Redis从精通到入门——数据类型List实现源码详解
Redis数据类型之List详解
- List简介
-
- List的常用操作
- 应用场景
- List实现
-
- ziplist
-
- 源码阅读
- 图解Ziplist
- zlentry数据结构
- quickList
-
- 源码阅读
- 图解quickList
List简介
Redis中List列表中的每个字符串成为元素,一个列表最多可以存储2^32 - 1个元素。
在Redis中,可以对列表两端插入(LPUSH)和弹出(LPOP),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,可以充当 栈 和 队列 的角色,在实际开发中有很多应用场景。
- 列表类型有以下特点:
- 列表中的元素是有序的
数据插入时即确定了顺序,可以通过索引下标获取某个元素或者某个范围内的元素列表; - 列表中的元素可以是重复的;
- 列表中的元素是有序的
List的常用操作
- LPUSH key value [value …] : 将一个或多个值value插入到key列表的表头;
最左边、头插法 - RPUSH key value [value …] :将一个或多个值value插入到key列表的表尾;
最右边、尾插法 - LPOP key :移除并返回key列表的头元素;
- RPOP key :移除并返回key列表的尾元素;
- LRANGE key start stop :返回列表key中指定区间内的元素,区间以偏移量start和stop指定`
- BLPOP key [key …] timeout :从key列表表头弹出一个元素,若列表中没有元素,阻塞等待,timeout秒,如果timeout=0,一直阻塞等待;
- BRPOP key [key …] timeout :从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 ,timeout秒,如果timeout=0,一直阻塞等待;
应用场景
- 用户消息列表展示(支持分页展示)
- 消息队列
List实现
- Redis采用quicklist(双端链表) 和 ziplist 作为List的底层实现;
- 可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率;
- list-max-ziplist-size :设置单个ziplist节点最大能存储数据大小 ,超过则进行分裂,将数据存储在新的ziplist节点中;
- list-compress-depth :0 代表所有节点,都不进行压缩,1, 代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4 … 以此类推;
ziplist
- ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率;
- ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供push和pop操作;
- 因为ziplist是一个内存连续的集合,所以ziplist遍历只要通过当前节点的指针 加上 当前节点的长度 或 减去 上一节点的长度 ,即可得到下一个节点的数据或上一个节点的数据,这样就省去的指针从而节省了存储空间,又因为内存连续所以在数据读取上的效率也远高于普通的链表。
源码阅读
以下为经过翻译的Ziplist源码注释(又加入部分博主自己的理解),如有错误谢谢指正
/*
* ZIPLIST OVERALL LAYOUT
* ======================
*
* ziplist的大体布局如下:
*
* ...
*
* 注意:如果没有另外指定,所有字段都以小端存储。
*
* 是一个无符号整数,32bit。用于表示ziplist占用的字节总数。
* ziplist占用字节总数,包括 zlbytes 字段本身的四个字节。
* 这个值主要用于在ziplist中 entry 元素变化导致ziplist进行内存重分配时使用,或者计算 zlend的位置时使用
* 遍历集合中数据时,无需先遍历它。
*
* 32bit,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。
* 通过zltail我们可以很方便地找到最后一项,从而可以在ziplist尾端快速地执行push或pop操作,无需遍历整个集合。
*
* 16bit,表示ziplist中数据项(entry)的个数。
*
* 8bit,ziplist最后1个字节,是一个结束标记,值固定等于0xFF,转换为十进制则为:255。
* entry 表示真正存放数据的数据项,长度不定,下文中进行详解
* ZIPLIST ENTRIES
* ===============
*/
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //获取ziplist的zlbytes的指针
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //获取ziplist的zltail的指针
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //获取ziplist的zllen的指针
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) //ziplist头大小
#define ZIPLIST_END_SIZE (sizeof(uint8_t)) // ziplist结束标志位大小
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) // 获取第一个元素的指针
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) // 获取最后一个元素的指针
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1) // 获取结束标志位指针
unsigned char *ziplistNew(void) { // 创建一个压缩表
unsigned int bytes = ZIPLIST_HEADER_SIZE+1; // zip头加结束标识位数
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); // 大小端转换
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0; // len赋值为0
zl[bytes-1] = ZIP_END; // 结束标志位赋值
return zl;
}
图解Ziplist
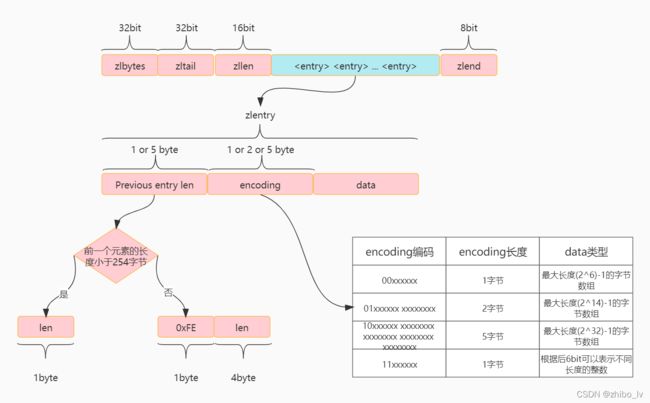
zlentry数据结构
/*
* 压缩列表节点 对应 上文中 Ziplist 中的 entry
* zlentry每个节点由三部分组成:Previous entry len、encoding、data
* prevlengh: 记录上一个节点的长度,为了方便反向遍历ziplist
* encoding: 编码,由于 ziplist 就是用来节省空间的,所以 ziplist 有多种编码,用来表示不同长度的字符串或整数。
* data: 用于存储 entry 真实的数据
* 结构体定义了7个字段,主要还是为了满足各种可变因素
*/
typedef struct zlentry {
unsigned int prevrawlensize; //prevrawlensize是描述prevrawlen的大小,有1字节和5字节两种
unsigned int prevrawlen; //prevrawlen是前一个节点的长度,
unsigned int lensize; //lensize为编码len所需的字节大小
unsigned int len; //len为当前节点长度
unsigned int headersize; //当前节点的header大小
unsigned char encoding; //节点的编码方式
unsigned char *p; //指向节点的指针
} zlentry;
如上Ziplist的设计结构,保障了空间的节省与查询的高效,但是当出现zlentry增加或删除时,Ziplist是不能直接在原有空间上进行修改,每一次变动都需要重新开辟空间去拷贝、修改。这样的场景下Ziplist一旦内部元素过多,将会导致性能的急剧下滑。因此Redis 在实现上做了一层优化,当Ziplist过大时,会将其分割成多个Ziplist,然后再通过一个双向链表将其串联起来。
quickList
Redis quicklist是Redis 3.2版本以后针对链表和压缩列表进行改造的一种数据结构,是 zipList 和 linkedList 的混合体,相对于链表它压缩了内存,进一步的提高了效率。
源码阅读
/*
* quicklist 是一个 40 字节的结构(在 64 位系统上),描述了一个快速列表。
* 'count' 所有ziplist数据项的个数总和。
* 'len' quicklist节点的个数。
* 'compress' 16bit,节点压缩深度设置,存放list-compress-depth参数的值。
* -1:禁止压缩
* >0:头/尾结点的前n个结点不压缩,其它结点压缩
* 'fill' 16bit,ziplist大小设置,存放list-max-ziplist-size参数的值。
*/
typedef struct quicklist {
quicklistNode *head; /* 指向头节点(左侧第一个节点)的指针。 */
quicklistNode *tail; /* 指向尾节点(右侧第一个节点)的指针。 */
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
/*
* quicklistNode 是一个 32 字节的结构,描述了一个快速列表的 ziplist。
* count: 16 bits, 表示ziplist里面包含的数据项个数。
* encoding: 2 bits, 1:RAW 未压缩, 2:LZF 被压缩了使用LZF压缩算法
* container: 2 bits, 1:NONE, 2:ZIPLIST。目前这个值只可能是 2:ZIPLIST.
* recompress: 1 bit, boolean,如果节点临时解压缩以供使用,则为 true。等待有机会了再把它重新压缩
* attempted_compress: 1 bit, boolean,用于测试期间的验证,不用关注
* extra: 10 bits, 预留字段
*/
typedef struct quicklistNode {
struct quicklistNode *prev; /* 指向链表前一个节点的指针。 */
struct quicklistNode *next; /* 指向链表后一个节点的指针。 */
unsigned char *zl; /* 数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构。 */
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/*
* quicklistLZF 是一个 4+N 字节结构,表示一个被压缩过的ziplist
* sz: 表示压缩后的ziplist大小。
* compressed: 是个柔性数组(flexible array member),存放压缩后的ziplist字节数组。
*/
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
图解quickList

通过控制ziplist 的大小,则很好的解决了超大ziplist 的拷贝情况下对性能的影响。每次改动只需要针对具体的小段ziplist 进行操作。
你的点赞就是我创作的最大动力,如果写的不错,来个三连行不行