IM通讯协议专题学习(七):手把手教你如何在NodeJS中从零使用Protobuf
1、前言
Protobuf是Google开源的一种混合语言数据标准,已被各种互联网项目大量使用。
Protobuf最大的特点是数据格式拥有极高的压缩比,这在移动互联时代是极具价值的(因为移动网络流量到目前为止仍然昂贵的),如果你的APP能比竞品更省流量,无疑这也将成为您产品的亮点之一。现在,尤其IM、消息推送这类应用中,Protobuf的应用更是非常广泛,基于它的优秀表现,微信和手机QQ这样的主流IM应用也早已在使用它。
现在随着WebSocket协议的越来越成熟,浏览器支持的越来越好,Web端的即时通讯应用也逐渐拥有了真正的“实时”能力,相关的技术和应用也是层出不穷,而Protobuf也同样可以用在WebSocket的通信中。而且目前比较活跃的WebSocket开源方案中,都是用NodeJS实现的,比如:socket.io和sockjs都是如此,因而本文介绍Protobuf在NodeJS上的使用,也恰是时候。

学习交流:
- 移动端IM开发入门文章:《 新手入门一篇就够:从零开发移动端IM 》
- 开源IM框架源码: https://github.com/JackJiang2011/MobileIMSDK ( 备用地址点此 )
(本文同步发布于:http://www.52im.net/thread-4111-1-1.html)
2、系列文章
本文是系列文章中的第 7 篇,本系列总目录如下:
《IM通讯协议专题学习(一):Protobuf从入门到精通,一篇就够!》
《IM通讯协议专题学习(二):快速理解Protobuf的背景、原理、使用、优缺点》
《IM通讯协议专题学习(三):由浅入深,从根上理解Protobuf的编解码原理》
《IM通讯协议专题学习(四):从Base64到Protobuf,详解Protobuf的数据编码原理》
《IM通讯协议专题学习(五):Protobuf到底比JSON快几倍?全方位实测!》
《IM通讯协议专题学习(六):手把手教你如何在Android上从零使用Protobuf》(稍后发布..)
《IM通讯协议专题学习(七):手把手教你如何在NodeJS中从零使用Protobuf》(* 本文)
《IM通讯协议专题学习(八):金蝶随手记团队的Protobuf应用实践(原理篇) 》(稍后发布..)
《IM通讯协议专题学习(九):金蝶随手记团队的Protobuf应用实践(实战篇) 》(稍后发布..)
3、Protobuf是个什么鬼?
Protocol Buffer(下文简称Protobuf)是Google提供的一种数据序列化协议,下面是我从网上找到的Google官方对Protobuf的定义:
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化,很适合做数据存储或 RPC 数据交换格式。它可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
道理我们都懂,然后并没有什么卵用,看完上面这段定义,对于Protobuf是什么我还是一脸懵逼。

4、NodeJS开发者为何要跟Protobuf打交道
作为JavaScript开发者,对我们最友好的数据序列化协议当然是大名鼎鼎的JSON啦!我们本能的会想protobuf是什么鬼?还我JSON!
这就要说到protobuf的历史了。
Protobuf由Google出品,08年的时候Google把这个项目开源了,官方支持C++,Java,C#,Go和Python五种语言,但是由于其设计得很简单,所以衍生出很多第三方的支持,基本上常用的PHP,C,Actoin Script,Javascript,Perl等多种语言都已有第三方的库。
由于protobuf协议相较于之前流行的XML更加的简洁高效(后面会提到这是为什么),因此许多后台接口都是基于protobuf定制的数据序列化协议。而作为NodeJS开发者,跟C++或JAVA编写的后台服务接口打交道那是家常便饭的事儿,因此我们很有必要掌握protobuf协议。
为什么说使用使用类似protobuf的二进制协议通信更好呢?
1)二进制协议对于电脑来说更容易解析,在解析速度上是http这样的文本协议不可比拟的;
2)有tcp和udp两种选择,在一些场景下,udp传输的效率会更高;
3)在后台开发中,后台与后台的通信一般就是基于二进制协议的。甚至某些native app和服务器的通信也选择了二进制协议(例如腾讯视频)。但由于web前端的存在,后台同学往往需要特地开发维护一套http接口专供我们使用,如果web也能使用二进制协议,可以节省许多后台开发的成本。
在大公司,最重要的就是优化效率、节省成本,因此二进制协议明显优于http这样的文本协议。
下面举两个简单的例子,应该有助于我们理解protobuf。
5、选择支持protobuf的NodeJS第三方模块
当前在Github上比较热门的支持protobuf的NodeJS第三方模块有如下3个:


根据star数和文档完善程度两方面综合考虑,我们决定选择protobuf.js(后面2个的地址:Google protobuf js、protocol-buffers)。
6、使用 Protobuf 和NodeJS开发一个简单的例子
6.1 概述
我打算使用 Protobuf 和NodeJS开发一个十分简单的例子程序。该程序由两部分组成:第一部分被称为 Writer,第二部分叫做 Reader。
Writer 负责将一些结构化的数据写入一个磁盘文件,Reader 则负责从该磁盘文件中读取结构化数据并打印到屏幕上。
准备用于演示的结构化数据是 HelloWorld,它包含两个基本数据:
1)ID:为一个整数类型的数据;
2)Str:这是一个字符串。
6.2 书写.proto文件
首先我们需要编写一个 proto 文件,定义我们程序中需要处理的结构化数据,在 protobuf 的术语中,结构化数据被称为 Message。proto 文件非常类似 java 或者 C 语言的数据定义。代码清单 1 显示了例子应用中的 proto 文件内容。
清单 1. proto 文件:
package lm;
message helloworld
{
required int32 id = 1; // ID
required string str = 2; // str
optional int32 opt = 3; //optional field
}
一个比较好的习惯是认真对待 proto 文件的文件名。比如将命名规则定于如下:
packageName.MessageName.proto
在上例中,package 名字叫做 lm,定义了一个消息 helloworld,该消息有三个成员,类型为 int32 的 id,另一个为类型为 string 的成员 str。opt 是一个可选的成员,即消息中可以不包含该成员。1、2、3这几个数字是这三个字段的唯一标识符,这些标识符是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。
6.3 编译 .proto 文件
我们可以使用protobuf.js提供的命令行工具来编译 .proto 文件。
用法:
# pbjs[options] [> outFile]
我们来看看options:
--help, -h Show help [boolean] 查看帮助
--version, -v Show version number [boolean] 查看版本号
--source, -s Specifies the source format. Valid formats are:
json Plain JSON descriptor
proto Plain .proto descriptor
指定来源文件格式,可以是json或proto文件。
--target, -t Specifies the target format. Valid formats are:
amd Runtime structures as AMD module
commonjs Runtime structures as CommonJS module
js Runtime structures
json Plain JSON descriptor
proto Plain .proto descriptor
指定生成文件格式,可以是符合amd或者commonjs规范的js文件,或者是单纯的js/json/proto文件。
--using, -u Specifies an option to apply to the volatile builder
loading the source, e.g. convertFieldsToCamelCase.
--min, -m Minifies the output. [default: false] 压缩生成文件
--path, -p Adds a directory to the include path.
--legacy, -l Includes legacy descriptors from google/protobuf/ if
explicitly referenced. [default: false]
--quiet, -q Suppresses any informatory output to stderr. [default: false]
--use, -i Specifies an option to apply to the emitted builder
utilized by your program, e.g. populateAccessors.
--exports, -e Specifies the namespace to export. Defaults to export
the root namespace.
--dependency, -d Library dependency to use when generating classes.
Defaults to 'protobufjs' for CommonJS, 'ProtoBuf' for
AMD modules and 'dcodeIO.ProtoBuf' for classes.
重点关注- -target就好,由于我们是在Node环境中使用,因此选择生成符合commonjs规范的文件。
命令如下:
# ./pbjs ../../lm.message.proto -t commonjs > ../../lm.message.js
得到编译后的符合commonjs规范的js文件:
module.exports = require("protobufjs").newBuilder({})['import']({
"package": "lm",
"messages": [
{
"name": "helloworld",
"fields": [
{
"rule": "required",
"type": "int32",
"name": "id",
"id": 1
},
{
"rule": "required",
"type": "string",
"name": "str",
"id": 2
},
{
"rule": "optional",
"type": "int32",
"name": "opt",
"id": 3
}
]
}
]
}).build();
6.4 编写 Writer
var HelloWorld = require('./lm.helloworld.js')['lm']['helloworld'];
var fs = require('fs');
// 除了这种传入一个对象的方式, 你也可以使用get/set 函数用来修改和读取结构化数据中的数据成员
varhw = newHelloWorld({
'id': 101,
'str': 'Hello'
})
varbuffer = hw.encode();
fs.writeFile('./test.log', buffer.toBuffer(), function(err) {
if(!err) {
console.log('done!');
}
});
6.5 编写Reader
var HelloWorld = require('./lm.helloworld.js')['lm']['helloworld'];
var fs = require('fs');
var buffer = fs.readFile('./test.log', function(err, data) {
if(!err) {
console.log(data); // 来看看Node里的Buffer对象长什么样子。
var message = HelloWorld.decode(data);
console.log(message);
}
})
6.6 运行结果
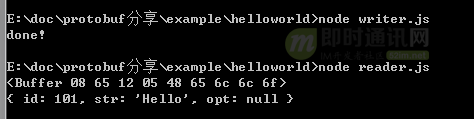
由于我们没有在Writer中给可选字段opt字段赋值,因此Reader读出来的opt字段值为null。
这个例子本身并无意义,但只要您稍加修改就可以将它变成更加有用的程序。比如将磁盘替换为网络 socket,那么就可以实现基于网络的数据交换任务。而存储和交换正是 Protobuf 最有效的应用领域。
7、使用 Protobuf 和NodeJS实现基于网络数据交换的例子
俗话说得好:“世界上没有什么技术问题是不能用一个helloworld的栗子解释清楚的,如果不行,那就用两个!”
在这个栗子中,我们来实现基于网络的数据交换任务。
7.1 编写.proto
cover.helloworld.proto文件:
package cover;
message helloworld {
message helloCoverReq {
required string name = 1;
}
message helloCoverRsp {
required int32 retcode = 1;
optional string reply = 2;
}
}
7.2 编写client
一般情况下,使用 Protobuf 的人们都会先写好 .proto 文件,再用 Protobuf 编译器生成目标语言所需要的源代码文件。将这些生成的代码和应用程序一起编译。
可是在某些情况下,人们无法预先知道 .proto 文件,他们需要动态处理一些未知的 .proto 文件。比如一个通用的消息转发中间件,它不可能预知需要处理怎样的消息。这需要动态编译 .proto 文件,并使用其中的 Message。
我们这里决定利用protobuf文件可以动态编译的特性,在代码中直接读取proto文件,动态生成我们需要的commonjs模块。
client.js:
var dgram = require('dgram');
var ProtoBuf = require("protobufjs");
var PORT = 33333;
var HOST = '127.0.0.1';
var builder = ProtoBuf.loadProtoFile("./cover.helloworld.proto"),
Cover = builder.build("cover"),
HelloCoverReq = Cover.helloworld.helloCoverReq;
HelloCoverRsp = Cover.helloworld.helloCoverRsp;
var hCReq = newHelloCoverReq({
name: 'R U coverguo?'
})
var buffer = hCReq.encode();
var socket = dgram.createSocket({
type: 'udp4',
fd: 8080
}, function(err, message) {
if(err) {
console.log(err);
}
console.log(message);
});
var message = buffer.toBuffer();
socket.send(message, 0, message.length, PORT, HOST, function(err, bytes) {
if(err) {
throw err;
}
console.log('UDP message sent to '+ HOST +':'+ PORT);
});
socket.on("message", function(msg, rinfo) {
console.log("[UDP-CLIENT] Received message: "+ HelloCoverRsp.decode(msg).reply + " from "+ rinfo.address + ":"+ rinfo.port);
console.log(HelloCoverRsp.decode(msg));
socket.close();
//udpSocket = null;
});
socket.on('close', function(){
console.log('socket closed.');
});
socket.on('error', function(err){
socket.close();
console.log('socket err');
console.log(err);
});
7.3 书写server
server.js:
var PORT = 33333;
var HOST = '127.0.0.1';
var ProtoBuf = require("protobufjs");
var dgram = require('dgram');
var server = dgram.createSocket('udp4');
var builder = ProtoBuf.loadProtoFile("./cover.helloworld.proto"),
Cover = builder.build("cover"),
HelloCoverReq = Cover.helloworld.helloCoverReq;
HelloCoverRsp = Cover.helloworld.helloCoverRsp;
server.on('listening', function() {
var address = server.address();
console.log('UDP Server listening on '+ address.address + ":"+ address.port);
});
server.on('message', function(message, remote) {
console.log(remote.address + ':'+ remote.port +' - '+ message);
console.log(HelloCoverReq.decode(message) + 'from client!');
var hCRsp = newHelloCoverRsp({
retcode: 0,
reply: 'Yeah!I\'m handsome cover!'
})
var buffer = hCRsp.encode();
var message = buffer.toBuffer();
server.send(message, 0, message.length, remote.port, remote.address, function(err, bytes) {
if(err) {
throw err;
}
console.log('UDP message reply to '+ remote.address +':'+ remote.port);
})
});
server.bind(PORT, HOST);
7.4 运行结果

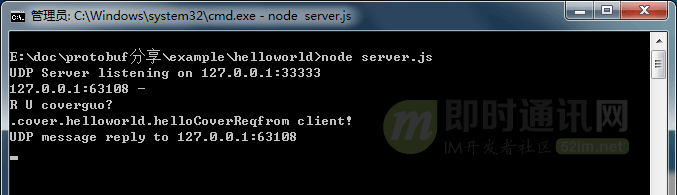
8、其他高级特性
8.1 嵌套Message
message Person {
required string name = 1;
required int32 id = 2; // Unique ID number for this person.
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
在 Message Person 中,定义了嵌套消息 PhoneNumber,并用来定义 Person 消息中的 phone 域。这使得人们可以定义更加复杂的数据结构。
8.2 Import Message
在一个 .proto 文件中,还可以用 Import 关键字引入在其他 .proto 文件中定义的消息,这可以称做 Import Message,或者 Dependency Message。
比如下例:
import common.header;
message youMsg{
required common.info_header header = 1;
required string youPrivateData = 2;
}
其中 ,common.info_header定义在common.header包内。
Import Message 的用处主要在于提供了方便的代码管理机制,类似 C 语言中的头文件。您可以将一些公用的 Message 定义在一个 package 中,然后在别的 .proto 文件中引入该 package,进而使用其中的消息定义。
Google Protocol Buffer 可以很好地支持嵌套 Message 和引入 Message,从而让定义复杂的数据结构的工作变得非常轻松愉快。
9、总结一下Protobuf
9.1 优点
简单说来 Protobuf 的主要优点就是:简洁,快。
为什么这么说呢?
1)简洁:
因为Protocol Buffer 信息的表示非常紧凑,这意味着消息的体积减少,自然需要更少的资源。比如网络上传输的字节数更少,需要的 IO 更少等,从而提高性能。
对于代码清单 1 中的消息,用 Protobuf 序列化后的字节序列为:
08 65 12 06 48 65 6C 6C 6F 77
而如果用 XML,则类似这样:
31 30 31 3C 2F 69 64 3E 3C 6E 61 6D 65 3E 68 65
6C 6C 6F 3C 2F 6E 61 6D 65 3E 3C 2F 68 65 6C 6C
6F 77 6F 72 6C 64 3E
一共 55 个字节,这些奇怪的数字需要稍微解释一下,其含义用 ASCII 表示如下:
101
hello
我相信与XML一样同为文本序列化协议的JSON也不会好到哪里去。
2)快:
首先我们来了解一下 XML 的封解包过程:
1)XML 需要从文件中读取出字符串,再转换为 XML 文档对象结构模型;
2)之后,再从 XML 文档对象结构模型中读取指定节点的字符串;
3)最后再将这个字符串转换成指定类型的变量。
这个过程非常复杂,其中将 XML 文件转换为文档对象结构模型的过程通常需要完成词法文法分析等大量消耗 CPU 的复杂计算。
反观 Protobuf:它只需要简单地将一个二进制序列,按照指定的格式读取到编程语言对应的结构类型中就可以了。而消息的 decoding 过程也可以通过几个位移操作组成的表达式计算即可完成。速度非常快。
9.2 缺点
作为二进制的序列化协议,它的缺点也显而易见——人眼不可读!
10、参考资料
[1] Protobuf 官方开发者指南(中文译版)
[2] Protobuf官方手册
[3] Why do we use Base64?
[4] The Base16, Base32, and Base64 Data Encodings
[5] Protobuf从入门到精通,一篇就够!
[5] 如何选择即时通讯应用的数据传输格式
[7] 强列建议将Protobuf作为你的即时通讯应用数据传输格式
[8] APP与后台通信数据格式的演进:从文本协议到二进制协议
[9] 面试必考,史上最通俗大小端字节序详解
[10] 移动端IM开发需要面对的技术问题(含通信协议选择)
[11] 简述移动端IM开发的那些坑:架构设计、通信协议和客户端
[12] 理论联系实际:一套典型的IM通信协议设计详解
[13] 58到家实时消息系统的协议设计等技术实践分享
(本文同步发布于:http://www.52im.net/thread-4111-1-1.html)