show attend and tell代码实现(绝对详细)
文章目录
-
- 有兄弟提出这个博客中使用的是cpu版本的torch,训练速度太慢
- 有兄弟找不到flick8k.json文件的
- 一、介绍数据集格式
- 二、第一种方法(失败啦)
- 三、 第二种方法(成功啦)
-
- create_input_files.py的调试
- 在这里插入图片描述 终于走了一步了,开心的呀~(2021/9/5晚)
- train.py的调试
- 找不到BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth.tar文件的同学看这里:
- caption.py的调试
- 好家伙!
- 看来以后要认真看代码呀,注意代码最后一行的注释是否忘记引掉了。
- 四、 详细代码:Caption.py / train.py / utils.py / eval.py / datasets.py / create_input_files.py
-
- 下面是 Caption.py
- 下面是train.py
- 下面是utils.py
- 下面是eval.py
- 下面是datasets.py
- 下面是create_input_files.py
参考的两位大佬:
https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning
https://blog.csdn.net/weixin_44826203/article/details/107609852
有兄弟提出这个博客中使用的是cpu版本的torch,训练速度太慢
大家可以直接安装GPU版本的torch和torchvision:torch1.5.0+GPU、torchvision0.6.0+GPU,不会安装的同学请参考:
1、安装gpu版本的torch
2、nvcc --version与nvidia-smi区别(仅作为网友在遇到困难时的一种参考,如有不对请指出~)
也可以先按照本文博客中步骤先安装cpu版本的,然后再换成GPU版本的,即先忽略以上五行字(先把整个项目跑通了再说torch的cpu/gpu问题)
有兄弟找不到flick8k.json文件的
以下是链接:在https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning界面中找 Andrej Karpathy’s training, validation, and test splits. 有下载链接:http://cs.stanford.edu/people/karpathy/deepimagesent/caption_datasets.zip,
可以直接下载
一、介绍数据集格式
文件dataset_coco.json的数据格式:
总体内容格式是这个
{"images": [{***},{***},{***},...], "cocoid": 475546}], "dataset": "coco"}
其中的{***}表示一张图的详细内容,如下:
{
"filepath":"val2014",
"sentids":[
770762,
771353,
772262,
772508,
775349
],
"filename":"COCO_val2014_000000052759.jpg",
"imgid":150,
"split":"val",
"sentences":[
{
"tokens":[
"an",
"airplane",
"sits",
"on",
"the",
"tarmac",
"of",
"an",
"airport",
"with",
"a",
"disconnected",
"boarding",
"gate"
],
"raw":"An airplane sits on the tarmac of an airport, with a disconnected boarding gate.",
"imgid":150,
"sentid":770762
},
{
"tokens":[
"plane",
"boarding",
"passengers",
"while",
"at",
"a",
"fancy",
"airport"
],
"raw":"Plane boarding passengers while at a fancy airport",
"imgid":150,
"sentid":771353
},
{
"tokens":[
"a",
"plane",
"sitting",
"on",
"a",
"runway",
"getting",
"ready",
"to",
"be",
"emptied"
],
"raw":"A plane sitting on a runway getting ready to be emptied.",
"imgid":150,
"sentid":772262
},
{
"tokens":[
"this",
"is",
"a",
"airplane",
"on",
"the",
"runway",
"of",
"the",
"airport"
],
"raw":"THIS IS A AIRPLANE ON THE RUNWAY OF THE AIRPORT",
"imgid":150,
"sentid":772508
},
{
"tokens":[
"a",
"plan",
"parked",
"on",
"the",
"cement",
"near",
"a",
"terminal"
],
"raw":"A plan parked on the cement near a terminal.",
"imgid":150,
"sentid":775349
}
],
"cocoid":52759
}
二、第一种方法(失败啦)
创建环境:
conda create -n pytorch04 python=3.6
使用下面的创建命令创建失败,不知道为啥。
conda create -n pytorch04 python=3.6 -i https://pypi.douban.com/simple/
激活环境:
activate pytorch04
进入程序所在位置:
cd E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master
运行create_input_files.py
python create_input_files.py
运行失败报错:
ModuleNotFoundError: No module named 'h5py'
安装h5py
pip install h5py -i https://pypi.douban.com/simple/
安装结果为:
Successfully installed cached-property-1.5.2 h5py-3.1.0
继续运行程序
python create_input_files.py
运行失败报错:
Traceback (most recent call last):
File "create_input_files.py", line 1, in <mo
from utils import create_input_files
File "E:\show attend and tell\a-PyTorch-Tuto
ils.py", line 5, in <module>
import torch
ModuleNotFoundError: No module named 'torch'
即环境中没有安装0.4版本的pytorch(github中原作者提示使用的是0.4版本的pytorch和3.6的python)
下一步安装0.4的pytorch
pip install http://download.pytorch.org/whl/cpu/torch-0.4.0-cp36-cp36m-win_amd64.whl
安装命令参考:Windows下安装PyTorch0.4.0
再次运行程序试试,出错:
Traceback (most recent call last):
File "create_input_files.py", line 1, in <modul
from utils import create_input_files
File "E:\show attend and tell\a-PyTorch-Tutoria
ils.py", line 5, in <module>
import torch
File "D:\python3\envs\pytorch04\lib\site-packag
in <module>
from torch._C import *
ImportError: DLL load failed: 找不到指定的模块。
网上查找解决方法之后使用(评论中该方法绝佳!)
conda install numpy pyyaml mkl cmake cffi
参考:from torch._C import * ImportError: DLL load failed: 找不到指定的模块。
输入python,再enter回车
输入import torch 没有报错,即表示导入torch不成功的问题已经解决,以上链接牛逼!
试试运行程序:
python create_input_files.py
结果为:
Traceback (most recent call last):
File "create_input_files.py", line 1, in <
from utils import create_input_files
File "E:\show attend and tell\a-PyTorch-Tu
ils.py", line 6, in <module>
from scipy.misc import imread, imresize
ModuleNotFoundError: No module named 'scipy'
使用:
pip install scipy
安装结果为:
Installing collected packages: scipy
ERROR: pip's dependency resolver does not currently take into account all the pa
ckages that are installed. This behaviour is the source of the following depende
ncy conflicts.
parl 1.3.2 requires click, which is not installed.
parl 1.3.2 requires flask-cors, which is not installed.
parl 1.3.2 requires psutil>=5.6.2, which is not installed.
parl 1.3.2 requires pyarrow==0.13.0, which is not installed.
parl 1.3.2 requires pyzmq==18.0.1, which is not installed.
parl 1.3.2 requires tb-nightly==1.15.0a20190801, which is not installed.
parl 1.3.2 requires termcolor>=1.1.0, which is not installed.
Successfully installed scipy-1.5.4
ERROR部分是红色,即除第一行和最后一行不显示红色,其余均为红色
方法参考网上:ModuleNotFoundError: No module named 'scipy’解决方法
再运行程序,报错:
Traceback (most recent call last):
File "create_input_files.py", line 1, in <module>
from utils import create_input_files
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\ut
ils.py", line 6, in <module>
from scipy.misc import imread, imresize
ImportError: cannot import name 'imread'
查看scipy版本:
(pytorch04) E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-maste
r>python
Python 3.6.13 |Anaconda, Inc.| (default, Mar 16 2021, 11:37:27) [MSC v.1916 64 b
it (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import scipy
>>> print(scipy.__version__)
1.5.4
>>>
安装较低版本1.2.0的scipy
Requirement already satisfied: numpy>=1.8.2 in c:\users\admin\appdata\roaming\py
thon\python36\site-packages (from scipy==1.2.0) (1.19.5)
Installing collected packages: scipy
Attempting uninstall: scipy
Found existing installation: scipy 1.5.4
Uninstalling scipy-1.5.4:
Successfully uninstalled scipy-1.5.4
ERROR: pip's dependency resolver does not currently take into account all the pa
ckages that are installed. This behaviour is the source of the following depende
ncy conflicts.
parl 1.3.2 requires click, which is not installed.
parl 1.3.2 requires flask-cors, which is not installed.
parl 1.3.2 requires psutil>=5.6.2, which is not installed.
parl 1.3.2 requires pyarrow==0.13.0, which is not installed.
parl 1.3.2 requires pyzmq==18.0.1, which is not installed.
parl 1.3.2 requires tb-nightly==1.15.0a20190801, which is not installed.
parl 1.3.2 requires termcolor>=1.1.0, which is not installed.
Successfully installed scipy-1.2.0
ERROR语句为红色
以上解决方法参考:解决ImportError: cannot import name ‘imread’ from ‘scipy.misc’
另外一个知识点:可以在终端直接输入:
python -c "import scipy; print(scipy.__version__)"
进行查看某包的版本号,而不用一行一行输入:先输入python,再换行输入import scipy,再换行输入print(scipy.version),这种方法太麻烦
在运行程序,还是报错:
Traceback (most recent call last):
File "create_input_files.py", line 1, in <module>
from utils import create_input_files
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\ut
ils.py", line 6, in <module>
from scipy.misc import imread, imresize
ImportError: cannot import name 'imread'
重启了一下终端仍不能导入imread,说明降低scipy版本此方法走不通
再次看另一位博主使用另一种方法:安装imageio
将原先的程序
from scipy.misc import imread, imresize
改为
from imageio import imread
from scipy.misc import imresize
首先安装imageio
pip install imageio
安装结果为:
Installing collected packages: pillow, imageio
ERROR: pip's dependency resolver does not currently take into account all the pa
ckages that are installed. This behaviour is the source of the following depende
ncy conflicts.
matplotlib 3.3.2 requires cycler>=0.10, which is not installed.
matplotlib 3.3.2 requires kiwisolver>=1.0.1, which is not installed.
matplotlib 3.3.2 requires pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.3, which is not
installed.
matplotlib 3.3.2 requires python-dateutil>=2.1, which is not installed.
Successfully installed imageio-2.9.0 pillow-8.3.1
以上解决方法参考:解决ImportError: cannot import name ‘imread’ from ‘scipy.misc’
再次运行程序,报其他错:
(pytorch04) E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-maste
r>python create_input_files.py
Traceback (most recent call last):
File "create_input_files.py", line 1, in <module>
from utils import create_input_files
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\ut
ils.py", line 9, in <module>
from tqdm import tqdm
ModuleNotFoundError: No module named 'tqdm'
说明使用imageio的方法正确,接下来解决tqdm安装问题
使用
conda install tqdm
使用pip install tqdm也可以,安装完毕后结果为:
done
以上解决方案参考:【解决错误】ModuleNotFoundError: No module named ‘tqdm‘
再次运行程序出错:
Traceback (most recent call last):
File "create_input_files.py", line 11, in <module>
max_len=50)
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\ut
ils.py", line 31, in create_input_files
with open(karpathy_json_path, 'r') as j:
FileNotFoundError: [Errno 2] No such file or directory: '../caption data/dataset
_coco.json'
说明走到这里的程序已经没有问题,文件路径有错,修改文件路径
我想在pycharm中运行一下程序,所以在pycharm中先要切换一下环境,步骤如下

然后一路点击确定(2个),知道切换成功。
在pycharm中运行程序create_input_files.py,报之前的错误:
Traceback (most recent call last):
File "E:/show attend and tell/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py", line 11, in <module>
max_len=50)
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\utils.py", line 31, in create_input_files
with open(karpathy_json_path, 'r') as j:
FileNotFoundError: [Errno 2] No such file or directory: '../caption data/dataset_coco.json'
很好!,说明pycharm切换环境成功,接下来修改文件路径
修改后,运行报错:
Traceback (most recent call last):
File "E:/show attend and tell/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py", line 11, in <module>
max_len=50)
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\utils.py", line 84, in create_input_files
with open(os.path.join(output_folder, 'WORDMAP_' + base_filename + '.json'), 'w') as j:
FileNotFoundError: [Errno 2] No such file or directory: '/media/ssd/caption data/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json'
提示没有文件,那就下载文件,找到网址:
https://drive.google.com/drive/folders/189VY65I_n4RTpQnmLGj7IzVnOF6dmePC
注册登录Google账号,下载更加方便参考我自己注册Google
账号中出现的问题,参考:此电话号码无法用于进行验证。
可以下载文件:WORDMAP_coco_5_cap_per_img_5_min_word_freq.json
另一个文件应该是生成的,所以不用去下载
运行程序,发现这句程序报错:
images = h.create_dataset('images', (len(impaths), 3, 256, 256), dtype='uint8')
报错为:
Traceback (most recent call last):
File "E:/show attend and tell/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py", line 11, in <module>
max_len=50)
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\utils.py", line 108, in create_input_files
images = h.create_dataset('images', (len(impaths), 3, 256, 256), dtype='uint8')
File "D:\python3\envs\pytorch04\lib\site-packages\h5py\_hl\group.py", line 148, in create_dataset
dsid = dataset.make_new_dset(group, shape, dtype, data, name, **kwds)
File "D:\python3\envs\pytorch04\lib\site-packages\h5py\_hl\dataset.py", line 137, in make_new_dset
dset_id = h5d.create(parent.id, name, tid, sid, dcpl=dcpl)
File "h5py\_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py\_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py\h5d.pyx", line 87, in h5py.h5d.create
ValueError: Unable to create dataset (name already exists)
我感觉是
images = h.create_dataset('images', (len(impaths), 3, 256, 256), dtype='uint8')
中的images的名字有重复的了,所以先暂时改名为
images = h.create_dataset('imagesss', (len(impaths), 3, 256, 256), dtype='uint8')
再次运行程序,结果报错:
Traceback (most recent call last):
File "E:/show attend and tell/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py", line 11, in <module>
max_len=50)
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\utils.py", line 127, in create_input_files
img = imread(impaths[i])
File "D:\python3\envs\pytorch04\lib\site-packages\imageio\core\functions.py", line 265, in imread
reader = read(uri, format, "i", **kwargs)
File "D:\python3\envs\pytorch04\lib\site-packages\imageio\core\functions.py", line 172, in get_reader
request = Request(uri, "r" + mode, **kwargs)
File "D:\python3\envs\pytorch04\lib\site-packages\imageio\core\request.py", line 124, in __init__
self._parse_uri(uri)
File "D:\python3\envs\pytorch04\lib\site-packages\imageio\core\request.py", line 260, in _parse_uri
raise FileNotFoundError("No such file: '%s'" % fn)
FileNotFoundError: No such file: 'E:\media\ssd\caption data\val2014\COCO_val2014_000000522418.jpg'
发现路径'E:\media\ssd\caption data\val2014\COCO_val2014_000000522418.jpg'没有见到过,
以上方法宣布失败。。。问题出在这句话上 images = h.create_dataset('images', (len(impaths), 3, 256, 256), dtype='uint8'),总是报以下错误,且在网上找不到原因
Traceback (most recent call last):
File "E:/show attend and tell/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py", line 11, in <module>
max_len=50)
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\utils.py", line 109, in create_input_files
images = h.create_dataset('images', (len(impaths), 3, 256, 256), dtype='uint8')
File "D:\python3\envs\pytorch04\lib\site-packages\h5py\_hl\group.py", line 148, in create_dataset
dsid = dataset.make_new_dset(group, shape, dtype, data, name, **kwds)
File "D:\python3\envs\pytorch04\lib\site-packages\h5py\_hl\dataset.py", line 137, in make_new_dset
dset_id = h5d.create(parent.id, name, tid, sid, dcpl=dcpl)
File "h5py\_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py\_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py\h5d.pyx", line 87, in h5py.h5d.create
ValueError: Unable to create dataset (name already exists)
三、 第二种方法(成功啦)
参考:超详细!“看图说话”(Image Caption)项目实战
重新创建环境
pytorch:1.5.0
conda create -n pytorch150 python=3.6
在以下网站
https://download.pytorch.org/whl/torch_stable.html
中下载文件
torch-1.5.0+cpu-cp36-cp36m-win_amd64.whl
然后将其放入环境D:\python3\envs\pytorch150\Scripts中,注意是Scripts下
在终端激活环境pytorch150,使用下面命令安装pytorch
pip install torch-1.5.0+cpu-cp36-cp36m-win_amd64.whl
安装其他包:
conda install scipy==1.2.1
conda install nltk
conda install h5py
conda install tqdm
pip 安装也可以,我使用的是pip安装以上包
create_input_files.py的调试
运行create_input_files.py程序报错:
Traceback (most recent call last):
File "create_input_files.py", line 1, in <module>
from utils import create_input_files
File "E:\show attend and tell\a-PyTorch-Tutorial-to-Image-Captioning-master\ut
ils.py", line 6, in <module>
from scipy.misc import imread, imresize
ImportError: cannot import name 'imread'
说明还是没有之前的包,继续安装imageio
将原先的程序
from scipy.misc import imread, imresize
改为
from imageio import imread
from scipy.misc import imresize
运行程序,报错:
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py", line 11, in <module>
max_len=50)
File "E:\Show\a-PyTorch-Tutorial-to-Image-Captioning-master\utils.py", line 31, in create_input_files
with open(karpathy_json_path, 'r') as j:
FileNotFoundError: [Errno 2] No such file or directory: '../caption data/dataset_coco.json'
错误出现在以下程序的karpathy_json_path='../caption data/dataset_coco.json'
from utils import create_input_files
if __name__ == '__main__':
# Create input files (along with word map)
create_input_files(dataset='coco',
karpathy_json_path='../caption data/dataset_coco.json',
image_folder='/media/ssd/caption data/',
captions_per_image=5,
min_word_freq=5,
output_folder='/media/ssd/caption data/',
max_len=50)
在create_input_files.py中调用了utils.py中的函数create_input_files
with open(karpathy_json_path, 'r') as j:
data = json.load(j)
这一句中没有找到文件地址,查看文件放置的正确性,修改好文件摆放位置之后,运行程序,正常啦!!!
如下图

再查看文件里面有什么变化没 喔呦!生成了下面的9个文件,和这位大神的实现一样

终于走了一步了,开心的呀~(2021/9/5晚)
开搞!(2021/9/6中午)
看了参考的文章下一步怎么做
train.py的调试
该运行train.py了,运行报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 5, in <module>
import torchvision.transforms as transforms
ModuleNotFoundError: No module named 'torchvision'
没有torchvision那就安装,回想起之前博主提起过安装这俩

我是只安装了pytorch1.50+python3.6,当时将pytorch1.50的安装包放在了Script文件下,然后在终端安装的,这次就先试试直接安装吧,
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>conda install torchvis
ion==0.6.0
Collecting package metadata (repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible so
lve.
PackagesNotFoundError: The following packages are not available from current cha
nnels:
- torchvision==0.6.0
Current channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/noarch
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/noarch
To search for alternate channels that may provide the conda package you're
looking for, navigate to
https://anaconda.org
and use the search bar at the top of the page.
用命令行安装失败了,哈哈哈哈哈,失败原因不管了,那就不用这种方法了
在下面
https://download.pytorch.org/whl/torch_stable.html
下载了名为torchvision-0.6.0+cpu-cp36-cp36m-win_amd64.whl的文件放在了pytorch150的环境下,具体文件地址是D:\python3\envs\pytorch150\Lib\site-packages,使用pip install torchvision-0.6.0+cpu-cp36-cp36m-win_amd64.whl安装好界面是下面的
又可以安装train.py文件啦!!!
运行试试!报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 331, in <module>
main()
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 50, in main
with open(word_map_file, 'r') as j:
FileNotFoundError: [Errno 2] No such file or directory: '/media/ssd/caption data\\WORDMAP_coco_5_cap_per_img_5_min_word_freq.json'
Process finished with exit code 1
干!!!!!!!
分析原因:是train.py中的
data_name = 'coco_5_cap_per_img_5_min_word_freq' # base name shared by data files
设置的不对,因为我使用的是Flickr8k,原代码中使用的是COCO
所以改一下
data_name = 'flickr8k_5_cap_per_img_5_min_word_freq' # base name shared by data files
在E:\media\ssd\caption data\Flickr8k中找到WORDMAP_flickr8k_5_cap_per_img_5_min_word_freq.json文件,以这个名修改上面的data_name,又因为在train.py的main()函数是用下面的方式处理的,所以省去WORDMAP_和.json
word_map_file = os.path.join(data_folder, 'WORDMAP_' + data_name + '.json')
with open(word_map_file, 'r') as j:
word_map = json.load(j)
修改好,在尝试运行,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 332, in <module>
main()
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 51, in main
with open(word_map_file, 'r') as j:
FileNotFoundError: [Errno 2] No such file or directory: '/media/ssd/caption data\\WORDMAP_flickr8k_5_cap_per_img_5_min_word_freq.json'
Process finished with exit code 1
原来是路径也需要修改
data_folder = '/media/ssd/caption data' # folder with data files saved by create_input_files.py
改为:
data_folder = '/media/ssd/caption data/Flicker8k/' # folder with data files saved by create_input_files.py
运行train.py报以下错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py
Downloading: "https://download.pytorch.org/models/resnet101-5d3b4d8f.pth" to C:\Users\admin/.cache\torch\checkpoints\resnet101-5d3b4d8f.pth
100%|██████████| 170M/170M [01:05<00:00, 2.74MB/s]
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 333, in <module>
main()
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 118, in main
epoch=epoch)
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 164, in train
for i, (imgs, caps, caplens) in enumerate(train_loader):
File "D:\python3\envs\pytorch150\lib\site-packages\torch\utils\data\dataloader.py", line 279, in __iter__
return _MultiProcessingDataLoaderIter(self)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\utils\data\dataloader.py", line 719, in __init__
w.start()
File "D:\python3\envs\pytorch150\lib\multiprocessing\process.py", line 105, in start
self._popen = self._Popen(self)
File "D:\python3\envs\pytorch150\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "D:\python3\envs\pytorch150\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "D:\python3\envs\pytorch150\lib\multiprocessing\popen_spawn_win32.py", line 65, in __init__
reduction.dump(process_obj, to_child)
File "D:\python3\envs\pytorch150\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
File "D:\python3\envs\pytorch150\lib\site-packages\h5py\_hl\base.py", line 372, in __getnewargs__
raise TypeError("h5py objects cannot be pickled")
TypeError: h5py objects cannot be pickled
Process finished with exit code 1
分析错误:说明已经下载了resnet模型:resnet101-5d3b4d8f.pth
参考这篇博客,修改如下:
将原代码中的
train_loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'TRAIN', transform=transforms.Compose([normalize])),
batch_size=batch_size, shuffle=True, num_workers=workers, pin_memory=True)
val_loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'VAL', transform=transforms.Compose([normalize])),
batch_size=batch_size, shuffle=True, num_workers=workers, pin_memory=True)
的两个num_workers=workers删除,运行train.py报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 333, in <module>
main()
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 118, in main
epoch=epoch)
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 181, in train
scores, _ = pack_padded_sequence(scores, decode_lengths, batch_first=True)
ValueError: too many values to unpack (expected 2)
Process finished with exit code 1
上网搜搜报的错是个啥意思嘿
哈哈哈,找到解决方法了,献上链接
修改程序中
scores, _ = pack_padded_sequence(scores, decode_lengths, batch_first=True)
为
scores = pack_padded_sequence(scores, decode_lengths, batch_first=True)[0]
print(scores)
顺便查看一下结果,再运行程序还是出原来的错,只是位置不同了
运行结果:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py
我已经运行到这里了
tensor([[-0.0136, 0.0150, 0.0528, ..., 0.2292, -0.2899, 0.3463],
[-0.5298, 0.1216, 0.1333, ..., 0.3054, 0.0307, -0.0306],
[-0.1771, 0.1554, 0.1336, ..., 0.1443, -0.0566, -0.2475],
...,
[ 0.1615, -0.0726, -0.0425, ..., -0.2490, -0.2140, -0.0373],
[-0.1486, -0.3121, -0.3258, ..., -0.3477, -0.5346, 0.3969],
[-0.0918, -0.1189, 0.1954, ..., 0.0450, -0.4835, 0.3521]],
grad_fn=<PackPaddedSequenceBackward>)
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 335, in <module>
main()
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 118, in main
epoch=epoch)
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py", line 184, in train
targets, _ = pack_padded_sequence(targets, decode_lengths, batch_first=True)
ValueError: too many values to unpack (expected 2)
Process finished with exit code 1
修改targets这一行代码为:
targets = pack_padded_sequence(targets, decode_lengths, batch_first=True)[0]
再次运行train.py,出现以下结果:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/train.py
我已经运行到这里了
Epoch: [0][0/938] Batch Time 14.813 (14.813) Data Load Time 0.325 (0.325) Loss 8.7799 (8.7799) Top-5 Accuracy 0.000 (0.000)
Process finished with exit code -1
说明train.py已经可以跑了,但是跑的数据量太大,就暂时停下,将Flickr8k的数据量降低,先跑出个demo出来,保证程序能够走通
我选择了100张图片放在路径E:\media\ssd\caption data\Flickr8k\Flicker8k_Dataset下,运行代码,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py
Reading TRAIN images and captions, storing to file...
0%| | 0/6000 [00:00<?, ?it/s]
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/create_input_files.py", line 27, in <module>
max_len=50)
File "E:\Show\a-PyTorch-Tutorial-to-Image-Captioning-master\utils.py", line 117, in create_input_files
img = imread(impaths[i])
File "D:\python3\envs\pytorch150\lib\site-packages\imageio\core\functions.py", line 265, in imread
reader = read(uri, format, "i", **kwargs)
File "D:\python3\envs\pytorch150\lib\site-packages\imageio\core\functions.py", line 172, in get_reader
request = Request(uri, "r" + mode, **kwargs)
File "D:\python3\envs\pytorch150\lib\site-packages\imageio\core\request.py", line 124, in __init__
self._parse_uri(uri)
File "D:\python3\envs\pytorch150\lib\site-packages\imageio\core\request.py", line 260, in _parse_uri
raise FileNotFoundError("No such file: '%s'" % fn)
FileNotFoundError: No such file: 'E:\media\ssd\caption data\Flickr8k\Flicker8k_Dataset\2513260012_03d33305cf.jpg'
Process finished with exit code 1
报错原因是在一个已经将Flickr8k的所有文本数据已经集成为一个json文件:dataset_flickr8k.json
中未找到对应的图片,所以程序会出现找不到文件得错误
而读取该文件的程序为:
with open(karpathy_json_path, 'r') as j:
data = json.load(j)
print(data)
这个文件的路径为karpathy_json_path='../caption data/dataset_flickr8k.json'
所以要保证程序能够运行,只能减小批的大小,将之前删掉的文件重新复制回去,再次运行create_input_files生成相应文件
把下面的参数维度都改的小一点:
由原来的
emb_dim = 512 # dimension of word embeddings
attention_dim = 512 # dimension of attention linear layers
decoder_dim = 512 # dimension of decoder RNN
改为
emb_dim = 16 # dimension of word embeddings
attention_dim = 16 # dimension of attention linear layers
decoder_dim = 16 # dimension of decoder RNN
将
epochs = 120
改为
epochs = 1
跑以下看看~
没跑完,电脑声音太大,手动暂停了
结果:

总结一下使用的包的版本(有兄弟提出这个博客中使用的是cpu版本的torch,训练速度太慢,大家可以直接安装GPU版本的torch和torchvision:torch1.5.0+GPU、torchvision0.6.0+GPU,不会安装的同学请参考:
1、安装gpu版本的torch
2、nvcc --version与nvidia-smi区别(仅作为网友在遇到困难时的一种参考,如有不对请指出~)
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip list
Package Version
------------------ -------------------
attrs 21.2.0
cached-property 1.5.2
certifi 2021.5.30
cffi 1.14.6
ChatterBot 1.1.0
click 8.0.1
cloudpickle 1.2.1
colorama 0.4.4
cryptography 3.4.8
Flask 1.1.2
future 0.18.2
h5py 3.1.0
imageio 2.9.0
importlib-metadata 4.8.1
Jinja2 2.11.2
joblib 1.0.1
mathparse 0.1.2
matplotlib 3.3.2
mkl-fft 1.3.0
mkl-random 1.1.1
mkl-service 2.3.0
nltk 3.6.2
numpy 1.19.5
pandas 1.1.5
parl 1.3.2
Pillow 8.3.2
Pint 0.17
pip 21.2.2
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycparser 2.20
regex 2021.8.28
scipy 1.2.1
service-identity 21.1.0
setuptools 52.0.0.post20210125
six 1.16.0
tensorboardX 1.8
torch 1.5.0+cpu
torchvision 0.6.0+cpu
tqdm 4.62.2
typing-extensions 3.10.0.2
wheel 0.37.0
wincertstore 0.2
zipp 3.5.0
找不到BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth.tar文件的同学看这里:
以上是对train文件的一个调试,即可以训练模型了,只要运行了train.py文件到它结束,就会得到在在训练过程中经过评估过的最好模型文件,其命名为BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth.tar,具体为什么会生成这样一个模型文件,可以在train.py中看相关代码
caption.py的调试
还没写完。
按照博客中写到的还有效果没有演示,也没有进行测试
继续进行调试代码
首先运行caption.py文件,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 6, in <module>
import matplotlib.pyplot as plt
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\__init__.py", line 107, in <module>
from . import cbook, rcsetup
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\rcsetup.py", line 28, in <module>
from matplotlib.fontconfig_pattern import parse_fontconfig_pattern
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\fontconfig_pattern.py", line 15, in <module>
from pyparsing import (Literal, ZeroOrMore, Optional, Regex, StringEnd,
ModuleNotFoundError: No module named 'pyparsing'
Process finished with exit code 1
安装该模块试试:成功安装~
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip install pyparsing
Looking in indexes: http://pypi.douban.com/simple
Collecting pyparsing
Downloading http://pypi.doubanio.com/packages/8a/bb/488841f56197b13700afd5658f
c279a2025a39e22449b7cf29864669b15d/pyparsing-2.4.7-py2.py3-none-any.whl (67 kB)
|██████████████▌ | 30 kB 1.9 MB/s eta 0:00:0
|███████████████████ | 40 kB 2.6 MB/s eta 0:
|████████████████████████ | 51 kB 3.2 MB/s e
|█████████████████████████████ | 61 kB 3.8 M
|████████████████████████████████| 67 kB 1.
1 MB/s
Installing collected packages: pyparsing
ERROR: pip's dependency resolver does not currently take into account all the pa
ckages that are installed. This behaviour is the source of the following depende
ncy conflicts.
matplotlib 3.3.2 requires cycler>=0.10, which is not installed.
matplotlib 3.3.2 requires kiwisolver>=1.0.1, which is not installed.
matplotlib 3.3.2 requires python-dateutil>=2.1, which is not installed.
Successfully installed pyparsing-2.4.7
再次执行caption.py代码,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 6, in <module>
import matplotlib.pyplot as plt
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\__init__.py", line 107, in <module>
from . import cbook, rcsetup
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\rcsetup.py", line 32, in <module>
from cycler import Cycler, cycler as ccycler
ModuleNotFoundError: No module named 'cycler'
Process finished with exit code 1
安装cycler~:
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip install cycler
Looking in indexes: http://pypi.douban.com/simple
Collecting cycler
Downloading http://pypi.doubanio.com/packages/f7/d2/e07d3ebb2bd7af696440ce7e75
4c59dd546ffe1bbe732c8ab68b9c834e61/cycler-0.10.0-py2.py3-none-any.whl (6.5 kB)
Requirement already satisfied: six in c:\users\admin\appdata\roaming\python\pyth
on36\site-packages (from cycler) (1.16.0)
Installing collected packages: cycler
ERROR: pip's dependency resolver does not currently take into account all the pa
ckages that are installed. This behaviour is the source of the following depende
ncy conflicts.
matplotlib 3.3.2 requires kiwisolver>=1.0.1, which is not installed.
matplotlib 3.3.2 requires python-dateutil>=2.1, which is not installed.
Successfully installed cycler-0.10.0
再次执行caption.py代码,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 6, in <module>
import matplotlib.pyplot as plt
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\__init__.py", line 174, in <module>
_check_versions()
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\__init__.py", line 168, in _check_versions
module = importlib.import_module(modname)
File "D:\python3\envs\pytorch150\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
ModuleNotFoundError: No module named 'dateutil'
怎么缺这么多东西?继续安装!报错:
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip install dateutil
Looking in indexes: http://pypi.douban.com/simple
ERROR: Could not find a version that satisfies the requirement dateutil (from ve
rsions: none)
ERROR: No matching distribution found for dateutil
找不到对应版本的dateutil,查一下,解决方法:python安装提示错误Could not find a version that satisfies the requirement dateutil
使用:
pip install python-dateutil
安装即可,安装结果为
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip install python-dat
eutil
Looking in indexes: http://pypi.douban.com/simple
Collecting python-dateutil
Downloading http://pypi.doubanio.com/packages/36/7a/87837f39d0296e723bb9b62bbb
257d0355c7f6128853c78955f57342a56d/python_dateutil-2.8.2-py2.py3-none-any.whl (2
47 kB)
|█████████████ | 102 kB 1.3 MB/s eta 0:00:01
|██████████████▌ | 112 kB 1.3 MB/s eta 0:00:
|████████████████ | 122 kB 1.3 MB/s eta 0:00
|█████████████████ | 133 kB 1.3 MB/s eta 0:0
|██████████████████▌ | 143 kB 1.3 MB/s eta 0
|████████████████████ | 153 kB 1.3 MB/s eta
|█████████████████████ | 163 kB 1.3 MB/s eta
|██████████████████████▌ | 174 kB 1.3 MB/s e
|████████████████████████ | 184 kB 1.3 MB/s
|█████████████████████████ | 194 kB 1.3 MB/s
|██████████████████████████▌ | 204 kB 1.3 MB
|████████████████████████████ | 215 kB 1.3 M
|█████████████████████████████ | 225 kB 1.3
|██████████████████████████████▌ | 235 kB 1.
|████████████████████████████████| 245 kB 1
|████████████████████████████████| 247 kB 1
.3 MB/s
Requirement already satisfied: six>=1.5 in c:\users\admin\appdata\roaming\python
\python36\site-packages (from python-dateutil) (1.16.0)
Installing collected packages: python-dateutil
ERROR: pip's dependency resolver does not currently take into account all the pa
ckages that are installed. This behaviour is the source of the following depende
ncy conflicts.
pandas 1.1.5 requires pytz>=2017.2, which is not installed.
matplotlib 3.3.2 requires kiwisolver>=1.0.1, which is not installed.
chatterbot 1.1.0 requires pytz, which is not installed.
chatterbot 1.1.0 requires pyyaml<5.4,>=5.3, which is not installed.
chatterbot 1.1.0 requires spacy<2.2,>=2.1, which is not installed.
chatterbot 1.1.0 requires sqlalchemy<1.4,>=1.3, which is not installed.
Successfully installed python-dateutil-2.8.2
安装过程中出现ERROR红色部分
再次执行caption.py代码,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 6, in <module>
import matplotlib.pyplot as plt
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\__init__.py", line 174, in <module>
_check_versions()
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\matplotlib\__init__.py", line 168, in _check_versions
module = importlib.import_module(modname)
File "D:\python3\envs\pytorch150\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
ModuleNotFoundError: No module named 'kiwisolver'
Process finished with exit code 1
安装kiwisolver,效果为
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip install kiwisolver
Looking in indexes: http://pypi.douban.com/simple
Collecting kiwisolver
Downloading http://pypi.doubanio.com/packages/6e/df/1250c32ab3b532c32a7e47c1cd
240faba98f75b1b5150939b10e9bffb758/kiwisolver-1.3.1-cp36-cp36m-win_amd64.whl (51
kB)
|███████████████████ | 30 kB 667 kB/s eta 0:
|█████████████████████████▌ | 40 kB 890 kB/s
|████████████████████████████████| 51 kB 1.
|████████████████████████████████| 51 kB 1.
3 MB/s
Installing collected packages: kiwisolver
Successfully installed kiwisolver-1.3.1
再次执行caption.py代码,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 8, in <module>
import skimage.transform
ModuleNotFoundError: No module named 'skimage'
Process finished with exit code 1
这次是运行了一小会儿才报错,之前是刚运行就报错,
再次执行caption.py代码,报错:
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip install skimage
Looking in indexes: http://pypi.douban.com/simple
Collecting skimage
Downloading http://pypi.doubanio.com/packages/3b/ee/edbfa69ba7b7d9726e634bfbee
fd04b5a1764e9e74867ec916113eeaf4a1/skimage-0.0.tar.gz (757 bytes)
ERROR: Command errored out with exit status 1:
command: 'D:\python3\envs\pytorch150\python.exe' -c 'import io, os, sys, se
tuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\admin\\AppData\\Local\\Temp\\p
ip-install-5elfgxoz\\skimage_60fd398f44644dd4b0bc3ba31cc28911\\setup.py'"'"'; __
file__='"'"'C:\\Users\\admin\\AppData\\Local\\Temp\\pip-install-5elfgxoz\\skimag
e_60fd398f44644dd4b0bc3ba31cc28911\\setup.py'"'"';f = getattr(tokenize, '"'"'ope
n'"'"', open)(__file__) if os.path.exists(__file__) else io.StringIO('"'"'from s
etuptools import setup; setup()'"'"');code = f.read().replace('"'"'\r\n'"'"', '"
'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' egg_info --
egg-base 'C:\Users\admin\AppData\Local\Temp\pip-pip-egg-info-7v71frr9'
cwd: C:\Users\admin\AppData\Local\Temp\pip-install-5elfgxoz\skimage_60f
d398f44644dd4b0bc3ba31cc28911\
Complete output (3 lines):
*** Please install the `scikit-image` package (instead of `skimage`) ***
----------------------------------------
WARNING: Discarding http://pypi.doubanio.com/packages/3b/ee/edbfa69ba7b7d9726e63
4bfbeefd04b5a1764e9e74867ec916113eeaf4a1/skimage-0.0.tar.gz#sha256=6c96a11d9deea
68489c9b80b38fad1dcdab582c36d4fa093b99b24a3b30c38ec (from http://pypi.doubanio.c
om/simple/skimage/). Command errored out with exit status 1: python setup.py egg
_info Check the logs for full command output.
ERROR: Could not find a version that satisfies the requirement skimage (from ver
sions: 0.0)
ERROR: No matching distribution found for skimage
错误有点类似上一个,就是找不到对应版本的,不知道使用那个方法如何,试了下
使用
pip install-skimage
不行,结果为
(pytorch150) D:\python3\envs\pytorch150\Lib\site-packages>pip install-skimage
ERROR: unknown command "install-skimage" - maybe you meant "install"
使用方法:skimage库安装
即使用命令行代码:
conda install scikit-image
安装效果已经被黑屏刷了只剩下个done
再次执行caption.py代码,报错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
kakak
Traceback (most recent call last):
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 311, in _check_seekable
f.seek(f.tell())
AttributeError: 'NoneType' object has no attribute 'seek'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 200, in <module>
checkpoint = torch.load(args.model, map_location=str(device))
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 584, in load
with _open_file_like(f, 'rb') as opened_file:
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 239, in _open_file_like
return _open_buffer_reader(name_or_buffer)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 224, in __init__
_check_seekable(buffer)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 314, in _check_seekable
raise_err_msg(["seek", "tell"], e)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 307, in raise_err_msg
raise type(e)(msg)
AttributeError: 'NoneType' object has no attribute 'seek'. You can only torch.load from a file that is seekable. Please pre-load the data into a buffer like io.BytesIO and try to load from it instead.
Process finished with exit code 1
记着之前参考的文章中评论中有关于该错误的描述,但是没有解决方法,那就上网搜
使用[retinanet] AttributeError: ‘NoneType‘ object has no attribuYou can only torch.load from a file that中介绍的方法将:
parser.add_argument('--model', '-m', help='path to model')
改为
parser.add_argument('--model', default='-m', help='path to model')
出错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 200, in <module>
checkpoint = torch.load(args.model, map_location=str(device))
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 584, in load
with _open_file_like(f, 'rb') as opened_file:
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 234, in _open_file_like
return _open_file(name_or_buffer, mode)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 215, in __init__
super(_open_file, self).__init__(open(name, mode))
FileNotFoundError: [Errno 2] No such file or directory: '-m'
Process finished with exit code 1
在程序
if __name__ == '__main__':
#大多数对 ArgumentParser 构造方法的调用都会使用 description= 关键字参数。这个参数简要描述这个程度做什么以及怎么做。
# 在帮助消息中,这个描述会显示在命令行用法字符串和各种参数的帮助消息之间。
parser = argparse.ArgumentParser(description='Show, Attend, and Tell - Tutorial - Generate Caption')
#给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。通常,这些调用指定 ArgumentParser
# 如何获取命令行字符串并将其转换为对象。这些信息在 parse_args() 调用时被存储和使用。
parser.add_argument('--img', '-i', help='path to image')
parser.add_argument('--model', '-m', help='path to model')
parser.add_argument('--word_map', '-wm', help='path to word map JSON')
parser.add_argument('--beam_size', '-b', default=5, type=int, help='beam size for beam search')
parser.add_argument('--dont_smooth', dest='smooth', action='store_false', help='do not smooth alpha overlay')
args = parser.parse_args()
print('----***----'*5)
添加输出符,发现并不是parser.add_argument中参数的问题
继续寻找bug吧
在程序
if __name__ == '__main__':
#大多数对 ArgumentParser 构造方法的调用都会使用 description= 关键字参数。这个参数简要描述这个程度做什么以及怎么做。
# 在帮助消息中,这个描述会显示在命令行用法字符串和各种参数的帮助消息之间。
parser = argparse.ArgumentParser(description='Show, Attend, and Tell - Tutorial - Generate Caption')
#给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。通常,这些调用指定 ArgumentParser
# 如何获取命令行字符串并将其转换为对象。这些信息在 parse_args() 调用时被存储和使用。
parser.add_argument('--img', '-i', help='path to image')
parser.add_argument('--model', '-m', help='path to model')
parser.add_argument('--word_map', '-wm', help='path to word map JSON')
parser.add_argument('--beam_size', '-b', default=5, type=int, help='beam size for beam search')
parser.add_argument('--dont_smooth', dest='smooth', action='store_false', help='do not smooth alpha overlay')
args = parser.parse_args()
# Load model
checkpoint = torch.load(args.model, map_location=str(device))
print('----***----' * 5)
出了错,并且没有print()应该就是checkpoint = torch.load(args.model, map_location=str(device))这句话有问题,
打印
print(args.model)
输出为
None
——————以下是2021/09/28更新——————
检查文件发现保存的模型文件名称为BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth.tar
这是压缩包呀,我可没见过模型保存为压缩包的。至于为啥保存为压缩包需要看eval.py文件中的保存方式,不多说了
1、试图解压这个压缩包,发现提示压缩文件不存在,反正就是解压不了,去他奶奶的!
2、换名称,直接去掉.tar,去掉之后以.pth结尾的文件咱是不是就见过了
此时再次运行caption.py出现错误:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
None
Traceback (most recent call last):
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 311, in _check_seekable
f.seek(f.tell())
AttributeError: 'NoneType' object has no attribute 'seek'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 208, in <module>
checkpoint = torch.load(args.model, map_location=str(device))
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 584, in load
with _open_file_like(f, 'rb') as opened_file:
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 239, in _open_file_like
return _open_buffer_reader(name_or_buffer)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 224, in __init__
_check_seekable(buffer)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 314, in _check_seekable
raise_err_msg(["seek", "tell"], e)
File "D:\python3\envs\pytorch150\lib\site-packages\torch\serialization.py", line 307, in raise_err_msg
raise type(e)(msg)
AttributeError: 'NoneType' object has no attribute 'seek'. You can only torch.load from a file that is seekable. Please pre-load the data into a buffer like io.BytesIO and try to load from it instead.
Process finished with exit code 1
查找出错原因,在[retinanet] AttributeError: ‘NoneType‘ object has no attribuYou can only torch.load from a file that中找到解决方案,同时发现该博主研究caption。。。牛批
增加这个文件的路径defult_path = './BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth'
方便调用,添加parser.add_argument('--model', '-m',default=defult_path, help='path to model')
if __name__ == '__main__':
defult_path = './BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth'
#大多数对 ArgumentParser 构造方法的调用都会使用 description= 关键字参数。这个参数简要描述这个程度做什么以及怎么做。
# 在帮助消息中,这个描述会显示在命令行用法字符串和各种参数的帮助消息之间。
parser = argparse.ArgumentParser(description='Show, Attend, and Tell - Tutorial - Generate Caption')
#给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。通常,这些调用指定 ArgumentParser
# 如何获取命令行字符串并将其转换为对象。这些信息在 parse_args() 调用时被存储和使用。
# 函数 add_argument() 第一个是选项, 第二个是数据类型, 第三个默认值, 第四个是help命令时的说明
# parser.add_argument('--img', '-i', help='path to image')
# parser.add_argument('--model', '-m', help='path to model')
parser.add_argument('--model', '-m',default=defult_path, help='path to model')
# parser.add_argument('--model', '-m', help='path to model')
# parser.add_argument('--word_map', '-wm', help='path to word map JSON')
# parser.add_argument('--beam_size', '-b', default=5, type=int, help='beam size for beam search')
# parser.add_argument('--dont_smooth', dest='smooth', action='store_false', help='do not smooth alpha overlay')
args = parser.parse_args()
print(args.model)
# Load model
checkpoint = torch.load(args.model, map_location=str(device))
print('----***----' * 5)
再次运行caption.py,输出结果为
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
./BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth
----***--------***--------***--------***--------***----
Process finished with exit code 0
输出结果是这样,但是还是不知道现在走到这里对不对,反正不出错了,先这样。
运行载入checkpoint 之后的几行代码
decoder = checkpoint['decoder']
decoder = decoder.to(device)
decoder.eval()
encoder = checkpoint['encoder']
encoder = encoder.to(device)
encoder.eval()
print('----***----' * 5)
出错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
./BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth
----***--------***--------***--------***--------***----
----***--------***--------***--------***--------***----
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 229, in <module>
visualize_att(args.img, seq, alphas, rev_word_map, args.smooth)
AttributeError: 'Namespace' object has no attribute 'img'
Process finished with exit code 1
说明checkpoint载入成功但是好像没有img属性啥的,那就先看看checkpoint是个啥东西
打印checpoint输出如下结果
{'epoch': 10, 'epochs_since_improvement': 0, 'bleu-4': 0.16030028115895864, 'encoder': Encoder(
(resnet): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(5): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(6): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(6): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(7): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(8): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(9): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(10): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(11): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(12): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(13): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(14): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(15): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(16): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(17): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(18): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(19): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(20): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(21): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(22): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(7): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
(adaptive_pool): AdaptiveAvgPool2d(output_size=(14, 14))
), 'decoder': DecoderWithAttention(
(attention): Attention(
(encoder_att): Linear(in_features=2048, out_features=512, bias=True)
(decoder_att): Linear(in_features=512, out_features=512, bias=True)
(full_att): Linear(in_features=512, out_features=1, bias=True)
(relu): ReLU()
(softmax): Softmax(dim=1)
)
(embedding): Embedding(2633, 512)
(dropout): Dropout(p=0.5, inplace=False)
(decode_step): LSTMCell(2560, 512)
(init_h): Linear(in_features=2048, out_features=512, bias=True)
(init_c): Linear(in_features=2048, out_features=512, bias=True)
(f_beta): Linear(in_features=512, out_features=2048, bias=True)
(sigmoid): Sigmoid()
(fc): Linear(in_features=512, out_features=2633, bias=True)
), 'encoder_optimizer': None, 'decoder_optimizer': Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 0.0004
weight_decay: 0
)}
好家伙!
查看checkpoint的数据类型,是字典
发现打印输出encoder和decoder的时候也会报错,错误原因和上面一样,输出decoder时报错如下:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
./BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth
----***--------***--------***--------***--------***----
DecoderWithAttention(
(attention): Attention(
(encoder_att): Linear(in_features=2048, out_features=512, bias=True)
(decoder_att): Linear(in_features=512, out_features=512, bias=True)
(full_att): Linear(in_features=512, out_features=1, bias=True)
(relu): ReLU()
(softmax): Softmax(dim=1)
)
(embedding): Embedding(2633, 512)
(dropout): Dropout(p=0.5, inplace=False)
(decode_step): LSTMCell(2560, 512)
(init_h): Linear(in_features=2048, out_features=512, bias=True)
(init_c): Linear(in_features=2048, out_features=512, bias=True)
(f_beta): Linear(in_features=512, out_features=2048, bias=True)
(sigmoid): Sigmoid()
(fc): Linear(in_features=512, out_features=2633, bias=True)
)
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 231, in <module>
visualize_att(args.img, seq, alphas, rev_word_map, args.smooth)
AttributeError: 'Namespace' object has no attribute 'img'
Process finished with exit code 1
再后来打印checkpoint的时候也出现这个错误,真奇了TM的怪了
冷静下来分析:错误中出现的’Namespace’ object是个什么玩意儿,上网搜搜学习一下
哦~~~~命名空间
在看到这个帖子的时候AttributeError: namespace object has no attribute 'accumulate’看到了几乎同样的错误,而在其他中文网站就没有相类似的错误,此时我突然想到之前调试时有一些程序是被引掉了,重新引回来
if __name__ == '__main__':
defult_path = './BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth'
#大多数对 ArgumentParser 构造方法的调用都会使用 description= 关键字参数。这个参数简要描述这个程度做什么以及怎么做。
# 在帮助消息中,这个描述会显示在命令行用法字符串和各种参数的帮助消息之间。
parser = argparse.ArgumentParser(description='Show, Attend, and Tell - Tutorial - Generate Caption')
#给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。通常,这些调用指定 ArgumentParser
# 如何获取命令行字符串并将其转换为对象。这些信息在 parse_args() 调用时被存储和使用。
# 函数 add_argument() 第一个是选项, 第二个是数据类型, 第三个默认值, 第四个是help命令时的说明
parser.add_argument('--img', '-i', help='path to image')
# parser.add_argument('--model', '-m', help='path to model')
parser.add_argument('--model', '-m',default=defult_path, help='path to model')
# parser.add_argument('--model', '-m', help='path to model')
parser.add_argument('--word_map', '-wm', help='path to word map JSON')
parser.add_argument('--beam_size', '-b', default=5, type=int, help='beam size for beam search')
parser.add_argument('--dont_smooth', dest='smooth', action='store_false', help='do not smooth alpha overlay')
args = parser.parse_args()
print(args.model)
# Load model
checkpoint = torch.load(args.model, map_location=str(device))#发现就没有找不到img这个错误啦,执行上面代码但是又有了新的错误:
第一行是Checkpoint的具体内容(当然内容不止一行),下面是报的错误
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 229, in <module>
visualize_att(args.img, seq, alphas, rev_word_map, args.smooth)
NameError: name 'seq' is not defined
照这个函数visualize_att,Ctrl+F找这个函数,发现在caption.py这个文件的最后一行visualize_att(args.img, seq, alphas, rev_word_map, args.smooth)的这句话没有引掉,才导致一直出现像seq没有命名的问题。
看来以后要认真看代码呀,注意代码最后一行的注释是否忘记引掉了。
没有引掉最后一行的原因原来是一般程序员在写代码时会在最后一行不留出空余的格子,最多剩下一行空行,在使用pycharm时我是直接使用鼠标将引掉的行选中,这次忽略了最后一行的原因应该是输出框遮住了最后一行,导致我以为鼠标的箭头已经覆盖了最后一行,所以以后在调试时将最后一行后面多加一些空白行,这样查看输出结果时不至于遮挡住代码行。
继续往下调试,运行
with open(args.word_map, 'r') as j:
word_map = json.load(j)
出错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 220, in <module>
with open(args.word_map, 'r') as j:
TypeError: expected str, bytes or os.PathLike object, not NoneType
Process finished with exit code 1
发现args.word_map也在之前的代码中出现过
我尝试使用Python 在用 Pyinstaller封装exe-TypeError: expected str, bytes or os.PathLike object, not NoneType 解决方法!种方法更换了bindepend.py,一共更换了两个,发现再次运行还是报同样的错误,重启了pycharm也不行。
只能一点一点看args.word_map是个啥,打印输出发现还是None。那就好办了
应该就是没有添加word_map的默认路径,找找word_map的路径是啥
原来在eval.py文件中注明了word_map_file = '/media/ssd/caption data/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json'
找到之后该文件之后将其拷贝到和文件一起的地方

之后类似于找不到model的解决方式,设置
word_map_path = './WORDMAP_flickr8k_5_cap_per_img_5_min_word_freq.json'
parser.add_argument('--word_map', '-wm', default=word_map_path,help='path to word map JSON')
即添加了默认路径,这次运行
with open(args.word_map, 'r') as j:
word_map = json.load(j)
就没出错
运行caption.py出错:
D:\python3\envs\pytorch150\python.exe E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py
Traceback (most recent call last):
File "D:\python3\envs\pytorch150\lib\site-packages\PIL\Image.py", line 2972, in open
fp.seek(0)
AttributeError: 'NoneType' object has no attribute 'seek'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 227, in <module>
seq, alphas = caption_image_beam_search(encoder, decoder, args.img, word_map, args.beam_size)
File "E:/Show/a-PyTorch-Tutorial-to-Image-Captioning-master/caption.py", line 32, in caption_image_beam_search
img = imread(image_path)
File "C:\Users\admin\AppData\Roaming\Python\Python36\site-packages\numpy\lib\utils.py", line 100, in newfunc
return func(*args, **kwds)
File "D:\python3\envs\pytorch150\lib\site-packages\scipy\misc\pilutil.py", line 164, in imread
im = Image.open(name)
File "D:\python3\envs\pytorch150\lib\site-packages\PIL\Image.py", line 2974, in open
fp = io.BytesIO(fp.read())
AttributeError: 'NoneType' object has no attribute 'read'
Process finished with exit code 1
查看一下
seq, alphas = caption_image_beam_search(encoder, decoder, args.img, word_map, args.beam_size)
中的每一项都是什么东西
print(encoder)
print(decoder)
print(args.img)
print(word_map)
print(args.beam_size)
发现只有args.img是None
所以搞他!
添加默认测试图片路径:
img_path = './img/dog.jpg'
运行caption.pychuxian1
弹出以下界面:
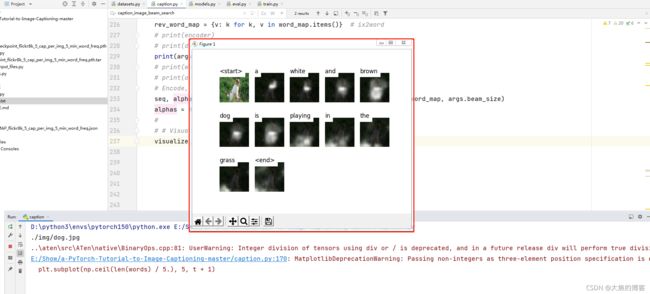
也会报错,但是兴奋的情绪让我不要去想它是为什么
图片链接:链接 用的时候我去了水印(去不去都差不多,模型能识别个物体都不错了,水印就更识别不到了)
在

看着效果还不错。
后来我又试了几张,效果奇差
原图(北工大西门2021年中秋夜,具体时间见图,哈哈哈):

效果:
<start> two people stand on a balcony <end> #两个人站在阳台上

原图:

效果:
<start> a white dog is playing with a ball <end>#一只白狗在玩儿球

说的是个啥玩意儿?那么可爱的小羊羊看不见吗,非得说狗,艹
之前有个错误是更新bindepend.py,不知道起作用了没,也有可能是不用更新就还可以。
-----------------------------以后更新代码解释--------------------------
四、 详细代码:Caption.py / train.py / utils.py / eval.py / datasets.py / create_input_files.py
下面是 Caption.py
import torch
import torch.nn.functional as F
import numpy as np
import json
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import skimage.transform
import argparse
from scipy.misc import imread, imresize
from PIL import Image
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def caption_image_beam_search(encoder, decoder, image_path, word_map, beam_size=3):
"""
Reads an image and captions it with beam search.
:param encoder: encoder model
:param decoder: decoder model
:param image_path: path to image
:param word_map: word map
:param beam_size: number of sequences to consider at each decode-step
:return: caption, weights for visualization
"""
k = beam_size
vocab_size = len(word_map)
# Read image and process
img = imread(image_path)
if len(img.shape) == 2:
img = img[:, :, np.newaxis]
img = np.concatenate([img, img, img], axis=2)
img = imresize(img, (256, 256))
img = img.transpose(2, 0, 1)
img = img / 255.
img = torch.FloatTensor(img).to(device)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform = transforms.Compose([normalize])
image = transform(img) # (3, 256, 256)
# Encode
image = image.unsqueeze(0) # (1, 3, 256, 256)
encoder_out = encoder(image) # (1, enc_image_size, enc_image_size, encoder_dim)
enc_image_size = encoder_out.size(1)
encoder_dim = encoder_out.size(3)
# Flatten encoding
encoder_out = encoder_out.view(1, -1, encoder_dim) # (1, num_pixels, encoder_dim)
num_pixels = encoder_out.size(1)
# We'll treat the problem as having a batch size of k
encoder_out = encoder_out.expand(k, num_pixels, encoder_dim) # (k, num_pixels, encoder_dim)
# Tensor to store top k previous words at each step; now they're just ' ]]] * k).to(device) # (k, 1)
# Tensor to store top k sequences; now they're just )?
incomplete_inds = [ind for ind, next_word in enumerate(next_word_inds) if
next_word != word_map['' ]]
complete_inds = list(set(range(len(next_word_inds))) - set(incomplete_inds))
# Set aside complete sequences
if len(complete_inds) > 0:
complete_seqs.extend(seqs[complete_inds].tolist())
complete_seqs_alpha.extend(seqs_alpha[complete_inds].tolist())
complete_seqs_scores.extend(top_k_scores[complete_inds])
k -= len(complete_inds) # reduce beam length accordingly
# Proceed with incomplete sequences
if k == 0:
break
seqs = seqs[incomplete_inds]
seqs_alpha = seqs_alpha[incomplete_inds]
h = h[prev_word_inds[incomplete_inds]]
c = c[prev_word_inds[incomplete_inds]]
encoder_out = encoder_out[prev_word_inds[incomplete_inds]]
top_k_scores = top_k_scores[incomplete_inds].unsqueeze(1)
k_prev_words = next_word_inds[incomplete_inds].unsqueeze(1)
# Break if things have been going on too long
if step > 50:
break
step += 1
i = complete_seqs_scores.index(max(complete_seqs_scores))
seq = complete_seqs[i]
alphas = complete_seqs_alpha[i]
return seq, alphas
def visualize_att(image_path, seq, alphas, rev_word_map, smooth=True):
"""
Visualizes caption with weights at every word.
Adapted from paper authors' repo: https://github.com/kelvinxu/arctic-captions/blob/master/alpha_visualization.ipynb
:param image_path: path to image that has been captioned
:param seq: caption
:param alphas: weights
:param rev_word_map: reverse word mapping, i.e. ix2word
:param smooth: smooth weights?
"""
image = Image.open(image_path)
image = image.resize([14 * 24, 14 * 24], Image.LANCZOS)
words = [rev_word_map[ind] for ind in seq]
for t in range(len(words)):
if t > 50:
break
plt.subplot(np.ceil(len(words) / 5.), 5, t + 1)
plt.text(0, 1, '%s' % (words[t]), color='black', backgroundcolor='white', fontsize=12)
plt.imshow(image)
current_alpha = alphas[t, :]
if smooth:
alpha = skimage.transform.pyramid_expand(current_alpha.numpy(), upscale=24, sigma=8)
else:
alpha = skimage.transform.resize(current_alpha.numpy(), [14 * 24, 14 * 24])
if t == 0:
plt.imshow(alpha, alpha=0)
else:
plt.imshow(alpha, alpha=0.8)
plt.set_cmap(cm.Greys_r)
plt.axis('off')
plt.show()
if __name__ == '__main__':
defult_path = './BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth'
word_map_path = './WORDMAP_flickr8k_5_cap_per_img_5_min_word_freq.json'
img_path = './img/dog.jpg'
img_path = './img/sheep.jpg'
# img_path = './img/schoolgate.jpg'
# img_path = './img/moon.jpg'
# img_path = './img/computer.jpg'
#大多数对 ArgumentParser 构造方法的调用都会使用 description= 关键字参数。这个参数简要描述这个程度做什么以及怎么做。
# 在帮助消息中,这个描述会显示在命令行用法字符串和各种参数的帮助消息之间。
parser = argparse.ArgumentParser(description='Show, Attend, and Tell - Tutorial - Generate Caption')
#给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。通常,这些调用指定 ArgumentParser
# 如何获取命令行字符串并将其转换为对象。这些信息在 parse_args() 调用时被存储和使用。
# 函数 add_argument() 第一个是选项, 第二个是数据类型, 第三个默认值, 第四个是help命令时的说明
parser.add_argument('--img', '-i',default = img_path, help='path to image')
# parser.add_argument('--model', '-m', help='path to model')
parser.add_argument('--model', '-m',default=defult_path, help='path to model')
# parser.add_argument('--model', '-m', help='path to model')
parser.add_argument('--word_map', '-wm', default=word_map_path,help='path to word map JSON')
parser.add_argument('--beam_size', '-b', default=5, type=int, help='beam size for beam search')
parser.add_argument('--dont_smooth', dest='smooth', action='store_false', help='do not smooth alpha overlay')
args = parser.parse_args()
# print(args.model)
# Load model
checkpoint = torch.load(args.model, map_location=str(device))#下面是train.py
import time
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torchvision.transforms as transforms
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence
from models import Encoder, DecoderWithAttention
from datasets import *
from utils import *
from nltk.translate.bleu_score import corpus_bleu
# Data parameters
# data_folder = '/media/ssd/caption data' # folder with data files saved by create_input_files.py
data_folder = '/media/ssd/caption data/Flickr8k/'
# data_name = 'coco_5_cap_per_img_5_min_word_freq' # base name shared by data files
data_name = 'flickr8k_5_cap_per_img_5_min_word_freq' # base name shared by data files
# Model parameters
emb_dim = 16 # dimension of word embeddings
attention_dim = 16 # dimension of attention linear layers
decoder_dim = 16 # dimension of decoder RNN
dropout = 0.5
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # sets device for model and PyTorch tensors
cudnn.benchmark = True # set to true only if inputs to model are fixed size; otherwise lot of computational overhead
# Training parameters
start_epoch = 0
epochs = 120 # number of epochs to train for (if early stopping is not triggered)
epochs_since_improvement = 0 # keeps track of number of epochs since there's been an improvement in validation BLEU
batch_size = 32
workers = 1 # for data-loading; right now, only 1 works with h5py
encoder_lr = 1e-4 # learning rate for encoder if fine-tuning
decoder_lr = 4e-4 # learning rate for decoder
grad_clip = 5. # clip gradients at an absolute value of
alpha_c = 1. # regularization parameter for 'doubly stochastic attention', as in the paper
best_bleu4 = 0. # BLEU-4 score right now
print_freq = 100 # print training/validation stats every __ batches
fine_tune_encoder = False # fine-tune encoder?
checkpoint = None # path to checkpoint, None if none
def main():
"""
Training and validation.
"""
global best_bleu4, epochs_since_improvement, checkpoint, start_epoch, fine_tune_encoder, data_name, word_map
# Read word map
word_map_file = os.path.join(data_folder, 'WORDMAP_' + data_name + '.json')
with open(word_map_file, 'r') as j:
word_map = json.load(j)
# Initialize / load checkpoint
if checkpoint is None:
decoder = DecoderWithAttention(attention_dim=attention_dim,
embed_dim=emb_dim,
decoder_dim=decoder_dim,
vocab_size=len(word_map),
dropout=dropout)
decoder_optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, decoder.parameters()),
lr=decoder_lr)
encoder = Encoder()
encoder.fine_tune(fine_tune_encoder)
encoder_optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, encoder.parameters()),
lr=encoder_lr) if fine_tune_encoder else None
else:
checkpoint = torch.load(checkpoint)
start_epoch = checkpoint['epoch'] + 1
epochs_since_improvement = checkpoint['epochs_since_improvement']
best_bleu4 = checkpoint['bleu-4']
decoder = checkpoint['decoder']
decoder_optimizer = checkpoint['decoder_optimizer']
encoder = checkpoint['encoder']
encoder_optimizer = checkpoint['encoder_optimizer']
if fine_tune_encoder is True and encoder_optimizer is None:
encoder.fine_tune(fine_tune_encoder)
encoder_optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, encoder.parameters()),
lr=encoder_lr)
# Move to GPU, if available
decoder = decoder.to(device)
encoder = encoder.to(device)
# Loss function
criterion = nn.CrossEntropyLoss().to(device)
# Custom dataloaders
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'TRAIN', transform=transforms.Compose([normalize])),
batch_size=batch_size, shuffle=True, pin_memory=True)
val_loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'VAL', transform=transforms.Compose([normalize])),
batch_size=batch_size, shuffle=True, pin_memory=True)
# Epochs
for epoch in range(start_epoch, epochs):
# Decay learning rate if there is no improvement for 8 consecutive epochs, and terminate training after 20
if epochs_since_improvement == 20:
break
if epochs_since_improvement > 0 and epochs_since_improvement % 8 == 0:
adjust_learning_rate(decoder_optimizer, 0.8)
if fine_tune_encoder:
adjust_learning_rate(encoder_optimizer, 0.8)
print('我已经运行到这里了')
# One epoch's training
train(train_loader=train_loader,
encoder=encoder,
decoder=decoder,
criterion=criterion,
encoder_optimizer=encoder_optimizer,
decoder_optimizer=decoder_optimizer,
epoch=epoch)
# One epoch's validation
recent_bleu4 = validate(val_loader=val_loader,
encoder=encoder,
decoder=decoder,
criterion=criterion)
# Check if there was an improvement
is_best = recent_bleu4 > best_bleu4
best_bleu4 = max(recent_bleu4, best_bleu4)
if not is_best:
epochs_since_improvement += 1
print("\nEpochs since last improvement: %d\n" % (epochs_since_improvement,))
else:
epochs_since_improvement = 0
# Save checkpoint
save_checkpoint(data_name, epoch, epochs_since_improvement, encoder, decoder, encoder_optimizer,
decoder_optimizer, recent_bleu4, is_best)
def train(train_loader, encoder, decoder, criterion, encoder_optimizer, decoder_optimizer, epoch):
"""
Performs one epoch's training.
:param train_loader: DataLoader for training data
:param encoder: encoder model
:param decoder: decoder model
:param criterion: loss layer
:param encoder_optimizer: optimizer to update encoder's weights (if fine-tuning)
:param decoder_optimizer: optimizer to update decoder's weights
:param epoch: epoch number
"""
decoder.train() # train mode (dropout and batchnorm is used)
encoder.train()
batch_time = AverageMeter() # forward prop. + back prop. time
data_time = AverageMeter() # data loading time
losses = AverageMeter() # loss (per word decoded)
top5accs = AverageMeter() # top5 accuracy
start = time.time()
# Batches
for i, (imgs, caps, caplens) in enumerate(train_loader):
data_time.update(time.time() - start)
# Move to GPU, if available
imgs = imgs.to(device)
caps = caps.to(device)
caplens = caplens.to(device)
# Forward prop.
imgs = encoder(imgs)
scores, caps_sorted, decode_lengths, alphas, sort_ind = decoder(imgs, caps, caplens)
# Since we decoded starting with , the targets are all words after , up to
targets = caps_sorted[:, 1:]
# print(targets)
# Remove timesteps that we didn't decode at, or are pads
# pack_padded_sequence is an easy trick to do this
# scores, _ = pack_padded_sequence(scores, decode_lengths, batch_first=True)
scores = pack_padded_sequence(scores, decode_lengths, batch_first=True)[0]
# print(scores)
# targets, _ = pack_padded_sequence(targets, decode_lengths, batch_first=True)
targets = pack_padded_sequence(targets, decode_lengths, batch_first=True)[0]
# Calculate loss
loss = criterion(scores, targets)
# Add doubly stochastic attention regularization
loss += alpha_c * ((1. - alphas.sum(dim=1)) ** 2).mean()
# Back prop.
decoder_optimizer.zero_grad()
if encoder_optimizer is not None:
encoder_optimizer.zero_grad()
loss.backward()
# Clip gradients
if grad_clip is not None:
clip_gradient(decoder_optimizer, grad_clip)
if encoder_optimizer is not None:
clip_gradient(encoder_optimizer, grad_clip)
# Update weights
decoder_optimizer.step()
if encoder_optimizer is not None:
encoder_optimizer.step()
# Keep track of metrics
top5 = accuracy(scores, targets, 5)
losses.update(loss.item(), sum(decode_lengths))
top5accs.update(top5, sum(decode_lengths))
batch_time.update(time.time() - start)
start = time.time()
# Print status
if i % print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Batch Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data Load Time {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Top-5 Accuracy {top5.val:.3f} ({top5.avg:.3f})'.format(epoch, i, len(train_loader),
batch_time=batch_time,
data_time=data_time, loss=losses,
top5=top5accs))
def validate(val_loader, encoder, decoder, criterion):
"""
Performs one epoch's validation.
:param val_loader: DataLoader for validation data.
:param encoder: encoder model
:param decoder: decoder model
:param criterion: loss layer
:return: BLEU-4 score
"""
decoder.eval() # eval mode (no dropout or batchnorm)
if encoder is not None:
encoder.eval()
batch_time = AverageMeter()
losses = AverageMeter()
top5accs = AverageMeter()
start = time.time()
references = list() # references (true captions) for calculating BLEU-4 score
hypotheses = list() # hypotheses (predictions)
# explicitly disable gradient calculation to avoid CUDA memory error
# solves the issue #57
with torch.no_grad():
# Batches
for i, (imgs, caps, caplens, allcaps) in enumerate(val_loader):
# Move to device, if available
imgs = imgs.to(device)
caps = caps.to(device)
caplens = caplens.to(device)
# Forward prop.
if encoder is not None:
imgs = encoder(imgs)
scores, caps_sorted, decode_lengths, alphas, sort_ind = decoder(imgs, caps, caplens)
# Since we decoded starting with , the targets are all words after , up to
targets = caps_sorted[:, 1:]
# Remove timesteps that we didn't decode at, or are pads
# pack_padded_sequence is an easy trick to do this
scores_copy = scores.clone()
scores, _ = pack_padded_sequence(scores, decode_lengths, batch_first=True)
targets, _ = pack_padded_sequence(targets, decode_lengths, batch_first=True)
# Calculate loss
loss = criterion(scores, targets)
# Add doubly stochastic attention regularization
loss += alpha_c * ((1. - alphas.sum(dim=1)) ** 2).mean()
# Keep track of metrics
losses.update(loss.item(), sum(decode_lengths))
top5 = accuracy(scores, targets, 5)
top5accs.update(top5, sum(decode_lengths))
batch_time.update(time.time() - start)
start = time.time()
if i % print_freq == 0:
print('Validation: [{0}/{1}]\t'
'Batch Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Top-5 Accuracy {top5.val:.3f} ({top5.avg:.3f})\t'.format(i, len(val_loader), batch_time=batch_time,
loss=losses, top5=top5accs))
# Store references (true captions), and hypothesis (prediction) for each image
# If for n images, we have n hypotheses, and references a, b, c... for each image, we need -
# references = [[ref1a, ref1b, ref1c], [ref2a, ref2b], ...], hypotheses = [hyp1, hyp2, ...]
# References
allcaps = allcaps[sort_ind] # because images were sorted in the decoder
for j in range(allcaps.shape[0]):
img_caps = allcaps[j].tolist()
img_captions = list(
map(lambda c: [w for w in c if w not in {word_map['' ], word_map['' ]}],
img_caps)) # remove and pads
references.append(img_captions)
# Hypotheses
_, preds = torch.max(scores_copy, dim=2)
preds = preds.tolist()
temp_preds = list()
for j, p in enumerate(preds):
temp_preds.append(preds[j][:decode_lengths[j]]) # remove pads
preds = temp_preds
hypotheses.extend(preds)
assert len(references) == len(hypotheses)
# Calculate BLEU-4 scores
bleu4 = corpus_bleu(references, hypotheses)
print(
'\n * LOSS - {loss.avg:.3f}, TOP-5 ACCURACY - {top5.avg:.3f}, BLEU-4 - {bleu}\n'.format(
loss=losses,
top5=top5accs,
bleu=bleu4))
return bleu4
if __name__ == '__main__':
main()
下面是utils.py
import os
import numpy as np
import h5py
import json
import torch
# from scipy.misc import imread, imresize
from imageio import imread
from scipy.misc import imresize
from tqdm import tqdm
from collections import Counter
from random import seed, choice, sample
def create_input_files(dataset, karpathy_json_path, image_folder, captions_per_image, min_word_freq, output_folder,
max_len=100):
"""
Creates input files for training, validation, and test data.
:param dataset: name of dataset, one of 'coco', 'flickr8k', 'flickr30k'
:param karpathy_json_path: path of Karpathy JSON file with splits and captions
:param image_folder: folder with downloaded images
:param captions_per_image: number of captions to sample per image
:param min_word_freq: words occuring less frequently than this threshold are binned as s
:param output_folder: folder to save files
:param max_len: don't sample captions longer than this length
"""
assert dataset in {'coco', 'flickr8k', 'flickr30k'}
# Read Karpathy JSON
with open(karpathy_json_path, 'r') as j:
data = json.load(j)
# print(data)
# Read image paths and captions for each image
train_image_paths = []
train_image_captions = []
val_image_paths = []
val_image_captions = []
test_image_paths = []
test_image_captions = []
word_freq = Counter()
for img in data['images']:
captions = []
for c in img['sentences']:
# Update word frequency
word_freq.update(c['tokens'])
if len(c['tokens']) <= max_len:
captions.append(c['tokens'])
if len(captions) == 0:
continue
path = os.path.join(image_folder, img['filepath'], img['filename']) if dataset == 'coco' else os.path.join(
image_folder, img['filename'])
if img['split'] in {'train', 'restval'}:
train_image_paths.append(path)
train_image_captions.append(captions)
elif img['split'] in {'val'}:
val_image_paths.append(path)
val_image_captions.append(captions)
elif img['split'] in {'test'}:
test_image_paths.append(path)
test_image_captions.append(captions)
# Sanity check
assert len(train_image_paths) == len(train_image_captions)
assert len(val_image_paths) == len(val_image_captions)
assert len(test_image_paths) == len(test_image_captions)
# Create word map
words = [w for w in word_freq.keys() if word_freq[w] > min_word_freq]
word_map = {k: v + 1 for v, k in enumerate(words)}
word_map['' ] = len(word_map) + 1
word_map['' ] = len(word_map) + 1
word_map['' ] = len(word_map) + 1
word_map['' ] = 0
# Create a base/root name for all output files
base_filename = dataset + '_' + str(captions_per_image) + '_cap_per_img_' + str(min_word_freq) + '_min_word_freq'
# Save word map to a JSON
with open(os.path.join(output_folder, 'WORDMAP_' + base_filename + '.json'), 'w') as j:
json.dump(word_map, j)
# Sample captions for each image, save images to HDF5 file, and captions and their lengths to JSON files
seed(123)
for impaths, imcaps, split in [(train_image_paths, train_image_captions, 'TRAIN'),
(val_image_paths, val_image_captions, 'VAL'),
(test_image_paths, test_image_captions, 'TEST')]:
with h5py.File(os.path.join(output_folder, split + '_IMAGES_' + base_filename + '.hdf5'), 'a') as h:
# Make a note of the number of captions we are sampling per image
h.attrs['captions_per_image'] = captions_per_image
# Create dataset inside HDF5 file to store images
images = h.create_dataset('images', (len(impaths), 3, 256, 256), dtype='uint8')
print("\nReading %s images and captions, storing to file...\n" % split)
enc_captions = []
caplens = []
for i, path in enumerate(tqdm(impaths)):
# Sample captions
if len(imcaps[i]) < captions_per_image:
captions = imcaps[i] + [choice(imcaps[i]) for _ in range(captions_per_image - len(imcaps[i]))]
else:
captions = sample(imcaps[i], k=captions_per_image)
# Sanity check
assert len(captions) == captions_per_image
# Read images
img = imread(impaths[i])
if len(img.shape) == 2:
img = img[:, :, np.newaxis]
img = np.concatenate([img, img, img], axis=2)
img = imresize(img, (256, 256))
img = img.transpose(2, 0, 1)
assert img.shape == (3, 256, 256)
assert np.max(img) <= 255
# Save image to HDF5 file
images[i] = img
for j, c in enumerate(captions):
# Encode captions
enc_c = [word_map['' ]] + [word_map.get(word, word_map['' ]) for word in c] + [
word_map['' ]] + [word_map['' ]] * (max_len - len(c))
# Find caption lengths
c_len = len(c) + 2
enc_captions.append(enc_c)
caplens.append(c_len)
# Sanity check
assert images.shape[0] * captions_per_image == len(enc_captions) == len(caplens)
# Save encoded captions and their lengths to JSON files
with open(os.path.join(output_folder, split + '_CAPTIONS_' + base_filename + '.json'), 'w') as j:
json.dump(enc_captions, j)
with open(os.path.join(output_folder, split + '_CAPLENS_' + base_filename + '.json'), 'w') as j:
json.dump(caplens, j)
def init_embedding(embeddings):
"""
Fills embedding tensor with values from the uniform distribution.
:param embeddings: embedding tensor
"""
bias = np.sqrt(3.0 / embeddings.size(1))
torch.nn.init.uniform_(embeddings, -bias, bias)
def load_embeddings(emb_file, word_map):
"""
Creates an embedding tensor for the specified word map, for loading into the model.
:param emb_file: file containing embeddings (stored in GloVe format)
:param word_map: word map
:return: embeddings in the same order as the words in the word map, dimension of embeddings
"""
# Find embedding dimension
with open(emb_file, 'r') as f:
emb_dim = len(f.readline().split(' ')) - 1
vocab = set(word_map.keys())
# Create tensor to hold embeddings, initialize
embeddings = torch.FloatTensor(len(vocab), emb_dim)
init_embedding(embeddings)
# Read embedding file
print("\nLoading embeddings...")
for line in open(emb_file, 'r'):
line = line.split(' ')
emb_word = line[0]
embedding = list(map(lambda t: float(t), filter(lambda n: n and not n.isspace(), line[1:])))
# Ignore word if not in train_vocab
if emb_word not in vocab:
continue
embeddings[word_map[emb_word]] = torch.FloatTensor(embedding)
return embeddings, emb_dim
def clip_gradient(optimizer, grad_clip):
"""
Clips gradients computed during backpropagation to avoid explosion of gradients.
:param optimizer: optimizer with the gradients to be clipped
:param grad_clip: clip value
"""
for group in optimizer.param_groups:
for param in group['params']:
if param.grad is not None:
param.grad.data.clamp_(-grad_clip, grad_clip)
def save_checkpoint(data_name, epoch, epochs_since_improvement, encoder, decoder, encoder_optimizer, decoder_optimizer,
bleu4, is_best):
"""
Saves model checkpoint.
:param data_name: base name of processed dataset
:param epoch: epoch number
:param epochs_since_improvement: number of epochs since last improvement in BLEU-4 score
:param encoder: encoder model
:param decoder: decoder model
:param encoder_optimizer: optimizer to update encoder's weights, if fine-tuning
:param decoder_optimizer: optimizer to update decoder's weights
:param bleu4: validation BLEU-4 score for this epoch
:param is_best: is this checkpoint the best so far?
"""
state = {'epoch': epoch,
'epochs_since_improvement': epochs_since_improvement,
'bleu-4': bleu4,
'encoder': encoder,
'decoder': decoder,
'encoder_optimizer': encoder_optimizer,
'decoder_optimizer': decoder_optimizer}
filename = 'checkpoint_' + data_name + '.pth.tar'
torch.save(state, filename)
# If this checkpoint is the best so far, store a copy so it doesn't get overwritten by a worse checkpoint
if is_best:
torch.save(state, 'BEST_' + filename)
class AverageMeter(object):
"""
Keeps track of most recent, average, sum, and count of a metric.
"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def adjust_learning_rate(optimizer, shrink_factor):
"""
Shrinks learning rate by a specified factor.
:param optimizer: optimizer whose learning rate must be shrunk.
:param shrink_factor: factor in interval (0, 1) to multiply learning rate with.
"""
print("\nDECAYING learning rate.")
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * shrink_factor
print("The new learning rate is %f\n" % (optimizer.param_groups[0]['lr'],))
def accuracy(scores, targets, k):
"""
Computes top-k accuracy, from predicted and true labels.
:param scores: scores from the model
:param targets: true labels
:param k: k in top-k accuracy
:return: top-k accuracy
"""
batch_size = targets.size(0)
_, ind = scores.topk(k, 1, True, True)
correct = ind.eq(targets.view(-1, 1).expand_as(ind))
correct_total = correct.view(-1).float().sum() # 0D tensor
return correct_total.item() * (100.0 / batch_size)
下面是eval.py
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torchvision.transforms as transforms
from datasets import *
from utils import *
from nltk.translate.bleu_score import corpus_bleu
import torch.nn.functional as F
from tqdm import tqdm
# Parameters
data_folder = '/media/ssd/caption data' # folder with data files saved by create_input_files.py
data_name = 'coco_5_cap_per_img_5_min_word_freq' # base name shared by data files
checkpoint = '../BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar' # model checkpoint
word_map_file = '/media/ssd/caption data/WORDMAP_coco_5_cap_per_img_5_min_word_freq.json'
# word map, ensure it's the same the data was encoded with and the model was trained with
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # sets device for model and PyTorch tensors
cudnn.benchmark = True # set to true only if inputs to model are fixed size; otherwise lot of computational overhead
# Load model
checkpoint = torch.load(checkpoint)
decoder = checkpoint['decoder']
decoder = decoder.to(device)
decoder.eval()
encoder = checkpoint['encoder']
encoder = encoder.to(device)
encoder.eval()
# Load word map (word2ix)
with open(word_map_file, 'r') as j:
word_map = json.load(j)
rev_word_map = {v: k for k, v in word_map.items()}
vocab_size = len(word_map)
# Normalization transform
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
def evaluate(beam_size):
"""
Evaluation
:param beam_size: beam size at which to generate captions for evaluation
:return: BLEU-4 score
"""
# DataLoader
loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'TEST', transform=transforms.Compose([normalize])),
batch_size=1, shuffle=True, num_workers=1, pin_memory=True)
# TODO: Batched Beam Search
# Therefore, do not use a batch_size greater than 1 - IMPORTANT!
# Lists to store references (true captions), and hypothesis (prediction) for each image
# If for n images, we have n hypotheses, and references a, b, c... for each image, we need -
# references = [[ref1a, ref1b, ref1c], [ref2a, ref2b], ...], hypotheses = [hyp1, hyp2, ...]
references = list()
hypotheses = list()
# For each image
for i, (image, caps, caplens, allcaps) in enumerate(
tqdm(loader, desc="EVALUATING AT BEAM SIZE " + str(beam_size))):
k = beam_size
# Move to GPU device, if available
image = image.to(device) # (1, 3, 256, 256)
# Encode
encoder_out = encoder(image) # (1, enc_image_size, enc_image_size, encoder_dim)
enc_image_size = encoder_out.size(1)
encoder_dim = encoder_out.size(3)
# Flatten encoding
encoder_out = encoder_out.view(1, -1, encoder_dim) # (1, num_pixels, encoder_dim)
num_pixels = encoder_out.size(1)
# We'll treat the problem as having a batch size of k
encoder_out = encoder_out.expand(k, num_pixels, encoder_dim) # (k, num_pixels, encoder_dim)
# Tensor to store top k previous words at each step; now they're just ' ]]] * k).to(device) # (k, 1)
# Tensor to store top k sequences; now they're just )?
incomplete_inds = [ind for ind, next_word in enumerate(next_word_inds) if
next_word != word_map['' ]]
complete_inds = list(set(range(len(next_word_inds))) - set(incomplete_inds))
# Set aside complete sequences
if len(complete_inds) > 0:
complete_seqs.extend(seqs[complete_inds].tolist())
complete_seqs_scores.extend(top_k_scores[complete_inds])
k -= len(complete_inds) # reduce beam length accordingly
# Proceed with incomplete sequences
if k == 0:
break
seqs = seqs[incomplete_inds]
h = h[prev_word_inds[incomplete_inds]]
c = c[prev_word_inds[incomplete_inds]]
encoder_out = encoder_out[prev_word_inds[incomplete_inds]]
top_k_scores = top_k_scores[incomplete_inds].unsqueeze(1)
k_prev_words = next_word_inds[incomplete_inds].unsqueeze(1)
# Break if things have been going on too long
if step > 50:
break
step += 1
i = complete_seqs_scores.index(max(complete_seqs_scores))
seq = complete_seqs[i]
# References
img_caps = allcaps[0].tolist()
img_captions = list(
map(lambda c: [w for w in c if w not in {word_map['' ], word_map['' ], word_map['' ]}],
img_caps)) # remove and pads
references.append(img_captions)
# Hypotheses
hypotheses.append([w for w in seq if w not in {word_map['' ], word_map['' ], word_map['' ]}])
assert len(references) == len(hypotheses)
# Calculate BLEU-4 scores
bleu4 = corpus_bleu(references, hypotheses)
return bleu4
if __name__ == '__main__':
beam_size = 1
print("\nBLEU-4 score @ beam size of %d is %.4f." % (beam_size, evaluate(beam_size)))
下面是datasets.py
import torch
from torch.utils.data import Dataset
import h5py
import json
import os
class CaptionDataset(Dataset):
"""
A PyTorch Dataset class to be used in a PyTorch DataLoader to create batches.
"""
def __init__(self, data_folder, data_name, split, transform=None):
"""
:param data_folder: folder where data files are stored
:param data_name: base name of processed datasets
:param split: split, one of 'TRAIN', 'VAL', or 'TEST'
:param transform: image transform pipeline
"""
self.split = split
assert self.split in {'TRAIN', 'VAL', 'TEST'}
# Open hdf5 file where images are stored
self.h = h5py.File(os.path.join(data_folder, self.split + '_IMAGES_' + data_name + '.hdf5'), 'r')
self.imgs = self.h['images']
# Captions per image
self.cpi = self.h.attrs['captions_per_image']
# Load encoded captions (completely into memory)
with open(os.path.join(data_folder, self.split + '_CAPTIONS_' + data_name + '.json'), 'r') as j:
self.captions = json.load(j)
# Load caption lengths (completely into memory)
with open(os.path.join(data_folder, self.split + '_CAPLENS_' + data_name + '.json'), 'r') as j:
self.caplens = json.load(j)
# PyTorch transformation pipeline for the image (normalizing, etc.)
self.transform = transform
# Total number of datapoints
self.dataset_size = len(self.captions)
def __getitem__(self, i):
# Remember, the Nth caption corresponds to the (N // captions_per_image)th image
img = torch.FloatTensor(self.imgs[i // self.cpi] / 255.)
if self.transform is not None:
img = self.transform(img)
caption = torch.LongTensor(self.captions[i])
caplen = torch.LongTensor([self.caplens[i]])
if self.split is 'TRAIN':
return img, caption, caplen
else:
# For validation of testing, also return all 'captions_per_image' captions to find BLEU-4 score
all_captions = torch.LongTensor(
self.captions[((i // self.cpi) * self.cpi):(((i // self.cpi) * self.cpi) + self.cpi)])
return img, caption, caplen, all_captions
def __len__(self):
return self.dataset_size
下面是create_input_files.py
from utils import create_input_files
if __name__ == '__main__':
# Create input files (along with word map)
# create_input_files(dataset='coco',
# karpathy_json_path='../caption data/dataset_coco.json',
# image_folder='/media/ssd/caption data/',
# captions_per_image=5,
# min_word_freq=5,
# output_folder='/media/ssd/caption data/',
# max_len=50)
# create_input_files(dataset='flickr8k',
# karpathy_json_path='../caption data/dataset_flickr8k.json',
# image_folder='/media/ssd/caption data/Flicker8k_Dataset',
# captions_per_image=5,
# min_word_freq=5,
# output_folder='/media/ssd/caption data/Flicker8k_Dataset',
# max_len=50)
create_input_files(dataset='flickr8k',
karpathy_json_path='../caption data/dataset_flickr8k.json',
image_folder='/media/ssd/caption data/Flickr8k/Flicker8k_Dataset/',
captions_per_image=5,
min_word_freq=5,
output_folder='/media/ssd/caption data/Flickr8k/',
max_len=50)
# create_input_files(dataset='coco',
# karpathy_json_path='../caption data/dataset_coco.json',
# image_folder='/media/ssd/caption data/',
# captions_per_image=5,
# min_word_freq=5,
# output_folder='/media/ssd/caption data/',
# max_len=50)