如何运用yolov5训练自己的数据(手把手教你学yolo)
在这篇博文中,我们对YOLOv5模型进行微调,用于自定义目标检测的训练和推理。
目录
-
引言: YOLOv5是什么?
-
YOLOv5提供的模型
-
YOLOv5提供的功能
-
使用YOLOv5进行自定义目标检测训练
-
自定义训练的方法 自定义训练代码
-
准备数据集
-
克隆YOLOv5存储库
-
训练小模型(yolov5s)
-
训练YOLOv5中型模型
-
冻结层训练中型YOLOv5模型
-
性能比较
-
结论
引言:
深度学习领域在2012年开始快速发展。在那个时候,这个领域还比较独特,编写深度学习程序和软件的人要么是深度学习实践者,要么是在该领域有丰富经验的研究人员,或者是具备优秀编码技能的人。
而现在,仅过去10年左右,情况已经发生了巨大变化,而且变得更好。现在,只需要学习了几周的学生就可以用不到20行代码训练一个神经网络模型。而且,这不仅仅是在基准数据集上进行训练,我们可以使用一些最好的模型来训练自定义数据集。不相信吗?好的,那么我们就在这篇文章中使用YOLOV5进行自定义目标检测训练,来证明这一点。
YOLOv5是什么?
如果你在机器学习和深度学习领域已经有一段时间了,很有可能你已经听说过YOLO。YOLO是You Only Look Once的缩写。它是一系列基于单阶段深度学习的目标检测器。它们能够以超过实时的速度进行目标检测,并具有最先进的准确性。
在Darknet框架中,官方发布了四个版本。
YOLOv5是一种用于目标检测的深度学习模型。它是YOLO(You Only Look Once)系列的下一代版本,采用了PyTorch框架,并由Ultralytics组织在GitHub上开发。YOLOv5包含了多种不同大小和准确性的模型,适用于各种场景和设备。
YOLOv5一共有五个模型,
包括:
- YOLOv5n:最小的nano模型,适用于边缘设备、物联网设备和具有OpenCV DNN支持的环境。
- YOLOv5s:小型模型,适合在CPU上进行推断。
- YOLOv5m:中等大小的模型,是速度和准确性之间的平衡点,适用于许多数据集和训练任务。
- YOLOv5l:大型模型,适用于需要检测较小物体的数据集。
- YOLOv5x:最大的模型,拥有最高的mAP指标,但相对较慢,参数数量为86.7百万。
使用YOLOv5进行自定义目标检测训练的方法如下:
- 准备数据集:包括标注好的图像和对应的标签文件。
- 克隆YOLOv5仓库:从GitHub上获取YOLOv5代码和预训练模型。
- 使用训练代码:根据需要选择合适的模型进行训练,并设置训练参数和路径。
- 运行训练:执行训练代码开始模型训练,可以根据需求选择使用GPU或CPU进行训练。
- 检查性能:比较不同模型的mAP、FPS和推断时间,评估训练结果。
总之,YOLOv5是一种强大的目标检测模型,在深度学习领域有着广泛的应用。它提供了多个模型可供选择,可以根据需求进行定制化训练,并能在不同设备上进行高效的目标检测。
训练自己的数据
具体来说,本文提到了使用YOLOv5进行自定义目标检测训练的步骤,并使用了Vehicle-OpenImages数据集作为示例。
mosaic数据增强

数据集包含439张用于训练的图像,125张用于验证,以及63张用于测试。但在本文中,我们只会使用训练和验证集。在继续之前,这里有几张图像,上面画有真实框的标注。

自定义训练的方法
让我们看一下使用YOLOv5进行自定义训练时我们将涵盖的内容。
我们将从训练小型YOLOv5模型开始。
然后我们将训练中型模型,并与小型模型进行比较,看是否有改进。
接下来,我们将冻结中型模型的几层,然后再次训练模型。
我们将在上述所有情况下进行推断,并比较推断视频过程中的mAP指标和FPS。
自定义训练代码
让我们开始编码部分。所有的代码都包含在一个Jupyter笔记本中,你可以从下载部分获取。
在这里,我们将介绍所有必要和重要的代码部分。包括:
准备数据集。
按照上面讨论的方法训练三个模型。
性能比较。
对图像和视频进行推断。
让我们仔细研究代码的所有重要部分,从导入我们在笔记本中使用的模块和库开始。
准备数据集 下一步是下载和准备数据集。我们需要一个简单的辅助函数来下载数据集并解压
if not os.path.exists('train'):#论文辅导、代码获取,作业帮助Qq——1309399183
!curl -L "https://public.roboflow.com/ds/xKLV14HbTF?key=aJzo7msVta" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
dirs = ['train', 'valid', 'test']
for i, dir_name in enumerate(dirs):
all_image_names = sorted(os.listdir(f"{dir_name}/images/"))
for j, image_name in enumerate(all_image_names):
if (j % 2) == 0:
file_name = image_name.split('.jpg')[0]
os.remove(f"{dir_name}/images/{image_name}")
os.remove(f"{dir_name}/labels/{file_name}.txt")
数据结构如下
├── test
│ ├── images
│ └── labels
├── train
│ ├── images
│ ├── labels
│ └── labels.cache
├── valid
│ ├── images
│ ├── labels
│ └── labels.cache
├── data.yaml
├── README.dataset.txt
└── README.roboflow.txt
配置文件YAML设置
YOLOv5训练中最重要的一个属性可能是数据集的YAML文件。该文件包含训练和验证数据的路径,以及类别名称。在执行训练脚本时,我们需要将此文件路径作为参数提供,以便脚本可以识别图像路径、标签路径和类别名称。数据集已经包含了这个文件。以下是我们在这里用于训练的data.yaml文件的内容
train: ../train/images
val: ../valid/images
nc: 5
names: ['Ambulance', 'Bus', 'Car', 'Motorcycle', 'Truck']
克隆代码
为了使用YOLOv5代码库的任何功能,我们需要克隆他们的存储库。以下几行代码克隆了存储库,进入yolov5目录,并安装我们可能需要运行代码的所有要求
if not os.path.exists('yolov5'):
!git clone https://ultralytics/yolov5.git
%cd yolov5/
!pip install -r requirements.txt
训练
现在,让我们一起了解训练脚本的所有参数。
–data:该参数接受我们之前创建的数据集YAML文件的路径。在我们的情况下,它是当前目录的上一级目录,因此为 …/data.yaml。
–weights:该参数接受我们想要用于训练的模型。由于我们使用YOLOv5系列中的小型模型,因此值为 yolov5s.pt。
–img:我们还可以在训练时控制图像大小。在将图像馈送到网络之前,图像将被调整为此值。我们将它们调整为640个像素,这也是最常用的尺寸之一。
–epochs:该参数用于指定训练的epoch数。由于我们已经在上面的EPOCHS变量中指定了epoch数,因此我们在此提供该变量。
–batch-size:这是在训练时将加载到一个批次中的样本数。虽然这里的值为16,但你可以根据可用的GPU内存进行更改。
–name:我们可以提供一个自定义目录名称,其中将保存所有结果。在我们的情况下,我们提供了刚刚通过调用set_res_dir函数创建的路径。
训练结果
Images Labels P R [email protected] mAP@
all 125 227 0.149 0.211 0.0944 0.0305
...
Epoch gpu_mem box obj cls labels img_size
24/24 3.94G 0.03121 0.01958 0.009307 21 640: 100%|███
Class Images Labels P R [email protected] mAP@
all 125 227 0.655 0.515 0.587 0.41
25 epochs completed in 0.190 hours.
Optimizer stripped from runs/train/results_4/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/results_4/weights/best.pt, 14.5MB
Validating runs/train/results_4/weights/best.pt...
Fusing layers...
Model summary: 213 layers, 7023610 parameters, 0 gradients
Class Images Labels P R [email protected] mAP@
all 125 227 0.514 0.646 0.588 0.41
Ambulance 125 32 0.541 0.812 0.741 0.605
Bus 125 23 0.586 0.739 0.714 0.502
Car 125 119 0.521 0.58 0.531 0.34
Motorcycle 125 23 0.668 0.699 0.659 0.397
Truck 125 30 0.254 0.4 0.296 0.20
评价指标展示

推理结果展示
在训练过程中,代码库会将每个epoch的验证批次的预测保存到结果目录中。在我们查看这些预测之前,让我们编写一个辅助函数来找到结果目录中的所有验证预测并展示它们
#论文辅导、代码获取,作业帮助Qq——1309399183
def show_valid_results(RES_DIR):
!ls runs/train/{RES_DIR}
EXP_PATH = f"runs/train/{RES_DIR}"
validation_pred_images = glob.glob(f"{EXP_PATH}/*_pred.jpg")
print(validation_pred_images)
for pred_image in validation_pred_images:
image = cv2.imread(pred_image)
plt.figure(figsize=(19, 16))
plt.imshow(image[:, :, ::-1])
plt.axis('off')
plt.show()

mAP比较
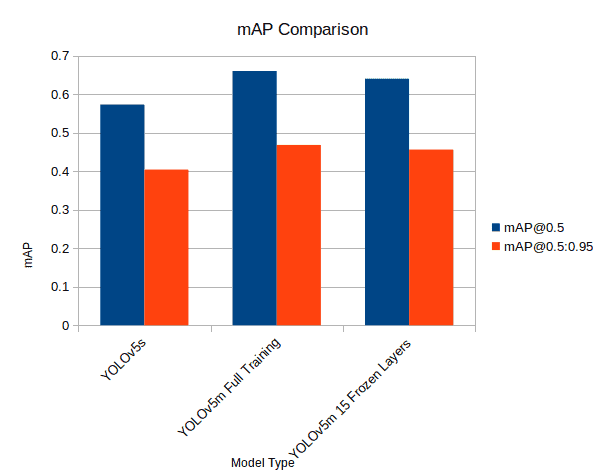
结论
在本文中,我们进行了许多使用YOLOv5进行训练和推理的实验。我们从使用YOLOv5小型模型进行自定义对象检测训练和推理开始。然后,我们转向YOLOv5中型模型的训练,还尝试了部分冻结层的中型模型训练。本文让我们深入了解了YOLOv5代码库的工作原理,并了解了不同模型之间的性能和速度差异。
论文辅导、代码获取,作业帮助Qq——1309399183
[外链图片转存中…(img-MOcL0kob-1695526726081)]
结论
在本文中,我们进行了许多使用YOLOv5进行训练和推理的实验。我们从使用YOLOv5小型模型进行自定义对象检测训练和推理开始。然后,我们转向YOLOv5中型模型的训练,还尝试了部分冻结层的中型模型训练。本文让我们深入了解了YOLOv5代码库的工作原理,并了解了不同模型之间的性能和速度差异。
论文辅导、代码获取,作业帮助Qq——1309399183
鉴于本文中进行的大量实验,你是否注意到了什么?除了一些通用的Python函数外,我们没有编写任何深度学习代码。这表明深度学习领域变得越来越易于访问,希望未来也会朝着同样的方向发展。如果你尝试在自己的数据集上进行自定义训练并发现有趣的结果,请不要忘记在评论区分享你的成果。