机器学习 09 随机森林
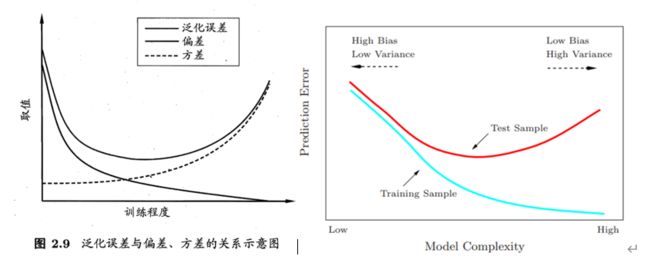
三、 偏差和方差
偏差度量了学习算法的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力。
方差:离散程度, 也就是该随机变量在其期望值附近的波动程度
噪声表达了在当前任务上,任何学习算法所能达到的期望泛化误差的下界, 即刻画了学习问题本身的难度。
泛化误差(Generalization error)是学得的模型f 对未知数据预测的误差。
The more complex model will lead to lower bias but higher variance.
更复杂的模型将导致偏差更低,但方差更高。
尝试增加正则化程度,尝试减少特征的数量 ————解决高方差
尝试减少正则化程度,尝试获得更多的特征 ————解决高偏差
尝试增加多项式特征 ————解决高偏差
四、 分类评估方法
根据预测正确与否,将样例分为以下四种:
TP(True positive,真正例)——将正类预测为正类数。
FP(False postive,假正例)——将反类预测为正类数。
TN(True negative,真反例)——将反类预测为反类数。
FN(False negative,假反例)——将正类预测为反类数。
精确度
精确度是分类正确的样本数占样本总数的比例。
查准率
查准率:真实为正的样本中占预测为正的样本的比例
查全率
查全率:查询的样本中为正的占查询出的数据的总量,也可以理解为 真实为正样本中有多少是预测正确的
性能度量:二分类问题常用的评价指标时查准率和查全率。
查准率和查全率是一对矛盾的度量。是查准率和查全率的调和平均:
当查重率和查准率都高时,F 1 也会高泛化能力






一、过拟合/欠拟合
拟合误差
拟合误差是指模型在训练数据上的误差。当我们训练一个模型时,我们希望它能够在训练数据上表现良好,但是我们也希望它能够在新的数据上表现良好。因此,我们需要控制拟合误差,以避免过拟合。
过拟合
在分类问题上就是训练集的损失函数值很小,但是验证集/测试集上的损失函数值很大
训练模型时,损失函数关于迭代次数的图像一直下降到很小的数值并不是什么好事,这恰恰暗示了我们的模型存在过拟合的风险。
过拟合是指模型在训练数据上表现良好,但在新的数据上表现不佳的情况。这是因为模型过于复杂,以至于它能够记住训练数据中的每一个细节,而无法泛化到新的数据上。因此,我们需要控制模型的复杂度,以避免过拟合。
过拟合解决办法:
①正则化Regularization
正则化是通过在损失函数中添加一个正则化项来控制模型的复杂度。正则化项通常是模型参数的范数,例如 L1 范数或 L2 范数。通过增加正则化项,我们可以使模型更加平滑,从而减少过拟合的风险。
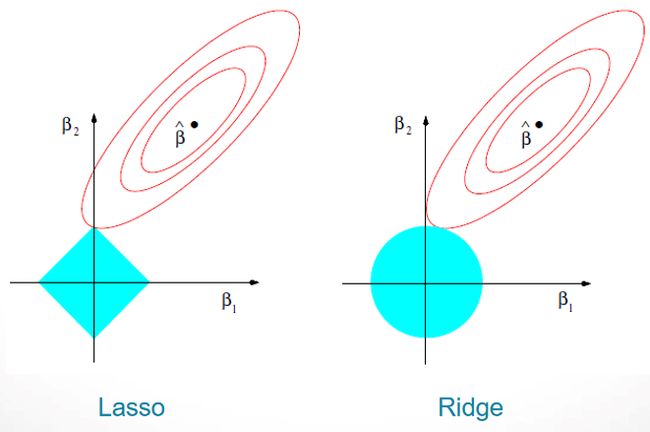
L1正则化会得到稀疏解,可用作特征选择。-- lasso
L2正则化会得到趋于0的解,起到防止过拟合的作用--岭回归
Shrinkage Methods收缩法,主要有 ridge regression 和 lasso 两种方法。
Lasso回归和岭回归的同和异:
相同:都可以用来解决标准线性回归的过拟合问题。
不同:
1、lasso 可以用来做 feature selection,而 ridge 不行。
2、lasso 更容易使得权重变为 0,而 ridge 更容易使得权重接近 0。
3、从贝叶斯角度看,lasso(L1 正则)等价于参数 (m w) 的先验概率分布满足拉普拉斯分布,而 ridge(L2 正则)等价于参数 (m w) 的先验概率分布满足高斯分布。
②使用更多的训练数据
当我们有更多的训练数据时,模型可以更好地学习数据的特征,从而减少过拟合的风险。
③使用 dropout 技术来随机地删除一些神经元,从而减少模型的复杂度。
④使用早停技术(Early stop technology)来在验证集上监测模型的性能,并在性能不再提高时停止训练,从而避免过拟合,从而使模型更加泛化。
欠拟合: 模型过于简单,在训练集和测试集的拟合的效果都不好。
简要解释机器学习中的过拟合和过拟合。 如何在现实中避免过拟合和过拟合。
Overfitting:The model performs well on the training set, but poorly on the test set.(1 point)
过拟合:该模型在训练集上表现良好,但在测试集上表现不佳。
Underfitting: The model performs poorly on both the training set and the test set(1 point
不足拟合:模型在训练集和测试集上都表现不佳。
How to avoid:如何避免:
Overfitting: (3 point)
1.Data augmentation 1.数据增强
2.Reduce model complexity 2.降低模型复杂度
3.Regularization method3.正则化方法
4.Dropout, neural network 4.Dropout,神经网络
5.Bayesian method 5.贝叶斯方法
6.Ensemble learning6集成学习
7.Early stopping7.早期停止
Undlerfitting: (2 point)
1、Add new features 1.增加新功能
2、Increase model complexity 2.增加模型复杂性
3、Reduce the regularization coefficient 3。减小正则化系数