增量表、全量表、拉链表的应用场景及优缺点详解
想要进行数据分析,首先要学会准确地获取数据,数据来源于数据库表,想要获取数据就需要知道库表的存储位置、存储形式等信息。一般来说,公司对于表的命名都有统一规范,比如:
(1)表明数据存储于哪些库,是数据接入层还是数据明细层?是数据聚合层还是数据应用层?这些层分别对应于哪些库,命名是什么。
(2)包含业务线、业务主题、表名、更新周期是什么。
一、维度表、事实表的定义及区分
维度表: 业务过程的业务实体 ,如:商品,用户,订单。
维度表中常见的column字段包含:
• 代理键(自增列,可以充当主键)
• 自然键(唯一区分,商品id,订单id)
• 维度属性(商品的大小,颜色等)
事实表: 业务内特定事件的数据(大量的行) ,如:商品的销售记录。
事实表的常见分类包括: 全量表 、 增量表 、 流水表 、 拉链表 。
表的命名规范: 表中常见的
i、s、a,分别代表增量表、快照表、全量表。
二、增量表、全量表、拉链表的定义
2.1 全量表
全量表: 记录更新周期内的全量数据,无论数据是否有变化都需要记录;
全量表的典型特征:
-
存储的是截至到目前最新状态的全部记录,有无变化,都要上报;
-
每次上报的数据都是所有的数据(变化的 + 没有变化的);
-
没有分区,所有数据存储在一个分区中。比如:今天是24号,那么全量表里面包含的数据是截至23号的所有数据,每次往全量表里面写数据都会覆盖之前的数据,所以全量表不能记录历史的数据情况 ,只有截止到当前最新的、全量的数据。
全量表的典型范例:
举个例子,2021年3月13号的全量表如图,当天有两位用户,其支付状态都是待支付。
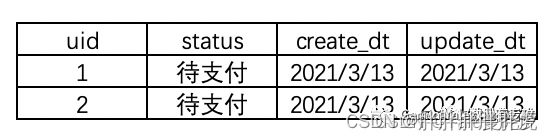
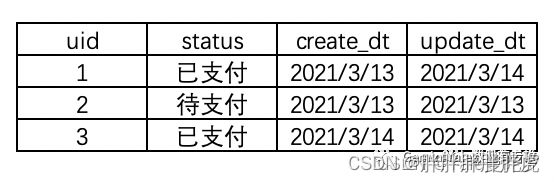
2021年3月14号,uid为1的用户支付了,且当天新增了一位已支付的uid为3的用户,那么2021年3月14号的全量表就变成了下图,13号uid为1的用户待支付状态更新为已支付。
2.2 增量表
增量表: 记录更新周期内的新增数据,即在原表中数据的基础上新增本周期内产生的新数据,没变化的数据不会被记录;
增量表的典型特征:
-
增量表是相对于全量表而言的,增量表是每次把新增的数据追加到原表中;
-
记录每次增加的量,而不是总量(只报变化量,无变化不用报);
-
存在分区,增量表中每次新增的数据单独存储在一个分区中,历史分区中的数据记录不发生变化。
增量表的典型范例:
增量表,就是记录每天新增数据的表。比如:从24号到25号新增了哪些数据,改变了哪些数据,这些都会存储在增量表在25号的分区里面。
增量表和快照表中【分区时间】分别代表什么?
- 快照表中时间分区 t 日,实际代表第 t+1日,例如:快照表中的25号分区和24号分区实际时间分别对应26号和25号),它俩的数据相减就是实际时间25号到26号有变化的、增加的数据,也就相当于增量表里面25号分区的数据。
- 增量表中时间分区t日,实际代表第 t 日。
流量和存量的定义与区别:
• 流量: 是指在一定时间内的增量,流量一般设计成增量表(日报-常用、月报);
• 存量: 是指在一定时间内的总量,存量一般设计成总量表;
• 流量和存量的区别: 流量是增量,存量是总量;
2.3 快照表
快照表: 就是截至过去某个时间点的所有数据,主要对过去某个时间点的数据状态进行记录,即:快照表主要存储的是历史状态的表,每个快照的数据单独存储在一个分区中。
快照表的适用场景:
为解决全量表无法查询历史数据的情况,引入了快照表。快照表是有时间分区的,每个分区里的数据都是分区时间对应的前一天的所有全量数据,比如:当前数据表有3个分区,24号、25号、26号。其中,24号分区里面的数据就是从历史到23号的所有数据,25号分区里面的数据就是从历史到24号的所有数据,以此类推。
快照表的典型特征: 按照时间分区进行数据存储;
快照表的优缺点:
• 优点:可实现对历史数据的查询;
• 缺点:数据量大时,由于每个分区都存储了许多重复数据,非常浪费存储空间。
快照表的典型范例:
快照表用来存储截止过去某个时间点的所有数据,比如:一些用户特征的表、标签表、订单状态表等多存储于快照表中,其实快照表也有所区分,本质是一段时间内数据的记录,主要还是看底层报表开发人员的逻辑。
-
有些快照表某分区的数据是从历史到此分区前一天的所有数据,如:12号分区中的数据是从历史到11号的所有数据,13号分区中的数据是从历史到12号的所有数据,其他的以此类推。
-
有些快照表某分区的数据是从历史到此分区的所有数据,如:12号分区中的数据是从历史到12号的所有数据,13号分区中的数据是从历史到13号的所有数据,其他的以此类推。
日常工作中我们也会经常用到快照表,以前不懂的时候就取好几个分区,导致取了大量且重复的数据, 实际上快照表最近的一个分区就存储了从历史到当前分区的所有数据 ,我们只需要取一个分区就可满足取数需求。
2.4 流水表
流水表: 对于表的每一个修改都会记录,可以用于反映实际记录的变更。
流水表的典型特征:
-
流水表是存储了所有修改记录的表。
-
流水表是每天的交易形成的历史;
-
流水表用于统计业务相关情况;
-
流水表与拉链表也有些类似,不同的是拉链表可以根据拉链粒度存储数据,也就是只存储特定维度的数据变化记录;而流水表存储的是每一个修改记录( 拉链表与流水表的区别 )。
2.5 拉链表
鉴于全量表、快照表的缺点,为了在保留所有状态的情况下,有效节省存储空间,引入了拉链表。
2.5.1 拉链表的基本属性
拉链表: 是一种维护历史状态,以及最新状态数据的一种表,记录数据从开始一直到当前状态所有变化的信息。
拉链表的典型特征:
记录一个事物从开始,一直到当前状态的所有变化的信息;
拉链表每次上报的都是历史记录的最终状态,是记录在当前时刻的历史总量;
拉链表通常是对账户信息的历史变动进行处理保留的结果;
拉链表用于统计账户及客户的情况;
拉链表和增量表的共同点:表结构基本一样。
与快照表类似,但拉链表存储的是在快照表的基础上去除了重复状态的数据 ,也就是说一些不变的信息在快照表中每个分区都会存储一份,可能造成存储浪费,而使用拉链表在更新频率和比例不是很大的情况下会十分节省存储。(
拉链表与快照表的区别 )。拉链表的封链时间可以是2999,3000,9999等等比较大的年份;拉链表到期时数据要报0;
拉链表的适用场景:
当数据量较大,表中某些字段有变化,但变化频率不是很高,而业务需求又需要统计这种变化状态,如果每天存储一份全量数据,不仅浪费存储空间,且不便于业务统计;这时,拉链表的作用就体现出来了,既节省空间,又满足需求。
在数据仓库的数据模型设计过程中,经常会遇到这样的需求:
-
数据量比较大;
-
表中的部分字段会被update,例如:用户的地址、产品的描述信息、订单的状态等等;
-
业务需要:(1)查看某一个时间点或者时间段的历史快照信息,比如:查看某一个订单在历史某一个时间点的状态;(2)统计订单信息的变化频次,比如:查看某一个用户在过去某一段时间内,更新过几次等等;
-
信息变化的比例和频率不是很大,比如:总共有1000万会员,每天新增和发生变化的有10万左右;
此时,如果对张表每天都保留一份全量,那么每次全量中会保存很多不变的信息,这对存储是极大的浪费;拉链表,既能满足反应数据的历史状态,又能最大程度地节省存储空间。
拉链表的优缺点:
• 优点:(1)保留了数据的历史信息;(2)节省存储空间;
• 缺点:同步和回滚逻辑复杂;
3.5.2 拉链表的典型范例
拉链表的典型范例:
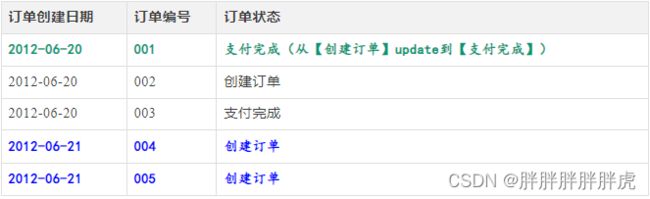
举个简单例子,比如有一张订单表,6月20号有3条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2012-06-20 | 001 | 创建订单 |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
到6月21日,表中有5条记录:
到6月22日,表中有6条记录:
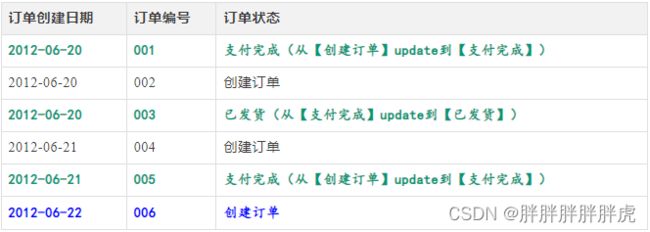
数据仓库中对该表的保留方法:
-
只保留一份全量,则最终的表数据和6月22日的记录一样,如果需要查看6月21日订单001的状态,则无法满足;
-
每天都保留一份全量,则数据仓库中的该表共有14条记录,但好多记录都是重复保存,没有任何变化,例如:订单002、004,数据量大了,会造成很大的存储浪费;
如果在数据仓库中设计成 历史拉链表 来保存数据,则会有下面这样一张表:
一般在数仓中通过增加 dw_begin_date,dw_end_date两个字段来表征 历史拉链表 。
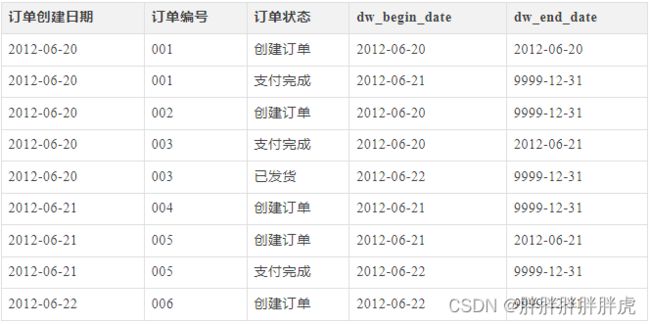
表中的字段及使用说明:
• dw_begin_date:表示该条记录的生命周期开始时间;
• dw_end_date:表示该条记录的生命周期结束时间;
• dw_end_date = ‘9999-12-31’:表示该条记录目前处于有效状态;
• 拉链表可以记录一条数据从开始到当前的所有历史信息,便于查询历史数据。
- 如果查询当前所有有效的记录,则
select * from order_his where dw_end_date = ‘9999-12-31′- 如果查询2012-06-21的历史快照,则
select * from order_his where dw_begin_date <= ‘2012-06-21′ and end_date >= ‘2012-06-21’,这条语句会查询到以下记录;- 通过dw_end_date过滤2020-06-02之前的旧数据;
- 通过dw_begin_date过滤2020-06-02之后的新数据。
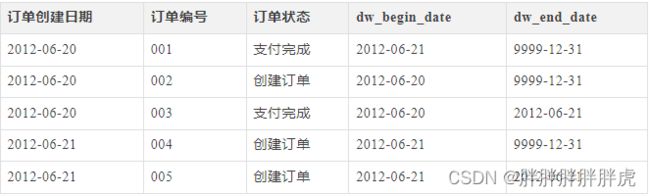
和源表在6月21日的记录完全一致:

可以看出,这样的历史拉链表,既能满足对历史数据的需求,又能很大程度的节省存储资源;
转自:https://mp.weixin.qq.com/s/Fq0iEY6gdHvSRZSeRNxlaA
参考:
1、真正秒懂增量表、全量表和拉链表: https://blog.csdn.net/Jun2613/article/details/106688930
2、 hive中拉链表: https://www.cnblogs.com/wujin/p/6121754.html
3、一文搞定数据仓库之拉链表,流水表,全量表,增量表: https://blog.csdn.net/mtj66/article/details/78019370
4、 数据仓库数据模型之:极限存储–历史拉链表: http://lxw1234.com/archives/2015/04/20.htm
5、 拉链表: https://hopefulnick.github.io/2020/10/17/201017%E6%8B%89%E9%93%BE%E8%A1%A8/
6、拉链表(二): https://zhuanlan.zhihu.com/p/76254774
7、你应该知道的全量表、增量表、快照表、拉链表: https://toutiao.io/posts/njwsij1/preview