spark笔记
spark 分布式计算框架
spark 不是部署分布式的 只是client而已 =》 hive
spark 支持分布式部署 =》 standalone
1.spark产生背景?
1.mr、hive批处理、离线处理 存在一些局限性:
1.mr api 开发复杂
2.只能做离线计算 不能做实时计算
3.性能不高
2.什么是spark?
1.spark.apache.org
1.计算引擎 【不关注数据存储】
2.特点
1.Batch/streaming data =》 批流一体
2.SQL analytics
3.Data science at scale
4.Machine learning
3.速度快:
1.spark基于内存计算
2.DAG 有向无环图
mr1=>mr2=>mr3
算子 链式编程
3.pipline 【通道的】
4.编程模型 线程级别的
4.易用性:
1.开发语言: java、scala、python、sql
2.封装好了多种外部数据源
3.80多个高级算子
5.通用性:
子模块
sparkcore =》 离线计算
sparksql =》 离线计算
sparkstreaming、structstreaming =》 实时计算
mllib =》 机器学习
图计算 =》 图处理
spark的子模块 之间可以进行交互式使用
6.运行作业的地方
1.yarn ***
2.mesos
3.k8s ***
4.standalone[spark本身集群 ]
3.hadoop生态圈 vs spark 生态圈
1.Batch:mr、hive vs sparkcore、sparksql
2.SQL:hive、impala vs sparksql
3.stream:storm vs sparkstreaming、sss
4.MLLib: Mahout vs MLlib
5.real 存储: HBase、cassandra vs DataSouce Api
sparkcore
rdd 开发 降低开发人员的开发成本
什么是rdd ?
1.“弹性 分布式 数据集”
2.数据集:
partitions: 元素 =》 一条一条的数据
3. 可以以并行的方式进行计算
1.弹性?容错 =》 计算的时候 可以重试
2.分布式?
1.存储
rdd: 1 2 3 4 5 6
partition1:1 2 3
partition2:4 5
partition3:6
2.计算
对rdd进行操作实际上是操作 rdd分区里面的数据
3.数据集: 就是构建rdd本身的数据
4.immutable 不可变的
不可变=》 rdda 通过计算/操作得到一个新的rdd
5.partitioned collection of elements 【rdd 可以被分区存储/计算的】
一个rdd是由多个partition所构成
rdd数据存储是分布式的 ,是跨节点进行存储的
6.elements that can be operated on in parallel =》 计算
对rdd进行操作 就是对rdd底层partition里面的元素进行操作
abstract class RDD[T: ClassTag](
@transient private var sc: SparkContext,
@transient private var deps: Seq[Dependency[]]
) extends Serializable with Logging {
1.abstract
2.T 泛型 =》 限定rdd里面数据 是什么类型的
RDD[String]、RDD[Int] 、RDD[Student]
3.Serializable 序列化 =》数据经过网络传输
4.@transient 注解 这个属性就不需要序列化 【了解】
RDD五大特性[面试】
1.rdd底层存储一系列partition
2.针对rdd做计算/操作其实就是对rdd底层的partition进行计算/操作
3.rdd之间的依赖关系 (血缘关系)
rdd 不可变 rdda => rddb => rddc
4.Partitioner => kv类型的rdd
默认分区:hash
5.数据本地性 =》 减少数据传输的网络io
优先把作业调度在数据所在节点 =》 【理想状况】
【常见计算】
作业调度在别的节点上 ,数据在另外一台节点上
只能把数据通过网络把数据传输到 作业所在节点上去进行计算
构建sparkcore 作业
1.添加依赖:
org.apache.spark
spark-core_2.12
3.2.1
2.Initializing Spark:
1. SparkContext =》 sparkcore 程序入口
tells Spark how to access a cluster.
2.SparkConf =》 指定 spark app 详细信息
1.AppName => 作业名字
2.Master =》 作业运行在什么地方 spark作业的运行模式
local、yarn、standalone、k8s、mesos
1.local[k]模式 k 指的是线程数
2.standalone spark://HOST:PORT
3.yarn
yarn 两种模式: client模式
cluster模式
4.k8s k8s://HOST:PORT
3.创建rdd
1. parallelize existing collection =》 已经存在的集合
2. makeRDD 已经存在的集合
2.referencing a dataset in an external storage system =》外部数据源 =》 textFile
1.外部数据源存储
hdfs、local、hbase、s3、cos、
2.数据文件类型:
text files, SequenceFiles, and any other Hadoop InputFormat
3.从已经存在rdd转换生成一个新的rdd
val conf: SparkConf = new SparkConf().setAppName("Spark01App").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
// 存在的集合方式创建rdd
val arr: Array[Int] = Array(1, 2, 3, 4, 5)// scala
val rdd: RDD[Int] = sc.parallelize(arr) // spark弹性分布式数据集
println(rdd.partitions.size)
val rddArr: Array[Int] = rdd.collect()// 将rdd变成数组输出
rddArr.foreach(println(_))
println("====================")
val rdd1: RDD[Int] = sc.parallelize(arr, 10) // 修改分区=>task
println(rdd1.partitions.size)
val rdd2array: Array[Int] = rdd1.collect()
rdd2array.foreach(println(_))
println("====================")
sc.stop()
val conf: SparkConf = new SparkConf().setAppName("Spark01App").setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
// 外部存储系统的方式创建rdd
val distFile: RDD[String] = sc.textFile("data/wc.data")
println(distFile.partitions.size)
distFile.collect().foreach(println(_))
distFile.saveAsTextFile("file:home/hadoop/tmp/spark/spark01")
distFile.saveAsTextFile("hdfs://bigdata12:9000/spark/spark01")
println("======================")
val distRdd2: RDD[String] = sc.textFile("data/wc.data", 10)
println(distRdd2.partitions.size)
distRdd2.collect().foreach(println(_))
distRdd2.saveAsTextFile("file:home/hadoop/tmp/spark/spark02")
distRdd2.saveAsTextFile("hdfs://bigdata12:9000/spark/spark02")
sc.stop()
spark-shell
spark-shell :
–master spark作业运行环境
–deploy-mode yarn模式 运行选择
–class spark作业包 运行主类main class 包名
–name 指定spark作业的名字
–jars 指定第三方的依赖包
–conf 指定spark作业配置参数
yarn 参数补充:
–num-executors 指定 申请资源的参数
–executor-memory 指定 申请资源的参数
–executor-cores 指定 申请资源的参数
–queue 指定作业 运行在yarn的哪个队列上
spark-shell 交互式命令 底层调用 =》 spark-submit
开发者 主要使用的脚本 用于提交用户自己开发的spark作业
为什么spark-shell webui名字 是Spark shell?如何修改 --name
spark-core 如何触发作业的执行呢?
1、sparkcore里面 触发作业的执行 必须使用action算子
2.创建rdd 是不会触发作业的执行
task数为什么是2?
有多少个partition就有多少个task去处理我们的数据
跟我们运行模式有关系
spark =》 hdfs 生成的文件数量 跟什么有关系?
spark => hdfs => tasks数 =》 parition数
rdd 里面parition有多少个 =》 文件落地有多少个文件
封装
1.隐式转换添加功能
package com.dl2262.sparkcore.function
import org.apache.spark.rdd.RDD
object ImplictAsRdd {
implicit def rdd2RichRdd[T](rdd:RDD[T]):RichRdd[T]={
new RichRdd[T](rdd)
}
}
class RichRdd[T](rdd:RDD[T]){
def print(num:Int)={
num match {
case 0 => rdd.foreach(println(_));println("===========")
case _ =>
}
}
}
2.封装重复代码
package com.dl2262.sparkcore.util
import org.apache.spark.{SparkConf, SparkContext}
object ContextUtils {
def getSparkContext(appName:String,master:String="local[2]")={
val conf: SparkConf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)
}
}
RDD 相关的操作
1.transformations 【转换操作】:create a new dataset from an existing one
1.All transformations in Spark are lazy =》 懒加载
rdda => rddb =>rddc => 不会立即执行 不会触发job的执行 当有action才会执行
rdd.map().fitler =》 rdd 血缘关系
map相关的算子:
1.map : 一一映射 处理rdd里面每一个元素
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
// map
val rdd: RDD[Int] = sc.parallelize(List(3, 4, 5, 6))
val mapData: RDD[Int] = rdd.map(x => x * 2)
mapData.foreach(x => println(x))
println("====================")
val array: Array[Int] = mapData.collect()
array.foreach(x => println(x))
println("==============")
sc.stop()
2.filter
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
// filter
val rdd1: RDD[Int] = sc.parallelize(1 to 10)
val filterRdd: RDD[Int] = rdd1.filter(_ % 2 == 0).filter(_ > 8)
filterRdd.foreach(println(_))
println("================")
val filterRdd2: RDD[Int] = rdd1.filter(x => x % 2 == 0 && x > 8)
filterRdd2.foreach(println(_))
println("==============")
import com.dl2262.sparkcore.function.ImplictAsRdd._
filterRdd2.print(0)
filterRdd2.print(1)
filterRdd2.print(0)
sc.stop()
3.mapPartitions 按分区处理数据 调优比map
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val rdd: RDD[Int] = sc.parallelize(List(1, 2, 4))
val rdd2: RDD[Int] = sc.makeRDD(List(1, 2, 3))
rdd.map(x=>{
println("调用")
x*2
}).print(0)
println(rdd.partitions.size)
println("=========")
rdd.mapPartitions(partition=>{
println("调用")
partition.map(x=>x*2)
}).print(0)
sc.stop()
需求: spark-core: map filter =》 不让用 如何实现其功能?实现底层MapPartitionsRDD
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
val rdd: RDD[Int] = sc.parallelize(1 to 10)
new MapPartitionsRDD[Int,Int](rdd,(_,_,iter)=>iter.map(_*2)).foreach(println(_))
sc.stop()
4.makeRDD = parallelize
5.mapPartitionsWithIndex 可以查看 rdd里面每个分区对应的数据
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val rdd: RDD[Int] = sc.parallelize(List(1, 2, 3, 4))
rdd.mapPartitionsWithIndex((index,partition) => {
partition.map(x => s"分区的下标${index},分区的元素${x}")
}).foreach(println(_))
println("=================")
sc.stop()
6.mapvalues 针对kv类型对v做处理
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val rdd: RDD[Int] = sc.parallelize(List(1, 2, 3, 4))
rdd.map(x => (x,1)).mapValues(v => v+1).print(0)
sc.stop()
7.flatMap 一一映射 底层也是MapPartitionsRDD
flatmap = flatten + map flatten => 压扁的
flatMap =》 更改原始数据结构的 map 不会改变数据结构
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val rdd1: RDD[List[Int]] = sc.parallelize(List(List(1, 2), List(3, 4)))
val value: RDD[List[Int]] = rdd1.map(x => x.map(_ * 2))
val value1: RDD[Int] = rdd1.flatMap(x => x.map(_ * 2))
sc.stop()
other算子:
1.glom : 把每一个分区的元素作为一个数组返回 比mapPartitionsWithIndex
val value2: RDD[Array[Int]] = sc.parallelize(1 to 9).glom()
scala> value2.collect
res0: Array[Array[Int]] = Array(Array(1, 2, 3, 4), Array(5, 6, 7, 8, 9))
2.sample 抽样
sc.parallelize(1 to 20).sample(true,0.4,10).print(0)
3.union : 简单数据合并 不去重 不要与sql : union union all弄混
val rdd2: RDD[Int] = sc.parallelize(1 to 3)
val rdd3: RDD[Int] = sc.parallelize(2 to 5)
rdd2.union(rdd3).print(0)
4.intersection 交集
val rdd2: RDD[Int] = sc.parallelize(1 to 3)
val rdd3: RDD[Int] = sc.parallelize(2 to 5)
rdd2.intersection(rdd3).print(0)
5.subtract 差集:显示a里面不含有b的元素
val rdd2: RDD[Int] = sc.parallelize(1 to 3)
val rdd3: RDD[Int] = sc.parallelize(2 to 5)
rdd2.subtract(rdd3).print(0)
rdd3.subtract(rdd2).print(0)
6.distinct 去重 *** 默认采用分区器: hash
hash分区:某个元素%分区总数
sc.parallelize(List(4,4,4,5,5,5,6,6,6)).distinct().print(1)
val rdd4: RDD[Int] = sc.parallelize(List(4, 4, 4, 5, 5, 5, 6, 6, 6, 7, 8, 9, 10, 10))
rdd4.distinct(4).mapPartitionsWithIndex((index,partition)=>{
partition.map(x => s"分区号:${index},元素:${x}")
}).print(0)
case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)// 底层调用map+reduceByKey+map完成对数据的key去重
需求: disctint =》 不使用distinct 完成数据去重?
val rdd5: RDD[Int] = sc.parallelize(List(1, 1, 1, 2, 2, 2, 3, 3, 3))
rdd5.map(x => (x,null)).reduceByKey((x,y) =>{
x
}).map(x => x._1).print(0)
kv类型的算子
1.groupByKey 按key进行分组 不要使用 效率低 不灵活 , mapSideCombine = false 没有开启的 发送数据 网络io 没有变化的
预聚合mapSideCombine: 减少map端输出的数据量 =》 减少网络io
map :
(a,1)
(a,1)
(a,1)
(b,1)
(b,1)
combine: 预聚合 按照map端输出的key进行聚合数据
(a,3)
(b,2)
reduce:
(a,3)
(b,2)
a,<3>
b,<2>
预聚合:前提: + - 操作 =》 预聚合开启
求平均值操作 =》 预聚合 结果数据 不对
val wc: RDD[(String, Int)] = sc.parallelize(List(("a", 1), ("b", 2), ("c", 2), ("a", 10)))
val groupbyData: RDD[(String, Iterable[Int])] = wc.groupByKey()
groupbyData.print(0)
(a,CompactBuffer(1, 10))
(b,CompactBuffer(2))
(c,CompactBuffer(2))
groupbyData.mapValues(x => x.sum).print(0)
(b,2)
(a,11)
(c,2)
wc.map(x =>(x._2,x._1)).groupByKey().print(0)
(1,CompactBuffer(a))
(10,CompactBuffer(a))
(2,CompactBuffer(b, c))
2.reduceByKey mapSideCombine = true + func,按照key进行分组对value进行操作
val wc: RDD[(String, Int)] = sc.parallelize(List(("a", 1), ("b", 2), ("c", 2), ("a", 10)))
wc.reduceByKey((x,y) => { //相同key后面的value
x+y
}).print(0)
(b,2)
(a,11)
(c,2)
3.groupby 自定义分组
val rdd6: RDD[String] = sc.parallelize(List("a", "a", "a", "a", "b", "b", "b"))
rdd6.groupBy(x => x).print(0)
val wc: RDD[(String, Int)] = sc.parallelize(List(("a", 1), ("b", 2), ("c", 2), ("a", 10)))
wc.groupBy(x => x._1).print(0)
(b,CompactBuffer(b, b, b))
(a,CompactBuffer(a, a, a, a))
===========
(b,CompactBuffer((b,2)))
(a,CompactBuffer((a,1), (a,10)))
(c,CompactBuffer((c,2)))
4.sortByKey =》按照key进行排序 分区排序 默认升序
想要全局排序的前提是rdd的分区只有一个
val rdd7: RDD[(String, Int)] = sc.parallelize(List(("zuan", 18), ("kaige", 20), ("doublehappy", 21)),1)
rdd7.sortByKey().print(0)
rdd7.sortByKey(false).print(0)
rdd7.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)).print(0)
(doublehappy,21)
(kaige,20)
(zuan,18)
===========
(zuan,18)
(kaige,20)
(doublehappy,21)
===========
(doublehappy,21)
(kaige,20)
(zuan,18)
5.sortby 自定义排序 灵活
val rdd7: RDD[(String, Int)] = sc.parallelize(List(("zuan", 18), ("kaige", 20), ("doublehappy", 21)),1)
rdd7.sortBy(x => x._2,false).print(0)
rdd7.sortBy(x => -x._2).print(0)
(doublehappy,21)
(kaige,20)
(zuan,18)
===========
(doublehappy,21)
(kaige,20)
(zuan,18)
6.join
val rdd7: RDD[(String, Int)] = sc.parallelize(List(("zuan", 18), ("kaige", 20), ("doublehappy", 21)))
val rdd8: RDD[(String, String)] = sc.parallelize(List(("zuan", "广西"), ("kaige", "中国"), ("doublehappy", "大连")))
rdd7.join(rdd8).print(0)
(doublehappy,(21,大连))
(zuan,(18,广西))
(kaige,(20,中国))
7.cogroup
val rdd7: RDD[(String, Int)] = sc.parallelize(List(("zuan", 18), ("kaige", 20), ("doublehappy", 21)))
val rdd8: RDD[(String, String)] = sc.parallelize(List(("zuan", "广西"), ("kaige", "中国"), ("doublehappy", "大连")))
rdd7.cogroup(rdd8).print(0)
(zuan,(CompactBuffer(18),CompactBuffer(广西)))
(doublehappy,(CompactBuffer(21),CompactBuffer(大连)))
(kaige,(CompactBuffer(20),CompactBuffer(中国)))
join vs cogroup
1.操作对象都是kv类型的
2.都是根据key进行关联
3.join返回值类型是RDD[(k,(option[v],option[w]))],cogroup的返回值类型是RDD[(k,(Iterable[v],Iterable[w]))],一个直接返回值,一个返回集合
4.join底层调用cogroup算子
scala:option 有就返回some 没有就返回none
val rdd7: RDD[(String, Int)] = sc.parallelize(List(("zuan", 18), ("kaige", 20), ("doublehappy1", 21)))
val rdd8: RDD[(String, String)] = sc.parallelize(List(("zuan", "广西"), ("kaige", "中国"), ("doublehappy", "大连")))
rdd7.join(rdd8).print(0)
rdd7.cogroup(rdd8).print(0)
(zuan,(18,广西))
(kaige,(20,中国))
===========
(doublehappy,(CompactBuffer(),CompactBuffer(大连)))
(kaige,(CompactBuffer(20),CompactBuffer(中国)))
(zuan,(CompactBuffer(18),CompactBuffer(广西)))
(doublehappy1,(CompactBuffer(21),CompactBuffer()))
转换算子常用的:map、flatmap、filter、mappartitions、distinct
kv:groupby、sortby、reducebykey、mapvalues
补充:zipWithIndex,生成kv,v是从0-n
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
rdd9.zipWithIndex().print(0)
(3,2)
(1,0)
(4,3)
(2,1)
(5,4)
2.actions 【触发job执行的操作】把服务器上的rdd拉到driver上 action算子不能再接一个action算子
which return a value to the driver program 【spark client、控制台】after running a computation on the dataset【rdd】
1.collect() 把rdd数据集拉到控制台上以数组形式显示
2.foreach() => 输出 driver 循环输出每一个元素
1.控制台
2.hdfs 不这样用
3.db
3.foreachPartition 按照分区循环输出 调优比foreach 获取链接次数少
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
rdd9.foreach(x =>{
println("调用")
println(x)
})
println("==================")
rdd9.foreachPartition(partition => {
println("调用")
partition.foreach(x => println(x))
})
4.reduce
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val res: Int = rdd9.reduce((x, y) => {
x + y
})
println(res)
15
rdd9.reduce(_+_)
5.first 和take(n)取数据集里面第一个到第n个的元素
first底层调用的是take算子
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val first: Int = rdd9.first()
println(first)
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val arr: Array[Int] = rdd9.take(3)
arr.foreach(print(_))
6.saveAsTextFile
7.top 和 takeOrdered 数据量不要太大 控制台拉回过程中也需要进行数据存储的,存储到内存
top是降序取前n个数据集, takeOrdered 是升序取前n个数据集
top底层是takeOrdered实现的
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val top: Array[Int] = rdd9.top(3)
top.foreach(println(_))
5
4
3
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val array: Array[Int] = rdd9.takeOrdered(2)
array.foreach(println(_))
1
2
8.countByKey 针对kv类型的rdd,按照key进行分组,统计key的数量
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val countbykey: collection.Map[Int, Long] = rdd9.zipWithIndex().countByKey()
countbykey.foreach(println(_))
(5,1)
(1,1)
(2,1)
(3,1)
(4,1)
9.collectAsMap把rdd转换为map输出,对比collect将rdd转换为数组输出
val rdd9: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val collectasmap: collection.Map[Int, Long] = rdd9.zipWithIndex().collectAsMap()
collectasmap.foreach(println(_))
(2,1)
(5,4)
(4,3)
(1,0)
(3,2)
10.count 返回rdd里面元素的个数
val rdd10: RDD[Int] = sc.parallelize(List(2, 5, 7, 9))
val cnt: Long = rdd10.count()
println(cnt)
4
action常用的算子:foreach()、foreachpartition()
思考: spark-core xxxBykey算子都是 转换算子 对么?
大部分 xxxBykey算子 =》 transformation算子 ,除了countByKey() =》 aciton算子
源码里面 :sparkcount.runjob => 触发作业的执行 =》 action算子
spark-core =》 业务分析
商品名字 商品价格 库存数量
dior 300 1000
香奈儿 4000 2
螺蛳粉 200 98
3090显卡 200 10
按照商品的价格进行【desc】排序 如果价格相同 按照库存排序【asc】
rdd:
1.常用数据类型:
1.tuple 推荐
2.class 不推荐
1.object not serializable ?
如果作业和数据不在一个节点时,要把数据拉取到作业所在节点,数据拉取的过程中需要进行网络传输,经过网络传输首先你的数据一定要实现序列化,如果不实现序列化是无法进行网络传输的
解决: extends Serializable
2.输出格式 不标准
override def toString
3.case class 推荐!!!
1.默认实现了 序列化
2.重写了 tostring方法
3.不用new可以直接用
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("dior 300 1000",
"香奈儿 4000 2",
"螺蛳粉 200 98",
"3090显卡 200 10"),1)
val etlData: RDD[(String, Int, String)] = input.map(line => {
val array: Array[String] = line.split("\t")
val name: String = array(0)
val price: Int = array(1).toInt
val cnt: String = array(2)
(name, price, cnt)
})
etlData.sortBy(x => (-x._2,x._3)).print(0)
etlData.sortBy(x => (-x._2,x._3)).saveAsTextFile("hdfs://bigdata12:9000/spark/spar01")
sc.stop()
(香奈儿,4000,2)
(dior,300,1000)
(3090显卡,200,10)
(螺蛳粉,200,98)
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("dior 300 1000",
"香奈儿 4000 2",
"螺蛳粉 200 98",
"3090显卡 200 10"), 1)
val etlData: RDD[Sku] = input.map(line => {
val array: Array[String] = line.split("\t")
val name: String = array(0)
val price: Double = array(1).toDouble
val cnt: Int = array(2).toInt
new Sku(name, price, cnt)
})
etlData.sortBy(x => (-x.price,x.cnt)).print(0)
etlData.sortBy(x => (-x.price,x.cnt)).saveAsTextFile("hdfs://bigdata12:9000/spark/spark01")
sc.stop()
}
class Sku(val name:String,val price:Double,val cnt:Int) extends Serializable{
override def toString: String = name + "\t" + price + "\t" + cnt
}
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("dior 300 1000",
"香奈儿 4000 2",
"螺蛳粉 200 98",
"3090显卡 200 10"), 1)
val etlData: RDD[SKU] = input.map(line => {
val array: Array[String] = line.split("\t")
val name: String = array(0)
val price: Double = array(1).toDouble
val cnt: Int = array(2).toInt
SKU(name, price, cnt)
})
etlData.sortBy(x => (-x.price,x.cnt)).print(0)
//etlData.sortBy(x => (-x.price,x.cnt)).saveAsTextFile("hdfs://bigdata12:9000/spark/spark02")
sc.stop()
}
case class SKU(val name:String,val price:Double,val cnt:Int)
按照 对象本身进行排序:
1.实现 排序的接口
Ordering =》 compareable
Ordered =》 comparetor
2.隐士转换 普通类 =》 nb类
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("dior 300 1000",
"香奈儿 4000 2",
"螺蛳粉 200 98",
"3090显卡 200 10"), 1)
val etlData: RDD[SKu] = input.map(line => {
val array: Array[String] = line.split("\t")
val name: String = array(0)
val price: Double = array(1).toDouble
val cnt: Int = array(2).toInt
new SKu(name, price, cnt)
})
etlData.sortBy(x => x).print(0)
sc.stop()
}
class SKu(val name:String,val price:Double,val cnt:Int) extends Serializable with Ordered[SKu]{
override def toString: String = name+"\t"+price+"\t"+cnt
override def compare(that: SKu): Int = {
if (-(this.price - that.price).toInt == 0){
this.cnt - that.cnt
} else {-(this.price - that.price).toInt}
}
}
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("dior 300 1000",
"香奈儿 4000 2",
"螺蛳粉 200 98",
"3090显卡 200 10"), 1)
val etlData: RDD[sku] = input.map(line => {
val array: Array[String] = line.split("\t")
val name: String = array(0)
val price: Double = array(1).toDouble
val cnt: Int = array(2).toInt
new sku(name, price, cnt)
})
implicit def sku2Ordered(sku:sku):Ordered[sku]={
new Ordered[sku] {
override def compare(that: sku): Int = {
if (-(sku.price-that.price).toInt==0){
sku.cnt-that.cnt
} else {
-(sku.price-that.price).toInt
}
}
}
}
etlData.sortBy(x => x).print(0)
sc.stop()
}
class sku(val name:String,val price:Double,val cnt:Int) extends Serializable {
override def toString: String = name+"\t"+price+"\t"+cnt
}
案例
eg:
word,show,click
a,1,2
a,2,3
b,3,4
输出: a,3,5
b,3,4
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("a,1,2",
"a,2,3",
"b,3,4"))
val etl: RDD[(String, (Int, Int))] = input.map(line => {
val array: Array[String] = line.split(",")
val word: String = array(0)
val show: Int = array(1).toInt
val click: Int = array(2).toInt
(word, (show, click))
})
/**
* a,(1,2)
* a,(2,3)
* a,<(1,2),(2,3)>
*/
etl.reduceByKey((x,y) => {
(x._1+y._1,x._2+y._2)
}).map(x => (x._1+"\t"+x._2._1+"\t"+x._2._2)).print(0)
sc.stop()
}
核心概念
1.Application:spark作业
1.a driver program =》 driver
2.executors on the cluster =》 executors
spark作业:
1.sparkcontext
2. web ui
2.Application jar: 通过代码生成的spark jar包
spark作业生成的jar包 =》 包含spark作业里面含有main方法 =》 开发完spark作业后部署服务器上
3.Driver program:
1.运行jar包里面的main 方法
2.创建sparkcontext
4.Cluster manager: 通过集群获取资源 An external service for acquiring resources
5.Deploy mode: 作业部署模式 spark jar 提交服务器去运行 =》 yarn yarn调度有两种模式
cluster: driver inside of the cluster driver跑在yarn所在的机器里面
client driver 运行在集群cluster之外,在哪提交作业的地方
6.Worker node: 工作节点 can run application code 一个Worker node包含多个Executor
补充: spark作业 yarn
Worker node相当于yarn里面的nodemanager
7.Executor: 相当于yarn里面的container: 容器 包含mem、cpu
1.runs tasks
2.keeps data in memory or disk storage
Each application has its own executors spark作业,每个作业运行过程中,都有自己的container,申请自己的资源
application1: 1driver + 2executor
application2: 1driver + 2executor 这两个executor是不一样的
8.Task: 任务等于rdd: partitions个数
9.Job:
action => job执行
spark作业 =》 Application
job =》 Application里面的jobs
10.Stage:
1.Each job gets divided into smaller sets of tasks => stage
2. depend on each other 依赖关系
总结:
一个application :包含 1 到n 个job
一个job: 包含 1到n个stage
rdda => rddb => rddc action => 一个job
01stage 02stage
一个stage:包含 1个到n个task
task 和 partition 一一对应
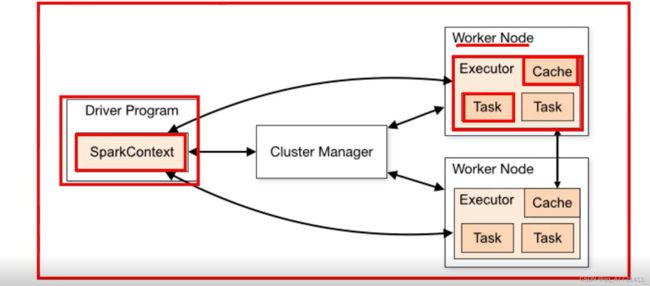
spark执行流程【面试】
1.spark作业运行在集群上 有一系列进程
2.SparkContext 去协调这些进程
进程 :
driver 1
executors
3.运行spark作业:
1.sc 去连接 集群cluster manager
2.只要连接到集群,cluster manager 给spark作业分配资源
3.spark一旦连接上cluster
1.启动executor
2.executor =》 计算和存储数据
4.
sparkcontext 发送代码 给executor
sparkcontext 发送task 去executor 运行
补充: mem、CPU
1.worknode =》 nodemanager 所在的节点
executor=》 container:
task、store data
4.spark执行架构补充:
1.每个spark作业有自己的executor进程
app1: executors 1
app2: executors 1
好处:
1.资源隔离,这个作业申请的executor,别的作业不能用
2.调度的隔离,每个driver调度自己的任务
不同作业之间数据是不能进行共享的,除非把数据存储在外部存储系统上
案例
数据:
用户:
uid log_type show click
u01,英雄联盟|绝活&职业|云顶之一|女神,1,1
u01,英雄联盟|绝活&职业|云顶之一|金铲铲,1,0
u01,英雄联盟|绝活&职业|云顶之一|带粉上车,1,0
u02,星秀|好声音|女团|小6,1,0
u02,星秀|好声音|女团|三年一班,1,1
u02,星秀|好声音|女团|姜恩惠Yommy,1,1
需求: 每个用户每个日志类型的 展现量 和点击量 =》 spark-core
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("u01,英雄联盟|绝活&职业|云顶之一|女神,1,1",
"u01,英雄联盟|绝活&职业|云顶之一|金铲铲,1,0",
"u01,英雄联盟|绝活&职业|云顶之一|带粉上车,1,0",
"u02,星秀|好声音|女团|小6,1,0",
"u02,星秀|好声音|女团|三年一班,1,1",
"u02,星秀|好声音|女团|姜恩惠Yommy,1,1"))
val etlData: RDD[((String, String), (Int, Int))] = input.flatMap(line => {
val array: Array[String] = line.split(",")
val uid: String = array(0)
val show: Int = array(2).toInt
val click: Int = array(3).toInt
val logtypes: String = array(1)
val logs: Array[String] = logtypes.split("\\|")
logs.map(log => ((uid, log), (show, click)))
})
etlData.reduceByKey((x,y) => {
(x._1+y._1,x._2+y._2)
}).map(line => {
line._1._1+"\t"+line._1._2+"\t"+line._2._1+"\t"+line._2._2
}).print(0)
sc.stop()
}
RDD持久化
rddb 持久化操作 =》 调优的
操作:
1.persist() or cache() methods
2.触发action之后 会对rdd数据进行持久化的
总结:
1.cache() 是lazy 是懒加载的 不是action算子
rdda => action job
rdda => cache => action job => rdd持久化 生效
rdda => action job rdda的数据从 rdd持久化的地方加载数据
rddb.cache 之后 rddb之后数据就不用从头开机计算 提升计算效率
补充: 对rdd做持久化 就是对rdd里面的分区做持久化
好处: 1.much faster 【计算效率】
2. reuse 复用
cache vs persist(更好) 区别:【面试】
1.cache底层就是调用 persist算子
2.spark-core 持久化 默认存储级别:StorageLevel.MEMORY_ONLY
存储级别
StorageLevel:
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val DISK_ONLY_3 = new StorageLevel(true, false, false, false, 3)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
存储级别选择:
1.MEMORY_ONLY 首选
2.MEMORY_ONLY_SER 次选 (cpu充足时)
1.Java serialization: By default,
2.Kryo: 注册 class 比java快
3.不建议选择磁盘
4.不要选择副本 太占内存
object Spark14App {
case class Info(name:String,age:Int,gender:String,address:String)
def main(args: Array[String]): Unit = {
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val names: Array[String] = Array("金社子", "刘裕众", "小歪歪的狗子")
val genders: Array[String] = Array("男", "女")
val addresses: Array[String] = Array("大连", "广西", "北京")
val infoes: ArrayBuffer[Info] = new ArrayBuffer[Info]()
(1 to 30000).map(x => {
val name: String = names(Random.nextInt(3))
val gender: String = genders(Random.nextInt(2))
val address: String = addresses(Random.nextInt(3))
val age: Int = Random.nextInt(40)
infoes += (Info(name,age,gender,address))
})
val data: RDD[Info] = sc.parallelize(infoes)
data.persist()// 10.3M
data.persist(StorageLevel.MEMORY_ONLY_SER)// 7.6M 默认是java 类需要序列化 样例类默认是实现序列化
// Kryo 8.6M 性能比java高
data.count()
sc.stop()
}
}
object ContextUtils {
def getSparkContext(appName:String,master:String="local[2]")={
//val conf: SparkConf = new SparkConf().set("spark.serializer","org.apache.spark.serializer.KryoSerializer").setAppName(appName).setMaster(master)
val conf: SparkConf = new SparkConf().setAppName(appName).setMaster(master)
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[Info]))
new SparkContext(conf)
}
}
移除rdd持久化 :
1.lru 会自动移除不常用的持久化数据
2.手动 :【生产】
RDD.unpersist(true) 立即执行的 eager
血缘关系
lineage: rdda => rddb => rddc
一个rdd是如何从父rdd计算得来的
好处: 容错(性能 + 容错)
rddb某个分区挂了时,直接从rdda对应的分区进行重新计算即可

而且 本身持久化的数据集 也支持 容错 重新进行计算
依赖关系
rdda => rddb
不同的依赖 会导致 生成rdd分区数发生变化的
分类:【面试】
1.宽依赖:
1.一个父rdd的parition会被子rdd的parition使用多次
2.会产生shuffle(数据重新洗牌) 会有新的stage产生
2.窄依赖:
1.一个父rdd的parition至多被子rdd的partition使用一次
2.不会产生shuffle,都是在一个stage里面完成的
宽依赖:
xxxbykey shuffle
其他: 普通/reducejoin
窄依赖:
mapjoin、map filter flatmap union
spark: stage是如何划分? ****
spark-core 产生 宽依赖 就会划分stage
算子:引起shuffle 就会划分stage
一个shuffle算子 会划分2个stage,两个shuffle算子 会产生3个stage
shuffle 算子
“生产上能使用窄依赖算子 就不使用宽依赖算子”:
1.不准确
1.生产上大部分 需求 必须使用宽依赖的
2.容错的角度 :
1.如果经过宽依赖之后的rdd的某一个分区数据挂掉
需要去父RDD分区重新计算 会把父rdd里面的所有分区都会算一下才行
引起shuffle的算子:
1.xxxbykey =》
2. repartition and coalesce【不准确】
3. join:
map join 不会引发shuffle
reduce join /common join =》 引起shuffle
生产上调整 计算的并行度:【重要】
coalesce: 一般用于 减少rdd的分区数 =》 窄依赖 =》 不会引起shuffle 减少并行度task少了
data.coalesce(1)
repartition:增加rdd的分区数 会引起shuffle data.repartition(3)
coalesce(num,shuffle=true)
思考:
可不可以使用coalesce 增加rdd分区数 ? 可以的 data.coalesce(4,true)
repartition 减少rdd的分区数? 不能
思考: coalesce 增加rdd分区数 ? 走不走shuffle? 必然走shuffle
思考:
rdd =》 hdfs 200个小文件 变成10个文件
rdd.coalesce(10)
区分代码里的driver和executor
主要看操作对象
操作对象是rdd的就是executor
操作对象不是rdd的就是driver
案例
网站访问量排名:
domain uid flow
www.baidu.com,uid01,1
www.baidu.com,uid01,10
www.baidu.com,uid02,3
www.baidu.com,uid02,5
www.github.com,uid01,11
www.github.com,uid01,10
www.github.com,uid02,30
www.github.com,uid02,50
www.bibili.com,uid01,110
www.bibili.com,uid01,10
www.bibili.com,uid02,2
www.bibili.com,uid02,3
需求: 每个域名每个用户的访问量的top2
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("www.baidu.com,uid01,1",
"www.baidu.com,uid01,10",
"www.baidu.com,uid02,3",
"www.baidu.com,uid02,5",
"www.github.com,uid01,11",
"www.github.com,uid01,10",
"www.github.com,uid02,30",
"www.github.com,uid02,50",
"www.bibili.com,uid01,110",
"www.bibili.com,uid01,10",
"www.bibili.com,uid02,2",
"www.bibili.com,uid02,3"))
val etlData: RDD[((String, String), Int)] = input.map(line => {
val array: Array[String] = line.split(",")
val domain: String = array(0)
val uid: String = array(1)
val flow: Int = array(2).toInt
((domain, uid), flow)
})
val res1: RDD[((String, String), Int)] = etlData.reduceByKey((x, y) => {
x + y
})
res1.groupBy(x => x._1._2).mapValues(x => x.toList.sortBy(x => -x._2).map(x => (x._1._1,x._2)).take(2)).print(0)
sc.stop()
存在安全隐患: x.toList 数据太大时会直接导致List存不下
sparkcore 进行数据分析: rdd进行操作 不要使用scala里面的集合进行存储
思想: 分而治之 类似 mr 分组
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val input: RDD[String] = sc.parallelize(List("www.baidu.com,uid01,1",
"www.baidu.com,uid01,10",
"www.baidu.com,uid02,3",
"www.baidu.com,uid02,5",
"www.github.com,uid01,11",
"www.github.com,uid01,10",
"www.github.com,uid02,30",
"www.github.com,uid02,50",
"www.bibili.com,uid01,110",
"www.bibili.com,uid01,10",
"www.bibili.com,uid02,2",
"www.bibili.com,uid02,3"))
val etlData: RDD[((String, String), Int)] = input.map(line => {
val array: Array[String] = line.split(",")
val domain: String = array(0)
val uid: String = array(1)
val flow: Int = array(2).toInt
((domain, uid), flow)
})
//val uids: Array[String] = Array("uid01", "uid02")
// collect只有在这种情况下才使用,适用于数据量小
val uids: Array[String] = etlData.map(_._1._2).distinct().collect()
for (elem <- uids) {
etlData.filter(x => x._1._2 == elem).reduceByKey(_+_).sortBy(x => -x._2).take(2).foreach(println(_))
}
sc.stop()
案例二
需求:
spark-core =》 wc
input:hdfs
todo:wc
output:hdfs
在resources里面添加core-site.xml和hdfs-site.xml
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val in: String = "hdfs://bigdata12:9000/input/"
val out: String = "hdfs://bigdata12:9000/output/"
val input: RDD[String] = sc.textFile(in)
FileUtils.deletePath(sc.hadoopConfiguration,out)
input.flatMap(line => {
line.split(",")
}).map(x => (x,1)).reduceByKey(_+_).saveAsTextFile(out)
sc.stop()
def deletePath(conf:Configuration,outpath:String)={
val fs: FileSystem = FileSystem.get(conf)
val out: Path = new Path(outpath)
if (fs.exists(out)){
fs.delete(out,true)
}
}
部署spark作业:
1.jar
2.spark-submit 提交作业
local法一:
def main(args: Array[String]): Unit = {
if (args.size != 2){
logError("请正确输入两个参数: " )
System.exit(0)
}
val in: String = args(0)
val out: String = args(1)
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
// val in: String = "hdfs://bigdata12:9000/input/"
// val out: String = "hdfs://bigdata12:9000/output/"
val input: RDD[String] = sc.textFile(in)
FileUtils.deletePath(sc.hadoopConfiguration,out)
input.flatMap(line => {
line.split(",")
}).map(x => (x,1)).reduceByKey(_+_).saveAsTextFile(out)
sc.stop()
}
spark-submit \
--class com.dl2262.sparkcore.day01.WCAPP \
--master local[2] \
--name wordcount \
/home/hadoop/project/spark/spark-2262-1.0.jar \
hdfs://bigdata12:9000/input/ hdfs://bigdata12:9000/output/
local法二:
def main(args: Array[String]): Unit = {
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
import com.dl2262.sparkcore.function.ImplictAsRdd._
val in: String = sc.getConf.get("spark.input.path", "hdfs://bigdata12:9000/input/")
val out: String = sc.getConf.get("spark.output.path", "hdfs://bigdata12:9000/output/")
val input: RDD[String] = sc.textFile(in)
FileUtils.deletePath(sc.hadoopConfiguration,out)
input.flatMap(line => {
line.split(",")
}).map(x => (x,1)).reduceByKey(_+_).saveAsTextFile(out)
sc.stop()
}
spark-submit \
--class com.dl2262.sparkcore.day01.WCAPP \
--master local[2] \
--name wordcount \
--conf spark.input.path=hdfs://bigdata12:9000/input/1 \
--conf spark.output.path=hdfs://bigdata12:9000/output1/ \
/home/hadoop/project/spark/spark-2262-1.0.jar.0
sparksql
1.什么是sparksql?
sparksql 主要处理结构化数据
什么是结构化数据?
“带有schema信息的数据” 【schema :table 字段的名称、字段的类型】eg:mysql
半结构化数据: csv(可以用excel打开)、json、orc、parquet
非结构化数据: nosql – redis、hbase
2.在spark里面 Spark SQL 模块 :不仅仅是sql 、还有dataframe
3.sparksql 有哪些特性?
0.sparksql dataframe api vs 同时sparkcore里面使用的算子在sparksql里面也可以使用的
1.Sparksql= sql + dataframe api 处理 结构化数据
2.Uniform data access 【外部数据源】
SparkSQL 是能够处理多种不同的数据源的数据:
Hive, Avro, Parquet, ORC, JSON, and JDBC text 数据
HDFS/s3(亚马逊)/oss(阿里)/cos(腾讯) 数据存储系统
3.Hive integration [整合hive(数据仓库)]
SparkSQL访问hive的元数据库即 可利用sparksql查询hive里面的数据
注意:
1.Sparksql 不仅仅是sql
2. hive on spark vs spark on hive
hive on spark : hive查询引擎是 mr=》 spark 【几乎不用,bug很多】
spark on hive :可以使用sparksql 去hive上查询数据 【可能hive 引擎是mr】【99.953%】
概述
概述:
1.sparksql 处理数据的性能比 spark rdd 方式的处理性能高
1.more information about the structure of both the data 【schema】
2.sparksql架构有关
sparksql底层跑的还是 Sparkcore rdd ,只是spark框架底层给我们做了优化
sparkcore:编程模型 rdd
sparksql: rdd[数据集] +schema[字段 字段的类型] =》 table
2.Spark SQL including SQL and the Dataset API
3.Datasets and DataFrames:
Dataset
1.Dataset 也是一个分布式数据集
2.比rdd多出的优势:
1.强类型
2.Dataset 也可以使用算子
3.optimized execution engine. 执行性能 高 【sparksql架构 catelyst 做了很多优化】
4.Dataset 是Spark 1.6 之后诞生的
3.Dataset API :scala java进行开发
DataFrame:
1.DataFrame 也是一个dataset
A DataFrame is a Dataset organized into named columns
2.DataFrame四种创建方式:
structured data files, tables in Hive, external databases, or existing RDDs
3. DataFrame is represented by a Dataset of Rows:
DataFrame = Dataset[Row]
Row => 一行数据 仅仅包含 named columns
DataFrame =》 table
sparkcore=> rdd 数据集
sparksql=》 DataFrame /df 数据集 【数据集 + 额外的信息【schema】】
rdd + schema => table
Sparksql:
1.0: schemaRDD : rdd(存数据)+ schema(数据的(额外信息:元数据):字段、字段类型) =》 table
=》1.2/3
=> DataFrame =>schemaRDD 变过来的
=》1.6
=》 DataSet =》 DataFrame 变过来的
DataFrame /df vs rdd:
区别:
1.rdd : 不同的语言开发的 rdd ,执行性能是不一样
java和scala(会被语言转换为jvm去运行)、python(pathon会转化成自己的运行时数据区去运行,pathon开发rdd性能没有java和scala高)
2.DataFrame/df:使用不同的开发语言 执行性能是一样的 (spark底层逻辑优化=》物理执行计划=》rdd执行,此时执行性能和语言就没有关系了),df比rdd开发简单
java、scala、python、r

开发 DF
1.idea里面开发sparksql
引入 sparksql依赖:
org.apache.spark
spark-sql_2.12
3.2.1
2.SparkSQL程序开发入口 :
1.rdd =》 SparkContext
2.SQL =》 SparkSession
获取df后会立即触发job,不是懒加载
3.SparkSQL进行数据分析:
1.sql方式 【好维护】
2.api方式【不好维护】
开发df:
1.sql 【idea api+sql 或者 hive sql文件 】
2.api 【一般用于 开发平台、工具】
1.api方式 =》
api =》 sql 一一对应
1.加载df中某个字段
select(“字段名字”) =》 string
select(col: String, cols: String*):
1. select(“字段名字”) =》 推荐
2. select($“字段名字”) + 隐士转换 import spark.implicits._
可以调用sql里面的函数
补充: df.select('age)
select(cols: Column*):
import org.apache.spark.sql.functions._
df.select(col(“age”))
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
// val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate()
val df: DataFrame = spark.read.text("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\wc.data")
df.select("age").show()
df.select("age","name").show()
import spark.implicits._
df.select($"age").show()
df.select($"age",$"name"+1).show()
df.select('age).show()
import org.apache.spark.sql.functions._
df.select(col("age")).show()
spark.stop()
2.sql方式进行操作
spark.sql(“select count(1) as cnt from test”).show()
开发数仓:
1.sql文件 维护数仓 =》 推荐 好维护
2.idea : 不好维护 udf函数比较方便
1.sql方式维护数仓 =》 有公司这么干的 【滴滴】
2.api方式维护数仓 =》 有公司这么干的
1.通用性的 代码来维护 code开发能力有要求 难度大
案例
df.show(2) 显示2条数据 默认显示20条数据
df.show(2,false) 显示2条数据,显示所有字符串长度,默认截至字符串20字节
df.printSchema() 显示数据集的字段名字和字段类型
需求分析
1、table中数据条数
2.table中所有人薪资总和
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
val df: DataFrame = spark.read.json("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\emp.json")
df.show(2)
df.printSchema()
import spark.implicits._
df.groupBy().count().select($"count".as("cnt")).show()
df.groupBy().sum("salary").select($"sum(salary)".as("sum_sal")).show()
df.createOrReplaceTempView("tmp")
spark.sql(
"""
|select count(1) as cnt from tmp
|""".stripMargin).show()
spark.sql(
"""
|select sum(salary) as sum_sal from tmp
|""".stripMargin).show()
spark.stop()
构建dataframe
三种方式:
existing RDD, from a Hive table, or from Spark data sources.
1.existing RDD
RDD =》dataframe 有两种方式:
1.反射的方式
2.编程的方式
1.RDD[Row]
2.schema
3.createDataFrame =>df
rdd + schema => table
schema: table 元数据【字段名字、字段的类型】 =》 StructType
fileds: 一个字段的元数据 =》 StructField
反射的方式创建:
object SparkSQL03 {
case class Info(uid:String,name:String,age:Int)
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
val sc: SparkContext = spark.sparkContext
val input: RDD[String] = sc.textFile("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\info.txt")
// rdd里面的数据结构case class 和tuple
val inputDF: DataFrame = input.map(line => {
val array: Array[String] = line.split(",")
val uid: String = array(0)
val name: String = array(1)
val age: Int = array(2).toInt
Info(uid, name, age)
}).toDF()
inputDF.show(5,false)
inputDF.printSchema()
val inputDF2: DataFrame = input.map(line => {
val array: Array[String] = line.split(",")
val uid: String = array(0)
val name: String = array(1)
val age: Int = array(2).toInt
(uid, name, age)
}).toDF("uid","name","age")
inputDF2.show(5,false)
inputDF2.printSchema()
spark.stop()
}
}
编程方式创建:
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
val sc: SparkContext = spark.sparkContext
val input: RDD[String] = sc.textFile("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\info.txt")
val rowRDD: RDD[Row] = input.map(line => {
val array: Array[String] = line.split(",")
val uid: String = array(0)
val name: String = array(1)
val age: Int = array(2).toInt
Row(uid, name, age)
})
val schema: StructType = StructType(Array(StructField("uid", StringType), StructField("name", StringType), StructField("age", IntegerType)))
val inputDF: DataFrame = spark.createDataFrame(rowRDD, schema)
inputDF.show(10,false)
inputDF.printSchema()
spark.stop()
相互转换【面试】
如何把rdd转变成df、ds?
rdd =》 toDF / => toDS
如何把 df/ds => rdd ?
df/ds.rdd
df 如何转变成ds ?
df.as[数据类型] =》 ds
val inputDS: Dataset[(String, String, Int)] = input.map(line => {
val array: Array[String] = line.split(",")
val uid: String = array(0)
val name: String = array(1)
val age: Int = array(2).toInt
(uid, name, age)
}).toDS()
val rdd: RDD[Row] = inputDF2.rdd
val dataset: Dataset[Info] = inputDF.as[Info]
构建 DataFrame
1.rdd
2.hive ***
3.外部数据源 *** json、csv、jdbc/odbc
1.读数据 api
spark.read.format(“text”).load(paths : _) =》 df
spark.read.format(“json”).load(paths : _)
spark.read.textFile(path) =》ds
2.写数据 api
df.write.mode(SaveMode.Overwrite).format(“text”).save(path)
df.write.mode(SaveMode.Append).format(“json”).save(path)
text文件
本身是不带有schema信息 【字段 value string 】
text 比 json csv 带有的schema信息偏少,只有一个value字段
1.text文件加载进来之后 需要解析数据 需要引入隐式转换
2.文本类型不支持Int类型
3.写数据时
Text data source supports only a single column, and you have 3 columns.
Text仅仅支持一列(一个字段)输出 不支持多列输出
使用sparksql 支持text多列输出?
1.自定义外部数据源 =》 难度
2.df 转变成rdd方式进行输出 =》 常用的手段
spark.read.text:
package com.dl2262.sparkcore.day02
import com.dl2262.sparkcore.util.{ContextUtils, FileUtils}
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}
object DataSource01 {
def text(spark: SparkSession, path: String) = {
import spark.implicits._
val df: DataFrame = spark.read.format("text").load(path)
df.show(false)
df.printSchema()
val data: DataFrame = df.map(row => { // df.map之后是dataset
val line: String = row.getString(0) // 读取第一个字段,text里面只有value一个字段
val array: Array[String] = line.split(",")
val uid: String = array(0)
val name: String = array(1)
val age:String = array(2)
(uid, name, age)
}).toDF("uid", "name", "age")
data.show(false)
data.printSchema()
val outpath: String = "hdfs://bigdata12:9000/spark/spark02"
FileUtils.deletePath(spark.sparkContext.hadoopConfiguration,outpath)
data.rdd.map(row => row.getString(0)+","+row.getString(1)+","+row.getString(2)).saveAsTextFile(outpath)
//data.write.mode(SaveMode.Overwrite).format("text").save("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\out-text")
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
// text df
text(spark,"file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\info.txt")
spark.stop()
}
}
spark.read.textFile:
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.{ContextUtils, FileUtils}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object DataSourceText02 {
def text(spark: SparkSession, path: String) = {
import spark.implicits._
val ds: Dataset[String] = spark.read.textFile(path)
ds.show()
ds.printSchema()
val data: DataFrame = ds.map(line => {
val array: Array[String] = line.split(",")
val uid: String = array(0)
val name: String = array(1)
val age: String = array(2)
(uid, name, age)
}).toDF("uid", "name", "age")
data.printSchema()
data.show()
val outpath: String = "hdfs://bigdata12:9000/spark/spark02"
FileUtils.deletePath(spark.sparkContext.hadoopConfiguration,outpath)
data.rdd.map(row => row.getString(0)+","+row.getString(1)+","+row.getString(2)).saveAsTextFile(outpath)
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
// text ds
text(spark,"file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\info.txt")
spark.stop()
}
}
json
1.普通json
2.嵌套json:
1.api:
struct:打点
array:expolde + struct:打点
2.sql:
hive
struct:打点
array:expolde + struct:打点
3.不规范json =》udf函数来解决
数据输出:
数据写出方式:
1.覆盖 overwrite
2.追加 append
普通json:
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object DataSourceJson01 {
def json(spark: SparkSession, path: String) = {
import spark.implicits._
val input: DataFrame = spark.read.format("json").load(path)
input.show()
input.printSchema()
input.createOrReplaceTempView("city_info")
spark.sql(
"""
|select count(1) as cnt from city_info
|""".stripMargin).write.mode(SaveMode.Overwrite).format("json").save("hdfs://bigdata12:9000/spark/spark03")
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
// 普通json
json(spark,"file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\city_info.json")
spark.stop()
}
}
嵌套json API:
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object DataSourceJson02 {
def json(spark: SparkSession, path: String) = {
import spark.implicits._
var jsonData: DataFrame = spark.read.format("json").load(path)
jsonData.show(false)
jsonData.printSchema()
import org.apache.spark.sql.functions._
jsonData=jsonData.withColumn("color",col("store.bicycle.color")) // 增加一个列或替代以及存在的一列
jsonData=jsonData.withColumn("price",col("store.bicycle.price"))
jsonData=jsonData.withColumn("fruit",explode(col("store.fruit")))
jsonData=jsonData.withColumn("type",col("fruit.type"))
jsonData=jsonData.withColumn("weight",col("fruit.weight"))
jsonData=jsonData.drop("store","fruit")
jsonData.show(false)
jsonData.printSchema()
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
// 嵌套json API
json(spark,"file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\store.json")
spark.stop()
}
}
嵌套json sql:
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.{DataFrame, SparkSession}
object DataSourceJsonSQL {
def json(spark: SparkSession, path: String) = {
val data: DataFrame = spark.read.format("json").load(path)
data.show(false)
data.printSchema()
data.createOrReplaceTempView("store_json")
val etl: DataFrame = spark.sql(
"""
|select
|email,
|owner,
|store.bicycle.color as color,
|store.bicycle.price as price,
|fruit.type as type,
|fruit.weight as weight
|from store_json
|lateral view explode(store.fruit) as fruit
|""".stripMargin)
etl.show(false)
etl.printSchema()
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
// 嵌套json sql
json(spark,"file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\store.json")
spark.stop()
}
}
csv
csv文件 excel=> spark-excel
1.可以使用excel打开
2.默认字段之间的分割符 , [可以进行更改]
常用参数:
read:
1.sep 分割符 ,
2.header 第一行作为table中的字段
3.inferSchema 类型推断功能
4.encoding 指定读取的csv文件的字符集 默认utf-8
write:
compression
sep
encoding
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object DataSourceCSV01 {
def csv(spark: SparkSession, path: String) = {
val data: DataFrame = spark.read.option("sep",";")
.option("header","true")
.option("inferSchema","true")
.format("csv").load(path)
import spark.implicits._
data.show(false)
data.printSchema()
data.createOrReplaceTempView("csv")
spark.sql(
"""
|select
|city_id,city_name,area
|from csv
|where lower(city_name)='beijing'
|""".stripMargin)
data.write.option("compression","gzip").mode(SaveMode.Overwrite).format("csv").save("hdfs://bigdata12:9000/spark/spark04")
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
// csv
csv(spark,"file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\city_info.csv")
spark.stop()
}
}
jdbc
1.目前这种写法 :
加载数据 性能不高:
1.直接表table 数据全部加载过来 , 再进行筛选 性能不高
加载数据: 谓词下压: 首选!!!先进性where 加载数据 性能高
2.写数据:
1.在mysql上先创建一个table
CREATE TABLE rpt_zihang_sum (
uid varchar(20) DEFAULT NULL,
name varchar(20) DEFAULT NULL,
sku varchar(20) DEFAULT NULL,
os varchar(20) DEFAULT NULL,
cnt int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.write
mysql
mysql-connector-java
5.1.49
package com.dl2262.sparksql.day02
import java.util.Properties
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object DataSourceJDBC01 {
def jdbc(spark: SparkSession) = {
val inputsql =
"""
|select *
|from dept
|where deptno=10
|""".stripMargin
val data: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://bigdata12:3306/bigdata")
.option("dbtable", s"($inputsql) as tmp")
.option("user", "root")
.option("password", "123456")
.load()
data.show(false)
data.printSchema()
val url = "jdbc:mysql://bigdata12:3306/bigdata"
val table = "dept01"
val properties: Properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
data.write.mode(SaveMode.Append).jdbc(url,table,properties)
}
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
jdbc(spark)
spark.stop()
}
}
sparksql整合hive
1.linux环境 spark 整合hive 【生产集群环境 配置】
2.代码开发 idea
1.生产环境
placing your hive-site.xml,
core-site.xml (for security configuration), and
hdfs-site.xml (for HDFS configuration) file in conf/.
把hive-site.xml, core-site.xml ,hdfs-site.xml 放置spark安装目录 conf文件下即可
之前spark 跑yarn上 : 已经配置了hadoop配置文件路径的参数 ,core-site.xml ,hdfs-site.xml是不需要再次配置在conf目录下
1.可以的 [不推荐]:cp hive_home/conf/hive-site.xml spark_home/conf/
2.最好使用软连接:[hadoop@bigdata12 conf]$ ln -s /home/hadoop/app/hive/conf/hive-site.xml ./hive-site.xml
spark-shell =》 hive : 报错:没有mysql驱动
spark整合hive,只需要spark作业能够访问hive metastore即可,hive的metastore在mysql里
spark作业添加mysql驱动:
1.linux环境变量里面 添加 mysql驱动包 【不常用】
2.当前spark作业 添加mysql驱动即可
spark:
driver
executor 每个executor都要有 mysql驱动jar包
启动spark-sql 脚本:
spark-sql --master local[2]
–jars /home/hadoop/software/mysql-connector-java-5.1.28.jar
–driver-class-path /home/hadoop/software/mysql-connector-java-5.1.28.jar
测试:
spark.sql(“show databases”).show()
spark.sql(“show tables in bigdata”).show()
spark.sql(“select * from bigdata.city_info”).show()
select count(1),city_name from city_info group by city_name
spark.sql(“select count(1),city_name from bigdata.city_info group by city_name”).show()
spark-shell => test
spark-submit => 用于提交用户 自己开发spark作业 jar
spark-sql => 类比于 hive
启动spark-sql 脚本:
spark-sql --master local[2]
–jars /home/hadoop/software/mysql-connector-java-5.1.28.jar
–driver-class-path /home/hadoop/software/mysql-connector-java-5.1.28.jar
补充: database namespace 都是指数据库
数据分析:数仓里面的数据
ad-hoc: 临时查询、测试
hive 脚本 :
分析少用
建表
spark-sql脚本:分析用
建议不要建表【sparksql hive 建表 有小问题 可以用】
hive function =》 spark绝对有
spark里面有的东西 =》 hive 未必有
维护数仓: 数据导入到xxl、airflow
hive -e/-f xxx.sql => mr
spark-sql -e/-f xxx.sql => sparksql => 推荐的方式 离线数仓 好维护 简单
=》 idea api 方式 不太推荐 离线数仓 不好维护
idea
1.在resources里面导入hive-site.xml并导入hive依赖包
org.apache.spark
spark-hive_2.12
3.2.1
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.SparkSession
object DataSourceHive01 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
import org.apache.spark.sql.functions._
val data = spark.sql(
"""
|select * from bigdata.city_info
|""".stripMargin)
data.printSchema()
data.show(false)
spark.stop()
}
}
案例
id visit_dt visit_cnt
u01 2017/1/21 5
u02 2017/1/23 6
u03 2017/1/22 8
u04 2017/1/20 3
u01 2017/1/23 6
u01 2017/2/21 8
u02 2017/1/23 6
u01 2017/2/22 4
create table user_log (
uid string,
visit_dt string,
visit_cnt int
)
row format delimited fields terminated by ','
load data local inpath '/home/hadoop/tmp/user.log' overwrite into table user_log;
需求:
要求使用sql 统计出 每个用户的累计访问次数
uid 月份(month) cnt 累计cnt
u01 2017-01 11 11
u01 2017-02 12 23
1.每个用户每个月的 访问次数
2.累计访问次数
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.SparkSession
object DataSourceHive02 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
import org.apache.spark.sql.functions._
val data = spark.sql(
"""
|select
|uid,
|month,
|cnt,
|sum(cnt) over(partition by uid order by month) as total_cnt
|from(
|select
|uid,
|date_format(replace('visit_dt','/','-'),'yyyy-MM') as month,
|sum(visit_cnt) as cnt
|from bigdata.user_log
|group by uid,month
|) as a
|""".stripMargin)
data.show(false)
data.printSchema()
spark.stop()
}
}
案例
需求:
mysql数据:
city_info、 城市表
product_info 商品表
{“product_status”:1}
1表示自营
0表示第三方
日志数据:user_click.txt
1.按照区域求最受欢迎【点击次数】的商品的 top3
2.统计每个城市每个商品状态[自营/非自营]的最受欢迎的商品
1.使用sparksql 代码的方式做需求,并把结果数据写入mysql
2.需求需要 部署在xxl上进行调度,调度周期 t+1
3.将结果数据进行可视化展示,使用superset:
1.可视化要求:必须要使用下拉框,其他图表任意使用
4.整理整个需求的思路架构图
临时需求:
1.数据源在不同位置:
1.把多种数据源数据 全部放到 hive 统一进行处理 【推荐】
2.sparksql 集成code 把各种各样的数据源都加载sparksql里 形成dataframe 不同dataframe可以进行数据交互 一般用于临时开发
input:
mysql:2table =》 sparksql =》 2df
日志数据:hdfs => sparksql => df
todo:
1.按照区域求最受欢迎【点击次数】的商品的 top3
2.统计每个城市每个商品状态[自营/非自营]的最受欢迎的商品
output: mysql
部署: xxl: T+1 报警
spark-submit jar
数据可视化: superset
idea 打包方式:
瘦包 仅仅把编好的代码打入到 jar里面 ,版本升级时不需要进行改动
胖包:除了打入编好的代码之外还会打入需要的依赖到jar里面
缺点: 160M * 1000 =》 linux 数据量太大
不建议: 把需要的jar包直接导入到spark里面的jars里,会脏了 spark 环境,导入的jar包很容易和spark里面的jar包冲突,导致spark用不了了,或版本升级后可能会导致jar包冲突
package com.dl2262.sparksql.day03
import java.util.Properties
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}
object UserLogApp {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
import org.apache.spark.sql.functions._
val city_info: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://bigdata12:3306/bigdata")
.option("dbtable", "city_info")
.option("user", "root")
.option("password", "123456")
.load()
val product_info: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://bigdata12:3306/bigdata")
.option("dbtable", "product_info")
.option("user", "root")
.option("password", "123456")
.load()
city_info.show(false)
product_info.show(false)
//spark.read.format("text").load("hdfs://bigdata12:9000//user/hive/warehouse/bigdata.db/user_click/")
val logData: Dataset[String] = spark.read.textFile("hdfs://bigdata12:9000//user/hive/warehouse/bigdata.db/user_click/")
val userLog: DataFrame = logData.map(line => {
val splits: Array[String] = line.split(",")
val uid: String = splits(0)
val session_id: String = splits(1)
val dt: String = splits(2)
val city_id: String = splits(3)
val product_id: String = splits(4)
(uid, session_id, dt, city_id, product_id)
}).toDF("uid", "session_id", "dt", "city_id", "product_id")
userLog.show(3,false)
city_info.createOrReplaceTempView("city_info")
product_info.createOrReplaceTempView("product_info")
userLog.createOrReplaceTempView("user_log")
spark.sql(
"""
|drop table if exists bigdata.dws_user_log
|""".stripMargin)
spark.sql(
"""
|create table bigdata.dws_user_log as
|select
|a.city_id,
|a.product_id,
|area,
|product_name
|from(
|select
|city_id,
|product_id
|from user_log
|) as a left join(
|select
|city_id,
|area
|from city_info
|) as b
|on a.city_id=b.city_id
|left join(
|select
|product_id,
|product_name
|from product_info
|)as c
|on a.product_id=c.product_id
|""".stripMargin)
spark.sql(
"""
|drop table if exists bigdata.rpt_user_log_click_rank
|""".stripMargin)
spark.sql(
"""
|create table bigdata.rpt_user_log_click_rank as
|select
|area,
|product_name,
|cnt,
|row_number() over(partition by area order by cnt desc) as rk
|from(
|select
|area,
|product_name,
|count(*) as cnt
|from bigdata.dws_user_log
|group by area,product_name
|) as a
|""".stripMargin)
val rpt = spark.sql(
"""
|select
|area,
|product_name,
|cnt,
|rk
|from bigdata.rpt_user_log_click_rank
|where rk <= 3
|""".stripMargin)
rpt.show(false)
val url = "jdbc:mysql://bigdata12:3306/bigdata"
val table = "rpt_cnt_top3"
val properties: Properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
rpt.write.mode(SaveMode.Append).jdbc(url,table,properties)
spark.stop()
}
}
def getSparkSession(appName:String,master:String="local[2]")={
SparkSession.builder()
//.appName(appName).master(master)
.enableHiveSupport().getOrCreate()
}
spark-submit \
--master local[2] \
--name userlog \
--class com.dl2262.sparksql.day03.UserLogApp \
--jars /home/hadoop/software/mysql-connector-java-5.1.28.jar \
--driver-class-path /home/hadoop/software/mysql-connector-java-5.1.28.jar \
/home/hadoop/project/spark/spark-2262-1.0.jar.1
以yarn方式进行部署【面试】
-
client : driver =》 client机器(提交机器) cluster: driver =》 集群内部的
2.提交作业有关
cluster :
提交作业 client作业提交 client就可以关闭了 对spark作业是没有影响的
client:
提交作业 client作业提交 如果client关闭了 driver process 挂了 对spark作业有影响的
3.输出日志
client =》 可以直接查看日志
cluster =》 yarn上去看运行日志
spark-submit \
--master yarn \
--deploy-mode client \
--name userlog \
--executor-memory 1G \
--num-executors 1 \
--executor-cores 1 \
--class com.dl2262.sparksql.day03.UserLogApp \
--jars /home/hadoop/software/mysql-connector-java-5.1.28.jar \
--driver-class-path /home/hadoop/software/mysql-connector-java-5.1.28.jar \
/home/hadoop/project/spark/spark-2262-1.0.jar.1
spark-submit \
--master yarn \
--deploy-mode cluster \
--name userlog \
--executor-memory 1G \
--num-executors 1 \
--executor-cores 1 \
--class com.dl2262.sparksql.day03.UserLogApp \
--jars /home/hadoop/software/mysql-connector-java-5.1.28.jar \
--driver-class-path /home/hadoop/software/mysql-connector-java-5.1.28.jar \
--driver-library-path /home/hadoop/software/mysql-connector-java-5.1.28.jar \
/home/hadoop/project/spark/spark-2262-1.0.jar.1
数据写入hive
1.sql方式: hivesql
普通表
1.hive创建一张普通表
2.insert :
insert into
insert overwrite 【常用】
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.SparkSession
object DataSourceHive02 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
import org.apache.spark.sql.functions._
val data = spark.sql(
"""
|select
|uid,
|month,
|cnt,
|sum(cnt) over(partition by uid order by month) as total_cnt
|from(
|select
|uid,
|date_format(replace('visit_dt','/','-'),'yyyy-MM') as month,
|sum(visit_cnt) as cnt
|from bigdata.user_log
|group by uid,month
|) as a
|""".stripMargin)
data.show(false)
data.printSchema()
/**
* sql方式写入数据
* 1.在hive里建普通表
* 2.insert进hive表里
*/
data.createOrReplaceTempView("result")
// spark.sql(
// """
// |--不推荐 ctas
// |create table bigdata.result01 as
// |select * from result
// |""".stripMargin)
// spark.sql(
// """
// |insert into table bigdata.result01
// |select * from result
// |""".stripMargin)
spark.sql(
"""
|insert overwrite table bigdata.result01
|select * from result
|""".stripMargin)
spark.stop()
}
}
分区表 :
1.hive创建一张分区表
2.insert :
into
overwrite
静态分区:
动态分区:
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.SparkSession
object WriteHive02 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
import org.apache.spark.sql.functions._
val data = spark.sql(
"""
|select
|uid,
|month,
|cnt,
|sum(cnt) over(partition by uid order by month) as total_cnt
|from(
|select
|uid,
|date_format(replace('visit_dt','/','-'),'yyyy-MM') as month,
|sum(visit_cnt) as cnt
|from bigdata.user_log
|group by uid,month
|) as a
|""".stripMargin)
data.show(false)
data.printSchema()
/**
* sql方式写入数据
* 1.在hive里面建分区表
* 2.insert进hive表里
*/
data.createOrReplaceTempView("result")
// spark.sql(
// """
// |--1.静态分区
// |insert overwrite table bigdata.result02 partition(month='2017-01')
// |select
// |uid,
// |cnt,
// |total_cnt
// |from result
// |where month='2017-01'
// |""".stripMargin)
spark.conf.set("hive.exec.dynamic.partition","true")
spark.conf.set("hive.exec.dynamic.partition.mode","nonstrict")
spark.sql(
"""
|--1.动态分区
|insert overwrite table bigdata.result02 partition(month)
|select
|uid,
|cnt,
|month,
|total_cnt
|from result
|""".stripMargin)
spark.stop()
}
}
2.api方式
table:
普通表
分区表
写入方式:
append
overwrite
package com.dl2262.sparksql.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.{SaveMode, SparkSession}
object WriteApiHive01 {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
import org.apache.spark.sql.functions._
val data = spark.sql(
"""
|select
|uid,
|month,
|cnt,
|sum(cnt) over(partition by uid order by month) as total_cnt
|from(
|select
|uid,
|date_format(replace('visit_dt','/','-'),'yyyy-MM') as month,
|sum(visit_cnt) as cnt
|from bigdata.user_log
|group by uid,month
|) as a
|""".stripMargin)
data.show(false)
data.printSchema()
/**
* Api写入数据
*/
// 普通表
// saveAsTable普通表会自动建表
data.write.mode(SaveMode.Append).format("hive").saveAsTable("bigdata.result03") data.write.mode(SaveMode.Overwrite).format("hive").saveAsTable("bigdata.result03")
data.createOrReplaceTempView("tmp")
val mon_data=spark.sql(
"""
|select * from tmp where month='2017-01'
|""".stripMargin)
// 分区表
// saveAsTable(不能用!!!):会自动建表 api默认是动态分区
spark.conf.set("hive.exec.dynamic.partition","true")
spark.conf.set("hive.exec.dynamic.partition.mode","nonstrict")
data.write.mode(SaveMode.Overwrite)
.partitionBy("month")
.format("hive")
.saveAsTable("bigdata.result04")
// SaveMode.Overwrite更新整个表,不是某个分区
mon_data.write.mode(SaveMode.Overwrite)
.partitionBy("month")
.format("hive")
.saveAsTable("bigdata.result04")
// insertInto不能和partitionBy连用 不能用于写入分区表!!!
mon_data.write.mode(SaveMode.Overwrite)
.partitionBy("month")
.format("hive")
.insertInto("bigdata.result04")
/**
* 解决手段:
* 把你的数据写入到hdfs对应的table path下面即可
* 等同于通过sqoop和datax直接把mysql里面的数据同步到hdfs
* hive里面的table能不能直接使用呢
* 普通表写到hdfs上之后,是可以直接read的
* 分区表写到hdfs上之后,不能直接读
* 因为hdfs上数据是ok的,但元数据是不ok的,会导致hive元数据和数据没有关联上
* 解决方法修复table中的元数据
*/
spark.stop()
}
}
文件存储格式:
text(单列输出)【有问题】、orc、parquet
create table bigdata.result05(
uid string,
cnt bigint,
total_cnt bigint
)
partitioned by(month string)
row format delimited fields terminated by ","
stored as orc
// 解决方法 分区表 不过更新的还是整张表
data.write.mode(SaveMode.Overwrite).partitionBy("month")
//.format("orc").save("")
.orc("hdfs://bigdata12:9000/user/hive/warehouse/bigdata.db/result05/")
spark.sql(
"""
|msck repair table bigdata.result05
|""".stripMargin)
mon_data.write.mode(SaveMode.Overwrite).partitionBy("month")
//.format("orc").save("")
.orc("hdfs://bigdata12:9000/user/hive/warehouse/bigdata.db/result05/")
spark.sql(
"""
|msck repair table bigdata.result05
|""".stripMargin)
如果想使用api的方式SaveMode.overwrite绝对用不了!!!SaveMode.overwrite操作的是table,不是具体的partition
解决方法:用SaveMode.Append,修改分区dt的过滤条件 select * from tmp where month=‘2017-01’
mon_data.write.mode(SaveMode.Append).partitionBy("month")
//.format("orc").save("")
.orc("hdfs://bigdata12:9000/user/hive/warehouse/bigdata.db/result05/")
spark.sql(
"""
|msck repair table bigdata.result05
|""".stripMargin)
但是SaveMode.Append相同分区再次修改会出现数据重复,要解决幂等性的问题
解决方法:
1.删除对应分区hdfs上数据 =》hdfs api
2.删除对应分区 元数据 =》 alter table xxx drop partition
3.api 写入对应分区 hdfs 上数据 =》sparksql api
4.api 加上对应分区 元数据 =》alter table xxx add partition或者msck repair table xxx
spark-hive udf catalog
catalog
hive元数据 mysql里面:
spark2.0之前 spark 想要访问hive元数据 要通过jdbc 连接,取数据
spark2.0之后 调用catalog 就可以拿到 hive元数据的内容
拿到hive元数据=》 做什么事情?
1.大数据平台: 哪些表是热表哪些表是冷表,哪些表什么时间段进来数据什么时间段出去数据,数据分析平台都可以利用元数据去取数据
val ct =spark.catalog
ct.listDatabases.show(5,false)
ct.listTables("bigdata").show(5,false)
ct.listFunctions().show(100,false)
ct.listColumns("bigdata.test1").show(false)
思考: spark-shell 以yarn方式运行 client/cluster都能启动嘛【面试题】
spark-shell \
--master yarn \
--deploy-mode client \
--name dl2262 \
--executor-memory 1G \
--num-executors 1 \
--executor-cores 1 \
--jars /home/hadoop/software/mysql-connector-java-5.1.28.jar \
--driver-class-path /home/hadoop/software/mysql-connector-java-5.1.28.jar
client可以,cluster不可以
因为spark-shell是交互式脚本,它的driver就在提交机器上,client的driver也在提交机器上,而cluster的driver在集群内部
udf
1.idea 代码的方式定义 udf函数
2.hive udf 可以在sparksql里面直接使用:
使用场景 : xxx.sql
hive jar: add jar xx.jar
create function 方法名字 as copy reference
package com.dl2262.sparksql.day03
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.sql.SparkSession
import scala.util.Random
object Udf {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
import spark.implicits._
import org.apache.spark.sql.functions._
val data = spark.sql(
"""
|select
|uid,
|month,
|cnt,
|sum(cnt) over(partition by uid order by month) as total_cnt
|from(
|select
|uid,
|date_format(replace('visit_dt','/','-'),'yyyy-MM') as month,
|sum(visit_cnt) as cnt
|from bigdata.user_log
|group by uid,month
|) as a
|""".stripMargin)
data.show(false)
data.createOrReplaceTempView("tmp")
/**
* udf:f(x)
* 添加一个随机数前缀
* u01 => 9_u01
*/
spark.udf.register("addRandom",(input:String) => {
Random.nextInt(10)+"_"+input
})
spark.sql(
"""
|select
|addRandom(uid) as uid_alias,month,cnt,total_cnt
|from tmp
|""".stripMargin).show(false)
spark.stop()
}
}
sparkstreamig
spark 提供的实时计算的模块:SparkStreaming、structuredStreaming
1.流处理 /实时计算
实时:storm、flink (来一条数据处理一条数据 ) event基于事件的方式进行计算 真正的实时计算
近实时:SparkStreaming 来一批数据处理一批数据 源源不断的来 mini-batch
2.批处理/离线计算
一次性处理某一个批次的数据 数据是有始有终的
流处理:
水龙头 数据是远远不断的来 数据没有始终
技术选型:
1.生产上:
SparkStreaming、structuredStreaming 10% spark
flink 90%
storm 2% 几乎不用
开发角度 :
code代码角度:flick开发简单
flick里面还支持sql方式处理 实时计算
sparkstreaming也能用sql,但是不是所有代码都是通过sql开发的,所以诞生了structuredStreaming(基于spark-sql进行开发),structuredStreaming开发角度比sparkstreaming更简单
业务:
1.实时指标
spark和flick都差不多
2.实时数仓
1.代码 =》 spark和flick都差不多 【都不好维护】
2.sql文件:
只有flinksql 能做到维护实时数仓
sparkstreaming:
1.Easy to use
2.sparkstreaming可以调用 sparksql 进行开发
SparkStreaming
1.Spark Streaming is an extension of the core Spark API
SparkStreaming开发 与sparkcore 算子开发 差不多
2.spark Streaming 数据源:Kafka, TCP sockets ,flume,hdfs =》 input
3.处理: 算子的方式进行处理 =》 todo
4. pushed out to filesystems, databases, hdfs,and live dashboards =》 output
数据源:
kafka **** 流式引擎 + kafka 【重要数据源】数据存储在topic里进行缓冲
flume 可以使用 一般不用 没有数据缓冲的作用
hdfs 很少使用
tcp sockets =》 测试代码 +运营商数据(早期采集数据方式 )
总结: 建议不要使用flume作为spark的数据源,因为flume缓冲能力很弱 之后数据计算 直接把数据干到 spark里面 会导致 spark计算程序挂掉
spark/flick对接kafka,流式处理系统会有自己吞吐量的处理能力
数据积压:kafka数据多,spark消费能力不足,导致kafka数据大量积压
解决方法:提高spark消费能力,提高吞吐量
SparkStreaming运行:
1. receives live input data streams 接收数据
2.divides the data into batches 把接收数据 拆分成batches
sparkstreaming编程模型:DStream
a DStream is represented as a sequence of RDDs.
sparkcore:rdd
sparksql :ds、df
如何构建DStream?
1.外部数据源【kafka】
2.高阶算子方式转换
Stream data 按照时间把数据拆分一个一个的 batch(batch就是一个一个的rdd )
流式处理:
对 DStream进行转换操作
实际上就是对 DStream里面的rdd进行操作
对rdd进行操作就是对 rdd里面分区的元素进行操作
总结: 程序入口
sparkstreaming :StreamingContext
sparkcore: sparkcontext
sparksql: sparksession
实时计算处理数据的qps是多少?
qps指的是计算程序每秒钟处理的数据是多少条
虚拟机上构建StreamingContext
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(5))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
idea构建StreamingContext
org.apache.spark spark-streaming_2.12 3.2.1 总结: 打印的东西: 1.spark处理 当前批次的数据的结果 2.不能处理 累计批次的数据 累计批次:多个批次之间又联系的 ```scala package com.dl2262.sparkstreaming.day01import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object sss01 {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
val lines = ssc.socketTextStream(“bigdata12”, 9999)
val words = lines.flatMap(.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey( + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
```scala
/**
* 获取StreamingContext
*/
def getStreamingContext(appName:String,batch:Int,master:String="local[2]")={
val conf = new SparkConf().setMaster(master).setAppName(appName)
new StreamingContext(conf, Seconds(batch))
}
如何构建DStream?
1.Input DStreams 【输入流 kafka】 *****
2.Receivers 【接收流 测试使用 生产上不用】: 为面试准备
并不是所有的接收数据都需要接收器
1.Receivers: 底层DStream前面带Receiver的就是接收流
1.socketTextStream:
底层调用socketStream
底层调用SocketInputDStream
Receiver:master =》 local[2] => local[1] code能否处理数据?【面试】
sparkstreaming: 1 cpu =》 1 core
1.接收流式数据 ok 需要1core去接收数据
2.流式数据 切分成 batch进行处理 no ok cpu不够 你的数据没有资源进行处理
要求:master cpu 个数 一定要大于Receiver 数量
什么是Receiver? 指的就是 接收数据形成的流 看底层返回值 底层DStream前面带Receiver的就是接收流 接收器
2.转换算子
1.transform ***
2.updateStateByKey
sparkstreaming处理数据的方式:
1.默认仅仅是计算当前批次的数据 只是计算10s一个批次的数据
需求:
统计 从现在时间点开始 b出现的累计次数?
updateStateByKey 用于解决 有状态问题
对于 累计批次的需求? 官方引出一个概念 状态
状态:State:
1.有状态 前后批次有联系的
2.无状态 前后批次是没有联系的
累计批次的需求?
1.updateStateByKey 算子解决
1.Define the state
2.Define the state update function
注意:
1.得指定 The checkpoint directory has not been set
package com.dl2262.sparkstreaming.day01
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.streaming.StreamingContext
object sss02 {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
ssc.checkpoint("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\checkpoint")
val lines = ssc.socketTextStream("bigdata12", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.updateStateByKey(updateFunction)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
/**
* Option some none
* @param newValues 最新批次的数据 (a,<1,1,1>)
* @param preValues 以前批次的一个累加值 (a,3)
* @return
*/
def updateFunction(newValues: Seq[Int], preValues: Option[Int]): Option[Int] = {
val curr_sum: Int = newValues.sum
val pre_sum: Int = preValues.getOrElse(0)// 取到了就取到了,取不到就给个0
Some(curr_sum+pre_sum)
}
}
总结:
1.为什么要指定checkpoint?
1.维护 当前批次和以前的累计批次的数据state
2.checkpoint 目录 生产上 得指定到 hdfs上进行存储?
存在问题:
1.checkpoint 每个批次都会产生 文件 =》 hdfs 扛不住 挂掉的风险
checkpoint 的作用 针对sparkstreaming来说
【checkpoint这个东西 生产上用不了 了解它 即可 面试准备】
1.作用:
1.为了容错
2.恢复作业【实时计算作业 挂掉之后 可以恢复起来】
package com.dl2262.sparkstreaming.day01
import com.dl2262.sparkcore.util.ContextUtils
import com.dl2262.sparkstreaming.day01.sss02.updateFunction
import org.apache.spark.streaming.StreamingContext
object sss03 {
def main(args: Array[String]): Unit = {
val ssc = StreamingContext.getOrCreate("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\checkpoint", functionToCreateContext)
ssc.start()
ssc.awaitTermination()
}
def functionToCreateContext(): StreamingContext = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
val lines = ssc.socketTextStream("bigdata12", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.updateStateByKey(updateFunction)
wordCounts.print()
ssc.checkpoint("file:///F:\\bigdata\\ideaProject\\spark-2262\\data\\checkpoint")
ssc
}
}
2.checkpoint存储的东西:
1.Metadata 元数据
Configuration 作业里面配置信息
DStream operations 作业code里面的算子操作
Incomplete batches 未完成的批次
2.Data
每个批次里面真正传过来的数据 +stateful转换
3.使用场景
1.Usage of stateful transformations
2.Recovering from failures of the driver running the application
恢复作业
4.如何正确使用checkpint?
如果你想要 恢复application 需要 正确编写 checkpoint设置代码
注意:
checkpoint缺点:
1.小文件多
2.修改代码程序就用不了【修改业务逻辑代码】
checkpoint 用不了生产上 =》 累计批次指标统计问题 updateStateByKey这个算子 也用不了!!!
那么如何实现 累计批次统计需求?
一: 100%来处理
1.把每个批次数据 写到外部存储
2.然后利用外部存储系统再统计即可
二:90%都没有解决
checkpoint 【解决 checkpoint 导致修改代码 报错问题+小文件问题解决】
3.输出算子:
1.print
2.foreachRDD =》 db
需求: wc案例结果写mysql里面
1.mysql创建一个表
create table wc(
word varchar(10),
cnt int(10)
);
Serialization stack:
- object not serializable (class: java.lang.Object, value: java.lang.Object@4c03b7b3)
1.某个东西没有进行序列化?
1.MySQL连接驱动没有进行序列化 【做不了】
2.ClosureCleaner
Closure 闭包的 意思
闭包的: 方法内使用了方法外的变量
2.正确写法:
rdd.foreachPartition{
mysql 连接次数 会减少 rdd有多少个分区 就有多少个连接
}
package com.dl2262.sparkstreaming.day01
import java.sql.Connection
import com.dl2262.sparkcore.util.{ContextUtils, MySQLUtil}
import com.dl2262.sparkstreaming.day01.sss02.updateFunction
import org.apache.spark.streaming.StreamingContext
object sss04 {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
val lines = ssc.socketTextStream("bigdata12", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_+_)
wordCounts.print()
//data output => mysql
wordCounts.foreachRDD(rdd => {
// mysql clickhouse drios phoenix
// 只有mysql连接不支持序列化,其他三个都支持
// rdd.foreach(pair => {// executor
// val conn: Connection = MySQLUtil.getConnection()
// val sql = s"insert into wc(word,cnt) values('${pair._1}','${pair._2}')"
// conn.createStatement().execute(sql)
// conn.close()
// })
//rdd.coalesce(10).foreachPartition()
// 如果连接有序列化可以把连接放在这
rdd.foreachPartition(partition => {
val conn: Connection = MySQLUtil.getConnection()
partition.foreach(pair => {
val sql = s"insert into wc(word,cnt) values('${pair._1}','${pair._2}')"
conn.createStatement().execute(sql)
})
conn.close()
})
ssc.start()
ssc.awaitTermination()
})
}
}
3.如果 rdd.foreachPartition 写数据 存在存储性能问题: 【一般不用,可以使用!!!】
1.可以使用连接池
2.rdd.coalse =》 减少rdd分区数
4.sparksql的方式写出 =》
package com.dl2262.sparkstreaming.day01
import java.sql.Connection
import java.util.Properties
import com.dl2262.sparkcore.util.{ContextUtils, MySQLUtil}
import com.dl2262.sparkstreaming.day01.sss02.updateFunction
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.streaming.StreamingContext
object sss04 {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
val lines = ssc.socketTextStream("bigdata12", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_+_)
wordCounts.print()
//data output => mysql
wordCounts.foreachRDD(rdd => {
// mysql clickhouse drios phoenix
// 只有mysql连接不支持序列化,其他三个都支持
// rdd.foreach(pair => {// executor
// val conn: Connection = MySQLUtil.getConnection()
// val sql = s"insert into wc(word,cnt) values('${pair._1}','${pair._2}')"
// conn.createStatement().execute(sql)
// conn.close()
// })
//rdd.coalesce(10).foreachPartition()
// 如果连接有序列化可以把连接放在这
// rdd.foreachPartition(partition => { // 推荐
// val conn: Connection = MySQLUtil.getConnection()
// partition.foreach(pair => {
// val sql = s"insert into wc(word,cnt) values('${pair._1}','${pair._2}')"
// conn.createStatement().execute(sql)
// })
// conn.close()
// sparksql的方式写出 推荐
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val df: DataFrame = rdd.toDF("word", "cnt")
df.printSchema()
df.show()
val url = "jdbc:mysql://bigdata12:3306/bigdata"
val table = "rpt_cnt_top3"
val properties: Properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
df.write.mode(SaveMode.Append).jdbc(url,table,properties)
})
ssc.start()
ssc.awaitTermination()
}
}
转换算子transform
transform =》 DStream 和 rdd之间数据进行交互的算子
需求:
流处理 数据源:
一个数据来自于 mysql数据/hdfs上文本数据 【量小】 维表
一个数据 来自于 kafka sss 读取形成 DStream数据 【量大】 主业务 =》 主表
案例: 弹幕 过滤的功能 /黑名单的功能
离线:
package com.dl2262.sparkstreaming.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object SparkSQLBlackListApp {
def main(args: Array[String]): Unit = {
val spark: SparkSession = ContextUtils.getSparkSession(this.getClass.getSimpleName)
val sc: SparkContext = spark.sparkContext
import spark.implicits._
import org.apache.spark.sql.functions._
/**
* 主表数据:弹幕日志数据
* 维表书局:需要过滤的弹幕 =》 黑名单
*/
val log: RDD[String] = sc.parallelize(List(
"好看",
"不好看",
"垃圾",
"男主好帅",
"女主好漂亮",
"666",
"男主演技拉跨",
"女主演技拉跨",
"台词拉跨"
))
val black: RDD[String] = sc.parallelize(List(
"男主演技拉跨",
"女主演技拉跨",
"台词拉跨"
))
val log_kv: RDD[(String, Int)] = log.map(line => (line, 1))
val black_kv: RDD[(String, Boolean)] = black.map(line => (line, true))
log_kv.leftOuterJoin(black_kv)
.filter(_._2._2.getOrElse(false) != true)
.map(_._1).foreach(println(_))
spark.stop()
}
}
实时:
package com.dl2262.sparkstreaming.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object SparkStreamingBlackApp {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
val sc: SparkContext = ssc.sparkContext
/**
* socket
* 主表数据:弹幕日志数据 DStream
* mysql/hdfs
* 维表数据:需要过滤的弹幕 =》 黑名单 rdd
*/
val logs: ReceiverInputDStream[String] = ssc.socketTextStream("bigdata12", 9527)
val black: RDD[String] = sc.parallelize(List(
"男主演技拉跨",
"女主演技拉跨",
"台词拉跨"
))
// 弹幕显示
val log_kv: DStream[(String, Int)] = logs.map(word => (word, 1))
val black_kv: RDD[(String, Boolean)] = black.map(line => (line, true))
val result: DStream[String] = log_kv.transform(rdd => {
rdd.leftOuterJoin(black_kv)
.filter(_._2._2.getOrElse(false) != true)
.map(_._1)
})
result.print()
ssc.start()
ssc.awaitTermination()
}
}
sparkstreaming + kafka 整合
kafka 数据源=》 sparkstreaming 消费
spark 2.x :
kafka版本:
0.8
0.10.0 or higher ok
spark 3.x => kafka :
1.kafka版本:
0.10.0 or higher ok
spark 去kafka读取数据的方式:
1.kafka 0.8 reciver方式读取kafka数据 【效率低 、代码开发复杂】
2.kafka 0.10.0版本之后 direct stream的方式加载kafka数据 【效率高、代码开发简单】
kafka:
版本也有要求:
0.11.0 版本之后
交付语义: consumer producer
producer 默认就是精准一次
consumer 交付语义取决于 consumer 框架本身
交付语义: consumer
至多一次 数据丢失问题
至少一次 数据不会丢失,数据重复消费
精准一次 数据不会丢失 数据也不会重复消费
spark 整合kafka 版本 0.10.0版本之后:
1.kafka 0.11.0之后 reciver => direct stream
2.sparkstreaming 默认消费kafka数据 交付语义: 至少一次
- spark消费kafka, DStream 【rdd 分区数】 =》 kafka topic 分区数 是一一对应的
1:1 correspondence between Kafka partitions and Spark partitions
2.spark整合kafka api:
1.simple API =》 过时不用了
2. new Kafka consumer API 整合 kafka 主流
3.引入依赖: org.apache.spark spark-streaming-kafka-0-10_2.12 3.2.1 不需要引入 kafka-clients 依赖
spark整合kafka操作
zkServer.sh start
zkServer.sh status
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
查看kafka topic命令:
kafka-topics.sh --list
–zookeeper bigdata12:2181/kafka
kafka-topics.sh --create
–zookeeper bigdata12:2181/kafka
–topic spark-kafka01
–partitions 3
–replication-factor 1
producer:
kafka-console-producer.sh
–broker-list bigdata12:9092
–topic dl2262
consumer:
kafka-console-consumer.sh
–bootstrap-server bigdata12:9092
–topic dl2262
–from-beginning
package com.dl2262.sparkstreaming.day02
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object ss01 {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
/**
* 加载kafka数据
* ssl权限校验
*/
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "bigdata12:9092",//kafka地址
"key.deserializer" -> classOf[StringDeserializer],//反序列化
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "dl2262",//指定一个消费者组id
"auto.offset.reset" -> "latest",//从哪个地方开始消费数据 偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)//offset提交 选择不自动提交 手动管理
)
val topics = Array("dl2262")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,//【面试】数据的存储策略:kafka数据均匀分布在各个executor上
Subscribe[String, String](topics, kafkaParams)//固定写法
)
stream.map(record => record.value()).print()
ssc.start()
ssc.awaitTermination()
}
}
需求: 消费kafka数据 wc 将 结果写到 mysql里面
package com.dl2262.sparkstreaming.day02
import java.util.Properties
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object ss02 {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
/**
* 加载kafka数据
* ssl权限校验
* input
*/
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "bigdata12:9092",//kafka地址
"key.deserializer" -> classOf[StringDeserializer],//反序列化
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "dl2262",//指定一个消费者组id
"auto.offset.reset" -> "latest",//从哪个地方开始消费数据 偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)//offset提交 选择不自动提交 手动管理
)
val topics = Array("dl2262")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,//【面试】数据的存储策略:kafka数据均匀分布在各个executor上
Subscribe[String, String](topics, kafkaParams)//固定写法
)
/**
* to do
*/
stream.map(record => record.value()).print()
val wc_result: DStream[(String, Int)] = stream.map(record => record.value())
.flatMap(line => line.split(","))
.map(word => (word, 1))
.reduceByKey(_ + _)
/**
* output
*/
wc_result.foreachRDD(rdd => {
//foreachPartition
//sparksql
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val wc: DataFrame = rdd.toDF("word", "cnt")
wc.show()
wc.printSchema()
//sink mysql
val url = "jdbc:mysql://bigdata12:3306/bigdata"
val table = "wc"
val properties: Properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
wc.write.mode(SaveMode.Append).jdbc(url,table,properties)
})
ssc.start()
ssc.awaitTermination()
}
}
模拟:spark作业挂掉 =》 重启
“消费完kafka的数据 程序重启之后接着从上次消费的位置接着消费 ”
目前: code不能满足
1.目前代码 这两个参数 不能动
“auto.offset.reset” -> “earliest”
“enable.auto.commit” -> (false: java.lang.Boolean)
2.主要原因 :
spark作业 消费kafka数据:
1.获取kafka offset =》 处理kafka数据 =》 “提交offset的操作” 没有
解决:
1.获取kafka offset // todo
2. 处理kafka数据
3.提交offset的操作 // todo
1.获取kafka offset // todo
1. kafka offset 信息
2.spark rdd分区数 和 kafka topic 的分区数 是不是 一对一
报错:
org.apache.spark.rdd.ShuffledRDD cannot be cast to org.apache.spark.streaming.kafka010.HasOffsetRanges
ShuffledRDD =》 HasOffsetRanges 说明 代码有问题
sparkstreaming里面: 开发模式:!!!
1.获取kafka 流数据
2. 流 Dstream =》 调用foreachRDD算子 进行输出:
0.获取offset 信息
1.做业务逻辑
2.结果数据输出
3.提交offset信息
offset解释:
01 batch:
rdd的分区数:3
topic partition fromOffset untilOffset
spark-kafka01 0 0 1
spark-kafka01 1 0 1
spark-kafka01 2 0 0
02 batch:
rdd的分区数:3
topic partition fromOffset untilOffset
spark-kafka01 0 1 1
spark-kafka01 1 1 1
spark-kafka01 2 0 0
此时 kafka 里面数据已经消费完了 fromOffset=untilOffset
3.提交offset信息
2.存储offset信息
spark流式处理 默认消费语义 : 至少一次
精准一次:
1.output + offset
1.Checkpoints =》 不能用
2.Kafka itself =》至少一次 =》
推荐使用 =》 简单 高效
90% 都可以解决 但不支持事务
package com.dl2262.sparkstreaming.day02
import java.util.Properties
import com.dl2262.sparkcore.util.ContextUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.kafka010.{CanCommitOffsets, HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object ss03 {
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = ContextUtils.getStreamingContext(this.getClass.getSimpleName, 10)
/**
* 加载kafka数据
* ssl权限校验
* input
*/
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "bigdata12:9092",//kafka地址
"key.deserializer" -> classOf[StringDeserializer],//反序列化
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "dl2262",//指定一个消费者组id
"auto.offset.reset" -> "earliest",//从哪个地方开始消费数据 偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)//offset提交 选择不自动提交 手动管理
)
val topics = Array("dl2262")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,//【面试】数据的存储策略:kafka数据均匀分布在各个executor上
Subscribe[String, String](topics, kafkaParams)//固定写法
)
stream.map(record => record.value()).print()
/**
* output
* 0.get offset
* 1.todo
* 2.output
* 3.提交offset
*/
stream.foreachRDD(rdd => {
//rdd分区数和kafka分区数是不是一一对应的
println(s"rdd分区数:${rdd.partitions.size}")
//获取kafka数据的offset信息 =》 当前批次
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
println("topic partition fromoffset untiloffset")
offsetRanges.foreach(offset => {
println(offset.topic+"\t"+offset.partition+"\t"+offset.fromOffset+"\t"+offset.untilOffset)
})
/**
* spark代码
*/
val spark: SparkSession = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val wcRDD: RDD[(String, Int)] = rdd.map(_.value()).flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
val wcDF: DataFrame = wcRDD.toDF("word", "cnt")
wcDF.show()
wcDF.printSchema()
//sink mysql
val url = "jdbc:mysql://bigdata12:3306/bigdata"
val table = "wc"
val properties: Properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
wcDF.write.mode(SaveMode.Append).jdbc(url,table,properties)
//提交offset
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}
10% 精准一次
3.Your own data store: =》 开发大量代码 =》
mysql、redis、hbase都支持事务
至少一次
精准一次
用mysql存储:
获取offset
todo
output
提交offset
spark作业挂了 =》 启动spark作业 :
1.从mysql里面获取offset
todo
output
提交offset
kafka消费语义:
1.至多一次 【丢数据】
2.至少一次 【不会丢数据 可能会重复消费数据】
3.精准一次 【不丢、不重复消费】
offset信息提交 :
1.spark todo :
至少一次:
1 2 3 4
offset get
业务逻辑 output db
提交offset
在提交offset时挂掉,下次再获取offset时,会再次获取上次的offset,再次输出到数据库从而导致数据重复
精准一次:output + 提交offset 一起发生 =》 事务来实现
事务: 一次操作要么都成功 要么都失败 ,失败时会发生回滚操作
存储offset:
kafka 本身:
offset 信息存储在哪?
kafka 某个topic下:
__consumer_offsets =》 spark作业 消费kafka topic offset 信息存储的地方