【转载】Huggingface NLP笔记
https://zhuanlan.zhihu.com/p/412290925
笔记1:直接使用pipeline,是个人就能玩NLP
直接使用Pipeline工具做NLP任务
Pipeline是Huggingface的一个基本工具,可以理解为一个端到端(end-to-end)的一键调用Transformer模型的工具。它具备了数据预处理、模型处理、模型输出后处理等步骤,可以直接输入原始数据,然后给出预测结果,十分方便。
给定一个任务之后,pipeline会自动调用一个预训练好的模型,然后根据你给的输入执行下面三个步骤:
- 预处理输入文本,让它可被模型读取
- 模型处理
- 模型输出的后处理,让预测结果可读
一个例子如下:
from transformers import pipeline
clf = pipeline('sentiment-analysis')
clf('Haha, today is a nice day!')
输出:
[{'label': 'POSITIVE', 'score': 0.9998709559440613}]
还可以直接接受多个句子,一起预测:
clf(['good','nice','bad'])
输出:
[{'label': 'POSITIVE', 'score': 0.9998160600662231},
{'label': 'POSITIVE', 'score': 0.9998552799224854},
{'label': 'NEGATIVE', 'score': 0.999782383441925}]
pipeline支持的task包括:
"feature-extraction": will return a FeatureExtractionPipeline."text-classification": will return a TextClassificationPipeline."sentiment-analysis": (alias of “text-classification”) will return a TextClassificationPipeline."token-classification": will return a TokenClassificationPipeline."ner"(alias of “token-classification”): will return a TokenClassificationPipeline."question-answering": will return a QuestionAnsweringPipeline."fill-mask": will return a FillMaskPipeline."summarization": will return a SummarizationPipeline."translation_xx_to_yy": will return a TranslationPipeline."text2text-generation": will return a Text2TextGenerationPipeline."text-generation": will return a TextGenerationPipeline."zero-shot-classification": will return a ZeroShotClassificationPipeline."conversational": will return a ConversationalPipeline.
下面可以可以来试试用pipeline直接来做一些任务:
Have a try: Zero-shot-classification
零样本学习,就是训练一个可以预测任何标签的模型,这些标签可以不出现在训练集中。
一种零样本学习的方法,就是通过NLI(文本蕴含)任务,训练一个推理模型,比如这个例子:
premise = 'Who are you voting for in 2020?'
hypothesis = 'This text is about politics.'
上面有一个前提(premise)和一个假设(hypothesis),NLI任务就是去预测,在这个premise下,hypothesis是否成立。
NLI (natural language inference)任务:it classifies if two sentences are logically linked across three labels (contradiction, neutral, entailment).
通过这样的训练,我们可以**直接把hypothesis中的politics换成其他词儿,就可以实现zero-shot-learning了。而Huggingface pipeline中的零样本学习,使用的就是在NLI任务上预训练好的模型**。
clf = pipeline('zero-shot-classification')
clf(sequences=["A helicopter is flying in the sky",
"A bird is flying in the sky"],
candidate_labels=['animal','machine']) # labels可以完全自定义
输出:
[{'sequence': 'A helicopter is flying in the sky',
'labels': ['machine', 'animal'],
'scores': [0.9938627481460571, 0.006137280724942684]},
{'sequence': 'A bird is flying in the sky',
'labels': ['animal', 'machine'],
'scores': [0.9987970590591431, 0.0012029369827359915]}]
参考阅读:
- 官方 Zero-shot-classification Pipeline文档:https://huggingface.co/transformers/main_classes/pipelines.html#transformers.ZeroShotClassificationPipeline
- 零样本学习简介:https://mp.weixin.qq.com/s/6aBz
Have a try: Text Generation
Huggingface pipeline**默认的模型都是英文的**,比如对于text generation默认使用gpt2,但我们也可以指定Huggingface Hub上其他的text generation模型,这里我找到一个中文的:
generator = pipeline('text-generation', model='liam168/chat-DialoGPT-small-zh')
给一个初始词句开始生产:
generator('上午')
输出:
[{'generated_text': '上午上班吧'}]
Have a try: Mask Filling
unmasker = pipeline('fill-mask')
unmasker('What the ?' , top_k=3) # 注意不同的模型,MASK token可能不一样,不一定都是 输出:
[{'sequence': 'What the heck?',
'score': 0.3783760964870453,
'token': 17835,
'token_str': ' heck'},
{'sequence': 'What the hell?',
'score': 0.32931089401245117,
'token': 7105,
'token_str': ' hell'},
{'sequence': 'What the fuck?',
'score': 0.14645449817180634,
'token': 26536,
'token_str': ' fuck'}]
其他Tasks
还有很多其他的pipeline,比如NER,比如summarization,这里就不一一尝试了。
想看官方实例的可以参见: https://huggingface.co/course/chapter1/3?fw=pt
总之,我们可以看出,Huggingface提供的pipeline接口,就是一个**”拿来即用“的端到端的接口,只要Huggingface Hub上有对应的模型**,我们几行代码就可以直接拿来做任务了,真是造福大众啊!
NLP笔记2:一文看清Transformer大家族的三股势力
一文看清Transformer大家族的三股势力
1. Transformer结构
Transformer结构最初就是在大2017年名鼎鼎的《Attention Is All You Need》论文中提出的,最开始是用于机器翻译任务。
这里先简单回顾一下Transformer的基本结构:
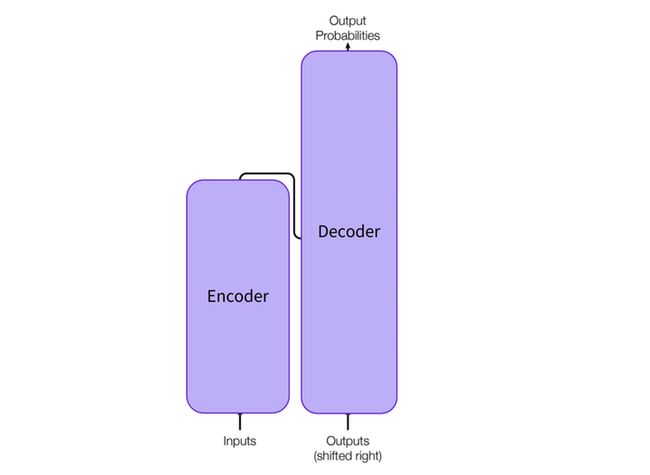
- 左边是encoder,用于对输入的sequence进行表示,得到一个很好特征向量。
- 右边是decoder,利用encoder得到的特征,以及原始的输入,进行新的sequence的生成。
encoder、decoder既可以单独使用,又可以再一起使用,因此,基于Transformer的模型可以分为三大类:
- Encoder-only
- Decoder-only
- Encoder-Decoder
2. Transformer家族及三股势力
随后各种基于Transformer结构的模型就如雨后春笋般涌现出来,教程中有一张图展示了一些主要模型的时间轴:
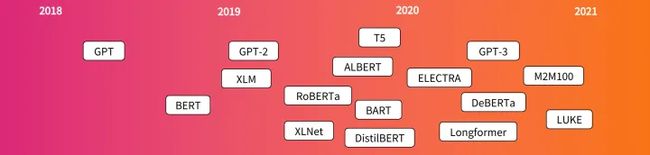
虽然模型多到四只jio都数不过来,但总体上可以分为三个阵营,分别有三个组长:
- 组长1:BERT。组员都是BERT类似的结构,是一类自编码模型。
- 组长2:GPT。组员都是类似GPT的结构,是一类自回归模型。
- 组长3:BART/T5。组员结构都差不多是encoder-decoder模型。
不同的架构,不同的预训练方式,不同的特长
对于Encoder-only的模型,预训练任务通常是==“破坏一个句子,然后让模型去预测或填补”==。例如BERT中使用的就是两个预训练任务就是Masked language modeling和Next sentence prediction。 因此,这类模型擅长进行文本表示,适用于做文本的分类、实体识别、关键信息抽取等任务。
对于Decoder-only的模型,预训练任务通常是Next word prediction,这种方式又被称为Causal language modeling。这个Causal就是“因果”的意思,对于decoder,它**在训练时是无法看到全文的,只能看到前面的信息。 因此这类模型适合做文本生成**任务。
而Seq2seq架构,由于包含了encoder和decoder,所以预训练的目标通常是融合了各自的目标,但通常还会设计一些更加复杂的目标,比如对于T5模型,会把一句话中一片区域的词都mask掉,然后让模型去预测。seq2seq架构的模型,就适合做翻译、对话等需要根据给定输入来生成输出的任务,这跟decoder-only的模型还是有很大差别的。
总结表如下:
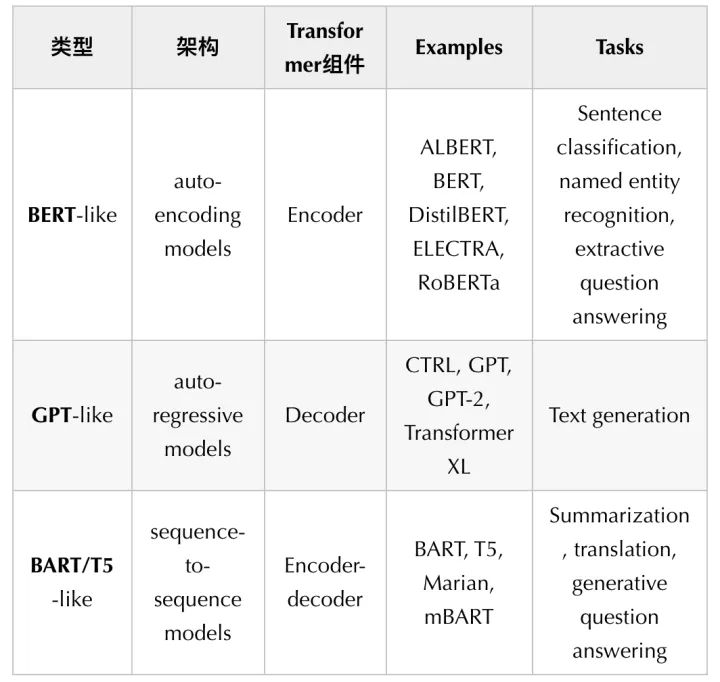
了解了Transformer一系列模型的来龙去脉,我们就可以更好地玩耍Transformer啦!下一集,我们会慢慢深入查看Huggingface transformers库背后的细节,从而更灵活地使用。
NLP笔记3:Pipeline端到端的背后发生了什么
Pipeline端到端的背后发生了什么★★★
在第1集中(Huggingface NLP笔记1:直接使用pipeline,是个人就能玩NLP),我们介绍了直接使用Huggingface的pipeline来轻松使用Transformer处理各种NLP问题,发现太方便了。这一集,我们就把这个pipeline的皮扒开,看看里面到底是怎么一步步处理的。
Pipeline的背后:
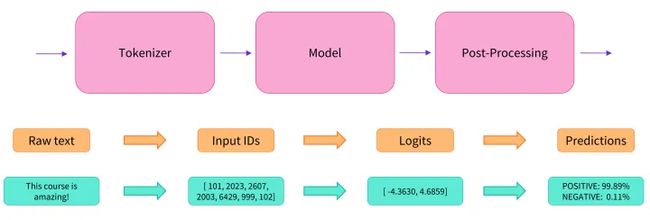
1. Tokenizer
我们使用的tokenizer必须跟对应的模型在预训练时的tokenizer保持一致,也就是词表需要一致【一般一个tokenizer对应一个模型】。
Huggingface中可以**直接指定模型的checkpoint的名字,然后自动下载对应的词表**。
checkpoint
在深度学习中,Checkpoint通常是指在训练过程中定期保存模型的参数和优化器状态等信息的文件。这些Checkpoint文件可以在训练过程中用于恢复模型的状态,也可以用于在训练结束后对模型进行评估和推理。
在TensorFlow中,Checkpoint文件通常包括一个或多个文件,其中包括模型参数的二进制数据和一个元数据文件。元数据文件通常具有类似于“model.ckpt-100.index”或“model.ckpt-100.meta”的命名模式,其中“checkpoint”是命名模式的一部分,表示这是一个模型Checkpoint文件。
具体方式是:
- 使用
AutoTokenizer的from_pretrained方法
tokenizer这个对象可以直接接受参数并输出结果,即它是callable的。具体参数见:
https://huggingface.co/transformers/master/internal/tokenization_utils.html#transformers.tokenization_utils_base.PreTrainedTokenizerBase
主要参数包括:
- text,可以是单条的string,也可以是一个string的list,还可以是list的list
- padding,用于填白
- truncation,用于截断
- max_length,设置最大句长
- return_tensors,设置返回数据类型
from transformers import AutoTokenizer
checkpoint = 'distilbert-base-uncased-finetuned-sst-2-english'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
这段代码使用了Hugging Face Transformers库中的AutoTokenizer模块,从预训练模型’ distilbert-base-uncased-finetuned-sst-2-english '中加载了一个Tokenizer对象。
Tokenizer是将自然语言文本分割成单词或子词(如BPE)并将其转换为计算机可以理解的数字形式(例如,整数或向量)的工具。在自然语言处理任务中,如情感分析、文本分类等,Tokenizer是数据预处理的必要步骤。
’ distilbert-base-uncased-finetuned-sst-2-english '是一个**经过微调(fine-tuned)的基于DistilBERT模型的预训练模型**,用于解决英文情感分析任务(SST-2数据集)。
AutoTokenizer模块从预训练模型中加载了一个预先训练的Tokenizer对象,以便在进行下游任务(如情感分析)时对数据进行预处理。
先看看直接使用tokenizer的结果:
raw_inputs = ['Today is a good day! Woo~~~',
'How about tomorrow?']
tokenizer(raw_inputs)
输出:
{'input_ids': [[101, 2651, 2003, 1037, 2204, 2154, 999, 15854, 1066, 1066, 1066, 102], [101, 2129, 2055, 4826, 1029, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]}
可以加上一个 padding=Ture 参数,让得到的序列长度对齐:
tokenizer(raw_inputs, padding=True)
输出:
{'input_ids': [[101, 2651, 2003, 1037, 2204, 2154, 999, 15854, 1066, 1066, 1066, 102], [101, 2129, 2055, 4826, 1029, 102, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]]}
tokenizer还有**truncation和max_length属性,用于在max_length处截断**:
tokenizer(raw_inputs, padding=True, truncation=True, max_length=7)
输出:
{'input_ids': [[101, 2651, 2003, 1037, 2204, 2154, 102], [101, 2129, 2055, 4826, 1029, 102, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 0]]}
**return_tensors属性**也很重要,用来指定返回的是什么类型的tensors,pt就是pytorch,tf就是tensorflow,np就是numpy:
tokenizer(raw_inputs, padding=True, truncation=True, return_tensors='pt')
输出:
{'input_ids': tensor([[ 101, 2651, 2003, 1037, 2204, 2154, 999, 15854, 1066, 1066,
1066, 102],
[ 101, 2129, 2055, 4826, 1029, 102, 0, 0, 0, 0,
0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]])}
2. Model
也可以通过AutoModel来直接从checkpoint导入模型。
这里导入的模型,是Transformer的基础模型,接受tokenize之后的输入,输出hidden states,即文本的向量表示,是一种上下文表示。
一般情况下tokenize和模型所采用的checkpoint(即为已经训练好了的一些预训练模型)是一致的。
这个向量表示,会有三个维度:
- batch size
- sequence length
- hidden size
from transformers import AutoModel
checkpoint = 'distilbert-base-uncased-finetuned-sst-2-english'
model = AutoModel.from_pretrained(checkpoint)
加载了模型之后,就可以把tokenizer得到的输出,直接输入到model中【outputs = model(**inputs) 】:
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors='pt')
outputs = model(**inputs) # 这里变量前面的**,代表把inputs这个dictionary给分解成一个个参数单独输进去
vars(outputs).keys() # 查看一下输出有哪些属性
输出:
dict_keys(['last_hidden_state', 'hidden_states', 'attentions'])
函数中**的用法:
**在函数中的作用就是把后面紧跟着的这个参数,从一个字典的格式,解压成一个个单独的参数。
回顾一下上面tokenizer的输出,我们发现它是一个包含了input_ids和attention_mask两个key的字典,因此通过**的解压,相当于变成了intput_ids=..., attention_mask=...喂给函数。
我们再来查看一下通过AutoModel加载的DistillBertModel模型的输入: https://huggingface.co/transformers/master/model_doc/distilbert.html#distilbertmodel
可以看到DistillBertModel的直接call的函数是:
forward(input_ids=None, attention_mask=None, ...) 正好跟**inputs后的格式对应上。
就可以看出这种**方式和直接写明参数可以达到同样的效果。
print(outputs.last_hidden_state.shape)
outputs.last_hidden_state
输出
torch.Size([2, 12, 768])
tensor([[[ 0.4627, 0.3042, 0.5431, ..., 0.3706, 1.0033, -0.6074],
[ 0.6100, 0.3093, 0.2038, ..., 0.3788, 0.9370, -0.6439],
[ 0.6514, 0.3185, 0.3855, ..., 0.4152, 1.0199, -0.4450],
...,
[ 0.3674, 0.1380, 1.1619, ..., 0.4976, 0.4758, -0.5896],
[ 0.4182, 0.2503, 1.0898, ..., 0.4745, 0.4042, -0.5444],
[ 1.1614, 0.2516, 0.9561, ..., 0.5742, 0.8437, -0.9604]],
[[ 0.7956, -0.2343, 0.3810, ..., -0.1270, 0.5182, -0.1612],
[ 0.9337, 0.2074, 0.6202, ..., 0.1874, 0.6584, -0.1899],
[ 0.6279, -0.3176, 0.1596, ..., -0.2956, 0.2960, -0.1447],
...,
[ 0.3050, 0.0396, 0.6345, ..., 0.4271, 0.3367, -0.3285],
[ 0.1773, 0.0111, 0.6275, ..., 0.3831, 0.3543, -0.2919],
[ 0.2756, 0.0048, 0.9281, ..., 0.2006, 0.4375, -0.3238]]],
grad_fn=<NativeLayerNormBackward>)
可以看到,输出的shape是torch.Size([2, 12, 768]),三个维度分别是 batch,seq_len和hidden size。
3. Model Heads★
在机器学习中,Model Heads 通常是**指模型的输出层,即最后一个神经网络层**。它的主要作用是将模型学习到的特征映射到预测的目标变量上。
在深度学习中,模型通常由两个部分组成:特征提取器和模型头。特征提取器是由一系列卷积层或全连接层组成的神经网络,它的主要作用是从原始输入数据中提取有用的特征。而模型头则是由一或多个全连接层组成的神经网络,它的作用是将特征映射到预测的目标变量上。
以图像分类为例,特征提取器通常是由一系列卷积层和池化层组成的卷积神经网络,它可以将输入的图像转换为一组特征向量。而模型头则是由一个或多个全连接层组成的神经网络,它将特征向量映射到每个类别的预测概率上。在训练过程中,特征提取器和模型头的参数都会被优化,以最小化预测结果与真实结果之间的差距。
总之,模型头是深度学习模型的一个重要组成部分,它的设计对于模型的预测性能有很大的影响。不同的模型头设计可以适用于不同的任务,比如分类、回归、分割等。
模型头,接在基础模型的后面,用于将hidden states文本表示进一步处理,用于具体的任务。
整体框架图:
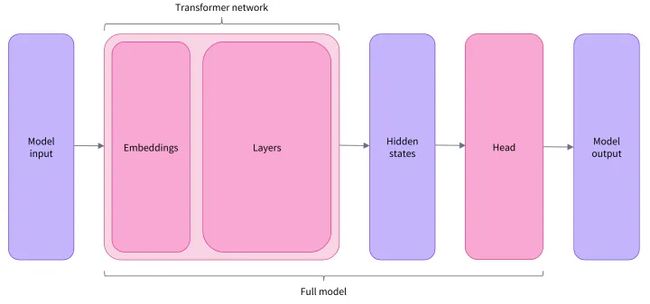
Head**一般是由若干层的线性层**来构成的。
Transformers库中的主要模型架构有:
- *Model (retrieve the hidden states)
- *ForCausalLM
- *ForMaskedLM
- *ForMultipleChoice
- *ForQuestionAnswering
- *ForSequenceClassification
- *ForTokenClassification
- …
单纯的*Model,就是不包含 Head 的模型,而有For*的则是**包含了具体 Head 的**模型。
例如,对于前面的那个做在情感分析上pretrain的checkpoint(distilbert-base-uncased-finetuned-sst-2-english),我们**可以使用包含 SequenceClassification 的Head的模型去加载**,就可以直接得到对应分类问题的logits,而不仅仅是文本向量表示。
在机器学习中,logits 通常指模型的输出层,未经过 softmax 函数或其他激活函数的输出值。Logits 是一个实数向量,每个元素表示模型对于每个可能的类别的预测得分。得分越高,模型越有把握该样本属于该类别。
from transformers import AutoModelForSequenceClassification
clf = AutoModelForSequenceClassification.from_pretrained(checkpoint)
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors='pt')
outputs = clf(**inputs)
print(vars(outputs).keys())
outputs.logits
输出:
dict_keys(['loss', 'logits', 'hidden_states', 'attentions'])
tensor([[-4.2098, 4.6444],
[ 0.6367, -0.3753]], grad_fn=<AddmmBackward>)
从outputs的属性就可以看出,带有Head的Model,跟不带Head的Model,输出的东西是不一样的。
没有Head的Model,输出的是'last_hidden_state', 'hidden_states', 'attentions'这些玩意儿,因为它仅仅是一个表示模型;
有Head的Model,输出的是'loss', 'logits', 'hidden_states', 'attentions'这些玩意儿,有logits,loss这些东西,因为它是一个完整的预测模型了。
可以顺便看看,加了这个 SequenceClassification Head的DistillBertModel的文档,看看其输入和输出:
https://huggingface.co/transformers/master/model_doc/distilbert.html#distilbertforsequenceclassification
可以看到,输入中,我们还可以提供labels,这样就可以直接计算loss了。
4. Post-Processing
后处理主要就是两步:
- 把logits转化成概率值 (用softmax)
- 把**概率值跟具体的标签对应上** (使用模型的config中的id2label)
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1) # dim=-1就是沿着最后一维进行操作
predictions
输出:
tensor([[1.4276e-04, 9.9986e-01],
[7.3341e-01, 2.6659e-01]], grad_fn=<SoftmaxBackward>)
这里我们输入的是两句话,所以得到两个元组,由于是一个二分类问题,所以每个元组中有两个元素。
得到了概率分布,还得知道具体是啥标签吧。标签跟id的隐射关系,也已经被保存在每个pretrain model的config中了, 我们可以去模型的config属性中查看id2label字段:
id2label = clf.config.id2label
id2label
输出:
{0: 'NEGATIVE', 1: 'POSITIVE'}
综合起来,直接从prediction得到标签:
for i in torch.argmax(predictions, dim=-1):
print(id2label[i.item()])
输出:
POSITIVE
NEGATIVE
本集我们大致了解了Huggingface Transformer库背后的操作流程。下一集我们会进一步深入地了解一下Huggingface的Models和Tokenizers。
NLP笔记4:Models,Tokenizers,以及如何做Subword tokenization
Models,Tokenizers,以及如何做Subword tokenization
Models
前面都是使用的AutoModel,这是一个智能的wrapper,可以根据你给定的checkpoint名字,自动去寻找对应的网络结构,故名Auto。
如果明确知道我们需要的是什么网络架构,就可以直接使用具体的*Model,比如BertModel,就是使用Bert结构。
随机初始化一个Transformer模型:通过config来加载
==*Config==这个类,用于给出某个模型的网络结构,通过config来加载模型,得到的就是一个模型的架子,没有预训练的权重。
from transformers import BertModel, BertConfig
config = BertConfig()
model = BertModel(config) # 模型是根据config来构建的,这时构建的模型是参数随机初始化的
看看config打印出来是啥:
print(config)
BertConfig {
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.3.3",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
更常用的做法则是**直接加载预训练模型,然后微调**。
★★初始化一个预训练的Transformer模型:通过from_pretrained来加载
from transformers import BertModel
model = BertModel.from_pretrained('bert-base-cased')
模型的保存:
model.save_pretrained("directory_on_my_computer")
# 会生成两个文件: config.json pytorch_model.bin
Tokenizer
transformer模型使用的分词方法,往往不是直接的word-level分词或者char-level分词。
前者会让词表过大,后者则表示能力很低。
因此主流的方式是进行 subword-level 的分词。例如对 “tokenization” 这个词,可能会被分成 “token” 和 “ization” 两部分。
Subword-level分词是一种文本处理技术,它**将单词分割成更小的单元**,称为subword。这些subword可以是字母、音节或其他类似的单位。Subword-level分词技术旨在解决一些语言处理中的挑战,如处理未登录词(out-of-vocabulary words)和处理不同形态的词汇形式。
相对于传统的单词级别的分词技术,subword-level分词技术可以更好地适应语言中的变化和多样性。例如,对于英语单词“running”,subword-level分词技术可以将其分割成“run”和“ning”,而单词级别的分词技术则无法处理这种情况。
常见的subword tokenization方法有:
- BPE
- WordPiece
- Unigram
- SentencePiece
- …
这里对BPE做一个简单的介绍,让我们对 sub-word tokenization 的原理有一个基本了解:
Subword tokenization (☆☆☆)
Subword tokenization的核心思想是:“频繁出现了词不应该被切分成更小的单位,但不常出现的词应该被切分成更小的单位”。
比方"annoyingly"这种词,就不是很常见,但是"annoying"和"ly"都很常见,因此细分成这两个sub-word就更合理。中文也是类似的,比如“仓库管理系统”作为一个单位就明显在语料中不会很多,因此分成“仓库”和“管理系统”就会好很多。
这样分词的好处在于,大大节省了词表空间,还能够解决OOV问题。因为我们很多使用的词语,都是由更简单的词语或者词缀构成的,我们不用去保存那些“小词”各种排列组合形成的千变万化的“大词”,而用较少的词汇,去覆盖各种各样的词语表示。同时,相比与直接使用最基础的“字”作为词表,sub-word的语义表示能力也更强。
那么,**用什么样的标准得到sub-word呢?**一个著名的算法就是 Byte-Pair Encoding (BPE) :
(下面的内容,主要翻译自Huggingface Docs中讲解tokenizer的部分,十分推荐大家直接阅读: https://huggingface.co/transformers/master/tokenizer_summary.html )
BPE————Byte-Pair Encoding:
Step1:首先,我们需要对语料进行一个预分词(pre-tokenization):
比方对于英文,我可以直接简单地使用空格加一些标点符号来分词;中文可以使用**jieba或者直接字**来进行分词。
分词之后,我们就得到了一个原始词集合,同时,还会记录每个词在训练语料中出现的频率。
假设我们的词集合以及词频是:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
Step2:构建基础词表(base vocab) 并开始学习 结合规则(merge rules):
①对于英语来说,我们选择字母来构成**基础词表**:
["b", "g", "h", "n", "p", "s", "u"]
注:这个基础词表,就是我们最终词表的初始状态,我们会**不断构建新词,加进去,直到达到我们理想的词表规模**。
②根据这个基础词表,我们可以**对原始的词集合进行细粒度分词,并看到基础词的词频**:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
③接下来就是BPE的Byte-Pair核心部分————找symbol pair(符号对)并学习结合规则,即,我们从上面这个统计结果中,找出出现次数最多的那个符号对:
统计一下:
h+u 出现了 10+5=15 次
u+g 出现了 10+5+5 = 20 次
p+u 出现了 12 次
...
统计完毕,我们发现u+g出现了最多次,因此,第一个结合规则就是:把u跟g拼起来,得到ug这个新词!
④那么,我们就把ug加入到我们的基础词表:
["b", "g", "h", "n", "p", "s", "u", "ug"]
同时,词频统计表也变成了:
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
Step3:反复地执行上一步,直到达到预设的词表规模。
我们接着统计,发现下一个频率最高的symbol pair是u+n,出现了12+4=16次,因此词表中增加un这个词;再下一个则是h+ug,出现了10+5=15次,因此添加hug这个词…
如此进行下去,当**达到了预设的vocab_size的数目时**,就停止,咱们的词表就得到啦!
Step4:如何分词:
得到了最终词表,在碰到一个词汇表中没有的词的时候,比如**bug就会把它分成b和ug**【ug词表中有】。也可以理解成,我首先把bug分解成最基本的字母,然后根据前面的结合规律,把u跟g结合起来,而b单独一个。具体在分词时候是如何做的,有时间去读读源码。
除了BPE,还有一些其他的sub-word分词法,可以参考 https://huggingface.co/transformers/master/tokenizer_summary.html 。
下面,我们就直接使用Tokenizer来进行分词:
from transformers import BertTokenizer # 或者 AutoTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
s = 'today is a good day to learn transformers'
tokenizer()
得到:
{'input_ids': [101, 2052, 1110, 170, 1363, 1285, 1106, 3858, 11303, 1468, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
了解一下内部的具体步骤:
tokenize()
s = 'today is a good day to learn transformers'
tokens = tokenizer.tokenize(s)
tokens
输出:
['today', 'is', 'a', 'good', 'day', 'to', 'learn', 'transform', '##ers']
注意这里的分词结果,transformers被分成了transform和##ers。这里的##代表这个词应该紧跟在前面的那个词,组成一个完整的词。
这样设计,主要是为了方面我们在还原句子的时候,可以正确得把sub-word组成成原来的词。
convert_tokens_to_ids()
ids = tokenizer.convert_tokens_to_ids(tokens)
ids
输出:
[2052, 1110, 170, 1363, 1285, 1106, 3858, 11303, 1468]
decode
print(tokenizer.decode([1468]))
print(tokenizer.decode(ids)) # 注意这里会把subword自动拼起来
输出:
##ers
today is a good day to learn transformers
Special Tokens
观察一下上面的结果,直接call tokenizer得到的ids是:
[101, 2052, 1110, 170, 1363, 1285, 1106, 3858, 11303, 1468, 102]
而通过convert_tokens_to_ids得到的ids是:
[2052, 1110, 170, 1363, 1285, 1106, 3858, 11303, 1468]
可以发现,前者在头和尾多了俩token,id分别是 101 和 102。
decode出来瞅瞅:
tokenizer.decode([101, 2052, 1110, 170, 1363, 1285, 1106, 3858, 11303, 1468, 102])
输出:
'[CLS] today is a good day to learn transformers [SEP]'
它们分别是 [CLS] 和 [SEP]。这两个token的出现,是因为我们调用的模型,在pre-train阶段使用了它们,所以tokenizer也会使用。
不同的模型使用的special tokens不一定相同,所以一定要让tokenizer跟model保持一致!
NLP笔记5:attention_mask在处理多个序列时的作用★★
attention_mask在处理多个序列时的作用
现在我们训练和预测基本都是批量化处理的,而前面展示的例子很多都是单条数据。单条数据跟多条数据有一些需要注意的地方。
处理单个序列
我们首先加载**一个在情感分类上微调过的模型,来进行我们的实验(注意,这里我们就不能能使用AutoModel【这种基础模型是没有微调的】,而应该使用AutoModelFor*这种带Head的model**)。
from pprint import pprint as print # 这个pprint能让打印的格式更好看一点
from transformers import AutoModelForSequenceClassification, AutoTokenizer
checkpoint = 'distilbert-base-uncased-finetuned-sst-2-english'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
对一个句子,使用tokenizer进行处理:
s = 'Today is a nice day!'
inputs = tokenizer(s, return_tensors='pt')
print(inputs)
{'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]]),
'input_ids': tensor([[ 101, 2651, 2003, 1037, 3835, 2154, 999, 102]])}
可以看到,这里的inputs包含了两个部分:input_ids和attention_mask.
模型可以直接接受input_ids:
model(inputs.input_ids).logits
输出:
tensor([[-4.3232, 4.6906]], grad_fn=<AddmmBackward>)
也可以通过**inputs同时接受inputs所有的属性:
model(**inputs).logits
输出:
tensor([[-4.3232, 4.6906]], grad_fn=<AddmmBackward>)
上面两种方式的结果是一样的。
**但是当我们需要同时处理多个序列时,情况就有变了!**★★
ss = ['Today is a nice day!',
'But what about tomorrow? Im not sure.']
inputs = tokenizer(ss, padding=True, return_tensors='pt')
print(inputs)
输出:
{'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
'input_ids': tensor([[ 101, 2651, 2003, 1037, 3835, 2154, 999, 102, 0, 0,
0],
[ 101, 2021, 2054, 2055, 4826, 1029, 10047, 2025, 2469, 1012,
102]])}
然后,我们试着直接把这里的input_ids喂给模型
model(inputs.input_ids).logits # 第一个句子原本的logits是 [-4.3232, 4.6906]
输出:
tensor([[-4.1957, 4.5675],
[ 3.9803, -3.2120]], grad_fn=<AddmmBackward>)
发现,第一个句子的logits变了!
这是因为**在padding之后,第一个句子的encoding变了,多了很多0**, 而self-attention会attend到所有的index的值,因此结果就变了。
这时,就需要我们不仅仅是传入input_ids,还需要给出attention_mask,这样模型就会在attention的时候,不去attend被mask掉的部分。
因此,在处理多个序列的时候,正确的做法是直接把tokenizer处理好的结果,整个输入到模型中,即==直接**inputs==。 通过**inputs,我们实际上就把attention_mask也传进去了:
model(**inputs).logits
输出:
tensor([[-4.3232, 4.6906],
[ 3.9803, -3.2120]], grad_fn=<AddmmBackward>)
现在第一个句子的结果,就跟前面单条处理时的一样了。
所以无论是处理单个还是多个序列,我们都将tokenizer处理之后的整个input传入model中。
NLP笔记6:数据集预处理,使用dynamic padding构造batch
数据集预处理,使用dynamic padding构造batch★
从这一集,我们就正式开始使用Transformer来训练模型了。今天的部分是关于数据集预处理。
试着训练一两条样本
# 先看看cuda是否可用
import torch
torch.cuda.is_available()
>>> True
首先,我们加载模型。既然**模型要在具体任务上微调了,我们就要加载带有Head的模型**,这里做的分类问题,因此加载ForSequenceClassification这个Head:
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
# Same as before
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
下面是模型输出的warning:
>>>
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
看到这么一大串的warning出现,不要怕,这个warning正是我们希望看到的。
为啥会出现这个warning呢,因为**我们加载的预训练权重是==bert-based-uncased,而使用的骨架是AutoModelForSequenceClassification**,前者是没有在下游任务上微调过的,所以用带有下游任务Head的骨架去加载,会**随机初始化这个Head**==。这些在warning中也说的很明白。
接下来,我们试试直接构造一个size=2的batch,丢进模型去。
当输入的batch是带有"labels"属性的时候,模型会自动计算loss,拿着这个loss,我们就可以进行反向传播并更新参数了:
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
batch['labels'] = torch.tensor([1, 1]) # tokenizer出来的结果是一个dictionary,所以可以直接加入新的 key-value
optimizer = AdamW(model.parameters())
loss = model(**batch).loss #这里的 loss 是直接根据 batch 中提供的 labels 来计算的,回忆:前面章节查看 model 的输出的时候,有loss这一项
loss.backward()
optimizer.step()
从Huggingface Hub中加载数据集★
这里,我们使用MRPC数据集,它的全称是Microsoft Research Paraphrase Corpus,包含了5801个句子对,标签是两个句子是否是同一个意思。
Huggingface有一个==datasets库,可以让我们轻松地下载常见的数据集==:
GLUE 数据集和评估任务由斯坦福大学、纽约大学和 AI2 (Allen Institute for Artificial Intelligence) 等机构共同推出。该套件的目的是为 NLP 社区提供一个公共的基准测试平台,以便不同的研究人员和团队能够直接比较和评估他们的模型在不同任务上的表现。
除了 GLUE 套件之外,还有一些类似的基准测试套件,如 SuperGLUE 和 XTREME,它们提供了更具挑战性的任务和数据集,可以更全面地评估模型的语言理解和推理能力。
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
# 加载了 GLUE (General Language Understanding Evaluation--一般语言理解评估) 数据集中的 MRPC (Microsoft Research Paraphrase Corpus) 子集
raw_datasets
看看加载的dataset的样子:
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
load_dataset出来的是一个DatasetDict对象,它包含了train,validation,test三个属性。可以**通过key来直接查询,得到对应的train、valid和test数据集**。
==这里的train,valid,test都是Dataset类型,有 features和num_rows两个属性。==还可以直接通过下标来查询对应的样本。
raw_train_dataset = raw_datasets['train']
raw_train_dataset[0] # 得到子数据集中的features部分
看看数据长啥样:
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0}
可见,每一条数据,就是一个dictionary。
Dataset的features可以理解为一张表的columns,Dataset甚至可以看做一个pandas的dataframe,二者的使用很类似。
我们可以直接像操作dataframe一样,取出某一列:
type(raw_train_dataset['sentence1']) # 直接取出所有的sentence1,形成一个list
>>> list
通过Dataset的features属性,可以**详细查看数据集特征,包括labels具体都是啥**:
raw_train_dataset.features
>>>
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
数据集的预处理
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
我们可以直接下面这样处理:
tokenized_sentences_1 = tokenizer(raw_train_dataset['sentence1'])
tokenized_sentences_2 = tokenizer(raw_train_dataset['sentence2'])
但对于MRPC任务,我们不能把两个句子分开输入到模型中,二者应该组成一个pair输进去。
MRPC: 查看两个句子是否是同一个意思。
tokenizer也可以直接处理sequence pair:
from pprint import pprint as print
inputs = tokenizer("first sentence", "second one")
print(inputs)
>>>
{'attention_mask': [1, 1, 1, 1, 1, 1, 1],
'input_ids': [101, 2034, 6251, 102, 2117, 2028, 102],
'token_type_ids': [0, 0, 0, 0, 1, 1, 1]}
我们把这里的input_ids给decode看一下:
tokenizer.decode(inputs.input_ids)
>>>
'[CLS] first sentence [SEP] second one [SEP]'
可以看到这里inputs里,还有一个token_type_ids属性,它在这里的作用就很明显了,指示哪些词是属于第一个句子,哪些词是属于第二个句子。tokenizer处理后得到的ids,解码之后,在开头结尾多了[CLS]和[SEP],两个句子中间也添加了一个[SEP]。另外注意,虽然**输入的是一个句子对,但是编码之后是一个整体,通过[SEP]符号相连**。
这种神奇的做法,其实是源于bert-base预训练的任务,即next sentence prediction。换成其他模型,比如DistilBert,它在预训练的时候没有这个任务,那它的tokenizer的结果就不会有这个token_type_ids属性了。
既然这里的tokenizer可以直接处理pair,我们就可以这么去分词:
tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)
但是这样不一定好,因为先是直接把要处理的整个数据集都读进了内存,又返回一个新的dictionary,会占据很多内存。
官方推荐的做法是通过Dataset.map方法,来调用一个分词方法,实现批量化的分词:
def tokenize_function(sample):
# 这里可以添加多种操作,不光是tokenize
# 这个函数处理的对象,就是Dataset这种数据类型,通过features中的字段来选择要处理的数据
return tokenizer(sample['sentence1'], sample['sentence2'], truncation=True) # 没有使用padding【原因见后面】
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
处理后的dataset的信息:
DatasetDict({
train: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})
看看这个map的一些参数:
raw_datasets.map(
function,
with_indices: bool = False,
input_columns: Union[str, List[str], NoneType] = None,
batched: bool = False,
batch_size: Union[int, NoneType] = 1000,
remove_columns: Union[str, List[str], NoneType] = None,
keep_in_memory: bool = False,
load_from_cache_file: bool = True,
cache_file_names: Union[Dict[str, Union[str, NoneType]], NoneType] = None,
writer_batch_size: Union[int, NoneType] = 1000,
features: Union[datasets.features.Features, NoneType] = None,
disable_nullable: bool = False,
fn_kwargs: Union[dict, NoneType] = None,
num_proc: Union[int, NoneType] = None, # 使用此参数,可以使用多进程处理
desc: Union[str, NoneType] = None,
) -> 'DatasetDict'
Docstring:
Apply a function to all the elements in the table (individually or in batches)
and update the table (if function does updated examples).
The transformation is applied to all the datasets of the dataset dictionary.
关于这个map,在Huggingface的测试题中有讲解,这里搬运并翻译一下,辅助理解:
Dataset.map方法有啥好处★★:
可以直接对数据库中的数据进行操作(数据预处理中的步骤),而不用占用大量的内存。
- The results of the function are cached, so it won’t take any time if we re-execute the code.
(通过这个map,对数据集的处理会被缓存,所以重新执行代码,也不会再费时间。) - It can apply multiprocessing to go faster than applying the function on each element of the dataset.
(它可以使用多进程来处理从而提高处理速度。) - It does not load the whole dataset into memory, saving the results as soon as one element is processed.
(它不需要把整个数据集都加载到内存里,同时每个元素一经处理就会马上被保存,因此十分节省内存。)
观察一下,这里通过map之后,得到的Dataset的features变多了:
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids']
多的几个columns就是tokenizer处理后的结果。
注意到,在这个tokenize_function中,我们没有使用padding,因为如果使用了padding之后,就会全局统一对一个maxlen进行padding,这样无论在tokenize还是模型的训练上都不够高效。
Dynamic Padding 动态padding
实际上,我们是故意先不进行padding的,因为我们想在划分batch的时候再进行padding,这样**可以避免出现很多有一堆padding的序列,从而可以显著节省我们的训练时间**。
这里,我们就需要用到**DataCollatorWithPadding,来进行动态padding**:
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
注意,我们需要使用tokenizer来初始化这个DataCollatorWithPadding,因为需要tokenizer来告知具体的padding token是啥,以及padding的方式是在左边还是右边(不同的预训练模型,使用的padding token以及方式可能不同)。
下面假设我们要搞一个size=5的batch,看看如何使用DataCollatorWithPadding来实现:
samples = tokenized_datasets['train'][:5]
samples.keys()
# >>> ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids']
samples = {k:v for k,v in samples.items() if k not in ["idx", "sentence1", "sentence2"]} # 把这里多余的几列去掉
samples.keys()
# >>> ['attention_mask', 'input_ids', 'label', 'token_type_ids']
# 打印出每个句子的长度:
[len(x) for x in samples["input_ids"]]
>>>
[50, 59, 47, 67, 59]
然后我们使用data_collator来处理:
batch = data_collator(samples) # samples中必须包含 input_ids 字段,因为这就是collator要处理的对象
batch.keys()
# >>> dict_keys(['attention_mask', 'input_ids', 'token_type_ids', 'labels'])
# 再打印长度:
[len(x) for x in batch['input_ids']]
>>>
[67, 67, 67, 67, 67]
可以看到,这个==data_collator就是一个**把给定dataset进行padding的工具**,其输入跟输出是完全一样的格式==。
{k:v.shape for k,v in batch.items()}
>>>
{'attention_mask': torch.Size([5, 67]),
'input_ids': torch.Size([5, 67]),
'token_type_ids': torch.Size([5, 67]),
'labels': torch.Size([5])}
这个batch,可以形成一个tensor了!接下来就可以用于训练了!
对了,这里多提一句,collator这个单词实际上在平时使用英语的时候并不常见,但却在编程中见到多次。
最开始一直以为是collector,意为“收集者”等意思,后来查了查,发现不是的。下面是柯林斯词典中对collate这个词的解释:
collate:
When you collate pieces of information, you gather them all together and examine them.
就是归纳并整理的意思。所以在我们这个情景下,就是对这些杂乱无章长短不一的序列数据,进行一个个地分组,然后检查并统一长度。
关于DataCollator更多的信息,可以参见文档:
https://huggingface.co/transformers/master/main_classes/data_collator.html?highlight=datacollatorwithpadding#data-collator
NLP笔记7:使用Trainer API来微调模型★★★★
使用Trainer API来微调模型
1. 数据集准备和预处理:
这部分就是回顾上一集的内容:
- 通过dataset包加载数据集
- 加载预训练模型和tokenizer
- 定义Dataset.map要使用的预处理函数(对数据集进行预处理)
- 定义DataCollator来用于构造训练batch (批处理)
import numpy as np
from transformers import AutoTokenizer, DataCollatorWithPadding
import datasets
checkpoint = 'bert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_datasets = datasets.load_dataset('glue', 'mrpc')
def tokenize_function(sample):
return tokenizer(sample['sentence1'], sample['sentence2'], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
2. 加载我们要fine-tune的模型:
num_labels=2是**指训练模型时使用的标签数量。具体来说,它指定了模型的分类任务输出的数量**。在这种情况下,num_labels=2表示模型将执行一个二元分类任务,即将每个输入序列分为两个类别之一。如果您的任务需要将输入序列分类到多个类别中,则应相应地将num_labels参数设置为所需的类别数量。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2) # 二元分类任务
>>> (warnings)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
不得不说,这个Huggingface很贴心,这里的warning写的很清楚。这里我们使用的是带ForSequenceClassification这个Head的模型,但是我们的bert-baed-cased虽然它本身也有自身的Head,但跟我们这里的二分类任务不匹配,所以可以看到,它的Head被移除了,使用了一个随机初始化的ForSequenceClassificationHead。
所以这里提示还说:“You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.”
3. 使用Trainer来训练★★
Trainer是Huggingface transformers库的一个高级API,可以帮助我们**快速搭建训练框架**:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(output_dir='test_trainer') # 指定输出文件夹,没有会自动创建
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator, # 在定义了tokenizer之后,其实这里的data_collator就不用再写了,会自动根据tokenizer创建
# data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
tokenizer=tokenizer,
)
我们看看TrainingArguments和Trainer的参数都有些啥:
- https://huggingface.co/transformers/master/main_classes/trainer.html
- https://huggingface.co/transformers/master/main_classes/trainer.html#trainingarguments
TrainingArguments(
output_dir: Union[str, NoneType] = None,
overwrite_output_dir: bool = False,
do_train: bool = False,
do_eval: bool = None,
do_predict: bool = False,
evaluation_strategy: transformers.trainer_utils.EvaluationStrategy = 'no',
prediction_loss_only: bool = False,
per_device_train_batch_size: int = 8, # 默认的batch_size=8
per_device_eval_batch_size: int = 8,
per_gpu_train_batch_size: Union[int, NoneType] = None,
per_gpu_eval_batch_size: Union[int, NoneType] = None,
gradient_accumulation_steps: int = 1,
eval_accumulation_steps: Union[int, NoneType] = None,
learning_rate: float = 5e-05,
weight_decay: float = 0.0,
adam_beta1: float = 0.9,
adam_beta2: float = 0.999,
adam_epsilon: float = 1e-08,
max_grad_norm: float = 1.0,
num_train_epochs: float = 3.0, # 默认跑3轮
...
Trainer(
model: Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module] = None,
args: transformers.training_args.TrainingArguments = None,
data_collator: Union[DataCollator, NoneType] = None,
train_dataset: Union[torch.utils.data.dataset.Dataset, NoneType] = None,
eval_dataset: Union[torch.utils.data.dataset.Dataset, NoneType] = None,
tokenizer: Union[ForwardRef('PreTrainedTokenizerBase'), NoneType] = None,
model_init: Callable[[], transformers.modeling_utils.PreTrainedModel] = None,
compute_metrics: Union[Callable[[transformers.trainer_utils.EvalPrediction], Dict], NoneType] = None,
callbacks: Union[List[transformers.trainer_callback.TrainerCallback], NoneType] = None,
optimizers: Tuple[torch.optim.optimizer.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None), # 默认会使用AdamW
)
Docstring:
Trainer is a simple but feature-complete training and eval loop for PyTorch, optimized for Transformers.
可见,这个Trainer把所有训练中需要考虑的参数、设计都包括在内了,我们可以在这里指定训练验证集、data_collator、metrics、optimizer,并通过TrainingArguments来提供各种超参数。
默认情况下,Trainer和TrainingArguments会使用:
- batch size=8
- epochs = 3
- AdamW优化器
定义好之后,直接使用.train()来启动训练:
trainer.train()
输出:
TrainOutput(global_step=1377, training_loss=0.35569445984728887, metrics={'train_runtime': 383.0158, 'train_samples_per_second': 3.595, 'total_flos': 530185443455520, 'epoch': 3.0})
用Trainer来预测
然后我们用Trainer来预测:
trainer.predict()函数处理的**结果是一个named_tuple(一种可以直接通过key来取值的tuple),类似一个字典,包含三个属性:predictions, label_ids, metrics**
注意,这里的三个属性:
predictions实际上就是logitslabel_ids不是预测出来的id,而是数据集中自带的ground truth的标签,因此如果输入的数据集中没给标签,这里也不会输出metrics,也是**只有输入的数据集中提供了label_ids才会输出metrics**,包括loss之类的指标
其中metrics中还可以包含我们自定义的字段,我们需要**在定义Trainer的时候给定compute_metrics参数**。
文档参考: https://huggingface.co/transformers/master/main_classes/trainer.html#transformers.Trainer.predict
predictions = trainer.predict(tokenized_datasets['validation'])
print(predictions.predictions.shape) # logits
# array([[-2.7887206, 3.1986978],
# [ 2.5258656, -1.832253 ], ...], dtype=float32) #输入的是两句话,是一个二分类问题
print(predictions.label_ids.shape) # array([1, 0, 0, 1, 0, 1, 0, 1, 1, 1, ...], dtype=int64)
print(predictions.metrics)
输出:
[51/51 00:03]
(408, 2)
(408,)
{'eval_loss': 0.7387174963951111, 'eval_runtime': 3.2872, 'eval_samples_per_second': 124.117}
然后就可以**用preds和labels来计算一些相关的metrics**了。
直接导入跟数据集相关的metrics
Huggingface datasets里面可以直接导入跟数据集相关的metrics:
from datasets import load_metric
preds = np.argmax(predictions.predictions, axis=-1)
metric = load_metric('glue', 'mrpc')
metric.compute(predictions=preds, references=predictions.label_ids)
>>>
{'accuracy': 0.8455882352941176, 'f1': 0.8911917098445595}
看看这里的metric(glue type)的文档:
Args:
predictions: list of predictions to score.
Each translation should be tokenized into a list of tokens.
references: list of lists of references for each translation.
Each reference should be tokenized into a list of tokens.
Returns: depending on the GLUE subset, one or several of:
"accuracy": Accuracy
"f1": F1 score
"pearson": Pearson Correlation
"spearmanr": Spearman Correlation
"matthews_correlation": Matthew Correlation
4.构建Trainer中的compute_metrics函数
前面我们注意到Trainer的参数中,可以提供一个compute_metrics函数,用于输出我们希望有的一些指标。
这个compute_metrics有一些输入输出的要求:
- 输入:是一个
EvalPrediction对象,是一个named tuple,需要有**至少predictions和label_ids两个字段**;经过查看源码,这里的predictions,就是logits - 输出:一个字典,包含各个metrics和对应的数值。
源码地址: https://huggingface.co/transformers/master/_modules/transformers/trainer.html#Trainer
from datasets import load_metric
def compute_metrics(eval_preds):
metric = load_metric("glue", "mrpc")
logits, labels = eval_preds.predictions, eval_preds.label_ids
# 上一行可以直接简写成:
# logits, labels = eval_preds 因为它相当于一个tuple
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
总结一下这个过程★★★★:
- 首先我们定义了一个
compute_metrics函数,交给Trainer; Trainer训练模型,模型会对样本计算,产生 predictions (logits);Trainer再把 predictions 和数据集中给定的 label_ids 打包成一个对象,发送给compute_metrics函数;compute_metrics函数计算好相应的 metrics 然后返回。
看看带上了 compute_metrics 之后的训练:
training_args = TrainingArguments(output_dir='test_trainer', evaluation_strategy='epoch')
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2) # new model
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator, # 在定义了tokenizer之后,其实这里的data_collator就不用再写了,会自动根据tokenizer创建
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
输出:
TrainOutput(global_step=1377, training_loss=0.32063739751678666, metrics={'train_runtime': 414.1719, 'train_samples_per_second': 3.325, 'total_flos': 530351810395680, 'epoch': 3.0})
可见,带上了compute_metircs函数之后,在Trainer训练过程中,会把增加的metric也打印出来,方便我们时刻了解训练的进展。
NLP笔记8:使用PyTorch来微调模型「初级教程完结撒花❀❀」★★★★★★
更加透明的方式——使用PyTorch来微调模型
这里我们不使用Trainer这个高级API,而是用pytorch来实现。
1. 数据集预处理
在Huggingface官方教程里提到,在使用pytorch的dataloader之前,我们需要做一些事情:
- 把dataset中一些不需要的列给去掉了,比如‘sentence1’,‘sentence2’等
- 把数据转换成pytorch tensors
- 修改列名 label 为 labels
为啥要修改列名 label 为 labels
其他的都好说,但为啥要修改列名 label 为 labels,好奇怪哦! 这里探究一下:
首先,Huggingface的这些transformer Model直接call的时候,接受的标签这个参数是叫"labels"。 所以不管你使用Trainer,还是原生pytorch去写,最终模型处理的时候,肯定是使用的名为"labels"的标签参数。
但在Huggingface的datasets中,数据集的标签一般命名为"label"或者"label_ids",那为什么在前两集中,我们没有对标签名进行处理呢?
这一点在transformer的源码trainer.py里找到了端倪:
# 位置在def _remove_unused_columns函数里
# Labels may be named label or label_ids, the default data collator handles that.
signature_columns += ["label", "label_ids"]
这里提示了, data collator 会负责处理标签问题。然后我又去查看了data_collator.py中发现了一下内容:
class DataCollatorWithPadding:
...
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
...
if "label" in batch:
batch["labels"] = batch["label"]
del batch["label"]
if "label_ids" in batch:
batch["labels"] = batch["label_ids"]
del batch["label_ids"]
return batch
这就真相大白了:不管数据集中提供的标签名叫"label",还是"label_ids", DataCollatorWithPadding 都会帮你转换成"labels",装进batch里,再返回。
前面使用Trainer的时候,DataCollatorWithPadding已经帮我们自动转换了,因此我们不需要操心这个问题。
但这就是让我疑惑的地方:我们==使用pytorch来写,其实也不用管这个,因为**在pytorch的data_loader里面,有一个collate_fn参数【就是一个数据整合函数,在这个函数里我们可以对数据集中的数据进行相关操作,其中就自然包括了数据集元素标签名字的替换(DataCollatorWithPadding对象实现)】**,我们可以把DataCollatorWithPadding对象传进去,也会帮我们自动把"label"转换成"labels"(具体看DataCollatorWithPadding函数代码即可)。==因此实际上,这应该是教程中的一个小错误,我们不需要手动设计(前两天在Huggingface GitHub上提了issue,作者回复我确实不用手动设置)。
下面开始正式使用pytorch来训练:
首先是跟之前一样,我们需要加载数据集、tokenizer,然后把数据集通过map的方式进行预处理。我们还需要定义一个data_collator方便我们后面进行批量化处理模型:
# 进行数据预处理
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer) # 用于后面进行批量化处理模型
查看一下处理后的dataset:
print(tokenized_datasets['train'].column_names)
>>>
['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids']
huggingface datasets贴心地准备了三个方法:remove_columns, rename_column, set_format
来方便我们为pytorch的Dataloader做准备:
Dataloader函数参数:attention_mask、input_ids、token_type_ids、labels
tokenized_datasets = tokenized_datasets.remove_columns(['sentence1', 'sentence2','idx'])
# tokenized_datasets = tokenized_datasets.rename_column('label','labels') # 实践证明,这一行是不需要的
tokenized_datasets.set_format('torch')
print(tokenized_datasets['train'].column_names)
>>>
['attention_mask', 'input_ids', 'label', 'token_type_ids']
查看一下:
tokenized_datasets['train'] # 经过上面的处理,它就可以直接丢进pytorch的Dataloader中了,跟pytorch中的Dataset格式已经一样了
>>>
Dataset({
features: ['attention_mask', 'input_ids', 'label', 'token_type_ids'],
num_rows: 3668
})
定义我们的pytorch dataloaders:
在pytorch的DataLoader里,有一个collate_fn参数,其定义是:“merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.” 我们可以直接把Huggingface的DataCollatorWithPadding对象传进去,用于对数据进行padding等一系列处理:
from torch.utils.data import DataLoader, Dataset
train_dataloader = DataLoader(tokenized_datasets['train'], shuffle=True, batch_size=8, collate_fn=data_collator) # 通过这里的dataloader,每个batch的seq_len可能不同【data_collator = DataCollatorWithPadding(tokenizer=tokenizer) # 用于后面进行批量化处理模型】
eval_dataloader = DataLoader(tokenized_datasets['validation'], batch_size=8, collate_fn=data_collator)
# 查看一下train_dataloader的元素长啥样
for batch in train_dataloader:
break
{k: v.shape for k, v in batch.items()}
# 可见都是长度为72,size=8的batch
>>>
{'attention_mask': torch.Size([8, 72]),
'input_ids': torch.Size([8, 72]),
'token_type_ids': torch.Size([8, 72]),
'labels': torch.Size([8])}
观察一下经过DataLoader处理后的数据,我们发现,标签那一列的列名,已经从"label"变为"labels"了!
2. 模型
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2) #二分类问题
前面dataloader出来的batch可以直接丢进模型处理:
前面dataloader出来的batch参数与model所需的参数一致:(attention_mask、input_ids、token_type_ids、labels)
具体实际应用场景:loss = model(**batch).loss
model(**batch)
>>>
SequenceClassifierOutput(loss=tensor(0.7563, grad_fn=<NllLossBackward>), logits=tensor([[-0.2171, -0.4416],
[-0.2248, -0.4694],
[-0.2440, -0.4664],
[-0.2421, -0.4510],
[-0.2273, -0.4545],
[-0.2339, -0.4515],
[-0.2334, -0.4387],
[-0.2362, -0.4601]], grad_fn=<AddmmBackward>), hidden_states=None, attentions=None)
定义 optimizer 和 learning rate scheduler
按道理说,Huggingface这边提供Transformer模型就已经够了,具体的训练、优化,应该交给pytorch了吧。但鉴于Transformer训练时,最常用的优化器就是AdamW,这里Huggingface也直接在transformers库中加入了AdamW这个优化器,还贴心地配备了lr_scheduler,方便我们直接使用。
from transformers import AdamW, get_scheduler
optimizer = AdamW(model.parameters(), lr=5e-5)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader) # num of batches * num of epochs
lr_scheduler = get_scheduler(
'linear',
optimizer=optimizer, # scheduler是针对optimizer的lr的
num_warmup_steps=0,
num_training_steps=num_training_steps)
print(num_training_steps)
1377
3. Training
首先,我们设置cuda device,然后把模型给移动到cuda上:
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
编写pytorch training loops ★★:
这里也很简单,思路就是这样:
- for每一个epoch
- 从dataloader里取出一个个batch
- 把batch喂给model(先把batch都移动到对应的device上)
- 拿出loss,进行反向传播backward
- 分别把optimizer和scheduler都更新一个step
最后别忘了每次更新都要清空grad,即对optimizer进行zero_grad()操作。
from tqdm import tqdm
for epoch in range(num_epochs):
for batch in tqdm(train_dataloader):
# 要在GPU上训练,需要把数据集都移动到GPU上:
batch = {k:v.to(device) for k,v in batch.items()}
loss = model(**batch).loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
100%|██████████| 459/459 [01:54<00:00, 4.01it/s]
100%|██████████| 459/459 [01:55<00:00, 3.98it/s]
100%|██████████| 459/459 [01:55<00:00, 3.96it/s]
4. Evaluation
这里跟train loop还是挺类似的,一些细节见注释即可:
metrics:度量函数,具体的可以直接通过命令查看使用实例:
from datasets import load_metric #加载一个评价指标 metric = load_metric('glue', 'mrpc') print(metric.inputs_description) >>> glue_metric = datasets.load_metric('glue', 'sst2') # 'sst2' or any of ["mnli", "mnli_mismatched", "mnli_matched", "qnli", "rte", "wnli", "hans"] >>> references = [0, 1] >>> predictions = [0, 1] >>> results = glue_metric.compute(predictions=predictions, references=references) >>> print(results) {'accuracy': 1.0}
from datasets import load_metric
metric= load_metric("glue", "mrpc")
model.eval()
for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad(): # evaluation的时候不需要算梯度
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
# 由于dataloader是每次输出一个batch,因此我们要等着把所有batch都添加进来,再进行计算
metric.add_batch(predictions=predictions, references=batch["labels"])
metric.compute()
>>>
{'accuracy': 0.8651960784313726, 'f1': 0.9050086355785838}
至此,Huggingface Transformer初级教程就完结撒花了!
ヽ(°▽°)ノ
更高级的教程,Huggingface也还没出 ,所以咱们敬请期待吧!不过,学完了这个初级教程,我们基本是也可以快乐地操作各种各样Transformer-based模型自由玩耍啦!