RabbitMQ总结
目录
1. 简述
2. 角色定义
3. 可靠性
4. 运维
5. AMQP0.9.1简介
6. 丰富的语言支持
7. 持久化
8. 使用
Q&A
1. 简述
RabbitMQ,被广发使用的开源的消息中间件。
2. 角色定义
2.1. 在使用rabbitmq过程中,涉及5种角色。
- producer
- consumer
- exchange
- binding
- queue
2.2. producer
producer,发送消息的用户应用。
可执行声明exchange,发布消息等操作。发布消息调用channel.basicPublish(),提供exchangeName,routingKey,消息内容等。
2.3. consumer
consumer,接受消息的用户应用。
可执行声明exchange和queue、定义binding、订阅队列等操作。
2.4. exchange
RabbitMQ消息模型的一个核心思想:生产者不可能将消息直接放入队列。
exchange位于producer和queue之间,一边接收producer发送的消息,一边将消息推给queue。由exchange type控制处理消息的规则。
exchange type主要种类如下:
- direct
- topic
- fanout
direct类型
为消费者提供了对消息的选择性接收的能力。通过binding key 绝对匹配 消息的routing key,确定消息发送到哪些queue。未匹配到binding key的消息被丢弃。

topic类型
为消费者提供了对消息的更灵活的选择性接收的能力。可以更灵活的建立消息到queue的关系。
发布者发布消息时提供的routing-key由多个用.连接的单词构成,可任意单词,但通常具有含义。
消费者定义绑定时提供的bindingkey通过通配符匹配routingkey,决定消息发到哪些queue。未匹配的消息被丢弃。
通配符说明:*代表一个单词,#代表多个单词。

fanout类型
收到的消息广播给所有queue。一个消息被放到多个队列,从而交付给多个消费者。
2.5. binding
由消费者定义,位于exchange和queue之间,通过binding key(routing_key)标识queue对exchange中哪些消息感兴趣。下图可以清晰的体现binding的位置。
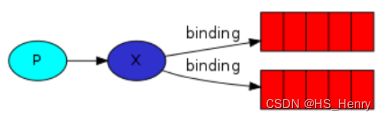
routing_key的具体含义是与exchange-type直接相关的,fanout-type时routing_key无意义。
指令
- 建立queue和exchange之间的绑定 channel.queueBind(queueName, "logs", "");
- rabbitmqctl list_bindings
2.6. queue
存储消息的FIFO队列。使用exchange时,由消费者定义queue和binding。
可不使用exchange,直接作为工作队列,每个消息只交付给一个消费者。生产者将消息直接放于队列,broker采用轮询robin方式,将消息分发给消费者。

声明queue时,可配置的属性:
| name | |
| 是否持久化 | |
| 是否排他性 | 仅供某个连接使用,当这个连接断开后该队列自动删除。 |
| 是否自动删除 | 没有消费者订阅这个队列时,队列自动删除 |
| 参数 | 如消息存活时长TTL、队列长度等 |
2.7 routingKey和bindingKey
建立queue和exchange间关系时提供bindingKey,发送消息时提供routingKey,当routingKey与bindingKey匹配时,消息进入queue。无论vhost,每个queue都默认与default exchange建立bind关系。
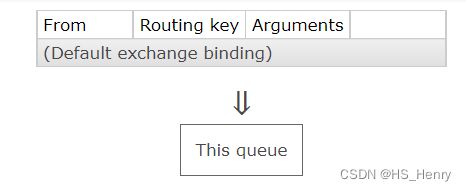
当queue和exchange之间不指定bindingKey时,bingdingKey默认为队列取名。此种情况,发送消息时routingKey设置为queue的完整名即可。
3. 可靠性
3.1. ack回告和确认
当连接失败时,处于传输过程中的msg需要重新传递,此时需要ack确定何时进行重传。
支持两个方向的回告
- consumer向server,告知已经收到或处理消息
- server告知producer,告知已经收到消息
TCP保证网络层的可靠性,ack和确认则保证应用层的可靠性,表示两层含义:接受者已经收到消息,接下来由接受者负责处理消息。
流程简述
- 消费者收到消息且处理(入库\转发等)
- 向broker发送ack
- broker收到ack
- broker释放消息
ack提供至少一次的交付保证,无ack(消息可能丢失)则提供至多一次的交付。
3.2. 心跳发现中断的TCP连接
AMQP 0-9-1协议要求提供心跳机制,确保应用层能及时发现中断的TCP连接。
3.3. borker
持久化支持:避免broker丢失消息,需要将'持久性exchange\queue\msg'持久到磁盘,以便在处理broker重启\硬件问题\宕机后恢复。
集群与高可用:RabbitMQ的所有定义(exchange\binging\user等)将在集群所有节点中进行镜像。
对queue,默认仅存在单独节点,可配置为多个节点。
3.4. consumer
consumer应进行幂等处理而不是简单的排重。
broker会对重复消息设置redelivered标签,consumer也可依据该标签。
当订阅的queue被删除后,consumer可收到cancel通知,以进行处理。
consumer可以拒绝收到的消息,使用basic.reject。
3.5. producer
producer从'网络问题'恢复时,需要对'未收到broker ack的消息'进行再传递。
在broker已发ack但producer未收到情况下,进行再次传递后,会造成消息重复,因此需要consumer进行排重或幂等处理。
4. 运维
| docker 镜像 | rabbitmq https://registry.hub.docker.com/_/rabbitmq/ https://registry.hub.docker.com/_/rabbitmq/ |
| management plugin | 提供针对RabbitMQ nodes and clusters的管理和监控的能力。 |
| 启动容器 | docker run -d --hostname my-rabbit --name some-rabbit -p 5672:5672 -p 8080:15672 -e RABBITMQ_DEFAULT_USER=guest -e RABBITMQ_DEFAULT_PASS=guestp rabbitmq:3-management |
| maven |
5. AMQP0.9.1简介
5.1. what
AMQP 即 Advanced Message Queuing Protocol 高级消息队列协议。AMQP0.9.1是一种消息协议,使得客户端与消息中间件broker可以进行交互。
5.2. message broker
message broker有两个职责,接收由生产者发布的消息,将消息路由给消费者。
5.3. AMQP0.9.1模型概述
模型图示

模型概述
- 消息被发布到exchange
- 依据分发规则binding,exchange将消息的拷贝分分发给queue
- broker将queue中的消息交付给订阅该queue的消费者(push),或者消费者从queue进行预先拉取(fetch/pull)
消息确认概念
面对网络问题或消费者处理问题,AMQP0.9.1采取了消息确认概念。当消息交付给消费者后,消费者需告知broker,可以是自动的,也可以是由消费者执行。当broker收到来自消费者的交付确认后,borker将删除对应queue的相应消息。
5.4. exchange和exchangeType
5.4.1. exchange简介
exchange负责接收消息和路由给0或多个队列。路由算法与exchangeType和binding规则有关。
声明时属性
- Name
- Durability 是否持久化
- Auto-delete 无绑定queue时是否自动删除
- Arguments 与插件或特性相关的参数
5.4.2. Direct exchange
默认类型,routing_key与binding_key进行精准匹配,将消息拷贝路由到匹配的queue。
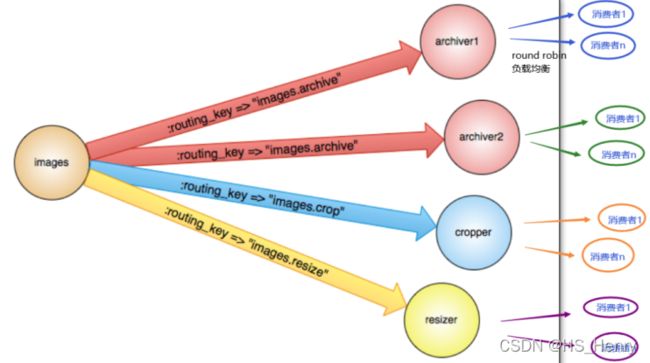
场景举例
- 多worker的分布式task,在消费者之间进行循环robin。
5.4.3. Fanout exchange
忽略routing_key,而是进行广播,即将消息拷贝路由到该exchange连接的所有queue。

场景举例
- 大规模多人在线(MMO)的游戏,通知所有用户某些信息,如选手积分榜更新、其他全局性事件
- 体育新闻网站,实时告知用户比赛分数变化
- 分布式系统,广播变量状态和配置更新
5.4.4. Topic exchange
消息routing_key与binding_key进行通配符匹配,适用于发布订阅模式,消息的多播路由,消费者考虑选择哪些类型的消息。
场景举例
- 与地理位置相关的分布式数据,例如销售地点
- 多worker参与的后台任务处理,要求每批worker负责特定的任务集
- 股票价格更新、其他金融数据更新
- 与类别或标签相关的新闻更新,例如特定的体育项目或团队
5.5.5. Headers exchange
忽略消息routing_key,而是基于消息headers中属性匹配binding数据进行路由。
5.5. queue
存储消息,供用户消费。
5.6. binding
exchange依据binding规则,决定将消息路由到哪些queue。
5.7. consumer
消费消息的方式
- push API,通过订阅方式进行交付,推荐行为
- pull API,大多数情况下低效,不推荐使用
5.8. 消息ack
消息ack用于解决broker何时删除queue中消息的问题。
两种ack方式
- 自动ack模式,broker向消费者发送消息之后
- channel.basicConsume#autoAck参数传递true
- 明确ack模式,消费者决定发送ack的时机
- channel.basicAck
5.9. 拒绝消息
消费者收到消息后,无论处理结果如何,都可以拒绝消息,并可以选择是否requeue。
5.10. 预先获取 prefetch
broker每次向消费者channel推送最多多少条未确认消息,若channel中未确认消息数量已达标,则broker停止向该channel推送消息,直到channel中所有消息均确认。0代表无限制。
broker交付消息,消费者确认消息,这些过程都是异步的。无限制的prefetch,可能导致消费者内存堆积,所以应当适当配置prefetch和手动确认。
broker简单的负载均衡,提升prefetch可以提升吞吐量。
配置方式
消费者配置prefetch
channel.basicQos(50);
broker配置
%% advanced.config file
[
{rabbit, [
{default_consumer_prefetch, {false,250}}
]
}
].5.11. connection
应用级别的TCP连接,当应用不需要连接时,需要进行关闭。
5.12. channel
建立在同一个TCP连接之上的轻量级连接,在一个connection基础上,可以创建多个channel。connection关闭,则关联的所有channel关闭。
多线程情况下,一个线程对应一个channel,不可以共享channel。
5.13. virtual hosts
多租用系统,使用vhost对实体进行分组,即对connection、exchange、queue、binding、user permission等进行分组。rabbitMQ使用命令行或httpAPI创建vhost。
vhost具有一个名称,默认为"/"。
逻辑隔离还是物理隔离?
virtual host提供了逻辑分组和资源的逻辑隔离。
例如资源权限是与virtual host关联的,一个用户无法具有全局权限,而只能具有一个或多个virtual host的权限。所以谈及资源权限时,必须明确virtual host。
vhost与connection的关系
当AMQP0.9.1客户端连接rabbitmq broker时,需要提供vhost名称,只有用户被授权了,才可以连接成功。连接成功后,只能操作该vhost分组内的实体。
管理vhost的方式
cli方式
新建vhost
rabbitmqctl add_vhost vhostName
删除vhost
rabbitmqctl delete_vhost qa1
设置vhost的连接数 0即不接受连接,-1无限制。
rabbitmqctl set_vhost_limits -p vhost_name '{"max-connections": 256}'
设置vhost队列数量,-1无限制。
rabbitmqctl set_vhost_limits -p vhost_name '{"max-queues": 1024}' httpAPI
curl -u userename:pa$sw0rD -X PUT http://rabbitmq.local:15672/api/vhosts/vh1
curl -u userename:pa$sw0rD -X DELETE http://rabbitmq.local:15672/api/vhosts/vh15.14. 访问控制
涉及用户、权限、授权的管理。
用户相关的管理
新建用户
rabbitmqctl add_user 'username' '2a55f70a841f18b97c3a7db939b7adc9e34a0f1b'
删除用户
rabbitmqctl delete_user 'username'
列举用户
rabbitmqctl list_users
排查用户登录信息
rabbitmqctl authenticate_user username password授权相关的管理
授权
rabbitmqctl set_permissions -p "vhostName" "username" "配置权限" "写权限" "读权限"
清除授权
rabbitmqctl clear_permissions -p "custom-vhost" "username"
列举授权
rabbitmqctl list_permissions --vhost vhostName 如/5.15. 内存空间
这个部分可以回答:内存都存储了什么信息 ?
connection
connection和channel会占用内存,主要由tcp buffer使用,分为发送buffer和接收buffer。默认由系统在80至128kb间自动调节。例如100kb,估算1w个连接就占用2g内存。调大buffer,可以提升吞吐量。减小buffer,则降低吞吐量。所以在每个连接内存占用量和吞吐量之间需要找个合理值。发送buffer和接收buffer大小必须一致,且不能低于8kb。
# rabbitmq配置文件,改为32kb
tcp_listen_options.sndbuf = 32768
tcp_listen_options.recbuf = 32768
# 设置每个连接的channel数量上限
channel_max = 16queue和message
queue、queue索引、queue状态都会占用内存。
message store索引
消息存储,使用所有消息的内存级索引。
插件占用
预先分配的内存
内部数据库
内部数据库表会在内存中维持一份全表备份
management数据库
使用management插件时的数据库,状态数据cache在内存。
二进制数据
运行时被分享的二进制数据,内存大部分存储消息的body和元数据。
5.16. 网络
如何提升吞吐量?
- 增加tcp buffer
- 关闭Nagle's algorithm
- 开启tcp特性
面对大量连接,如何调整?
- 系统文件标识符上限
- 每个连接的内存占用量
- 每个连接的cpu占用量
- 占线进程队列上限
减少指标收集周期频率
周期性收集每个连接的指标数据,通过增大周期间隔,可以减少内存使用。
# 默认5秒,修改为间隔60秒
collect_statistics_interval = 60000减少每个连接的channel上限
当使用以rabbitmq为基础的某些包时,需要调研每个连接需要的channel数量。
# 设置每个连接的channel上限为16
channel_max = 16关闭Nagle's algorithm
可降低延迟、增加吞吐量
配置
rabbitmq.conf
tcp_listen_options.backlog = 4096
tcp_listen_options.nodelay = true
advanced.config
rabbitmq启动时,该配置文件内容会与rabbitmq.conf内容进行合并。
[
{kernel, [
{inet_default_connect_options, [{nodelay, true}]},
{inet_default_listen_options, [{nodelay, true}]}
]}].占线IO线程池调整
对于没有接收到客户端确认的连接请求,被记录于backlog队列。队列默认长度128,最大65535。调整吞吐量时,推荐4096和8192作为开始值。记录小时维度的连接峰值和尖刺。
# rabbitmq配置文件
tcp_listen_options.backlog = 4096
tcp_listen_options.nodelay = true如何处理高频的连接创建与关闭?
高频率的连接创建与关闭,可能导致broker特定资源枯竭,例如文件控制器达到上限、port区间,从而导致broker无法接收新的连接,降低系统可用性。
处理方式
- 心跳配置
- 减小TCP TIME_WAIT
- 关闭的连接会保持TIME_WAIT状态一段时间,然后才会被清理,这会导致连接积累。所以缩短这个时间,可以避免资源占用。
#
net.ipv4.tcp_fin_timeout = 30
# 需配置toc keepalive判断失联,30s空闲后,每隔10s一次,尝试4次,期间无回复,即70s失联。
net.ipv4.tcp_keepalive_time=30
net.ipv4.tcp_keepalive_intvl=10
net.ipv4.tcp_keepalive_probes=4系统层面调整
与网络、tcp相关的一些配置
linux使用指令sysctl -w;
永久生效,需配置/etc/sysctl.conf
fs.file-max 内核允许创建文件标识符数量的上限
net.ipv4.ip_local_port_range port区间,需要考虑并发连接的峰值
net.ipv4.tcp_tw_reuse 1开启 0关闭,重用即将关闭连接,当连接节点使用NAT时很危险。
net.ipv4.tcp_fin_timeout 15-30s之间,关闭的连接保留时长
net.core.somaxconn 同时处于正在建立连接过程的连接数量,默认128.可以调整到4096或更高,以支持新建连接请求暴增的情况。
net.ipv4.tcp_max_syn_backlog 对于没有接收到客户端确认的连接请求,被记录于backlog队列。
net.ipv4.tcp_keepalive_time
net.ipv4.tcp_keepalive_intvl
net.ipv4.tcp_keepalive_probestcp socket配置
rabbitmq配置文件
tcp_listen_options.nodelay 默认true,推荐配置。
tcp_listen_options.sndbuf 默认由系统自动调解,区间88kb至128kb。增加大小可以提升消费者吞吐量,增加每个连接的内存占用量。
tcp_listen_options.recbuf 默认由系统自动调解,区间88kb至128kb。手动配置的话,要保持sndbuf和recbuf一致。但是它时针对发布者和协议操作,即增加大小可以提升broker接收消息的吞吐量。
tcp_listen_options.backlog 未被接纳的tcp连接队列的最大长度,当queue满时,拒绝新连接。面对上万并发新连接和大量客户端重连的情况,可以设置4096或更高。
tcp_listen_options.keepalive 设置为true,则开启tcp keepalive。6. 丰富的语言支持
- java
- .net
- ruby
- python
- php
- js node.js
- go
- ios android
- Objective-C and Swift
- c c++
- ...
7. 持久化
rabbitmq的持久层,致力于在大多数情况下提供合理的好的吞吐量。可以对节点的吞吐量、延迟和IO进行配置。 持久层具有两个组件,分别为queue index队列索引和msg store消息存储。
持久化和临时消息都可以被存储到磁盘。
- 当消息到达queue时,持久化消息存到磁盘,持久化消息也尽可能放在磁盘,为了读写效率;
- 内存紧张且消息被驱逐时,临时化消息存到磁盘。
queue index队列索引
索引用于定位消息以及是否交付和ack。每个queue对应一个索引。
意图在于将非常小的消息放到队列索引,其他的消息都存储到message store。默认情况,消息序列化(包括属性和header信息)size小于4096字节时,会放入到队列索引。每个队列索引至少将一个segment文件保留在内存中,而一个segment文件包含16384个消息。所以即使配置项queue_index_embed_msgs_below有少量的增加,也会导致内存的大量占用。
| 优点 | 一个操作即可写入磁盘 |
| 写入到队列索引的消息,不需要再次写入message store。 | |
| 缺点 | 每个消息索引在内存中保留一定数量的消息记录,可能占用大量内存。 |
| 若消息通过exchange被路由到多个队列,则消息被写入到多个队列索引中,也就多占用了内存和磁盘空间。若消息写入到消息存储,则只需写入一次。 | |
| 存储在队列索引的未确认消息,将一直保留在内存中 |
msg store消息存储
存储是以k-v方式存储消息,且该server中所有queue共享一个存储。
影响持久层的效率
- os的文件控制器,每个网络连接和磁盘访问都对应一个文件句柄,分别需要一个文件控制器。
- 异步线程,vm会创建异步线程池用于处理长时间的IO操作。
8. 使用
spring进行了集成,只需要添加依赖、添加连接配置、使用监听器注解、使用template,即可发送和接收rabbitmq消息。
Spring AMQP
step1:添加maven依赖
// 根据项目使用spring framework的版本选择amqp的版本
org.springframework.amqp
spring-rabbit
2.4.8
org.springframework.amqp
spring-amqp
2.4.8
com.rabbitmq
amqp-client
5.13.1
org.springframework
spring-messaging
5.3.24
step2:添加配置信息
spring:
rabbitmq:
addresses: ip/host:port
username: xxxxxx
password: xxxxxxstep3:添加队列监听
// 该方式要求queue必须已经存在,否则报错
@RabbitListener(queues = {"myQueue3"}, group = "${rabbit.customer.group}")
// 该方式不要求queue必须存在,但是exchangeName必须有数据
//@RabbitListener(bindings = @QueueBinding(value = @Queue(value = "myQueue3", durable = "true"), exchange = @Exchange(name = "mustUseExchangeName")))
public void listenQueue3(String in) {
System.out.println("myQueue3 : " + in);
}step4:使用template发送消息
@Autowired
AmqpTemplate amqpTemplate;
/**
* 明确知晓 exchange 和 routingKey 时使用
* @param exchangeName
* @param routingKey
* @param msg
*/
public boolean sendMsg(@NotEmpty String exchangeName, @NotEmpty String routingKey, @NotEmpty String msg) {
String uuid = UUID.randomUUID().toString();
Message buildMessage = MessageBuilder.withBody(msg.getBytes(StandardCharsets.UTF_8))
.setContentType(MessageProperties.CONTENT_TYPE_JSON)
.setMessageId(uuid)
.build();
try {
amqpTemplate.send(exchangeName, routingKey, buildMessage);
if (log.isInfoEnabled()) {
log.info("sendToMq{} success {} {} {}", uuid, exchangeName, routingKey, msg);
}
return true;
} catch (Exception e) {
log.warn("sendToMq{} ex", uuid, e);
return false;
}
}
/**
* 使用默认exchange,使用queueName作为routingKey。
* @param queueName
* @param msg
*/
public boolean sendMsg(@NotEmpty String queueName, @NotEmpty String msg) {
String uuid = UUID.randomUUID().toString();
Message buildMessage = MessageBuilder.withBody(msg.getBytes(StandardCharsets.UTF_8))
.setContentType(MessageProperties.CONTENT_TYPE_JSON)
.setMessageId(uuid)
.build();
try {
amqpTemplate.send(queueName, buildMessage);
if (log.isInfoEnabled()) {
log.info("sendToMq{} success {} {}", uuid, queueName, msg);
}
return true;
} catch (Exception e) {
log.warn("sendToMq{} ex", uuid, e);
return false;
}
}
至此,咱们已经走完从概念原理理解到具体使用的过程。
Q&A
Q1:Cannot convert from [[B] to [xx] for GenericMessage
MessageConversionException: Cannot convert from [[B] to [com.creditease.openapi.zma.SIAMessage] for GenericMessage [payload=byte[883], headers={amqp_receivedDeliveryMode=PERSISTENT, amqp_receivedRoutingKey=xxxxxxx, amqp_deliveryTag=1, amqp_consumerQueue=xxxxx, amqp_redelivered=false, id=38a8f84c-214d-3b2d-a145-1290ff0d95a3, amqp_consumerTag=amq.ctag-ybguNgI74bd7GDEqIyMNTw, amqp_lastInBatch=false, contentType=text/plain, timestamp=1673933990248}]
原因:
converter 支持的contentType与接收到消息的contentType不匹配
Jackson2JsonMessageConverter默认supportedContentType=application/json,与上述contentType=text/plain不匹配。
解决方式:
确定发送方和接收方contentType一致的情况下,修改converter配置
@Bean
public MessageConverter jsonMessageConverter() {
Jackson2JsonMessageConverter jsonConverter = new Jackson2JsonMessageConverter();
jsonConverter.setSupportedContentType(MimeTypeUtils.parseMimeType("确定一致的类型,如text/plain"));
return jsonConverter;
}否则,在无法确定发送方和接收方contentType一致的情况下,不要使用JsonConverter。
在@RabbitListener的方法入参使用String,内部自行转换,这样保险。