MySQL 全球大会summit 2023年度 --- MySQL 高可用和灾备 (音译)

开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1350人左右 1 + 2 + 3 + 4) 3群突破 400会关闭自由申请,新人会进4群,另欢迎 OpenGauss 的技术人员加入。
每日感悟
人活在这个世界上,真心为你好的人屈指可数,降低预期,降低期待,严格按照礼尚往来,相敬如宾,可能关系能持久些。
相对于其他的数据库厂商大会,MySQL的的确寒酸,连幕头都没有,上来就直接讲,不过也符合MySQL一贯的风格。这次翻译的是 2023年MySQL summit -- MySQL high availability and disaster recovery。开始本次的讲解人是 MySQL的产品经理,明显和我之前听的MongoDB的两期差距较大,一看是不善言辞的人。
——————————————————————————————

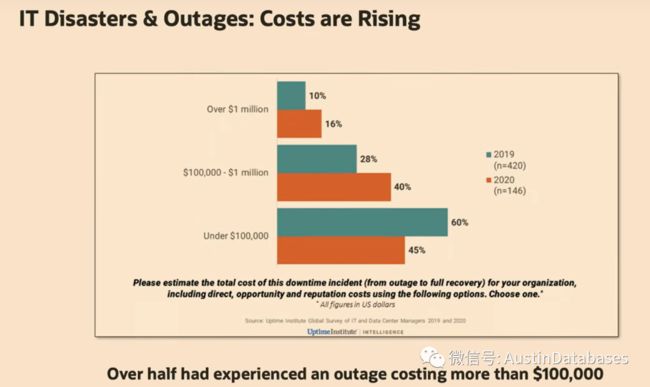
大家好,我是MySQL的产品经理,我本期为大家介绍的是 MySQL的高可用和灾难恢复上的一些新的解决方案,这里我们先看这张图,在数据库的故障中,关于产生故障的原因有有很多种,饱含电力,网络,数据服务器中心,制冷等多种故障
与此同时灾难恢复的成本却在不断的升高,从这里我们可以看到很多可以换提出灾难恢复的成本问题,对比2019年到2020年成本超过了100万美元。
包含OVH是欧洲较大的数据服务中心,他们发生火灾给相关的机构产生了很大的损失,估算上亿的经济损失。下面我将开始我对MySQL的高可用方面的介绍方便大家使用更低成本的,让MySQL的高可用更加容易的实现。

MySQL 存在很多年了20-25年,这里我找了一个我上学时候的一个图,希望我没有找错,基于MySQL的复制的灵活性,我们可以进行横向的扩展,提供高可用性,或提供功能横向扩展等等。因为他非常的灵活,可以进行异步的复制,保证最终一致性,同时还有一些搞出双主的模式的,虽然我十分不建议这样进行高可用的实现。

同时之前的一些问题,导致大量的自动化优化的团队,DBA都在致力于MySQL的自动化平台等相关的设计和部署的工作,在2016年我们就提出了innodb cluster,这是基于组复制同时使用异步数据复制的方式来实现数据库高可用集群,在事务提交中我们以大多数节点提交事务作为事务确认的,当节点加入时,无需进行设置,自动配置所有的部分都是内置并自动完成的,他会处理网络分区,不会出现脑裂,同时我们也提供多节点多住写入,这就是我们在2016年提供的,后来我们提供了一个工具集,mysql shell 是这里面客户访问的工具可以在其中进行集群的配置,我们稍后会提供一些案例。

你可以通过这个部分来进行数据库的集群配置和自动化配置的工作等,这里非常容易得进行节点的添加和删除等等,数据量较少则几分钟就可以组建出一个集群,MySQL shell 提供了他所需要的接口,这些技术中,一个物理快照,有趣的部分是我们在2019年提供的Clone ,这里MySQL提供了一个快照,提供节点并配置复制,所有这些都通过一个命令的形式进行,如果你想要自定义架构,那么这些部分的每一个都可以单独使用,但我们关注如何给大部分企业大多数提供需要的环境,故障转移在5秒内可以发生,数据丢失可能性为0,通常的情况下需要5-10秒,具体取决于工作的负载。他可能需要更长的时间,转移不可能会丢失数据,这是最常用的高可用,当发生故障时,数据中心内的单个服务器发生故障,所以组复制时复制数据库当时的状态,需要注意这不是一种分片的技术,他提供的是一种高可用和节点扩展的技术。
您可以配置您想要的一致性,您可以在主数据库上写入并同时从从库读取数据,默认情况下您将获得最终的一致性,这意味着您可以读取主数据库上不是最新的数据,但您也可以启用完全一致,并且提出我想读取最新的数据,这样就可以启用全局读,这一切都是使用了MySQL的高可用框架,使用BINLOG , RELAY LOG , 全局事务。

看上去这很棒,但是很多用户都提出如果我没有稳定的网络怎么办,那么就需要接受一些数据的丢失,或者我有更好的写入的吞吐量,因为异步的复制会更快,事务可以在本地提交不需要得到其他成员的确认,但如果这些都没有,那么你可能会丢数据,少量的几秒钟。
在2020年,我们有了innodb clusterSET 在之前的高可用基础行,进行了一个补充,我们将我们的功能添加到MySQL Shell,然后添加一个从库或多个从库我们这里要做的就是灾难恢复,我们在两个区域之间配置异步复制,两个或多个区域,添加的区域数量没有限制,通过这种方式我们可以使用MySQL Shell来简单的切换到布鲁塞尔的集群上,使其成为主集群。他会重新配置所有的内容,所有的这一切都是一个命令就可以解决,当然区域之间可能有数据丢失。

通常来说大多数公司不希望区域之间有任何的数据丢失,这通常是可以接受的,当一个区域发生故障的时候,您需要没有数据丢失,就需要产生3个区域,把innodb 集群中的成员拆分,这样就可以不丢失数据,同时通过MySQL Shell 可以进行快速的节点添加节点删除,在通过MySQL ROUTER 可以快速的掌握你整个的数据库架构,通过设置可以连接到主集群上进行读写。

同时我们针对区域中的集群不非要是3台主机,这里一个区域也可以是一台主机。这里我举几个例子,因为时间的原因可能这些例子不是完整的。这里我们通过MySQL Shell进行登录,然后建立一个高可用的模式,并添加节点。在MySQL底层配置一些设置后,这些都不需要SSH的支持,这些都是通过MySQL的connection来进行的,使用这个命令你就可以建立一个Mysql 集群非常非常简单。这里你可以通过他来进行那个是主,配置参数的改变,所有的操作都在 MySQL Shell中。


通过clusterset.status() 命令可以看到当前的集群的状态,以及那个是主节点等信息。
这里还可以通过命令来改变主节点,并且通过myrouter将工作负载发送到新的主节点上。

这里还可以改变主节点,整个的改变过程不会出现脑裂的问题,我们要做的就是简单的命令,安全的转换副集群转为主集群。

当主节点CRASH 了,我们在复制中添加了相关的的功能,当主节点失效后,会自动选主相关其他的节点会自动重新配置,并指向新的主节点,并对集群的状态进行修改。

下面是一个数据中心的例子,这里有两个数据中心,其中一个Cluster在主数据中心当主数据库中心出现火灾,可以通过手工的方式,强制将备用的数据中心的MySQL 集群进行启用,当网络出现问题的时候,为了防止脑裂,必须通过手工的方式进行隔离,或停掉其中一组区域的MySQL集群,目的就是要防止脑裂,防止在两个区域出现两个主集群。

这里RPO为0说明不会丢失数据,如果我们采用异步的方式,并未网络出现问题可能会丢失几秒的数据,具体还和你网络带宽有关,RTO为我们需要多长时间来进行数据的恢复,我们都希望RPO=0 没有数据丢失,RTO=0我们立即恢复数据,但从高可用的角度来看,但这里实际上我们的需求是不一样,如果你只是单区域,那么你在意的是你数据库的高可用,但如果是灾难恢复,则你需要注意的是你的多区域的设置。当然还有人为的误删除数据,或SQL注入等问题,那么你需要做的是通过备份来恢复,或者通过延迟节点来进行相关的工作。所以我们这里介绍的部分,是不能

这里如果你需要的是数据不丢失,秒级的数据恢复那么你可以选择innodb cluster,如果你能接受数据丢失,分钟级别的数据恢复和手动的数据节点的切换,那么你可以选择 innodb relicaset (实际上他指的就是我们一直在用的主从复制)
 这里如果要一个稳定的高可用和灾备,达到RPO=0,RTO在秒级,你需要有3个区域的MySQL 集群,同时你的网络必须是稳定的,因为他们之间要互相的发送消息,互联网方式的连接是不可以,你需要通过专线来将各个数据中心进行连接,网络问题或数据包丢失可能导致你的集群的不稳定和问题,这存在着风险问题,并且你要保证带宽足够的高,满足你的数据传输的要求,同时尽量降低些延迟问题的发生,在DC 和 DC 之间。
这里如果要一个稳定的高可用和灾备,达到RPO=0,RTO在秒级,你需要有3个区域的MySQL 集群,同时你的网络必须是稳定的,因为他们之间要互相的发送消息,互联网方式的连接是不可以,你需要通过专线来将各个数据中心进行连接,网络问题或数据包丢失可能导致你的集群的不稳定和问题,这存在着风险问题,并且你要保证带宽足够的高,满足你的数据传输的要求,同时尽量降低些延迟问题的发生,在DC 和 DC 之间。
 这就是我们针对MySQL 高可用和灾难恢复的给客户的方案,大部分情况下数据是可以恢复的,但异步的区域之间的手动切换会丢失数据。
这就是我们针对MySQL 高可用和灾难恢复的给客户的方案,大部分情况下数据是可以恢复的,但异步的区域之间的手动切换会丢失数据。

这里就是我的所要展示的所有内容。
