离线数仓问题总结
一、采集
1.1 maxwell中的默认JDBC驱动包
其版本不适用于MySQL 5.7版本
二、数仓
2.1 关于hive如何支持json类型的字段
主要在建表语句上指定上
DROP TABLE IF EXISTS ods_log_inc;
CREATE EXTERNAL TABLE ods_log_inc
(
`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc
:STRING> COMMENT '公共信息',
`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id
:STRING,source_type :STRING> COMMENT '页面信息',
`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',
`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`order` :STRING,pos_id
:STRING>> COMMENT '曝光信息',
`start` STRUCT<entry :STRING,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms
:BIGINT> COMMENT '启动信息',
`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',
`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_log_inc/';
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'确定了使用json格式的字段- 查询时使用
字段名.属性的方式进行调用,且会自动为当前列起别名为属性名
2.2 使用with ... as语句简化sql
https://blog.csdn.net/Abysscarry/article/details/81322669
2.3 Hive的复杂数据类型(Array Map Struct 等)
https://blog.csdn.net/qq_46893497/article/details/109961401
select
sku_id,
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrs
from ${APP}.ods_sku_attr_value_full
where dt='$do_date'
group by sku_id
collect_set可以将一组数据去重后合并为一个数组
2.4 关于开窗函数
- 开窗函数和聚合函数的区别:
(1)SQL 标准允许将所有聚合函数用作开窗函数,用OVER 关键字区分开窗函数和聚合函数。
(2)聚合函数每组只返回一个值,开窗函数每组可返回多个值。
开窗函数每组可返回多个值的理解:比如求某一列的最大值,使用group by+聚合函数max()得到的效果是,每一组返回一行,一行两列,分别为组名和改组最大值;二使用开窗函数,则会返回所有的行,每一行都会多一列,这一列就是其所在组的列的最大值。
- 概念理解:https://blog.csdn.net/qq_31183727/article/details/107023293
- 简单实操:https://blog.csdn.net/super_qing_/article/details/115725430
2.5 union操作
union用于合并两个
select查询结果(不能合并表),且两个子查询必须列名和数量完全一致
- 官方文档:https://www.docs4dev.com/docs/zh/apache-hive/3.1.1/reference/LanguageManual_Union.html
- 实操:https://blog.csdn.net/liuguangfudan/article/details/78623074
2.6 ORC列式存储
https://juejin.cn/post/6844903939020685325
可以大大提升单独查询某一列的速度
2.7cast类型转换
https://blog.csdn.net/qq_26502245/article/details/108510747
2.8 sql执行顺序
https://www.cnblogs.com/xqzt/p/4972789.html\
The following steps show the processing order for a SELECT statement:
FROM
ON
JOIN
WHERE
GROUP BY
WITH CUBE or WITH ROLLUP
HAVING
SELECT
DISTINCT
ORDER BY
TOP
https://blog.csdn.net/u013887008/article/details/93377939
2.9 Hive动态分区
https://blog.csdn.net/jmx_bigdata/article/details/88606394
可以在配置文件配置(永久),也可以使用sql配置(会话期间有效)
2.10 各层设计要点
ODS层的设计要点如下:
1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。
2)ODS层要保存全部历史数据,故其压缩格式应选择压缩比较高的,此处选择gzip。
3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
DIM层设计要点:
1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
2)DIM层的数据存储格式为orc列式存储+snappy压缩。
3)DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)
DWD层设计要点:
1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
2)DWD层的数据存储格式为orc列式存储+snappy压缩。
3)DWD层表名的命名规范为dwd_数据域_表名_单分区增量全量标识(inc/full)
DWS层设计要点:
1)DWS层的设计参考指标体系。
2)DWS层的数据存储格式为orc列式存储+snappy压缩。
3)DWS层表名的命名规范为dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)
注:1d表示最近1日,nd表示最近n日,td表示历史至今。
一张汇总表通常包含业务过程相同、统计周期相同、统计粒度相同的多个派生指标,但是有时候为了保证应用的灵活性,也会设计成一个派生指标对应一张汇总表
2.11 Hive中文comment乱码问题
https://blog.csdn.net/xianpanjia4616/article/details/90733124
2.12 金额相关的字段都用DECIMAL()类型
直接用
double或者float会存在精度问题
2.13 使用sum、if组合实现简化计算最近n天的sql
insert overwrite table dws_trade_user_sku_order_nd partition(dt='2020-06-14')
select
user_id,
sku_id,
sku_name,
category1_id,
category1_name,
category2_id,
category2_name,
category3_id,
category3_name,
tm_id,
tm_name,
sum(if(dt>=date_add('2020-06-14',-6),order_count_1d,0)),
sum(if(dt>=date_add('2020-06-14',-6),order_num_1d,0)),
sum(if(dt>=date_add('2020-06-14',-6),order_original_amount_1d,0)),
sum(if(dt>=date_add('2020-06-14',-6),activity_reduce_amount_1d,0)),
sum(if(dt>=date_add('2020-06-14',-6),coupon_reduce_amount_1d,0)),
sum(if(dt>=date_add('2020-06-14',-6),order_total_amount_1d,0)),
sum(order_count_1d),
sum(order_num_1d),
sum(order_original_amount_1d),
sum(activity_reduce_amount_1d),
sum(coupon_reduce_amount_1d),
sum(order_total_amount_1d)
from dws_trade_user_sku_order_1d
where dt>=date_add('2020-06-14',-29)
group by user_id,sku_id,sku_name,category1_id,category1_name,category2_id,category2_name,category3_id,category3_name,tm_id,tm_name;
sum(if(dt>=date_add('2020-06-14',-6),order_count_1d,0)) -- 最近7天
sum(order_count_1d) -- 最近30天
2.14 关于null+数字=null
可使用nvl()解决
nvl(old.payment_count_td,0)+nvl(new.payment_count_1d,0)
2.15 环境变量配置说明
Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/*.sh,~/.bashrc,~/.bash_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可分为login shell和non-login shell。
例如,我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell,而当我们执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,~/.bash_profile,~/.bashrc,non-login shell启动时会加载~/.bashrc。即login shell会多加载/etc/profile文件。
而在加载~/.bashrc(实际是~/.bashrc中加载的/etc/bashrc)或/etc/profile时,都会执行如下代码片段,
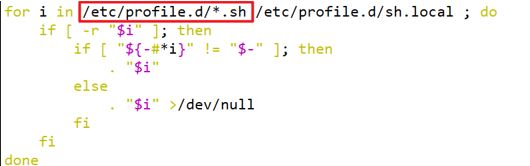
因此不管是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量。而login shell会多加载/etc/profile.d/sh.local文件。
2.16 union和join的使用时机
当不同的select字句需要放到同一行时使用join,不同行时用union
2.17 子查询一定要起别名
select
concat('step-',rk,':',page_id) as pageid,
concat('step-',rk,':',next_page_id) as next_page_id
from
(
select
page_id,
lead(page_id) over (partition by session_id order by view_time) as next_page_id,
rank() over (partition by session_id order by view_time) as rk
from dwd_traffic_page_view_inc
) tmp;
这里为子查询起了一个
tmp的别名,否则会报错cannot recognize input near '' ' ' ' ' in subquery source
2.18 group by和partition by都可以指定多个字段
2.19 使用explode给表添加标识,用于实现一条sql查询最近1 7 30天的聚合结果
select
recent_days,
sum(if(login_date_last>=date_add('2020-06-14',-recent_days+1),1,0)) new_user_count
from dws_user_user_login_td lateral view explode(array(1,7,30)) tmp as recent_days -- 添加标识
where dt='2020-06-14'
group by recent_days -- 根据标识分组聚合
2.20 关于使用awk指令和xargs结合实现关闭程序的指令
ps -ef | grep file_to_kafka.conf | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9
awk负责切割,xargs可以接收管道传来的参数并传递给要执行的指令(比如kill -9)
2.21 Hadoop 接入 kerberos实现安全认证
https://intl.cloud.tencent.com/zh/document/product/1026/31166
2.22 DolphinScheduler部署之后点击登录一直转圈
大多是因为数据的配置问题,在安装后的配置文件data.properties文件的MySQL连接配置中添加useSSL=false即可,改完后记得向集群分发。