2-3种模态(例如图像、文本、音频等)来学习一个共享的嵌入空间,以便进行不同的下游任务。这是因为目前缺乏多种模态成对匹配出现的数据集,而且制作这种数据集非常困难。那是否还有可能学习更多模态的联合嵌入空间呢,ImageBind提出了一种方法,来学习一种6个模态的联合空间(图像,文本,音频,深度,热力图,和IMU数据)。论文指出没必要学习所有模态成对的数据,仅仅用图像作为匹配足以绑定所有模态。
1.该方法产生了新的涌现能力,能够做很多框架之外的任务,例如模态检索,结合其他模态,和跨模态检测。
2.在零样本识别任务中,产生的涌现能力超过了原有的特定监督任务的模型。
3.在少样本识别任务中,性能超过了以前的工作。
4.用ImageBind作为一种新的评估视觉和非视觉任务的视觉模型的新方法。
1.Introduction
图像与生俱来具有绑定其他模态的自然属性,可以结合任何和图像有关的感官体验的模态(声音,文字等等)。
理想条件下,对齐所有与图像相关的模态就可以在单个联合空间中学习到各种模态与图像有关的特征。但是缺乏所有模态一起出现的大量多模态数据。
最近的研究,都是建立在对单个或几个模态对进行训练学习,在应用时,仅限使用训练时使用的模态做下游任务,比方说学习到的视频-音频的embeddings不能用于图像文本的任务。
ImageBind想法如下:
1.利用图像自然的绑定属性,只将其他模态对齐图像模态就能涌现出所有模态对其的统一Embedding。
2.利用了互联网上的图像、文本数据集,再加上天然绑定的模态数据,例如(视频,音频),(图像,深度)等等。来学习一个统一的联合空间。
3.通过将其他模态与图像对齐,ImageBind也能隐式地将其他模态之间进行对齐。
4.ImageBind能够从Clip视觉语言模型上初始化开始训练。
结果表明,出现了强大的零样本涌现能力。
2.Related Work
1.之前的工作中主要学习文本、图像的联合嵌入空间,采用对比学习方法,产生了强大的零样本性能。
2.受预训练的图像文本模型启发,很多工作在尝试将其他模态与语言信号配对,学习深层次的语义特征。很多方法采用Clip模型作为挖掘深层次语义特征的方法,例如AudioClip。而ImageBind无需专门配对所有模态的数据,使用图像作为一种自然弱监督信号来统一所有模态。(即用图像信号绑定所有模态信号)

3.Method
3.1思路:
将其他模态与图像作匹配,从而学习到强大的联合嵌入空间。
3.2学习方法
称( I I I, M M M)为对齐的模态数据对,对于 I i I_i Ii和与其相对应的模态 M i M_i Mi,我们分别对其编码到标准化的嵌入空间:
q i = f ( I i ) k i = g ( M i ) \begin{align*} q_i &= f(I_i)\\ k_i &=g(M_i) \end{align*} qiki=f(Ii)=g(Mi)
f f f和 g g g分别是深层神经网络,在训练优化时采用InfoNCE loss(信息噪声对比估计损失函数):
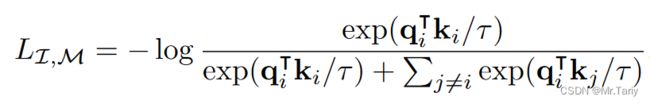
它的主要目标是通过最大化正样本对的概率来学习有用的特征表示。这个概率是通过与一些负样本对(noise samples,噪声样本,又名负样本)进行对比来估计的。
在这个公式里, q i q_i qi和 k j k_j kj用于表示负样本对,通过计算正样本占正负总样本对数的概率,通过损失函数最大化该概率,使模型能够学习到如何将其他模态对齐到图像模态。
在实际训练过程中,用的是该损失函数的对称形式, l o s s loss loss = L I , M + L M , I L_{I,M} + L_{M,I} LI,M+LM,I,用于同时学习图像到该模态,以及该模态到图像的对齐。
通过这种学习方式,最终能够隐式学习到模态 ( M 1 , M 2 ) (M_1,M_2) (M1,M2)的嵌入空间。
3.3实现细节
1.编码方案
对于文本,使用CLIP中的文本编码器。
对于图像,使用CLIP中的Vision Transformer编码,即ViT。
由于已有现成的从大量图像文本数据中预训练的模型OpenCLIP,因此将直接采用OpenCLIP的预训练好的文本和图像编码器,并且在训练ImageBind时,将冻结这两个编码器。
对于视频,使用ViT进行编码,临时增加了图像块投影层,并从2秒视频中采样2帧进行编码。
对于音频,将以16kHz采样的2秒音频转换为包含128个Mel频谱图频道的声谱图。由于声谱图也是一个类似于图像的二维信号,因此使用了一个ViT模型进行编码,其中图像块的大小为16,步幅为10。
对于IMU,提取了由X、Y和Z轴上的加速度计和陀螺仪测量组成的IMU信号。从5秒的视频剪辑中采样了2,000个时间步的IMU读数,这些读数通过一个卷积核大小为8的一维卷积进行投影,随后送入Transformer(这里采用CLIP模型的text encoder结构)中进行编码。
对于热成像图和深度图像,将其看作chanel为1的二维图片,分别送入ViT-B和VIT-S中进行编码。
最后在每个模态编码器后加一个线性投影层,将每个模态的编码转为固定的维度 d d d。
2.数据集来源
(video,audio)视频,音频对来自于Audioset。
(image,depth)图像,深度图对来自于SUN RGB-D。
(image, thermal)图像,热力图对来自于LLVIP。
(video, IMU)视频,IMU对来自于Ego4D。
由于LLVIP和SUN RGB-D数据集样本较少,因此复制了50次用于训练。
4.Experiments
4.1强大的zero-shot分类能力
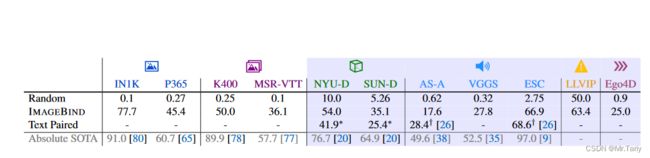
如上表所示,Random对表中不同数据集进行随机分类,Text Paired表示使用专门的文本与数据集对应的模态进行对比学习训练的zero-shot性能表现,ImageBind表示在表中各数据集上做zero-shot分类任务上的结果,Absolute SOTA表示在特定数据集上专门有监督训练的最好模型,可以看出ImageBind使用图像绑定了其他模态进行对比学习出的嵌入空间,能够隐式学习到文本和其他模态的嵌入空间,从而能够涌现出zero-shot的分类能力。在深度图像集NYU-D和SUN-D上,ImageBind的zero-shot分类性能超过了专门作Text Paired对比学习的性能。并且在一些数据集上,ImageBind的性能可以与SOTA模型相比。
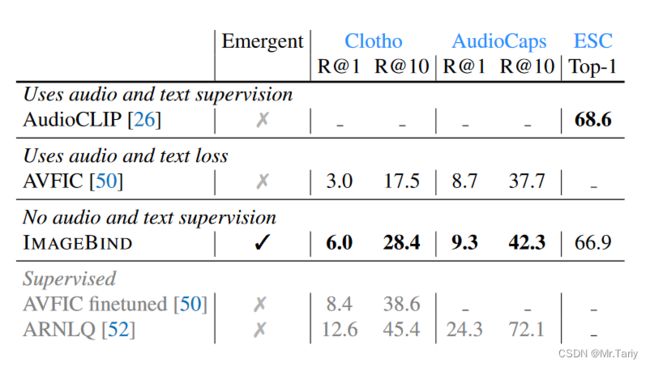
本文将ImageBind与先前的零样本音频检索和音频分类工作进行了比较。
在Clotho和AudioCaps音频文本检索数据集上,ImageBind的性能表现两倍于之前的模型AVFIC,在ESC音频分类数据集上,ImageBind在没有专门学习音频到文本的嵌入空间的前提下的性能与专门作对比学习训练的AudioCLIP的性能相当。
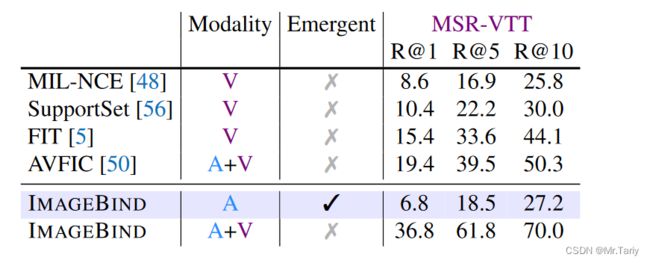
在MSR-VTT 1K-A数据集上,本文进行了文本到音频和视频的检索性能实验。在只提供音频信息时,ImageBind就涌现出强大的零样本检索能力,和之前的工作MIL-NCE模型的性能相当。在同时提供音频和视频信息时,ImageBind的检索能力超过了以往所有作视频检索任务的模型。
4.2 少样本分类能力
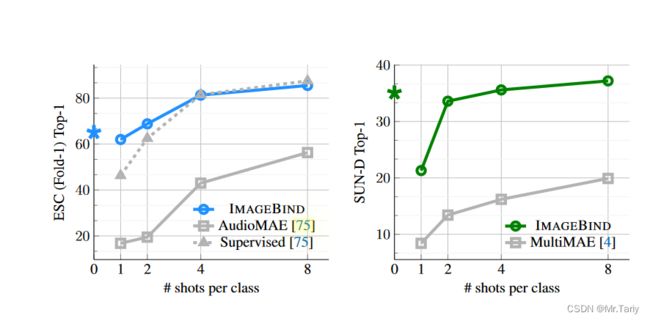
如上图所示,本文进行了音频和深度图像的少样本分类任务的性能实验。在对ImageBind作少样本学习时,只训练它的分类头。
在左图中,ImageBind的性能远远超过作自监督学习的AudioMAE模型,并且在之学习了2个样本后,ImageBind的性能就已经和做有监督学习的AudioMAE模型的性能相当。
在右图中,ImageBind与使用图像、深度和语义分割掩模进行训练的MultiMAE模型进行比较。IMAGEBIND在少样本深度图像分类任务上的性能远远优于MultiMAE。
4.3 模态组合的应用

如上图所示,使用水果的图像加鸟叫的声音,就可以使用ImageBind检索出鸟在果树上的图片。

简单地将ImageBind的音频编码器替换基于CLIP的 目标检测模型的文本prompt编码器,就可以使其成为可通过音频作为prompt的目标检测模型,并且不需要重新训练。如上图所示,给一段冲浪的声音和狗叫的声音,并一张小狗在冲浪的图片,就可以让目标检测框出小狗和冲浪板。
5.Ablation Study
5.1消融实验设置
在消融实验中,本文用VIT-B对音频,深度图以及热力图模态进行编码,并且训练了16个epochs。对于IMU模态,使用6层宽度为512维的轻量级的编码器,并采用8个注意力头进行训练,训练了8个epochs。图像和文本的编码器使用CLIP预训练模型的编码器进行初始化。
5.2针对图像编码器的尺寸实验
在ImageBind中,核心思路就是以图像为中心绑定其他所有模态,隐式学习一个所有模态的联合嵌入空间,因此本文认为有必要研究一下图像编码器对涌现出的零样本能力的作用。
在本文中,针对不同尺寸的图像编码器,分别采用了预训练CLIP模型的VIT-B和VIT-L以及VIT-H编码器,为了设置对照实验,其他模态的编码器将保持固定尺寸,即VIT-B。

如上图所示,对于深度图像以及音频图像分类,采用VIT-H对图像进行编码比采用VIT-B的性能,分别提升了7%和4%的性能(在图中分别是NYU-D以及ESC FOLD-1数据集)。因此,本文认为更强大的图像特征将能够给本模型带来非图像特征识别的性能提升,例如更换了更强大的编码器VIT-H,将能够提升识别音频和深度图像的性能。
5.3针对训练过程的调整实验
1.不同的温度系数的影响
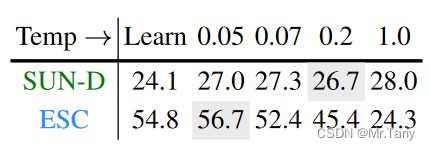
在上图中,针对不同温度系数 τ τ τ进行横向比较,最左侧的固定值 τ τ τ设为0.7,与其他温度系数进行对比。对于深度图像模态的训练,较高的温度系数 τ τ τ效果更好,而对于音频模态,较低的温度系数 τ τ τ效果最佳。
2.不同投影头的影响
在本文中将投影头的全连接层换为768 hidden dimensions的多层感知机进行对照实验。

结果表明,针对每个模态的投影头采用全连接层比较好。
3.训练epochs大小的影响

结果表明,采用越大的epochs会训练出更好的性能。
4.数据增强
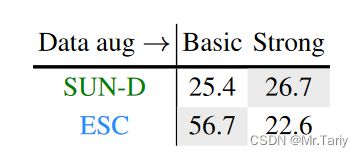
训练过程中,使用基本的数据增强技术(如裁剪、颜色抖动)或者更强的数据增强技术。数据增强有助于在使用SUN RGB-D深度图像数据集中的进行训练时提高分类的性能。然而,对于音频任务,对视频进行数据增强使任务变得复杂,导致模型无法进行有效学习,ESC音频识别任务的性能显著下降了34%。
5.batch size对不同模态的影响

如表所示,根据相应的预训练数据集的大小和复杂性选择合适的batch size将会带来比较好的性能提升。
6.将ImageBind作为评估预训练模型的工具
这是一个比较有趣的想法,文中使用预训练模型DINO和DeiT来初始化图像编码器,其他模态的编码器不变。与有监督的DeiT模型相比,自监督学习的DINO模型在深度和音频模态上的零样本分类性能更好。ImgeBind可以作为一个评估多模态性能的工具,用来评估采用视觉模型作为图像编码器后在多模态应用中的性能表现。
6. Discussion and Limitations
ImageBind想法简单清晰,只使用图像对齐其他模态就可以训练一个联合嵌入空间。通过跨模态检索和基于文本的零样本分类任务进行了性能衡量实验。证明了该方法的在多模态学习的有效性。
目前还有很多改进方法:
1.可以再对齐其他模态来改进模型性能,例如可以将文本与音频进行对比学习,学习一个更好的文本与音频的嵌入空间。
2.没有针对不同下游任务进行特定的训练,性能不如特定领域的专家模型。所以未来的研究可能从事于将该想法通用化到每个下游任务,例如多模态检测等等。
最后,本文提出了一种新的多模态评估概念,将一种模态的预训练模型嵌入到ImageBind的对应模态的编码器上,来评估该模态的预训练模型应用到多模态任务上的性能。