yolov3原理解析及代码流程
一.原理解析
1.yolov3在yolo、yolov2基础之上进行了优化,使得模型既保提升了一定的性能又在速度上做了折中;结构网络示意图如下:
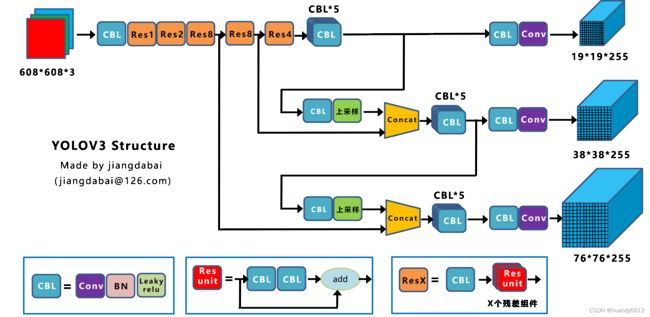
(注:图片借鉴网上相关领域大佬制作的图片,如有侵权请联系本人删除处理)
2.Backbone网络:Backbone使用了DarkNet-53(模型共有106层),这就是速度下降的主要原由;CBL是网络结构的基础模块,此模块主要讲解BN,BN全称为Batch normalization为批量归一化(批量标准化),和LRN(Local response normalization)区分开;BN主要影响数据集数据分布,这个修正主要影响模型收敛速度;LRN会影响权重参数学习对数据进行量级归拢。下面给出两个概念的公式及注解:
1)BN:

2)LRN:
公式中的a表示卷积层(包括卷积操作和池化操作)后的输出结果,这个输出结果的结构是一个四维数组[batch,height,width,channel],这里可以简单解释一下,batch就是批次数(每一批为一张图片),height就是图片高度,width就是图片宽度,channel就是通道数可以理解成一批图片中的某一个图片经过卷积操作后输出的神经元个数(或是理解成处理后的图片深度)。ai(x,y)表示在这个输出结构中的一个位置[a,b,c,d],可以理解成在某一张图中的某一个通道下的某个高度和某个宽度位置的点,即第a张图的第d个通道下的高度为b宽度为c的点。论文公式中的N表示通道数(channel)。a,n/2,k,α,β分别表示函数中的input,depth_radius,bias,alpha,beta,其中n/2,k,α,β都是自定义的,特别注意一下∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着a中的第3维channel方向的,也就是一个点同方向的前面n/2个通道(最小为第0个通道)和后n/2个通道(最大为第d-1个通道)的点的平方和(共n+1个点)。而函数的英文注解中也说明了把input当成是d个3维的矩阵,说白了就是把input的通道数当作3维矩阵的个数,叠加的方向也是在通道方向。第i个核在位置(x,y)运用激活函数ReLU后的输出,n是同一位置上临近的kernal map的数目,N是kernal的总数。参数K,n,alpha,belta都是超参数,一般设置k=2,n=5,aloha=1*e-4,beta=0.75。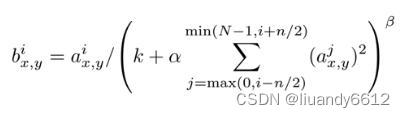
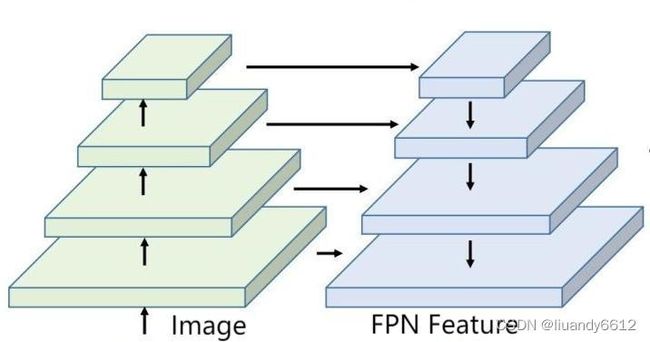
3.Neck网络:Neck网络也是yolov3算法的主要改变之处之一,采用了多尺寸检测(三个分支),并实现了FPN(通过上采样),这样就区别于两阶算法的单一输出尺寸特征图并实现了特征融合;进而提升了模型对于小目标的效果。FPN结构示意图如下:
4.yolo_head实现了输出结果并进行修正(bbox坐标)等操作,最后会送入损失层计算损失作为最终的输出;对网络输出结果bbox坐标修正公式如下:

(cx,cy):该点所在网格的左上角距离最左上角相差的格子数。
(pw,ph):先验框的边长
(tx,ty):目标中心点相对于该点所在网格左上角的偏移量
(tw,th):预测边框的宽和高
这里说一个注意的trick:在大多数算法里NMS(非极大值抑制)都是在预测阶段执行,在训练阶段一般不会去执行。
5.LOSS层:
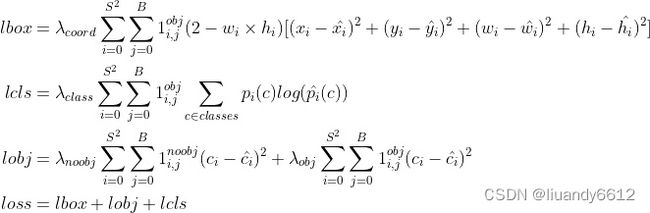
S:grid size,即13×13,26×26,52×52
B:box
![]() :如果在i,j处的box有目标,其值为1,否则为0
:如果在i,j处的box有目标,其值为1,否则为0
![]() :如果在i,j处的box没有目标,其值为1,否则为0
:如果在i,j处的box没有目标,其值为1,否则为0
注意区分公式里的c和ci的区分一个表示类别标签,一个表示概率。
6.总结:
1)yolov3较之前的两个版本主要优化了实现三个分支网络并实现了FPN,并在最后分类计算时实现了逻辑分类器。
2)在每个网络 分支下实现了每个网格3个anchors。
3)在基础网络Backbone上实现了DarkNet53。
4)由于在计算损失值之前用逻辑分类器代替softmax进而可以实现多类别标签预测。
二.代码流程如下图所示: