量化交易全流程(四)
本节目录
数据准备(数据源与数据库)
CTA策略
数据源:
在进行量化分析的时候,最基础的工作是数据准备,即收集数据、清理数据、建立数据库。下面先讨论收集数据的来源,数据来源可分为两大类:免费的数据源和商业数据库。
免费数据源包括新浪财经、Yahoo财经等。这些数据源提供的接口比较复杂,不是很好用。好消息是,Python中有对应的开源工具可以让数据获取变得简单。比如,akShare 能够获取新浪财经的数据,pandas-reader能够获取 Yahoo Finance 的数据。本章主要讨论akShare 和 pandas-reader 的用法。
商业数据库包括万得(Wind)、同花顺(iFind)、聚源等。商业数据库也分为两种,一种是软件终端,除了可以提供各种数据查询和可视化功能之外,还提供了接口以便从终端上提取数据。比如万得终端。终端的好处是价格便宜,简单易用。坏处是对提取的数据量有限制,而且数据的定制化功能很差,很多数据甚至都没有提供接口。另一种是落地数据库,通常是SQL数据库,所有数据直接落地,可以用SQL语句进行提取。落地数据库的好处是数据丰富,定制灵活,没有数据量限制;缺点是成本较高,而且技术门槛也相对较高。大部分人使用的是第一种,即终端提供的接口。本章就以Wind为例,讨论第一种数据库的用法。
前几张也详细谈到过获取数据接口,这里就不展开了,接找几个有用的技巧:
获取交易日历:
import akshare as ak
from datetime import datetime
# Get the trade date history dataframe
tool_trade_date_hist_sina_df = ak.tool_trade_date_hist_sina()
# Specify the start and end dates
start_date = "2022-01-01"
end_date = "2022-12-31"
start_date = datetime.strptime(start_date, "%Y-%m-%d").date()
end_date = datetime.strptime(end_date, "%Y-%m-%d").date()
# Extract the dates within the specified range
selected_dates = tool_trade_date_hist_sina_df[(tool_trade_date_hist_sina_df["trade_date"] >= start_date)\
& (tool_trade_date_hist_sina_df["trade_date"] <= end_date)]
print(selected_dates)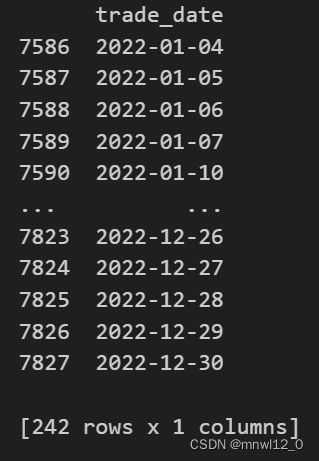
import akshare as ak
from datetime import datetime
macro_usa_gdp_monthly_df = ak.macro_usa_gdp_monthly()
start_date = "2022-01-01"
end_date = "2022-12-31"
start_date = datetime.strptime(start_date, "%Y-%m-%d").date()
end_date = datetime.strptime(end_date, "%Y-%m-%d").date()
# Extract the dates within the specified range
selected_dates = macro_usa_gdp_monthly_df[(macro_usa_gdp_monthly_df["日期"] >= start_date)\
& (macro_usa_gdp_monthly_df["日期"] <= end_date)]
print(selected_dates)如果想要获取国外市场数据,那么pandas-reader将是一个很好的免费数据接口。但pandas-reader也没有包含在Anaconda当中,需要自行安装。可以使用pip命令进行安装,命令如下:
pip install pandas-datareaderPandas集成了很多免费的数据接口,包括但不限于Yahoo Finance、Google Finance、quandl、美联储、世界银行等提供的数据。
pandas-reader的接口使用也很简单。先导入相关的函数,命令如下:
import pandas_datareader.data as web但是好像接口被关闭,获取不到数据。
获取美国宏观经济数据:
import akshare as ak
from datetime import datetime
macro_usa_gdp_monthly_df = ak.macro_usa_gdp_monthly()
start_date = "2022-01-01"
end_date = "2022-12-31"
start_date = datetime.strptime(start_date, "%Y-%m-%d").date()
end_date = datetime.strptime(end_date, "%Y-%m-%d").date()
# Extract the dates within the specified range
selected_dates = macro_usa_gdp_monthly_df[(macro_usa_gdp_monthly_df["日期"] >= start_date)\
& (macro_usa_gdp_monthly_df["日期"] <= end_date)]
print(selected_dates)
万得接口
一个简单例子
万得(Wind)提供了一系列的接口,其中也包含Python的接口。下面列举一段简单的示例代码,用于提取股票000001.SZ一周的日线数据,具体如下:
由于没有账号不方便演示,自行学习跳过。教你使用Python连接Wind金融数据接口 - 知乎 (zhihu.com)
基于Wind返回的data的数据结构特点,在创建DataFrame的时候,必须先将index与Fields 对应,columns与日期对应,之后再进行矩阵转置。
数据库:
存储数据有很多种方式。有人比较喜欢以文件的形式存储,比如,csv文件或hdf5文件。但通常情况下,我还是比较喜欢建立一个数据库,以便于进行数据的管理和分享。而且,数据库本身也能完成很多数据计算和分析工作。
现今的数据库主要分为两种:一种是关系型数据库,也就是使用SQL语句进行操作的数据库,常见的有MySQL、PostgreSQL、SQL Sever等;一种是非关系型(NoSQL)数据库,比如MongoDB。这两种数据库各有其优势,这里主要还是使用传统的SQL数据库。本书中以PostgreSQL为例。SQL基础知识的讲解不在范围之内,大家可以自行查找相关的教程进行学习。这里假设读者已经具有SQL的相关基础。
Pandas利用SQLAlchemy包,提供了简单的数据库接口。比如,我们想把一个dataframe 存储到数据库里面,
前提是已经安装了:
pip install psycopg2
pip install sqlalchemy可以使用如下代码:
from sqlalchemy import create_engine
engine=create_engine ('postgresql://postgres@localhost:5432/postgres')
df.to_sql('stock_all_info',engine, if_exists='replace', index=True)其中,engine存储了连接数据库的相关信息(数据库地址、数据库名称、用户名和密码)。
在df.to_sql中,第一个参数表示表的名称。参数if_exists表示假如现在已经存在此表,应进行什么操作;append代表在当前表中添加新的列;replace 表示替换当前表(删除当前已有的表);fail 表示不进行任何操作,默认值是fail;参数index 表示是否将DataFrame的索引也存储到表中。
存储的时候,数据库会自动识别每列的数据类型,并对应到SQL数据库的类型。比如我们将前面获取到的数据存储到stock_all_info中。数据库中会生成一张表。
由于date在df里面是索引,所以数据库也会自动地为这张表创建一个 date索引。
数据库的读取也非常容易,可以使用如下代码实现:
df=pd.read_sql('select * from stock_info',where windcode = '000001.SZ',engine)其中,第一个参数是一个SQL查询语句,接口将返回该查询语句对应的DataFrame。
下载所有股票历史数据并存储
做策略研究的朋友经常会有建立一个完整的股票数据库的需求。本节将展示一个小程序,指导下载所有股票历史行情并存储到数据库中。
此处展示只获取5只股票,市场上有5000多只股票,获取不完,要花很长时间,另外获取时间我固定为20210101到现在的行情,如果有需求的话自行修改代码中的start_date;
先回顾如何在数据库里面创建表:(自行学习前面的数据库,这里不再介绍)
CREATE TABLE stocks (
date DATE,
stock_code VARCHAR(20),
open DECIMAL(15,4),
high DECIMAL(15,4),
low DECIMAL(15,4),
close DECIMAL(15,4),
volume DECIMAL(30,8)
);表里面具体的有日期,股票代码,四个价以及成交量。
实现代码具体如下:
delete from stocks;
查看表里面内容:
select * from stocks; 
全部代码如下:(已经封装成类)
import akshare as ak
import datetime
import mysql.connector
import pymysql
import pandas as pd
class StockDataUpdater:
def __init__(self, host, user, password, port, db):
self.host = host
self.user = user
self.password = password
self.port = port
self.db = db
# -------------------------获取数据库中每只股票的历史数据---------------------------------------
# 获取所有股票代码
def all_stock_codes(self):
all_stock_codes = ak.stock_zh_a_spot_em()[['代码']].sort_values(by='代码')
all_stock_codes = all_stock_codes.reset_index(drop=True)
return all_stock_codes
# 判断股票所属市场
def code_type(self, code):
if code.find('60',0,3)==0:
gp_type='sh'
elif code.find('688',0,4)==0:
gp_type='sh'
elif code.find('689',0,4)==0:
gp_type='sh'
elif code.find('900',0,4)==0:
gp_type='sh'
elif code.find('00',0,3)==0:
gp_type='sz'
elif code.find('300',0,4)==0:
gp_type='sz'
elif code.find('301',0,4)==0:
gp_type='sz'
elif code.find('200',0,4)==0:
gp_type='sz'
elif code.find('8',0,1)==0:
gp_type='bj'
elif code.find('430',0,4)==0:
gp_type='bj'
code = gp_type+code
return code
# 获取股票指标数据
def get_indicator(self, stock_ID):
stock_individual_info = ak.stock_individual_info_em(symbol = stock_ID)
# 获取索引
index = stock_individual_info.loc[stock_individual_info['item'] == '上市时间'].index[0]
# 使用索引定位value列的开始日期
start_date = str(stock_individual_info.loc[index, 'value'])
start_date = start_date[:4] + start_date[4:6] + start_date[6:]
start_date = '20210104'
# 获取当前日期
end_date = datetime.datetime.now().strftime('%Y%m%d')
end_date = '20220104'
# 新浪拉取数据,有些数据拉取不全
stock_code = self.code_type(stock_ID)
try:
data = ak.stock_zh_a_daily(symbol=stock_code, start_date=start_date, end_date=end_date, adjust="qfq")
df = data[['date','open','high','low','close','volume']]
df = df.dropna()
return df
except:
return None
# 连接数据库
def insert_info(self, stock_indicator):
conn = pymysql.connect(host = self.host # 连接名称,默认127.0.0.1
,user = self.user # 用户名
,password = self.password # 密码
,port = self.port # 端口,默认为3306
,db = self.db # 数据库名称
,charset = 'utf8' # 字符编码
)
cur = conn.cursor() # 生成游标对象
for index, row in stock_indicator.iterrows():
sql = "INSERT INTO stocks(date,stock_code,open,high,low,close,volume) VALUES (%s, %s, %s, %s, %s, %s, %s)"
cur.execute(sql, (row['date'], row['stock_code'], row['open'], row['high'],row['low'], row['close'],row['volume']))
conn.commit() # 提交事务
cur.close() # 关闭游标
conn.close() # 关闭连接
# -------------------------更新数据库中每只股票的最新数据---------------------------------------
# 获取数据库中每个股票的最新日期
def get_latest_date(self, stock_code):
conn = pymysql.connect(host='127.0.0.1', user='root', password='152617', port=3306, db='stock_info', charset='utf8')
cur = conn.cursor()
sql = f"SELECT MAX(date) FROM stocks WHERE stock_code = '{stock_code}'"
cur.execute(sql)
latest_date = cur.fetchone()[0]
cur.close()
conn.close()
return latest_date
# 拉取股票历史数据
def update_historical_data(self):
stocks_info = self.all_stock_codes()
for i in range(len(stocks_info)):
if i<3:
stock_indicator = self.get_indicator(stocks_info['代码'][i])
if stock_indicator is not None:
stock_indicator = stock_indicator.assign(stock_code = stocks_info['代码'][i])
self.insert_info(stock_indicator)
else:
break
# 更新股票最新行情数据
def update_latest_data(self):
stocks_info = self.all_stock_codes()
for i in range(len(stocks_info)):
if i < 5:
stock_code = stocks_info['代码'][i]
latest_date = self.get_latest_date(stock_code)
if latest_date is not None:
latest_date = latest_date.strftime('%Y%m%d')
stock_indicator = self.get_indicator(stock_code)
if stock_indicator is not None:
stock_indicator = stock_indicator.assign(stock_code=stock_code)
if latest_date is not None:
stock_indicator = stock_indicator[stock_indicator['date'] > latest_date]
if not stock_indicator.empty:
self.insert_info(stock_indicator)
else:
break
host = '127.0.0.1'
user = 'root'
password = '152617'
port = 3306
db = 'stock_info'
updater = StockDataUpdater(host, user, password, port, db)
# 更新历史数据
updater.update_historical_data()
# 更新最新数据
# updater.update_latest_data() 在这里我先将时间固定在20210104—20220104:
运行结果为:文件名为info.py

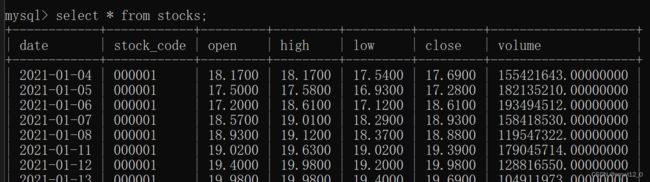
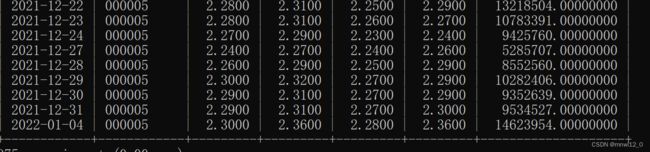
在获取历史行情时要去掉updater.update_latest_data();
然后更新股票时去掉updater.update_historical_data();同时要去掉end_date:

重新运行:

运行结果为:
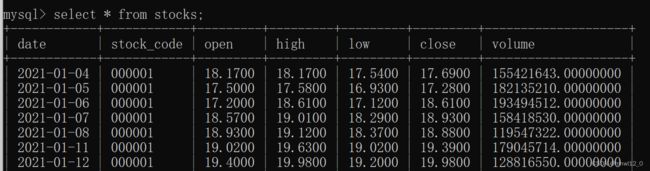
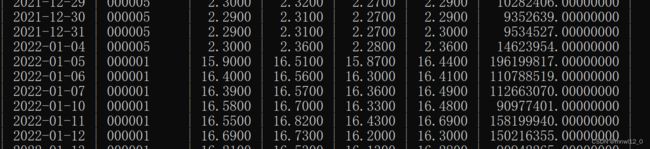

有一点不完善的是更新的数据并不是append在原来股票代码后面,但这并不影响,只要在数据库里面按照stock_code sort一下即可。这里就不详细演示了。
上面的程序,主要分为两步,第一步获取所有A股的代码。第二步是针对每一个股票,获取对应的指标(这里是open、high、low、close),并存储于数据库中,并进行实时更新。
下面这部分代码是获取全部股票行情数据存放到数据库中(耗时很长,谨慎运行):
import akshare as ak
import datetime
import mysql.connector
import pymysql
import pandas as pd
class StockDataUpdater:
def __init__(self, host, user, password, port, db):
self.host = host
self.user = user
self.password = password
self.port = port
self.db = db
# -------------------------获取数据库中每只股票的历史数据---------------------------------------
# 获取所有股票代码
def all_stock_codes(self):
all_stock_codes = ak.stock_zh_a_spot_em()[['代码']].sort_values(by='代码')
all_stock_codes = all_stock_codes.reset_index(drop=True)
return all_stock_codes
# 判断股票所属市场
def code_type(self, code):
if code.find('60',0,3)==0:
gp_type='sh'
elif code.find('688',0,4)==0:
gp_type='sh'
elif code.find('689',0,4)==0:
gp_type='sh'
elif code.find('900',0,4)==0:
gp_type='sh'
elif code.find('00',0,3)==0:
gp_type='sz'
elif code.find('300',0,4)==0:
gp_type='sz'
elif code.find('301',0,4)==0:
gp_type='sz'
elif code.find('200',0,4)==0:
gp_type='sz'
elif code.find('8',0,1)==0:
gp_type='bj'
elif code.find('430',0,4)==0:
gp_type='bj'
code = gp_type+code
return code
# 获取股票指标数据
def get_indicator(self, stock_ID):
stock_individual_info = ak.stock_individual_info_em(symbol = stock_ID)
# 获取索引
index = stock_individual_info.loc[stock_individual_info['item'] == '上市时间'].index[0]
# 使用索引定位value列的开始日期
start_date = str(stock_individual_info.loc[index, 'value'])
start_date = start_date[:4] + start_date[4:6] + start_date[6:]
start_date = '20210104'
# 获取当前日期
end_date = datetime.datetime.now().strftime('%Y%m%d')
# end_date = '20220104'
# 新浪拉取数据,有些数据拉取不全
stock_code = self.code_type(stock_ID)
try:
data = ak.stock_zh_a_daily(symbol=stock_code, start_date=start_date, end_date=end_date, adjust="qfq")
df = data[['date','open','high','low','close','volume']]
df = df.dropna()
return df
except:
return None
# 连接数据库
def insert_info(self, stock_indicator):
conn = pymysql.connect(host = self.host # 连接名称,默认127.0.0.1
,user = self.user # 用户名
,password = self.password # 密码
,port = self.port # 端口,默认为3306
,db = self.db # 数据库名称
,charset = 'utf8' # 字符编码
)
cur = conn.cursor() # 生成游标对象
for index, row in stock_indicator.iterrows():
sql = "INSERT INTO stocks(date,stock_code,open,high,low,close,volume) VALUES (%s, %s, %s, %s, %s, %s, %s)"
cur.execute(sql, (row['date'], row['stock_code'], row['open'], row['high'],row['low'], row['close'],row['volume']))
conn.commit() # 提交事务
cur.close() # 关闭游标
conn.close() # 关闭连接
# -------------------------更新数据库中每只股票的最新数据---------------------------------------
# 获取数据库中每个股票的最新日期
def get_latest_date(self, stock_code):
conn = pymysql.connect(host='127.0.0.1', user='root', password='152617', port=3306, db='stock_info', charset='utf8')
cur = conn.cursor()
sql = f"SELECT MAX(date) FROM stocks WHERE stock_code = '{stock_code}'"
cur.execute(sql)
latest_date = cur.fetchone()[0]
cur.close()
conn.close()
return latest_date
# 拉取股票历史数据
def update_historical_data(self):
stocks_info = self.all_stock_codes()
for i in range(len(stocks_info)):
if True:
stock_indicator = self.get_indicator(stocks_info['代码'][i])
if stock_indicator is not None:
stock_indicator = stock_indicator.assign(stock_code = stocks_info['代码'][i])
self.insert_info(stock_indicator)
else:
break
# 更新股票最新行情数据
def update_latest_data(self):
stocks_info = self.all_stock_codes()
for i in range(len(stocks_info)):
if True:
stock_code = stocks_info['代码'][i]
latest_date = self.get_latest_date(stock_code)
if latest_date is not None:
latest_date = latest_date.strftime('%Y%m%d')
stock_indicator = self.get_indicator(stock_code)
if stock_indicator is not None:
stock_indicator = stock_indicator.assign(stock_code=stock_code)
if latest_date is not None:
stock_indicator = stock_indicator[stock_indicator['date'] > latest_date]
if not stock_indicator.empty:
self.insert_info(stock_indicator)
else:
break
host = '127.0.0.1'
user = 'root'
password = '152617'
port = 3306
db = 'stock_info'
updater = StockDataUpdater(host, user, password, port, db)
# 更新历史数据
updater.update_historical_data()
# 更新最新数据
# updater.update_latest_data() 获取好后,数据库中存在所有行情大致为:反正一直在更新数据(数据量很大)

这里面有一些重复数据的行,因为运行的时候忘记先保存再运行,导致查找到了一些重复的行并添加了进来。
以下是在db里面运行:
先备份表,
-- 创建一个和stocks一样的表
create table stock_info.stock like stock_info.stocks;
-- 将信息复制到stock里面
INSERT INTO stock_info.stock(date, stock_code ,open,high,low,close,volume)
SELECT date, stock_code ,open,high,low,close,volume FROM stock_info.stocks;-- 添加唯一标识列id列
ALTER TABLE stock_info.stock ADD COLUMN id INT AUTO_INCREMENT PRIMARY KEY;
-- 创建临时表,按7个列的值排序
use stock_info;
CREATE TEMPORARY TABLE tmp_table
SELECT MIN(id) AS id
FROM stock_info.stock
GROUP BY date, stock_code, open, high, low, close, volume;
-- 删除重复值的行
DELETE FROM stock_info.stock
WHERE id NOT IN (
SELECT id FROM tmp_table
);
-- 删除临时表
DROP TEMPORARY TABLE tmp_table;处理完后数据大概有:

将stock数据赋值给stocks;
-- 删除原表的内容
delete from stocks;
-- 将信息复制到stocks里面,不复制id列
INSERT INTO stock_info.stocks(date, stock_code ,open,high,low,close,volume)
SELECT date, stock_code ,open,high,low,close,volume FROM stock_info.stock;数据准备过程就完成了。
查看数据:
select * from stock_info.stocks order by stock_code,date ;
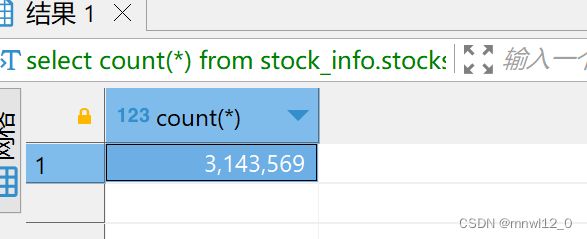
select count(*) from stock_info.stocks;
CTA策略
数据准备好后,下面进行策略介绍:
CTA全称是Commodity Trading Advisor,即"商品交易顾问",是由NFA(美国全国期货协会)认定的,在CFTC(商品期货交易委员会)注册,并接受监管的投资顾问。CTA 一般是指通过为客户提供期权、期货方面的交易建议,或者直接通过受管理的期货账户参与实际交易,来获得收益的机构或个人。
以上的定义只是原始的意思,随着市场的发展,市场对CTA策略的理解普遍发生了改变,它已不再只是商品期货了。实际上,目前国内的 CTA 策略大都是基于量价的趋势跟踪策略。无论是商品期货、金融期货,还是股票、外汇,只要是有历史公开量价的二级市场,都可以成为CTA策略运作的市场。国内市场中,期货是T+0,股票是T+1,且期货可以做多做空,所以期货的研究空间要大很多。国内成熟的第三方自动化交易软件,基本上都是从期货人手的。所以本部分就以期货作为研究对象,介绍基本的CTA策略研究思路和方法。
趋势跟踪策略理论基础
但凡接触过投资的,大概都听过"趋势跟踪"的概念。著名经济学家大卫.李嘉图曾将"趋势跟踪"策略表述为"截断亏损,让利润奔跑"。"趋势跟踪"策略,通俗地讲,就是涨了的股票,会涨得更高;跌了的股票,会跌得更低。只要我们顺着大势做,就能赚钱。
很多人将"趋势跟踪"奉为圭臬,坚定不移。也有人将其当作"金融巫术",认为该策略不值一提。那么"趋势跟踪"是否真的有效?很多信徒内心也不免打鼓。这种怀疑,就像肉中刺,平时隐隐作痛,令人不得安稳。假若不幸,连续亏损,则是"发炎肿胀",让人难受得开始怀疑人生。
"趋势跟踪"不是魔法,不可能让你天天赚钱,甚至都不一定能年年赚钱。但既然该策略能广为流传,那一定是有其道理的。
为了"讲清道理",各种机构的学者没少花时间和精力来研究该策略。
2012年,Tobias J. Moskowitz 等人发表的文章《Time series momentum》,使用了最基本的"趋势跟踪"策略——买人最近上涨的资产,卖空最近下跌的资产。此策略自 1985年以来,在几乎所有的股票指数期货、债券期货、商品期货以及远期货币上,平均来看,都是盈利的。
当然,30 年的数据不算太长,为了能有更强的说服力,美国著名的对冲基金AQR.发表了报告《A Century of Evidence on Trend-Following Investing》(《趋势投资策略:一个世纪的证据》),报告中列举了100年的数据,证明了"趋势跟踪"策略是有效的,不仅长期来看取得了正收益,而且与各传统大类资产相关性很低,是一种非常好的分散风险的投资方法。
既然上文已从实证的角度说明了"趋势跟踪"策略的有效性,那么此类策略的现实逻辑基础究竟是什么呢?为了回答这个问题,我们可以反过来思考:"趋势跟踪"策略无效的理论基础是什么?就是赫赫有名的"弱有效市场假说"。此假说指出,证券的历史价格已反映了全部的市场信息。历史价格是公开的,所有投资者都可以基于此做出理性的判断,从而形成当前的有效价格。换句话说,当前资产是被完美定价的。
此假说明显不符合事实,投资界的"非理性狂热"和"羊群效应"是明显存在的。也正是这种"非理性"的部分,常常使得证券价格偏离了"实际价值",也就是被错误定价。由于"非理性"的长期存在,"趋势跟踪"策略也能长期有效。
著名的《黑天鹅》作者,纳西姆·塔勒布其实也是类似策略的践行者。不过他实现的方式不一样,他的交易策略是买入那些远离实际价格的期权,平时亏小钱,希望在大波动来临的时候,一把挣足。实际情况就是,他开办的公司在最初几年,表现平平,略有亏损,结果在"911事件"的时候,大发横财。这也符合了他的理念,"极端行情比我们想象的要多而且极端"。正是这一认知误差,使得市场长期低估了"大趋势"出现的可能性。这也是"趋势跟踪"策略长期有效的根本原因。
技术指标
国内的量化CTA大部分使用的都是技术指标构建策略。所谓技术指标,就是价格、成交量、持仓量的数学组合。大体上,技术指标可分为三种类型,具体说明如下。
(1)趋势型
顾名思义,趋势型指标可用于描述并捕捉趋势行情,适合趋势跟踪策略,比如,MACD、SAR等。
(2)超买超卖型(也可以称作"反转型")
股市价格的涨跌中,也会有反复和振荡,比如,KDJ、RSI等。超买超卖型与趋势型刚好相反,此类指标可用于描述并捕捉趋势行情的终结,即反转状态,目标是为了识别震荡和短期的头部底部。
(3)能量型
能量型的指标是指从成交量的角度考察价格变动的力量,常用于辅助判断信号的强度。比如VOL、OBV等。
主力合约的换月问题
期货合约是会到期的。若要进行较长历史的回测,使用的数据则是由多个合约拼接而换月时会产生"假跳空"的问题。由于不同合约经常会存在一个较大的价差,因此表现在成的,也就是所谓的主力连续合约。使用这种主力连续合约,往往会存在一个问题,就是连续合约上,就会产生一个大的跳空,这个跳空就是"假跳空"。这种"假跳空",最大的影响就是技术指标的计算会失真。比如,实际行情明明没有突破,但由于存在"假跳空"的问题,从而出现了突破。举个例子,比如某期货品种,假设换月前两天的收盘价依次为1020、1000,换月后的价格为1200、1220。那么由于跳空的问题,就好像价格突然上涨了200一样,从而就出现了"假突破"问题,如果不进行复权处理,那么很可能会产生多头信号,然则这个信号其实是错误的。
在进行回测的时候,我们需要处理"假跳空"的问题。为了避免"假跳空"问题带来的误差,一般会采用如下三种方法。
□使用期货的合成指数来进行回测。
□对跳空进行复权处理。
□不使用主力合约,而是使用单独月份的合约来进行分析。
这三种方法的实现成本依次递增,准确性也依次增强。在实际应用中,需要针对自己的具体需求来选择。下面针对这三种方法做一个详细介绍。
1使用合成指数进行回测
合成指数,是指对某个品种各个月份的价格,分配权重,计算出一个综合性指数,用于代表该品种的整体走势。计算指数的时候,算法一般都会保证其连续性,不会出现"假跳空"的问题。市面上很多第三方平台都会提供期货的合成指数。这样就可以直接使用指数进行回测,回测结果也就不会受到"假跳空"问题的影响。但这种方法也存在缺点:一是指数不是真实的价格数据,多少会存在一些误差;二是指数的计算公式往往不是透明的,而且各个平台很可能又是不一样的。使用"黑盒"的指数,总是感觉会有些不踏实,这种方法比较适合进行初步的测试。初步回测通过之后,就可以考虑使用更精确的方法来回测了。
2.对主力连续合约进行复权处理,抹平跳空
复权算法共有好几种,一般包含两个维度。首先,复权可以分为加减复权和乘除复权;其次,可以分为前复权和后复权。这样两两组合,其实就有四种算法了。
为了更清楚地解释复权的概念,这里使用本节开始的例子来进行说明。假设有四天的数据,换月前两天的收盘价依次为1020、1000,换月后的价格为1200、1250,这样在换月时候就会有200的"假跳空"价差了。
先解释加减复权和乘除复权。所谓加减复权是指对跳空产生的价差进行加减平移。比如说,我们将换月后两天的数据,也就是1200和1250,都减去200,得到1000和1050。处理后的数据序列就是:1020、1000、1000、1050。加减复权的好处是,直观易理解,价格序列比较"整洁",不会出现小数点。缺点是收益率会出现偏差,比如处理之前的1200到1250,涨幅是(1250-1200)/1200-0.042,处理之后涨幅是(1050-1000)/1000=0.05。为了保证收益率不出现偏差,就需要使用乘除复权了。顾名思义,乘除复权是指在价格的基础上乘上一个因子。比如这里,换月前后,1000跳空到1200,相当于是白白乘了1.2倍。为了复权,就需要将换月后的数据除以1.2。这样得到的数据序列就是1020和1000,1200/1.2=1000.1250/1.2=1041.66,这样保证每天收益率不会因为复权而产生偏差,缺点是复权之后的数据就没有那么"整洁"了,出现了小数点。在各大股票软件中,一般使用乘除复权。但其实这两种方法都有自己的用武之地。比如,在高频策略的研究中,由于价差变化非常小,因此加减复权带来的收益率偏差也很小,可以忽略不计,这个时候就可以使用加减复权,来保证数据的整洁性。
3.不使用主力连续合约,使用单独的实际合约进行回测
这种方法的缺点是,由于大部分指标都需要针对一段时间内的历史数据进行计算,因此这段时间内,是不会有交易信号的,相当于损失了这段时间内的历史数据,所以这种方法比较适合于小周期策略的回测(比如15分钟策略),因为小周期策略损失的数据会很少,一般就是两三天,影响并不大。
用Python实现复权
上一节中介绍了处理合约换月的几种方法,本节就来介绍如何编写程序完成复权操作。复权方法共有两种:加减复权和乘除复权。下面将讲解这两种复权方法的实现。
加减复权
假设每次换月的时候,换月前的收盘价和换月后的开盘价就是换月导致的"伪跳空"价差。这个假设并不完全准确,但是这样假设比较简便,容易处理。
这样我们就可以得到相应的算法了,具体步骤如下。
1)初始化复权因子为0。
2)每次换月后,将"伪跳空"累加到复权因子上,算出所有的复权因子。
3)统一将所有的价格都减去复权因子。
在 Pandas 里面,我们可以很方便地用向量化还有对应的函数来实现这个功能,甚至不需要编写循环语句就可以完成。以下是完成加减复权的函数,具体代码如下:
def adjust_price_sum(df):
"""
加减复权
参数:df:原始的OHLC数据,列名依次为:date,trade_hiscode,open,high,low,close
其中,trade_hiscode代表了合约的代码,因为存在换月的问题,因此这个代码是会变动的
返回值:df:进行复权处理后的数据,OHLC 所有价格数据都要进行复权,并返回对应的复权因子adj_factor
"""
# 生成前一天的收盘价,以便于向量化计算复权价格
df['close_pre'] = df.close.shift(1)
# 判断是否换月
df['roll_over'] = (df.trade_hiscode != df.trade_hiscode.shift(1)) & (~df.trade_hiscode.shift(1).isnull())
# 初始化复权因子
df['adj_factor'] = 0
# 计算因换月问题导致的复权因子变化
df.loc[df.roll_over, 'adj_factor'] = df.loc[df.roll_over, 'close_pre'] - df.loc[df.roll_over, 'open']
# 累积所有复权因子的变化,得到最终的复权因子
df['adj_factor_cum'] = df.adj_factor.cumsum()
# 对OHLC的四个数据都进行复权
df['open'] = df.open + df.adj_factor_cum
df['high'] = df.high + df.adj_factor_cum
df['low'] = df.low + df.adj_factor_cum
df['close'] = df.close + df.adj_factor_cum
# 删除中间数据
del df['close_pre']
del df['roll_over']
del df['adj_factor']
del df['adj_factor_cum']
df = df.dropna()
return df
在以上函数中,我们使用了Pandas的 shift 函数完成了今日和昨日的比较和运算,使用cumsum()函数完成了复权因子的累加。
乘除复权
乘除复权和加减复权在总体逻辑上是一致的,但是在算法的具体细节上却有所不同。乘除复权的具体算法步骤如下。
1)初始化复权因子为1。
2)每次换月后,将"伪跳空"累乘到复权因子上,算出所有的复权因子。
3)统一将所有的价格都乘以复权因子。
乘除复权对应的函数代码具体如下:
def adjust_price_sum(df):
"""
乘除复权
参数:df:原始的OHLC数据,列名依次为:date,trade_hiscode,open,high,low,close
其中,trade_hiscode代表了合约的代码,因为存在换月的问题,因此这个代码是会变动的
返回值:df:进行复权处理后的数据,OHLC 所有价格数据都要进行复权,并返回对应的复权因子adj_factor
"""
# 生成前一天的收盘价,以便于向量化计算复权价格
df['close_pre'] = df.close.shift(1)
# 判断是否换月
df['roll_over'] = (df.trade_hiscode != df.trade_hiscode.shift(1)) & (~df.trade_hiscode.shift(1).isnull())
# 初始化复权因子
df['adj_factor'] = 1
# 计算因换月问题导致的复权因子变化
df.loc[df.roll_over,'adj_factor'] = df.loc[df.roll_over,'close_pre']/df.loc[df.roll_over,'open']
# 累积所有复权因子的变化,得到最终的复权因子
df['adj_factor_cum'] = df.adj_factor.cumprod()
# 对OHLC的四个数据都进行复权
df['open']=round(df.open * df.adj_factor_cum, 2)
df['high']=round(df.high * df.adj_factor_cum, 2)
df['low']=round(df.low * df.adj_factor_cum, 2)
df['close']=round(df.close * df.adj_factor_cum, 2)
# 删除中间数据
del df['close_pre']
del df['roll_over']
del df['adj_factor']
del df['adj_factor_cum']
df=df.dropna()
return df处理好合约数据之后,我们就可以开始着手构建交易策略了。在"趋势跟踪"系统中,技术指标是必不可少的。好消息是,技术指标的计算不需要重新造轮子,因为已经有很成熟的库可供我们使用了,比如 ta-lib。ta-lib 本身是基于C语言的技术指标库,现在也提供开源的经Python包装后的库,那也是比较好用的。技术指标是技术分析流派的核心组成部件,所以花费较大的篇幅来介绍ta-lib将是很值得的。
安装ta-lib
Anaconda 预装是没有ta-lib的,我们需要手动进行安装。到这里寻找对应python版本的Ta-Lib进行下载:(新建了一个环境python3.8,因为没有3.11的Ta-Lib)
Archived: Python Extension Packages for Windows - Christoph Gohlke (uci.edu)
使用pip install Ta-Lib会报错,因此需要去下载安装,找对本地python对应版本 比如TA_Lib-0.4.24-cp38-cp38-win_amd64.whl这个文件此本版 他的python版本就是3.8的版本,然后点击下载 PS:我的是python3.8的所以就下载这个! 对于一切上述ERROR只要重新尝试下载不同版本TA_Lib即可解决,都是版本不适配导致的。
下载完成后在下载路径下:

打开cmd,先激活虚拟环境,再输入命令安装:
 安装好测试:
安装好测试:

可以正常调入,没有问题。
ta-lib的指标和函数介绍
本节将会详细介绍ta-lib的用法和指标函数。
ta-lib本身是由C语言完成的,但ta-lib自己的官网文档却很少,反倒是Python封装项目文档比较详细,这也是我们主要的参考资料。不过,该文档是英文的,下面的指标名称主要以英文为主,同时也带有中文翻译。
ta-lib的函数主要分为10组,具体如下。
□ Overlap Studies (可叠加指标)
□Momentum Indicators(动量指标)
□ Volume Indicators(成交量指标)
□ Volatility Indicators(波动率指标)
□ Price Transform(价格变换)
□ Cycle Indicators(周期指标)
□ Pattern Recognition(模式识别)
□ Statistic Functions(统计函数)
□ Math Transform(数学变换)
□Math Operators(数学运算符)
Python版中ta-lib的使用语法是比较简单的,有两种方式来计算指标值。函数式API (Function API)和抽象API(Abastract API)。
函数式API提供了一种轻量级的调用方式。函数式API主要输入的是四个同样长度的ndarray,分别是open、high、low和close。比如,我们首先可以通过如下命令生成一个close:
在vscode里面更改内核为py38;
import numpy
import talib
close=numpy.random.random(100)
# 然后,调用talib.SMA计算简单的移动平均,代码如下:
output=talib.SMA(close)
output结果:

有时候也可以指定不同的均线计算方式,比如计算布林线,命令如下:
from talib import MA_Type
# 下面使用参数matype 来指定使用三重指数平滑均线计算布林线。
upper, middle, lower = talib.BBANDS(close, matype=MA_Type.T3)
# 同时,也可以使用参数timeperiods-5来指定计算周期,示例代码如下:
output = talib.MOM(close,timeperiod=5)
print(output)
# 在调用形态识别函数的时候,需要输入open、high、low、close四组数据,示例代码如下
import numpy as np
# note that all ndarrays must be the same length!
inputs = {
'open': np.random.random(100),
'high': np.random.random(100),
'low': np.random.random(100),
'close': np.random.random(100),
'volume': np.random.random(100)
}
output = talib.CDL2CROWS (inputs['open'], inputs['high'], inputs['low'], inputs['close'])
print(output)
还有一种是抽象式API,也尝试过,但感觉不太习惯,就放弃使用了,现在一直坚持使用函数式API,因为该方式更清晰易懂。
ta-lib总共包含了7组指标。下面将对比较重要的指标做一个简单的介绍。当然,限于篇幅,无法全部解释,读者可以自行查阅。
我们可以显示Ta lib的所有TA函数,返回一个 list 或者 dict
import talib
print (talib.get_functions())
print (talib.get_function_groups())
![]()
指标学习参考:
链接:https://pan.baidu.com/s/1vwEIUBJb-FVZ6B9sirAX8g?pwd=1234
提取码:1234
Function Groups
- Overlap Studies 重叠的研究
- Momentum Indicators 动量指标
- Volume Indicators 量指标
- Volatility Indicators 波动性指标
- Price Transform 价格指标
- Cycle Indicators 循环指标
- Pattern Recognition 模式识别
- Statistic Functions 统计功能
- Math Transform 数学变换
- Math Operators 数学运算符
Overlap Studies
BBANDS Bollinger Bands #布林带
DEMA Double Exponential Moving Average #双指数移动平均线
EMA Exponential Moving Average #指数滑动平均
HT_TRENDLINE Hilbert Transform - Instantaneous Trendline #希尔伯特变换瞬时趋势
KAMA Kaufman Adaptive Moving Average #卡玛考夫曼自适应移动平均
MA Moving average #均线
MAMA MESA Adaptive Moving Average #自适应移动平均
MAVP Moving average with variable period #变周期移动平均
MIDPOINT MidPoint over period #在周期的中点
MIDPRICE Midpoint Price over period #中间时段价格
SAR Parabolic SAR #抛物线转向指标
SAREXT Parabolic SAR - Extended
SMA Simple Moving Average
T3 Triple Exponential Moving Average (T3)
TEMA Triple Exponential Moving Average
TRIMA Triangular Moving Average
WMA Weighted Moving Average
Momentum Indicators
ADX Average Directional Movement Index
ADXR Average Directional Movement Index Rating
APO Absolute Price Oscillator
AROON Aroon
AROONOSC Aroon Oscillator
BOP Balance Of Power
CCI Commodity Channel Index
CMO Chande Momentum Oscillator
DX Directional Movement Index
MACD Moving Average Convergence/Divergence
MACDEXT MACD with controllable MA type
MACDFIX Moving Average Convergence/Divergence Fix 12/26
MFI Money Flow Index
MINUS_DI Minus Directional Indicator
MINUS_DM Minus Directional Movement
MOM Momentum
PLUS_DI Plus Directional Indicator
PLUS_DM Plus Directional Movement
PPO Percentage Price Oscillator
ROC Rate of change : ((price/prevPrice)-1)*100
ROCP Rate of change Percentage: (price-prevPrice)/prevPrice
ROCR Rate of change ratio: (price/prevPrice)
ROCR100 Rate of change ratio 100 scale: (price/prevPrice)*100
RSI Relative Strength Index
STOCH Stochastic
STOCHF Stochastic Fast
STOCHRSI Stochastic Relative Strength Index
TRIX 1-day Rate-Of-Change (ROC) of a Triple Smooth EMA
ULTOSC Ultimate Oscillator
WILLR Williams' %R
Volume Indicators
AD Chaikin A/D Line
ADOSC Chaikin A/D Oscillator
OBV On Balance Volume
Volatility Indicators
ATR Average True Range
NATR Normalized Average True Range
TRANGE True Range
Price Transform
AVGPRICE Average Price
MEDPRICE Median Price
TYPPRICE Typical Price
WCLPRICE Weighted Close Price
Cycle Indicators
HT_DCPERIOD Hilbert Transform - Dominant Cycle Period
HT_DCPHASE Hilbert Transform - Dominant Cycle Phase
HT_PHASOR Hilbert Transform - Phasor Components
HT_SINE Hilbert Transform - SineWave
HT_TRENDMODE Hilbert Transform - Trend vs Cycle Mode
Pattern Recognition
CDL2CROWS Two Crows
CDL3BLACKCROWS Three Black Crows
CDL3INSIDE Three Inside Up/Down
CDL3LINESTRIKE Three-Line Strike
CDL3OUTSIDE Three Outside Up/Down
CDL3STARSINSOUTH Three Stars In The South
CDL3WHITESOLDIERS Three Advancing White Soldiers
CDLABANDONEDBABY Abandoned Baby
CDLADVANCEBLOCK Advance Block
CDLBELTHOLD Belt-hold
CDLBREAKAWAY Breakaway
CDLCLOSINGMARUBOZU Closing Marubozu
CDLCONCEALBABYSWALL Concealing Baby Swallow
CDLCOUNTERATTACK Counterattack
CDLDARKCLOUDCOVER Dark Cloud Cover
CDLDOJI Doji
CDLDOJISTAR Doji Star
CDLDRAGONFLYDOJI Dragonfly Doji
CDLENGULFING Engulfing Pattern
CDLEVENINGDOJISTAR Evening Doji Star
CDLEVENINGSTAR Evening Star
CDLGAPSIDESIDEWHITE Up/Down-gap side-by-side white lines
CDLGRAVESTONEDOJI Gravestone Doji
CDLHAMMER Hammer
CDLHANGINGMAN Hanging Man
CDLHARAMI Harami Pattern
CDLHARAMICROSS Harami Cross Pattern
CDLHIGHWAVE High-Wave Candle
CDLHIKKAKE Hikkake Pattern
CDLHIKKAKEMOD Modified Hikkake Pattern
CDLHOMINGPIGEON Homing Pigeon
CDLIDENTICAL3CROWS Identical Three Crows
CDLINNECK In-Neck Pattern
CDLINVERTEDHAMMER Inverted Hammer
CDLKICKING Kicking
CDLKICKINGBYLENGTH Kicking - bull/bear determined by the longer marubozu
CDLLADDERBOTTOM Ladder Bottom
CDLLONGLEGGEDDOJI Long Legged Doji
CDLLONGLINE Long Line Candle
CDLMARUBOZU Marubozu
CDLMATCHINGLOW Matching Low
CDLMATHOLD Mat Hold
CDLMORNINGDOJISTAR Morning Doji Star
CDLMORNINGSTAR Morning Star
CDLONNECK On-Neck Pattern
CDLPIERCING Piercing Pattern
CDLRICKSHAWMAN Rickshaw Man
CDLRISEFALL3METHODS Rising/Falling Three Methods
CDLSEPARATINGLINES Separating Lines
CDLSHOOTINGSTAR Shooting Star
CDLSHORTLINE Short Line Candle
CDLSPINNINGTOP Spinning Top
CDLSTALLEDPATTERN Stalled Pattern
CDLSTICKSANDWICH Stick Sandwich
CDLTAKURI Takuri (Dragonfly Doji with very long lower shadow)
CDLTASUKIGAP Tasuki Gap
CDLTHRUSTING Thrusting Pattern
CDLTRISTAR Tristar Pattern
CDLUNIQUE3RIVER Unique 3 River
CDLUPSIDEGAP2CROWS Upside Gap Two Crows
CDLXSIDEGAP3METHODS Upside/Downside Gap Three Methods
Statistic Functions
BETA Beta
CORREL Pearson's Correlation Coefficient (r)
LINEARREG Linear Regression
LINEARREG_ANGLE Linear Regression Angle
LINEARREG_INTERCEPT Linear Regression Intercept
LINEARREG_SLOPE Linear Regression Slope
STDDEV Standard Deviation
TSF Time Series Forecast
VAR Variance
熟悉上面指标需要花费大量时间,但是是必经之路,是必需要学习的。
一个简单策略模式
下面将介绍一个简单的策略模式,实际应用中我们可以根据自己的偏好和习惯进行选择和组合。一个合理的CTA策略,一般是以"趋势跟踪"为主,以反转指标和能量指标为辅。
为了说明技术指标组合,下面分别选取趋势指标T、反转指标R、能量指标E进行说明。
我们假设趋势指标为T,T+代表趋势指标出现多头信号,比如5日均线(MA(5))上穿20日均线(MA(20));T﹣代表空头信号,比如MA(5)下穿MA(20)。趋势指标是最重要的,一个策略可以没有反转指标、能量指标,但不能没有趋势指标。定义趋势可以有很多种方法,但各种方法其实都大同小异。以下两种方法最为常用。
1)突破。当前价格大于先前N期的价格,就视为突破。举个例子,将N定义为10,如果当前价格大于前10天的最高价,则认为是向上突破。反之,当前价格小于前10天的最低价,则认为是向下突破。
2)移动平均线的穿越。移动平均线简称均线,是一种平滑价格的方法。计算前N期(包含当期)收盘价的平均值,就得到了当期的均线值MA(N)。比如MA(10),就是今天与过去9天收盘价的平均值。均线可以筛除一些短期波动,突显较长期的趋势,但也因此会让均线的转折点落后于价格本身的转折点。当短期均线上穿长期均线,比如MA(5)上穿MA(10)时,可以视为一种突破。
假设反转指标为R,R+代表反转指标出现多头信号,R﹣代表反转指标出现空头信号。反转指标R通常与趋势跟踪指标相反,价格越涨,我们越要害怕,怕涨太高会回调;或者跌太狠,会反抽。一个典型的反转指标是RSI。比如,我们假设RSI达到70以上,说明出现了超买情况,属于空头信号。RSI达到30以下,说明出现了超卖情况,属于多头信号。
假设能量指标为E,能量指标通常与成交量结合计算,比如能量潮指标OBV。OBV指标的计算方法比较简单,主要是计算累积成交量。
下面以日为计算周期举例说明,其计算公式为:
当日OBV=本日值+前一日的OBV值
如果本日收盘价或指数高于前一日收盘价或指数,则本日值为正值;如果本日的收盘价或指数低于前一日的收盘价,则本日值为负值;如果本日值与前一日的收盘价或指数持
平,则本日值不参与计算,然后计算累积成交量。E大于某阈值m时,可以作为筛选条件。
综合趋势指标T、反转指标R、能量指标E,我们就有了一个简单的策略套路,具体说
明如下。
口空仓时,若出现T+,则开多仓;若出现T-,则开空仓。
口当前是多头时,若出现T-,则平多反手开空;若出现R-,则平多不开新仓。
口 当前是空头时,若出现T+,则平空反手开多;若出现R+,则平空不开新仓。
口所有的信号均可以用能量E超过某阈值m来辅助,只有当E有效时,信号才有效。
这样就可以构建一个简单的策略。当然,在这个策略中,所有的参数,比如均线的周期数、RSI的信号范围、E的阈值m,都可以作为可变的参数。我们也可以对这些参数进行优化,以达到最佳历史效果。
当然,这里只是列举了一个简单的例子,实际中,各种各样的组合非常多。都需要自己去尝试。这里只是提供一个思路和实现框架,供读者参考。
当我们处理好输入的合约数据,并且确定了策略逻辑,就需要对策略进行回测了,下部分将会讨论策略回测中的相关问题。