数据湖在爱奇艺数据中台的应用
01
我们眼中的数据湖
作为爱奇艺的数据中台团队,我们的核心任务是管理和服务公司内的大量数据资产。在实施数据治理的过程中,我们不断吸收新的理念,引入尖端的工具,以精细化我们的数据体系管理。
“数据湖”作为近年来数据领域广泛热议的概念,其技术层面也受到了业界的广泛关注。我们的团队对相关数据湖的理论和实践进行了深入研究,我们认为,数据湖不仅是一种治理数据的全新视角,更是一种集成和处理数据的极具前景的技术。
02
数据湖是一种数据治理的思想
实施数据湖的主旨,在于提供一个高效的存储和管理方案,将数据的易用性和可用性提升至新的高度。

数据湖作为一种创新的数据治理理念,其价值主要体现在以下两方面:
1. 能够全面储存所有数据,无论这些数据是否正在被使用,或是否暂时无法使用,都可以确保在需要时能轻松找到所需信息,提高工作效率;
2. 数据湖中的数据经过了科学的管理和组织,使得用户可以更加方便地自助查找和使用数据。这种管理模式大大减少了数据工程师的参与程度,用户可以自行完成数据查找与使用的任务,从而节省了大量的人力资源
为了更有效地管理各类数据,数据湖根据不同的特性和需求将数据划分为四个核心领域,分别为原始区、产品区、工作区和敏感区:
原始区:这一区域专注于满足数据工程师和专业数据科学家的需求,其主要目的是存储未经处理的原始数据。当必要时,也可以对其进行局部开放,以支持特定的访问需求。
产品区:产品区内的数据多数经过数据工程师、数据科学家和业务分析师的加工和处理,以确保数据的标准化和高度治理。这类数据通常被广泛应用于业务报告、数据分析以及机器学习等领域。
工作区:工作区域主要用于存储各类数据工作者生成的中间数据。在这里,用户需自行负责管理其数据,以支持灵活的数据探索和实验,以满足不同用户群体的需求。
敏感区:敏感区专注于安全性,主要用于存储敏感数据,如个人身份信息、财务数据以及法律合规数据等。这一领域受到最高级别的访问控制和安全保护。
通过这一划分方式,数据湖能够更好地管理不同类型的数据,同时提供便捷的数据访问和利用,以满足各种需求。
03
数据湖的数据治理思想在数据中台的应用
数据中台的目标是解决由于数据激增和业务扩大而引发的统计口径不一致、重复开发、指标开发需求响应慢、数据质量低下和数据成本高等问题。
数据中台和数据湖的目标有一致性。通过结合数据湖的理念,对数据中台的数据体系和整体架构进行了优化升级。
在数据中台建设的初级阶段,我们对公司的数据仓库体系进行了整合,对业务进行了深入研究,整理了已有的字段和维度信息,归纳出了一致性维度,并建立了统一的指标体系,制定了数据仓库建设规范。根据该规范,我们构建了统一数据仓库的原始数据层(ODS)、明细数据层(DWD)、聚合数据层(MID),并建立了设备库,其中包括累积设备库和新增设备库。在统一数据仓库的基础上,数据团队根据不同的分析统计方向和业务需求,构建了主题数据仓库和业务市场。主题数据仓库和业务市场包括进一步处理的明细数据、聚合数据以及应用层数据表,数据应用层使用这些数据向用户提供不同的服务。

在统一的数据仓库体系中,原始数据层及以下是不对外开放的,用户只能使用数据工程师处理加工后的数据,因此难免会造成一些数据细节的损失。在日常工作中,常常会有具备数据分析能力的用户希望访问底层原始数据,进行个性化的分析或者问题排查。
而数据湖的数据管理理念能够有效地解决这个问题。在引入数据湖的数据治理思想后,我们对再次已有的数据资源进行了梳理和整合,对数据的元数据进行了丰富和扩充,并构建了一个专门用于管理元数据中心的数据元数据中心。

在引入数据湖理念进行数据治理后,我们将原始数据层以及其他原始数据(例如原始日志文件)归置到原始数据区,有数据处理能力的用户可以申请权限使用该区域的数据。
统一数仓的明细层、聚合层以及主题数仓、业务集市归置在产品区,这些数据已经经过数据团队的数据工程师加工处理作为最终数据成品提供给用户使用,该区域的数据经过数据治理,因此数据质量有所保障。
我们还为敏感数据划定了敏感区,重点管控访问权限。
日常由用户及数据开发人员产生的临时表或个人表归置在临时区,这些数据表由用户自行负责,可以有条件的开放给其他用户使用。
通过元数据中心维护各数据的元数据,包含表信息、字段信息以及字段所对应的维度和指标。同时,我们还维护数据血缘,包括表级别和字段级别的血缘关系。
通过数据资产中心维护数据的资产特性,包括针对数据级别、敏感性和权限的管理。
为方便用户更好地自助使用数据,我们在应用层提供了数据图谱作为数据目录供用户查询数据,包括数据的用途、维度、指标、血缘等元数据。同时,该平台也可作为权限申请的一个入口。
此外,我们还提供自助分析平台为数据用户提供自助分析的能力。
在优化数据体系的同时,我们也结合数据湖思想,对数据中台架构进行了升级。
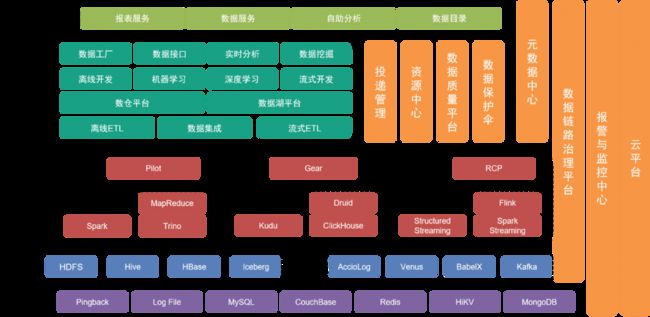
底层为数据层,包括各种数据来源,如Pingback数据,主要用于收集用户行为,业务数据则存储在各种关系型数据库和NoSQL数据库。这些数据通过传输层的不同收集工具,存储在存储层。
数据层之上是存储层,主要基于HDFS这个分布式文件系统来存储原始文件。其他结构或非结构数据则存储在Hive、Iceberg或HBase中。
再往上是计算层,主要使用离线引擎Pilot驱动Spark或Trino进行离线计算,同时使用调度引擎Gear离线工作流引擎进行定时工作流调度。而RCP实时计算平台则负责调度流式计算。经过几轮迭代,目前流式计算主要使用Flink作为计算引擎。
在计算层之上的开发层,通过对计算层和传输层的各个服务模块进一步封装,提供了用来开发离线数据处理工作流、对数据进行集成,开发实时处理工作流,开发机器学习工程实现等完成开发工作的工具套件和中间服务。其中数据湖平台对数据湖中各个数据文件与数据表的信息进行管理,数仓平台则对数仓数据模型、物理模型、维度、指标等信息进行管理。
同时,我们在纵向提供多种管理工具和服务,比如投递管理工具管理Pingback埋点的规范、字段、字典、投递时机等元信息;元数据中心、资源中心等模块用来维护数据表或数据文件的元信息,以及保障数据安全;数据质量中心和链路治理平台则监控数据质量和数据链路生产情况,及时通知相关团队进行保障,结合已有预案对线上问题和故障进行快速响应。
底层服务由云服务团队提供私有云和公有云支持。
架构上层则提供数据图谱作为数据目录供用户寻找所需要的数据。此外,我们提供魔镜、北斗等自助应用,满足不同层次的用户自助进行数据工作的需求。
经过改造后的整个架构体系,数据的集成和管理更加灵活且全面。我们通过优化自助工具降低用户使用门槛,满足不同层次用户的需求,提高数据使用效率,提升数据价值。
04
数据湖技术在数据中台的应用
广义上,数据湖是一种数据治理的理念,狭义上,数据湖也指代一种数据处理技术。
数据湖技术涵盖了数据表的存储格式以及数据在入湖后的处理技术。
数据湖中的存储解决方案,业界主要有三种:Delta Lake、Hudi和Iceberg,三者对比如下:
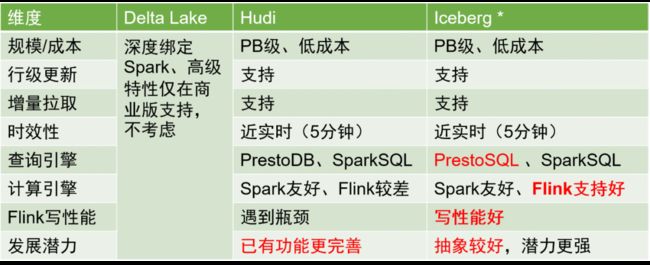
在综合考量后,我们选择了Iceberg作为数据表的存储格式。
Iceberg是一种表存储格式,组织底层文件系统或对象存储的数据文件。
以下是Iceberg与Hive的主要对比:

与Hive表相比,Iceberg表具有显著的优势,因为它能够更好地支持行级更新,数据时效性可以提高到分钟级别。这在数据处理中具有重要意义,因为数据及时性的提升可以极大地改进数据处理ETL的效率。
因此,我们可以方便地对现有的Lambda架构进行改造,实现流批一体架构:

在引入数据湖技术之前,我们采用离线处理与实时处理相结合的方式,提供离线数据仓库和实时数据仓库。
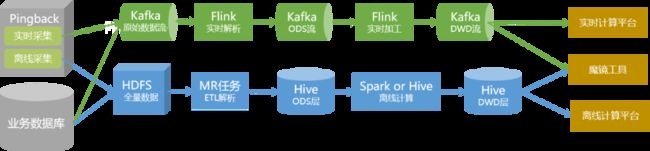
全量数据通过传统的离线解析处理方式,构建成为数仓数据,并以Hive表的形式存储在集群中。对于实时性要求高的数据,我们单独通过实时链路生产,并以Kafka中的Topic的形式提供给用户使用。
然而,这种架构存在以下问题:
实时和离线两条通路需要维护两套不同的代码逻辑。当处理逻辑发生变化时,实时和离线两条通路都需要同时更新,否则会出现数据不一致的情况。
离线链路的小时级更新以及1小时左右的延迟,使得在00:01的数据可能在02:00才能查询到。对于部分实时性要求较高的下游业务来说,这是无法接受的,因此需要支持实时链路。
虽然实时链路的实时性可以达到秒级,但其成本较高。对于大多数使用者来说,五分钟级别的更新已经足够满足需求。同时,Kafka流的消费不如直接操作数据表方便。
针对这些问题,通过使用Iceberg表与流批一体化的数据处理方式,可以较好地解决。
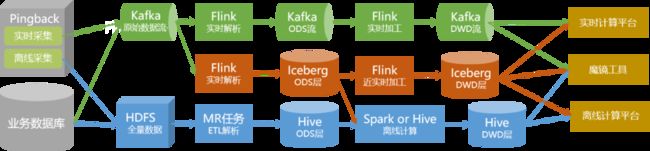
优化过程中,我们主要对ODS层和DWD层表进行Iceberg改造,并将解析和数据处理加工重构为Flink任务。
为确保改造过程中,数据生产的稳定性和准确性不受影响,我们采取以下措施:
1. 首先从非核心数据着手进行切换。根据实际业务情况,我们以QOS投递和自定义投递作为试点。
2. 通过对离线解析逻辑进行抽象处理,形成统一的Pingback解析入库SDK,实现了实时与离线的统一部署,使代码更加规范化。
3. Iceberg表以及新的生产流程部署完成后,我们进行了两个月双链路并行运行,并对数据进行常规化对比监测。
4. 确认数据和生产都没有问题后,我们对上层进行无感知切换。
5. 对于核心数据相关的启动、播放数据,我们将在整体验证稳定后再进行流批一体改造。
改造后,收益如下:
1. qos和自定义投递数据链路整体实现了近实时化。小时级延迟的数据达到五分钟级更新。
2. 除特殊情况外,流批一体链路已可以满足实时需求。因此,我们可以下线与QOS和自定义相关的既有实时链路和离线解析链路,从而节省资源。
通过对数据处理的改造,未来一段时间内,我们的数据链路会如下图所示:

05
后续规划
对于数据湖在数据中台应用的后续规划,主要从两方面:
从架构层面,会继续细化各个模块的开发,让数据中台提供的数据与服务更加全面,更加易用,让不同的用户都可以方便地自助使用;
在技术层面,我们将继续对数据链路进行流批一体改造,同时继续积极引入合适的数据技术,提高数据的生产和使用效率,降低生产成本。
参考文献
1. Dixon, James (14 October 2010). "Pentaho, Hadoop, and Data Lakes". James Dixon’s Blog.
2. Iceberg: A modern table format for big data
3. Apache Iceberg: An Architectural Look Under the Covers
4. Iceberg Table Spec
5. Apache Flink
6. Alex Gorelik. The Enterprise Big Data Lake.
也许你还想看
爱奇艺数据湖实战
爱奇艺数据湖实战 - 广告数据湖应用
爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进