量化交易全流程(五)
本节目录
策略回测
本节主要讨论回测相关的内容,包括两种不同的回测机制,即向量化回测和事件驱动回测;如何灵活使用开源工具来编写自己的回测程序;不同实现方式的优劣对比等。
在我们研究策略的时候,需要知道某个策略的历史表现,这种情况就需要编写回测程序来查看了。编写回测程序有两种模式,一种是向量化回测,一种是事件驱动回测。这两种模式都有其对应的优点和缺点。本部分将对这两种模式进行讨论,包括如何自己编写回测程序,如何使用开源框架等
回测系统是什么
最基本的回测系统是指,当我们有一组交易规则,需要根据历史数据来获取这组交易规则的业绩表现时,除了给出历史表现之外,有时候还需要优化参数。比如,交易规则设定了一些参数,我们需要知道哪组参数表现最好,这种情况就还需要一个优化系统。更精细一点的,有时候还需要对下单的冲击成本进行模拟,这种情况就还需要一个模拟撮合系统。这些系统都是回测系统的一部分。可以看到,回测系统想要简单时可以非常简单,想要复杂时也可以非常复杂。具体如何选用、开发,还是要根据自己的需求来决定。
各种回测系统简介
策略回测是一个非常广泛的需求,市面上有很多商业的或者开源的系统。各种系统数量之多,如何选择也是一个问题。一般来说,开发回测程序有三种方式,具体如下。
口 使用现成的商业软件,这种商业软件提供的编程语言大体包含两类,一类是比较简单的Easy Language,比如Multicharts、Tradeblazer、文华财经等。另一类是稍微复杂的事件驱动型,比如优矿、OpenQuant、quantopian。
口 使用开源的框架进行二次开发,比如zipline、pyalgotrade等。
口 使用任何一门编程语言自行开发,比较流行的有Python、Java、C#、Matlab、R等。
(1)商业软件
使用商业软件,最大的好处是比较省时省力,而且由于有一个专业的公司在维护,系统出Bug的概率比较小。缺陷是缺乏灵活性,它们往往只适用于几类策略。对于更为灵活开放的策略往往是没有办法的。有时候,也会有保密性方面的担忧。
(2)开源框架二次开发
使用开源框架进行二次开发,可以兼顾省时省力和灵活性。由于已经有了开发好的大量模块,所以直接进行二次开发,比自己从头开发要容易很多。不过,这只是针对相对复杂的回测系统而言,比如,要实现tick级别的下单算法模拟。
(3)自己从头开发
完全自己开发,拥有完全的灵活性。更重要的是,很多策略回测往往并不需要复杂的回测系统,有时候很简单的脚本就能完成回测。
以上三种方法各有优劣,都有自己适合的场景。具体使用哪种方法,并没有一定之规。在实际应用中,这三种方法很可能是交叉应用的。即使在同一家公司之内,由于同事的工作习惯不同,在进行合作研究的时候,也不得不来回切换。
由于本书主要集中于Python相关的内容,所以本章主要介绍如何使用Python 自主开发,以及如何使用开源框架进行二次开发。
什么是回测
回测是量化投资研究中的一个基本方法。简单定义,回测就是针对历史价格设定的一系列的交易规则,从而得到交易规则的历史业绩表现。
具体地说就是,针对一系列的资产,我们设定一个机制,用来选择,什么时间持有资产,什么时间清空资产。再加上资产本身的历史价格,我们就能计算出这个"交易策略"在历史业绩中的表现,比如,年化收益率、波动率、最大回撤等。
有句话用于描述回测非常合适,"所有的模型都是错的,但有一些是有用的"。我们并不能保证历史回测表现好的模型在将来就一定能赚钱。那么回测的目的又是什么呢?
简单地说就是,回测结果可以让我们过滤很多不好的模型。是否选择上线某个策略,我们需要参考很多信息,历史回测是其中一个非常重要的参考依据。如果历史回测都表现不好,那么我们很难相信这个策略在将来会表现得很好。
总之,回测好的策略不一定赚钱,但回测不好的策略基本上是不可能赚钱的。所以回测对于我们筛选策略,还是有相当大的重要性的。事实上,不少投资经理,在没有实际去回测某个指标的有效性的情况下,依然还是在凭感觉使用。我并不认为这是一种理性的方式。当然,这也是有客观原因的,比如,很多投资经理,使用的主观投资方法,完全不会编程,平时又很忙,让他们自行编写程序进行回测,似乎也不可能。这一点目前国内基金行业需要提高的一个地方。投资行业中的竞争可以用惨烈来形容,高手间的博弈,你比别人好一点点,积累下来,结果可能就是天差地别。所以既然这块有可以提高的空间,那么为什么不去尝试做呢?
回测系统的种类
回测系统一般包含三种类型,"for循环"系统、"向量化"系统、"事件驱动"系统。这三种系统的区别主要在于程序结构逻辑上。下面对这三种方式做一个简单的介绍。
"向量化"系统
"向量化"计算是一种特殊的计算方式,意思是用矩阵运算的方式来进行程序的编写。这种编写方式多见于Matlab、Python、R等带有科学计算性质的语言中,最大的好处是速度快。因为在科学计算中,矩阵运算由于频繁使用,所以其是经过专门优化的。比如,对于将两个数组中的元素一一对应相加的操作,使用向量化的方式,比使用迭代循环的方式,两者的速度差距很可能是十倍甚至百倍。
所以"向量化"系统最大的优势就是速度快,特别适合于需要大量优化参数的策略。实际上,最近正火热的"深度学习",其本质就是各种矩阵运算,如何优化矩阵运算的速度,其实是一个框架需要考虑的非常重要的特性。
"向量化"系统的主要缺陷就是,对于一些复杂的逻辑是无法实现的。比如说,有一类逻辑具有"路径依赖性",也就是说,当前值的计算需要依赖于前一个值的计算结果。由于向量化计算是同时计算出所有的值,所以这类"路径依赖"的问题是无法用向量化来计算的。对于这种情况,我们不得不使用迭代循环的方式来进行计算。
For 循环回测系统
For循环回测系统是最直观的回测系统。For循环系统比较简单直观,所以很多回测使用的都是For循环系统。For循环系统是指针对每一个数据点进行遍历。比如,对于日线数据,就是循环遍历每一个OHLC(Open、High、Low、Close)数据。在遍历的时候同时进行计算,比如计算移动均线,然后在此过程中决定是买人还是卖出某资产。一般是以当天的收盘价或者第二天的开盘价作为买人或者卖出价。当然,有时候为了止损止盈,也需要使用不同的价格。
For循环系统的优势具体总结如下。
□ For循环系统最符合人类交易的直觉,简单直观,易于实现。任何语言都可以用来快速地实现一个For循环系统,所以For循环系统非常常见。
□For循环系统可以解决"路径依赖"的问题,因为我们是依次迭代每一个数据点,这样在计算当前数据点的时候,前面的结果都已经计算好了,可以直接使用。
For循环系统的劣势具体总结如下。
□相对于向量化系统,速度比较慢。比如,在Python中使用Pandas进行迭代循环,就会比较慢。或者在Matlab中使用循环,也会非常的慢。如果数据量比较小,则速度慢是没关系的。但是很多回测数据量其实是比较大的,比如回测2000支股票数据,这种情况下,速度就非常重要了。
□比较容易出现前视偏差。比如,我们在编写策略逻辑的时候,经常会使用索引值来调用不同的数据点,比如使用i-1来调用前一个数据点。这个时候可能会出现失误,调用了i+1的值。而这个值在回测中应该是未知的,这样就出现了前视偏差。
□ For 循环只能用于测试,而不能用于实盘,这样回测和实盘就分别拥有两套代码了。同时维护两套代码,可能会出现逻辑不一致的问题。
事件驱动系统
事件驱动系统会尽可能地模拟真实的交易机制,是一种结构更为复杂的系统。在事件驱动系统中,交易相关的所有行为都是由事件触发的。比如,当前K线结束了,我们需要做什么?发出委托之后,我们需要做什么?委托成交之后,我们需要做什么?事件驱动系统详尽地定义了交易中可能发生的每一个相关事件,并用函数的形式来指定发生对应事件后所应采取的行动。
事件驱动系统具有很多优势,具体如下。
□避免"前视偏差"。因为在事件驱动系统中,所有的数据只有等事件发生之后(比如下一根K线开始了),才会看得到这个数据,并采取相应的行动。这样就完全避免了不小心使用未来函数。
□代码复用。很多事件驱动系统其本身就带有实盘交易模块。这样,回测程序就可以直接用于实盘交易中了。回测和实盘交易使用的是同一套代码,非常便于维护。
□ 可以最大程度地模拟真实交易,甚至包括下单的冲击成本都可以模拟。
事件驱动系统虽然具有很多优势,是非常完善的系统,但其也有如下缺点。
□ 实现困难。事件驱动系统是一个比较复杂的系统,需要进行精心的设计和调试,也就是说,需要花费大量的精力在该系统上。对于一个IT开发人员来说,这个问题可能并不算困难。但对于很多策略研发者、投资经理来说,自己开发则几乎是不可能的任务。当然,好消息是现在有很多开源框架可以使用,但即使是开源框架,想要入手用起来也有一定的学习曲线。
□实现策略逻辑复杂。事件驱动系统中,有大量的事件对应的行动需要自行定义,这会让编程变得比较复杂,对于很多简单的策略来讲,有点杀鸡用牛刀的感觉。
□速度很慢。事件驱动的特点就决定了它的运行速度不会很快。在有大量参数需要优化的时候,事件驱动系统就会变得非常难用。
总的来说,并没有哪一种方法可以包打天下,都要具体问题具体分析。比如,策略逻辑很简单,但需要优化的参数很多,这种情况就适合使用向量化系统。若策略无法向量化实现,但又想快速进行验证,这种情况就比较适合采用For循环系统。若策略参数已经确定,想比较真实地进行模拟,这种情况就适合使用事件驱动系统。
所以理想情况下,这三种系统最好都要会使用。
回测的陷阱
在回测的时候,会遇到很多陷阱,让回测结果出现偏差。其实很多陷阱都是可以避免的。比较常见的陷阱一般包含以下几种情况。
□ 样本内回测。如果我们使用同样的样本数据去训练模型(参数优化)并得到测试结果,那么这个测试结果一定是被夸大的。因为这里的训练是纯粹针对已知的数据进行训练,并没有对未知的数据进行测试。所以在实盘的时候,表现会差得很远。这是一种过度拟合的形式。
□ 幸存者偏差。比如将市面上的对冲基金业绩表现做一个综合性指数,这个指数其实并不能代表对冲基金的真实业绩,因为业绩很差的那些基金都已经不存在了。在编制指数的时候,如果不对这种情况加以考虑,就会产生很大的偏差,因为最差的那一部分并没考虑进来。
□ 前视偏差。在进行回测的时候,有时候我们会不小心使用未来的数据(又称为"未来函数")。举个例子,假设我们使用线性回归,计算了某段时间内价格的斜率,如果在这段时间内,我们又用到了这个斜率,那么这就是使用了未来数据。有时候,如果历史回测表现得非常好,甚至是惊艳,那么就需要注意了,这很有可能是因为使用了未来数据。这种情况比较严重。
□ 交易成本。交易成本在回测中其实非常重要。假如我们将交易成本设为0,那么在训练模型的时候,筛选出来的模型往往都是交易频率非常高的模型。这些交易频率非常高的模型在0成本的时候表现非常好。但是一旦加入了交易成本,这些模型就会一落千丈。所以在回测的时候,一定要加入合理估计的交易成本。
□市场结构转变。在进行长时间的回测的时候,经常会忽视这个问题。比如,国内的期货品种,有的品种有夜盘交易,夜盘交易的时间还变化过好几次。在进行回测的时候,如果不能对应地做出合理的调整,那么也会出现一定的问题。
回测中的其他考量
对于回测,其实还有很多细节和问题需要考虑,具体如下。
□ 数据的准确性。获取数据有很多种来源。没有人能打包票,百分之百地确定数据一定是准确的。但是我们应该在一定的成本范围内,尽量保证数据的准确性。所以开始的数据清洗工作就显得异常重要了。当然,会有很多供应商号称自己提供的数据是经过认真清洗的,但我们不能完全信任他们。毕竟承担投资决簧结果的是投资者,而不是他们。
□流动性限制。在回测的时候,我们很容易假设能买到所有的股票,但实际上,很多股票因为流动性的原因,其实是买不到的。或者即使买到了,冲击成本也远高于正常的成本。比如,有的股票一天的交易量就只有100手,那么肯定就没办法买到200手。再比如,有的股票一开盘就涨停,这种情况下我们也买不到。
□选取合理的比较基准。
□稳定性。对于一个策略,我们希望它的表现越稳定越好,这就是所谓的稳定性。稳定性有两个衡量维度,一是时间上的稳定性,二是参数上的稳定性。时间上的稳定性,是指策略对于一个特定的周期,在不同的时间段,表现相对稳定,不会出现某段时间大赚,另外一段时间大亏的情况。不稳定的策略,在实际中几乎不可能坚持应用。比如,一个策略在回测中,今年收益50%,明年倒亏30%,试想在实盘中,如果亏损了30%,那么谁还敢坚持使用?而且,回测稳定的策略有助于我们判断策略是否失效,一个每个月都赚钱的策略,突然连续几个月不赚钱了,那很有可能就是失效了,这个时候就需要我们再次进行研究,是策略暂时性的失效,还是市场结构本身发生了变化而导致的失效。参数上的稳定性,是指策略的表现不会随着参数的微小变化而大起大落。一般来说,策略都会有与其对应的参数(无参数策略也有,但是比较少见),当我们针对历史优化出一套参数之后,我们希望这套参数是比较可靠的。一个评价标准就是这套参数邻近的参数表现都比较好。如果一个参数的微小变化就会导致策略表现大幅下降,则说明参数的稳定性不够,这套参数是不可靠的。比如,我们得到的最优参数是(2,6,20),如果参数(2,5,19)表现突然变差,那就说明(2,6,20)不是一组好参数。换句话说,我们实际上是要找到"一块"优秀的参数区域,然后再在其中挑选对应的参数。
□ 心理因素。心理因素在回测的时候常常会被忽略。虽然量化交易是比较系统的交易方法,但也要把心理因素考虑进来。比如,能接受的胜率、最大回撤分别是多少?实盘中,胜率太低,或者回撤太大,都可能导致投资者自我怀疑,从而不得不放弃策略,甚至开始手动操作。
□ 交叉验证。我们在进行回测的时候,为了确保策略的稳定性,需要进行交叉验证。交叉验证一般可以在两种维度上展开,一是在不同的品种上进行交叉验证,二是在不同的时间周期和时间段上进行交叉验证。
回测系统概览
本部分将要讨论市面上现有的编程语言以及回测平台,包括商业系统和开源系统两个方面的。
如果想要自己开发回测系统,那么第一个问题就是,应选择什么样的编程语言?
最常用编程语言有Python、Matlab、R、Java、C#等。目前国内的情况是,使用Matlab 的人数最多,但使用Python的人数增长最快。
如果在最大的开源平台GitHub上搜索 backtesting,那么搜索出来的项目中,Python的数量将是最多的,并且远远超过第二名R的项目。
使用 Python搭建回测系统
在前面的讨论中,我们知道编写回测系统有三种方式,分别是向量化系统、For循环系统、事件驱动系统。使用Python 语言,可以很方便地实现这三种系统。
其中,向量化系统和For循环系统,其实自己从头开始写,也是可以的,并不算很复杂,而且具有充分的灵活性。对于临时性的策略验证,我是比较推荐自己写脚本的。
而对于事件驱动系统,不建议自己从头开始写,因为这会涉及整体的系统架构设计问题,这个领域其实是比较专业的IT人士才能胜任的。如果只是投资经理或者研究员,那么花这个力气其实是没必要的。
这里我们将依次讨论如何搭建这三种回测系统,使用的是比较简单的双均线突破策略。策略的核心就是趋势跟踪,也就是说,当短期均线高于长期均线的时候,则认为是多头趋势,这个时候持多仓。当短期均线低于长期均线的时候,则认为是空头趋势,这个时候持空仓。
策略的具体逻辑如下所示。
□ 计算两根移动均线 ma1、ma2,周期分别是len1、len2,其中len1
□当均线mal下穿ma2的时候,平掉多头仓位(如果有),卖出做空。
这是一个很简单的策略,不太可能真的赚钱。不过,这里只是为了演示如何编写回测程序,而不是试图介绍如何研究赚钱的策略,这是两码事。
1、Python向量化回测
说是"系统",倒不如说是脚本,因为能使用向量化计算的策略,逻辑一般都比较简单。这种策略使用的是向量化的计算,需要编写的代码并不多。
不过市面上仍然有向量化的回测框架,这些框架一般会提供很多其他的功能。我在这里将要讨论如何从头编写一个回测程序。同时,也会简单介绍一些开源的向量化回测项目。
首先,我们先用最容易理解的方式,即使用Pandas 的DataFrame来实现这个双均线回测。
要计算策略的表现,最重要的是算出每天的持仓情况,根据持仓情况再计算每天的盈亏。从策略逻辑上,我们可以知道,只要 ma1 > ma2,那么就是持有多仓,只要mal
import mysql.connector
import pymysql
import pandas as pd
import numpy as np
class StockData:
def __init__(self):
self.host = '127.0.0.1'
self.user = 'root'
self.password='152617'
self.port= 3306
self.db='stock_info'
def data_convert(self, df):
df["open"] = df['open'].astype(float)
df["high"] = df['high'].astype(float)
df["low"] = df['low'].astype(float)
df["close"] = df['close'].astype(float)
df["volume"] = df['volume'].astype(float)
df = df.dropna()
return df
def get_stock_data(self, stock_code, start_date, end_date):
conn = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port, db=self.db, charset='utf8')
cur = conn.cursor()
sql = f"select * from `stocks` where stock_code = {stock_code} and date > {start_date} and date < {end_date}"
cur.execute(sql)
data = cur.fetchall()
data = pd.DataFrame(data)
data = data.rename(columns={0: "date", 1: "stock_code", 2: "open", 3: "high", 4: "low", 5: "close", 6: "volume"})
df = self.data_convert(data)
cur.close()
conn.close()
return df
sd = StockData()
stock_code = '600519'
start_date = '20230104'
end_date = '20230904'
df = sd.get_stock_data(stock_code, start_date, end_date)
df.head()
我们使用talib来计算移动均线,也就是SMA(Simple Moving Average),代码如下:
import talib as ta
# 两条均线的参数
L1 = 3
L2 = 7
# 使用talib计算移动均线
df['ma1'] = ta.SMA(df.close.values, timeperiod=L1)
df['ma2'] = ta.SMA(df.close.values, timeperiod=L2)import talib as ta
# 两条均线的参数
L1 = 3
L2 = 7
# 使用talib计算移动均线
df['ma1'] = ta.SMA(df.close.values, timeperiod=L1)
df['ma2'] = ta.SMA(df.close.values, timeperiod=L2)根据移动均线ma1、ma2来计算趋势值,用0代表没有趋势,1代表多头趋势,-1代表空头趋势,计算趋势代码如下:
# 定义多头空头趋势
con_long = df['ma1'] > df['ma2']
con_short = df['ma1'] < df['ma2']
# 计算趋势。0代表没有趋势,1代表多头趋势,-1代表空头趋势
df['trend'] = 0
df.loc[con_long,'trend'] = 1
df.loc[con_short,'trend'] = -1现在可以直接计算每天收盘后的仓位了。这里假设出信号后,第二天开盘再交易,因为出信号的时候,已经收盘了,这个时候是无法交易的,所以仓位要比趋势滞后一天。计算仓位代码如下:
# 假设出现信号后,第二天开盘进行交易,每次开仓1手(即100股)
df['pos'] = 100 * df['trend'].shift(1)现在可以通过仓位来计算每天的盈亏了。这里有一点需要注意的是,今天新开的仓位,与从昨天继承的旧仓位,盈亏是不一样的。因为今天的新仓位是以开盘价为起点,收盘价为终点,所以盈亏是当天的收盘价减开盘价。而从昨天继承的旧仓位,是以昨天的收盘价为起点,以今天的收盘价为终点,所以盈亏是今天的收盘价减去昨天的开盘价。所以这两种情况应分开来计算盈亏,计算盈亏代码如下:
# 计算旧仓位和新仓位
df['new_pos'] = df['pos'] - df['pos'].shift(1)
df['old_pos'] = df['pos'] - df['new_pos']假设我们都能以开盘价成交,即开仓价就是开盘价 open,代码如下:
# 把开盘价作为交易价格
df['entry_p'] = df['open']分别计算两种仓位的盈亏值,代码如下:
# 计算旧仓位的盈利和新仓位的盈利
df['p&l_new'] = (df['close']-df['entry_p']) * df['new_pos']
df['p&l_old'] = (df['close']-df['close'].shift(1)) * df['old_pos']
# 每日盈亏由两部分组成
df['p&l'] = df['p&l_new'] + df['p&l_old']将每日的盈亏累加在一起,再加上初始资本,就可以得到资本曲线(如图所示),代码如下:
# 计算累计盈亏
df['p&l_cum']=df['p&l'].cumsum()
# 计算净值曲线,假设初始资金是1000
ini_cap=1000000
df['capital'] = df['p&l_cum'] + ini_cap
df['net_value'] = df['capital'] / ini_cap
# 绘制净值曲线
df = df.set_index('date')
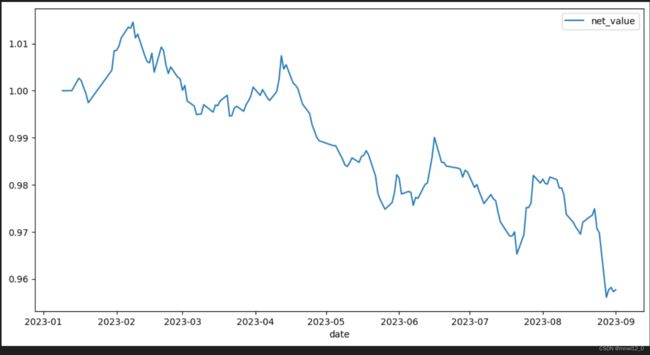
df.plot(figsize=(12,6), y=['net_value'])最后盈亏状况如图:
下面是完整代码:(拉取数据——画蜡烛图——画净收益图)
import mysql.connector
import pymysql
import pandas as pd
import numpy as np
import talib as ta
from mpl_finance import candlestick_ohlc
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
class StockData:
def __init__(self ,L1, L2):
self.host = '127.0.0.1'
self.user = 'root'
self.password='152617'
self.port= 3306
self.db='stock_info'
self.L1 = L1 # 均线策略的两个参数
self.L2 = L2
def data_convert(self, sql_data): # 拉取数据库对数据进行转换
sql_data["open"] = sql_data['open'].astype(float)
sql_data["high"] = sql_data['high'].astype(float)
sql_data["low"] = sql_data['low'].astype(float)
sql_data["close"] = sql_data['close'].astype(float)
sql_data["volume"] = sql_data['volume'].astype(float)
sql_data = sql_data.dropna()
return sql_data
def convert_date(self, candlestick_data): # 蜡烛图日期格式转换
data_price = candlestick_data # 选取日期、高开低收价格、成交量数据
data_price['date'] = data_price['date'].astype(str) # 先将日期转为字符串
data_price.set_index('date', inplace=True) # 将日期作为索引
# 将日期格式转为 candlestick_ohlc 可识别的数值
data_price['date'] = list(map(lambda x:mdates.date2num(datetime.datetime.strptime(x,'%Y-%m-%d')),data_price.index.tolist()))
return data_price
def get_stock_data(self, stock_code, start_date, end_date): # 拉取数据stock_data
conn = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port, db=self.db, charset='utf8')
cur = conn.cursor()
sql = f"select * from `stocks` where stock_code = {stock_code} and date > {start_date} and date < {end_date}"
cur.execute(sql)
data = cur.fetchall()
data = pd.DataFrame(data)
data = data.rename(columns={0: "date", 1: "stock_code", 2: "open", 3: "high", 4: "low", 5: "close", 6: "volume"})
stock_data = self.data_convert(data)
cur.close()
conn.close()
return stock_data
def candlestick(self, candlestick_df): # 画蜡烛图
df = self.convert_date(candlestick_df) # 去除非交易日的间隔
ohlc = df[['date','open','high','low','close']]
ohlc.loc[:,'date'] = range(len(ohlc)) # 重新赋值横轴数据,使横轴数据为连续数值
# 绘图
f1, ax = plt.subplots(figsize = (6,4))
candlestick_ohlc(ax, ohlc.values.tolist(), width=.7, colorup='red', colordown='green')
plt.xticks(rotation = 30) # 日期显示的旋转角度
plt.title(stock_code,fontsize = 14) # 设置图片标题
plt.xlabel('日 期',fontsize = 14) # 设置横轴标题
plt.ylabel('价 格(元)',fontsize = 14) # 设置纵轴标题
date_list = ohlc.index.tolist() # 获取日期列表
xticks_len = round(len(date_list)/(len(ax.get_xticks())-1)) # 获取默认横轴标注的间隔
xticks_num = range(0,len(date_list),xticks_len) # 生成横轴标注位置列表
xticks_str = list(map(lambda x:date_list[int(x)],xticks_num)) # 生成正在标注日期列表
ax.set_xticks(xticks_num) # 设置横轴标注位置
ax.set_xticklabels(xticks_str) # 设置横轴标注日期
plt.show()
def sma(self, sma_df): # 移动均线策略
# 两条均线的参数
sma_df = sma_df.drop(columns=['date'])
df = sma_df.reset_index()
df = df[['date','open','high','low','close']]
# 使用talib计算移动均线
df['ma1'] = ta.SMA(df.close.values, timeperiod = self.L1)
df['ma2'] = ta.SMA(df.close.values, timeperiod = self.L2)
# 定义多头空头趋势
con_long = df['ma1'] > df['ma2']
con_short = df['ma1'] < df['ma2']
# 计算趋势。0代表没有趋势,1代表多头趋势,-1代表空头趋势
df['trend'] = 0
df.loc[con_long,'trend'] = 1
df.loc[con_short,'trend'] = -1
# 假设出现信号后,第二天开盘进行交易,每次开仓1手(即100股)
df['pos'] = 100 * df['trend'].shift(1)
# 计算旧仓位和新仓位
df['new_pos'] = df['pos'] - df['pos'].shift(1)
df['old_pos'] = df['pos'] - df['new_pos']
# 把开盘价作为交易价格
df['entry_p'] = df['open']
# 计算旧仓位的盈利和新仓位的盈利
df['p&l_new'] = (df['close'] - df['entry_p']) * df['new_pos']
df['p&l_old'] = (df['close'] - df['close'].shift(1)) * df['old_pos']
# 每日盈亏由两部分组成
df['p&l'] = df['p&l_new'] + df['p&l_old']
# 计算累计盈亏
df['p&l_cum'] = df['p&l'].cumsum()
# 计算净值曲线,假设初始资金是1000000
ini_cap=1000000
df['capital'] = df['p&l_cum'] + ini_cap
df['net_value'] = df['capital'] / ini_cap
# 绘制净值曲线
df = df.set_index('date')
df.plot(figsize=(6,4), y=['net_value'])
import matplotlib.pyplot as plt
plt.xticks(rotation=30)
plt.show()
sd = StockData(3,7)
stock_code = '600519'
start_date = '20230104'
end_date = '20230904'
stock_dt = sd.get_stock_data(stock_code, start_date, end_date)
print(stock_dt)
sd.candlestick(stock_dt)
sd.sma(stock_dt)
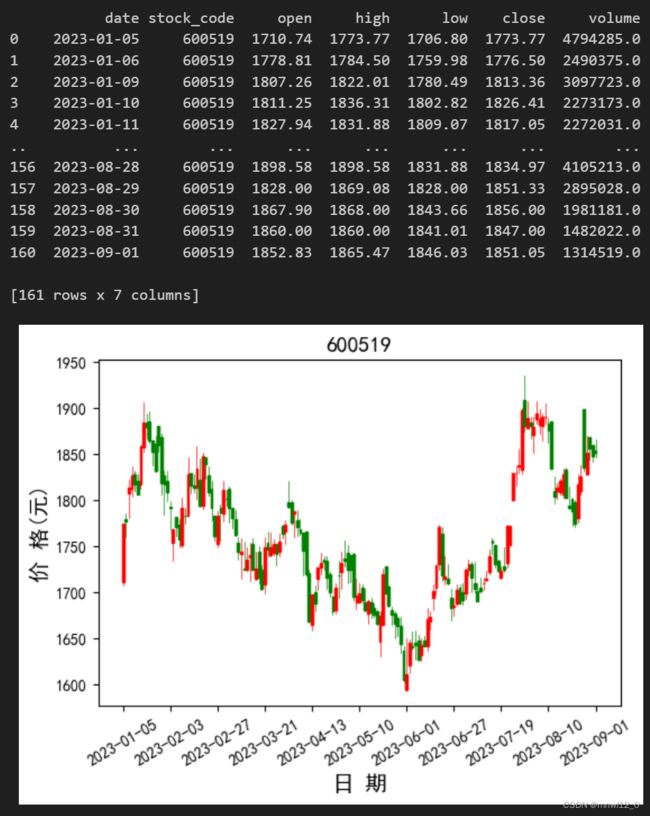
结果如图:

通过这个例子,我们可以看到,回测其实就是从策略逻辑开始,逐步求出策略的表现。策略表现有很多种形式,比如每日盈亏、累计盈亏、净值曲线等。在实际应用中,我们不一定需要求出每一个统计值,往往只需要求出最需要的那个统计值就可以了。比如,我就经常只求到每日盈亏,就直接计算夏普比率,这样不用考虑初始资金,可以充分简化问题。这也是自己写回测的最大好处,方便又灵活。
得到的结论为:你的最终收益可能跟股票走势没有关系,股票价格回升,但你的账户依旧在亏损。
2、Python For循环回测
诚然,如果能使用向量化的方法,就尽量使用向量化的方法,因为向量化的方法代码简洁,而且效率很高。不过,仍然有很多逻辑是向量化方法无法实现的。遇到这种情况,我们就不得不使用For循环的方法。不过值得注意的是,在Pandas中,For循环的效率是比较低的,比如,对DataFrame或者Series 进行循环操作,For循环的效率都比较低。所以碰到循环的时候,最好先转化成NumPy里的数据结构,再进行循环。为了让大家对效率有一个直观的感受,这里我们做一个小实验,来测一下速度差异。
首先,生成两个同样大小的数组,一个是NumPy的array,一个是Pandas里的Series,代码如下:
import numpy as np
import pandas as pd
# 生成ndarray
a = np.arange(100)
# 生成Series
s = pd.Series(a)
# 随机生成索引
i = np.random.randint(0, 99)
# 使用魔法函数%timeit来测算运行时间
# 测算ndarray的时间
%timeit a[i]
# 测算Seried的效率
%timeit s[i]
使用魔法函数%timeit来测算运行时间结果为:1000ns=1us
可以看到,Series所花的时间是ndarray的20倍左右,可以说差距是非常的大了。由于篇幅有限,这里不会对其中的原理进行分析,感兴趣的朋友可以自行搜索关于Python性能优化的内容。
总之,我们知道了ndarray在循环上具有非常大的效率优势,所以这里使用ndarray来获取测试数据,代码如下:
import mysql.connector
import pymysql
import pandas as pd
import numpy as np
import talib as ta
from mpl_finance import candlestick_ohlc
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
class StockData:
def __init__(self):
self.host = '127.0.0.1'
self.user = 'root'
self.password='152617'
self.port= 3306
self.db='stock_info'
def data_convert(self, sql_data): # 拉取数据库对数据进行转换
sql_data["open"] = sql_data['open'].astype(float)
sql_data["high"] = sql_data['high'].astype(float)
sql_data["low"] = sql_data['low'].astype(float)
sql_data["close"] = sql_data['close'].astype(float)
sql_data["volume"] = sql_data['volume'].astype(float)
sql_data = sql_data.dropna()
return sql_data
def get_stock_data(self, stock_code, start_date, end_date): # 拉取数据stock_data
conn = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port, db=self.db, charset='utf8')
cur = conn.cursor()
sql = f"select * from `stocks` where stock_code = {stock_code} and date > {start_date} and date < {end_date}"
cur.execute(sql)
data = cur.fetchall()
data = pd.DataFrame(data)
data = data.rename(columns={0: "date", 1: "stock_code", 2: "open", 3: "high", 4: "low", 5: "close", 6: "volume"})
stock_data = self.data_convert(data)
cur.close()
conn.close()
return stock_data
sd = StockData()
stock_code = '002245'
start_date = '20230104'
end_date = '20230904'
stock_dt = sd.get_stock_data(stock_code, start_date, end_date)
print(stock_dt)初始化相关的变量,在这里,我们对每一个变量,都使用一个单独的ndarray,比如pos就代表了总的仓位,代码如下:
open = df.open.values
high = df.high.values
low = df.low.values
close= df.close.values
# 总的样本数量
n = len(close)
# 两条均线的参数
L1 = 3
L2 = 7
# 使用talib计算移动均线
ma1 = ta.SMA(df.close.values,timeperiod=L1)
ma2 = ta.SMA(df.close.values,timeperiod=L2)
# 计算趋势
con_long = ma1 > ma2
con_short = ma1 < ma2
trend = np.zeros(n)
trend[con_long] = 1
trend[con_short] = -1
# 仓位变化,比如从﹣1到1,变化为2
sig = np.zeros(n)
# 当前总仓位
pos = np.zeros(n)
# 新仓位的开仓价
pce = np.zeros(n)
# 保存交易信息
trade_info = [" " for i in range(n)]
# 每次开仓一手
new_pos = 1策略逻辑如下,在这里,我们首先定义了目标仓位,然后基于目标仓位计算了仓位变化(新的仓位),假设这里是使用开盘价作为交易价格,同时还记录了交易的log信息,以便于理解策略逻辑和进行调试。
for i in range(L2, n):
# 正常情况下,仓位保持不变
pos[i] = pos[i-1]
# 昨天收盘,新出现多头趋势,开盘就开多头仓(如果有空头仓,则先平空头仓)
if trend[i-1] > 0 and pos[i-1] <= 0:
# 目标仓位
pos[i] = new_pos
# 计算仓位变化
sig[i] = new_pos-pos[i-1]
# 记录交易价格
pce[i] = open[i]
# 记录交易log信息
trade_info[i]=u'long at %s' %(pce[i])
# 昨天收盘,新出现空头趋势,开盘就开空头仓(如果有多头仓,则先平多头仓)
elif trend[i-1] < 0 and pos[i-1] >= 0:
# 目标仓位
pos[i] = -new_pos
# 计算仓位变化
sig[i] = -new_pos-pos[i-1]
# 记录交易价格
pce[i] = open[i]
# 记录交易log信息
trade_info[i]=u'short at %s' %(pce[i])当然,最终我们还是要将结果转化成DataFrame,以便于进行最后的处理和观察。
df = pd.DataFrame({'open':open, 'high':high, 'low' :low, 'close':close, 'ma1':ma1, 'ma2':ma2, 'trend':trend, \
'sig':sig, 'pce':pce, 'pos':pos, 'trade_info':trade_info},\
columns=['open','high','low','close','ma1','ma2','trend','sig','pos','pce','trade_info'])
df['new_pos'] = df['pos'] - df['pos'].shift(1)
df['old_pos'] = df['pos'] - df['new_pos']
df['p&l_new'] = (df['close']-df['pce']) * df['new_pos']
df['p&l_old'] = (df['close']-df['close'].shift(1)) * df['old_pos']
df['p&l'] = df['p&l_new'] + df['p&l_old']
del df['new_pos']
del df['old_pos']
del df['p&l_new']
del df['p&l_old']
df=df.dropna()
print(df)
np.sum(df['p&l'])下面我们来看一下df的值,如图所示。(买茅台属于亏钱状态)

换了一组股票测试:蔚蓝锂芯002245


不考虑手续费情况下是赚钱的,但如果考虑手续费每买一次就5块,或者买的量越大,按照资金量比例来算也是亏钱的。
下面是完整代码:(拉取数据——测算收益)
import mysql.connector
import pymysql
import pandas as pd
import numpy as np
import talib as ta
from mpl_finance import candlestick_ohlc
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
class StockData:
def __init__(self, L1, L2):
self.host = '127.0.0.1'
self.user = 'root'
self.password='152617'
self.port= 3306
self.db='stock_info'
self.L1 = L1
self.L2 = L2
def data_convert(self, sql_data): # 拉取数据库对数据进行转换
sql_data["open"] = sql_data['open'].astype(float)
sql_data["high"] = sql_data['high'].astype(float)
sql_data["low"] = sql_data['low'].astype(float)
sql_data["close"] = sql_data['close'].astype(float)
sql_data["volume"] = sql_data['volume'].astype(float)
sql_data = sql_data.dropna()
return sql_data
def get_stock_data(self, stock_code, start_date, end_date): # 拉取数据stock_data
conn = pymysql.connect(host=self.host, user=self.user, password=self.password, port=self.port, db=self.db, charset='utf8')
cur = conn.cursor()
sql = f"select * from `stocks` where stock_code = {stock_code} and date > {start_date} and date < {end_date}"
cur.execute(sql)
data = cur.fetchall()
data = pd.DataFrame(data)
data = data.rename(columns={0: "date", 1: "stock_code", 2: "open", 3: "high", 4: "low", 5: "close", 6: "volume"})
stock_data = self.data_convert(data)
cur.close()
conn.close()
return stock_data
def p_l(self, test_data):
df = test_data
open = df.open.values
high = df.high.values
low = df.low.values
close= df.close.values
# 总的样本数量
n = len(close)
# 使用talib计算移动均线
ma1 = ta.SMA(df.close.values,timeperiod=self.L1)
ma2 = ta.SMA(df.close.values,timeperiod=self.L2)
# 计算趋势
con_long = ma1 > ma2
con_short = ma1 < ma2
trend = np.zeros(n)
trend[con_long] = 1
trend[con_short] = -1
# 仓位变化,比如从﹣1到1,变化为2
sig = np.zeros(n)
# 当前总仓位
pos = np.zeros(n)
# 新仓位的开仓价
pce = np.zeros(n)
# 保存交易信息
trade_info = [" " for i in range(n)]
# 每次开仓一手
new_pos = 1
for i in range(self.L2, n):
# 正常情况下,仓位保持不变
pos[i] = pos[i-1]
# 昨天收盘,新出现多头趋势,开盘就开多头仓(如果有空头仓,则先平空头仓)
if trend[i-1] > 0 and pos[i-1] <= 0:
# 目标仓位
pos[i] = new_pos
# 计算仓位变化
sig[i] = new_pos-pos[i-1]
# 记录交易价格
pce[i] = open[i]
# 记录交易log信息
trade_info[i]=u'long at %s' %(pce[i])
# 昨天收盘,新出现空头趋势,开盘就开空头仓(如果有多头仓,则先平多头仓)
elif trend[i-1] < 0 and pos[i-1] >= 0:
# 目标仓位
pos[i] = -new_pos
# 计算仓位变化
sig[i] = -new_pos-pos[i-1]
# 记录交易价格
pce[i] = open[i]
# 记录交易log信息
trade_info[i]=u'short at %s' %(pce[i])
df = pd.DataFrame({'open':open, 'high':high, 'low' :low, 'close':close, 'ma1':ma1, 'ma2':ma2, 'trend':trend, \
'sig':sig, 'pce':pce, 'pos':pos, 'trade_info':trade_info},\
columns=['open','high','low','close','ma1','ma2','trend','sig','pos','pce','trade_info'])
df['new_pos'] = df['pos'] - df['pos'].shift(1)
df['old_pos'] = df['pos'] - df['new_pos']
df['p&l_new'] = (df['close']-df['pce']) * df['new_pos']
df['p&l_old'] = (df['close']-df['close'].shift(1)) * df['old_pos']
df['p&l'] = df['p&l_new'] + df['p&l_old']
del df['new_pos']
del df['old_pos']
del df['p&l_new']
del df['p&l_old']
df=df.dropna()
return df
sd = StockData(3, 7)
stock_code = '002245' #'600519'
start_date = '20230104'
end_date = '20230904'
stock_dt = sd.get_stock_data(stock_code, start_date, end_date)
# print(stock_dt)
net_pl = sd.p_l(stock_dt)
np.sum(net_pl['p&l'])结果为:

3、PyAlgoTrade简介
本部分将简单介绍一下开源的事件驱动系统PyAlgoTrade的使用。这里使用的是PyAlgoTrade 0.18版本。Anaconda并没有自带PyAlgoTrade,所以读者需要自行下载安装,这里不再介绍。
pip install pyalgotrade首先是数据问题,PyAlgoTrade是将数据封装在其提供的feed类中,读取数据的方式是读取csv文件,PyAlgoTrade是不能直接读取数据框的数据。PyAlgoTrade需要从数据源中获取数据,例如CSV文件、MySQL数据库或者在线数据API(如Yahoo Finance)。如果您想使用数据框中的数据,您需要先将其读入到PyAlgoTrade支持的数据源中,然后再使用PyAlgoTrade。您可以将数据框转换为CSV文件或者MySQL数据库,然后使用PyAlgoTrade的数据接口来读取数据。
因为从本地读取csv文件极不方便,因此我直接从数据库拉取数据,下面是完整的回测代码:
#coding=utf-8
#mac is Moving Average Crossover
import pymysql
import numpy as np
import pandas as pd
from pyalgotrade import bar
from datetime import datetime
from pyalgotrade.technical import ma
from pyalgotrade import strategy,plotter
from pyalgotrade.bar import BasicBar, Frequency
# from pyalgotrade.barfeed import BarFeed
from pyalgotrade.stratanalyzer import returns, sharpe
from pyalgotrade.barfeed.csvfeed import GenericBarFeed # 从csv或者数据库读取数据
class MyStrategy(strategy.BacktestingStrategy):
# 初始化bar线,stock_code,均线1和2的周期,本金
def __init__(self,feed, stock_code, smaPeriod1, smaPeriod2, par):
if feed is None:
return
else:
strategy.BacktestingStrategy.__init__(self, feed, par)
self.__stock_code = stock_code
self.__sma1=ma.EMA(feed[stock_code].getPriceDataSeries(),smaPeriod1)
self.__sma2=ma.EMA(feed[stock_code].getPriceDataSeries(),smaPeriod2)
self.__shortPos = None
self.__longPos = None
# 获取到bars线数据重新初始化函数
def setFeed(self,feed, stock_code, smaPeriod1, smaPeriod2, par):
self.__feed = feed
self.__init__(feed, stock_code, smaPeriod1, smaPeriod2, par)
# 拉取数据库对数据进行转换
def data_convert(self, sql_data):
# sql_data["date"] = [str(date_str) for date_str in sql_data["date"]]
# sql_data["date"] = [datetime.strptime(date_str, "%Y-%m-%d").strftime("%Y-%m-%d %H:%M:%S") for date_str in sql_data["date"]]
sql_data["open"] = sql_data['open'].astype(float)
sql_data["high"] = sql_data['high'].astype(float)
sql_data["low"] = sql_data['low'].astype(float)
sql_data["close"] = sql_data['close'].astype(float)
sql_data["volume"] = sql_data['volume'].astype(float)
sql_data = sql_data.dropna()
return sql_data
# 返回计算MA的元组数值
def getSMA(self):
return self.__sma1,self.__sma2
# 持仓进入市场被取消时触发,检查被取消的持仓是否匹配long和short,反映持仓能够正确更新
def onEnterCanceled(self, position):
if self.__shortPos == position:
self.__shortPos = None
elif self.__longPos == position:
self.__longPos = None
else:
assert False
# 检查持仓交易成功进入
def onEnterOk(self, position):
execInfo = position.getEntryOrder().getExecutionInfo()
self.info('buy at %.2f' % (execInfo.getPrice()))
# 检查持仓交易成功退出
def onExitOk(self, position):
execInfo = position.getExitOrder().getExecutionInfo()
self.info('sell at %.2f' % (execInfo.getPrice()))
if self.__shortPos == position:
self.__shortPos = None
elif self.__longPos == position:
self.__longPos = None
else:
assert False
# 交易信号,短线MA>长线MA进入多头(退出空头)
def onExitCanceled(self, position):
position.exitMarket()
def enterLongSignal(self, bar):
return self.__sma1[-1] > self.__sma2[-1]
def exitLongSignal(self):
return self.__sma1[-1] < self.__sma2[-1]
def exitShortSignal(self):
return self.__sma1[-1] > self.__sma2[-1]
def enterShortSignal(self):
return self.__sma1[-1] < self.__sma2[-1]
# 拉取数据stock_data,填充到onbars里面,特别要注意GenericBarFeed、bar.BasicBar里面的参数传递有哪些
def get_stock_data(self, stock_code, start_date, end_date):
conn = pymysql.connect(host='127.0.0.1', user='root', password='152617', port=3306, db='stock_info', charset='utf8')
cur = conn.cursor()
sql = f"select * from `stocks` where stock_code = {stock_code} and date > {start_date} and date < {end_date}"
cursor = conn.cursor()
cursor.execute(sql)
rows = cursor.fetchall()
rows = pd.DataFrame(rows)
rows = rows.rename(columns={0: "date", 1: "stock_code", 2: "open", 3: "high", 4: "low", 5: "close", 6: "volume"})
rows = self.data_convert(rows)
#print(rows)
bars = GenericBarFeed(Frequency.DAY, None, None)
for i in range(len(rows)):
date_time = rows['date'][i]
# print(date_time)
bar_data = bar.BasicBar(date_time, rows['open'][i], rows['high'][i], rows['low'][i], \
rows['close'][i], rows['volume'][i], None, Frequency.DAY)
# print(bar_data)
bars.addBarsFromSequence(stock_code, [bar_data])
# 关闭连接
conn.close()
return bars
# 根据MA交叉信号进行交易决策,买入后只买一次
def onBars(self, bars):
if self.__sma1[-1] is None or self.__sma2[-1] is None: # 检查指标是否可用
return
bar = bars[self.__stock_code] # 拉取每一天k线数据
if self.__longPos is not None:# 检查是否存在多头持仓,若存在,检查是否有退出多头持仓信号
if self.exitLongSignal():
self.__longPos.exitMarket()
elif self.__shortPos is not None:
if self.exitShortSignal():
self.__shortPos.exitMarket()
else:# 既无多头也无空头持仓,判断是否需要进入多头持仓 # 或空头
if self.enterLongSignal(bar):
shares = int(self.getBroker().getCash() / bars[self.__stock_code].getPrice() * 0.8)# 计算可购买股票数量,0.8是成交委托比
self.__longPos = self.enterLong(self.__stock_code,shares,True)
# elif self.enterShortSignal(bar):
# shares = int(self.getBroker().getCash() / bars[self.__stock_code].getPrice() * 0.8)
# self.__shortPos = self.enterShort(self.__stock_code, shares, True)
def run_strategy(smaPeriod1,smaPeriod2, stocks_code, start_date, end_date, par_value):
# feed = GenericBarFeed(Frequency.DAY,None,None)
# feed.addBarsFromCSV("stock_code","stockdt") # 从本地文件读取csv数据
myStrategy = MyStrategy(None, stocks_code, smaPeriod1, smaPeriod2, par_value)
bars = myStrategy.get_stock_data(stocks_code, start_date, end_date)
myStrategy.setFeed(bars, stocks_code, smaPeriod1, smaPeriod2, par_value)
retAnalyzer = returns.Returns()
myStrategy.attachAnalyzer(retAnalyzer)
plt = plotter.StrategyPlotter(myStrategy)
plt.getInstrumentSubplot(stocks_code).addDataSeries('SMA1',myStrategy.getSMA()[0])
plt.getInstrumentSubplot(stocks_code).addDataSeries('SMA2',myStrategy.getSMA()[1])
plt.getOrCreateSubplot('returns').addDataSeries('returns',retAnalyzer.getReturns())
myStrategy.run()
plt.plot()
# sharpeRatioAnalyzer = sharpe.SharpeRatio()
# returned = retAnalyzer.getReturns()
# returned = returned.dropna()
# sharpeRatio = sharpeRatioAnalyzer.getSharpeRatio(returned, riskFreeRate=0.05)
# print("Sharpe Ratio: %.2f" % sharpeRatio)
# myStrategy.attachAnalyzer(sharpeRatioAnalyzer)
# print("Sharpe ratio: %.2f" % sharpeRatioAnalyzer.getSharpeRatio(0.05))
print("Final portfolio value: %.4f" % myStrategy.getBroker().getEquity())
ma1 = 3
ma2 = 7
stock_codes = '000001'
start_date = '20230104'
end_date = '20230904'
par_value = 100000
run_strategy(ma1, ma2, stock_codes, start_date, end_date, par_value)详细的代码注解都有注释,有几点强调:
该策略回测效果并不好。
未设置手续费和滑点等参数,有效性和可靠性有待校正。
操作的买卖信号被定义成了买入后不会追加,且不能做空。
选出操作的最优股票的代码还没有完善,也就是这里只是回测,选股功能后面我再开发,目前数据库里面存在沪深5000多只股票,再定义一个函数应该就能达到选股功能。但是选股功能的筛选条件这里用SPR算不出来,不知道哪里问题,尝试了好几种方式,returned读取不了。暂不解决,后续用收益比作为指标去筛选股票。最终结果如图:
