【计组学习笔记】2.数据的表示和运算
1. 真值(非逻辑学中的真值),机器数,原码、反码、补码、移码这几个概念被提出的根本原因是:计算机需要一套合理的规则来表示负数
真值是指带了+或-的数,即把一个数的正负性用符号表示,与进制无关,也就是说不仅有十进制真值,而且有“二进制真值”甚至“十六进制真值”等概念,真值是方便人类理解和计算的感受值
机器数是把一个数的正负性同样用数字表示,包括原码反码补码移码,因为是“机器”数,所以通常是二进制,注意:这四个概念都是相对于真值而言的,即“原码”指的是真值的“原码”,反码指的是真值的“反码”,补码指的是真值的“补码”,移码指的是真值的“移码”。没有“原码的反码”,“原码的补码”,“补码的移码”这种概念,严格来讲应该是“原码所对应真值的反码”……这样的强调是有必要的,否则可能会出现“既然原码的反码是反码,那么反码的反码就是原码本身”这样的错误想法
2. 切记一条:原反补移是相对于有符号数的概念,对于无符号数没有这四种表示码,并且在有符号数里面:正数的原码补码反码是一模一样的,无需进行变换,但是移码不一样,它依然是对补码的首位取反
3. 总结一下纯整数、纯小数、整数小数混合数的加减法规则:

纯整数:
无符号整数:
加法:操作数1+操作数2,逐位相加即可
减法:(只能大数减小数):操作数1-操作数2,把操作数2全部按位取反,末位加 1,然后操作数1+新的操作数2即可
带符号整数:(有了原反补的概念,在说“加”“减”的时候注意区分是对哪一种码):
加法:
两补码相加:逐位相加即可,所得仍为补码
两原码相加:先把两数转补码,再按上面方法相加,可以选择把所得补码结果重新转回原码表示,注意此时如果补码结果为1000……,则不能再转回原码表示,因为此时所得的正确真值为-2^n,是原码无法表示的一个数,强行转回去只会得到错误真值-0
其他编码均先表示成原码或补码后再按上面的方法计算
减法:
两补码相减:操作数2全部按位取反,末尾加1,然后逐位相加,所得仍为补码
两原码相减:先把两数转补码,再按上面方法相减,可以选择把所得补码结果重新转回原码表示,注意此时如果补码结果为1000……,则不能再转回原码表示,因为此时所得的正确真值为-2^n,是原码无法表示的一个数,强行转回去只会得到错误真值-0
其他编码均先表示成原码或补码后再按上面的方法计算
纯小数:与纯整数一模一样
整数小数混合数:先算整数部分,再算小数部分,二者运算结果转成真值后相加合并,然后再转为想要的形式(原反补移)
4. 逻辑移位和算术移位:
二者都是全移,是的,每一位都要移,带符号数的符号位也要移
二者的区别不在于移动哪些位,而在于逻辑上把机器数当做有符号数还是无符号数来移动,这种区别体现在物理上就是移位后添加数字的规则不一样。逻辑移位为左右无脑添0,算术移位为第11条所总结的表格所示
5. 标志位生成: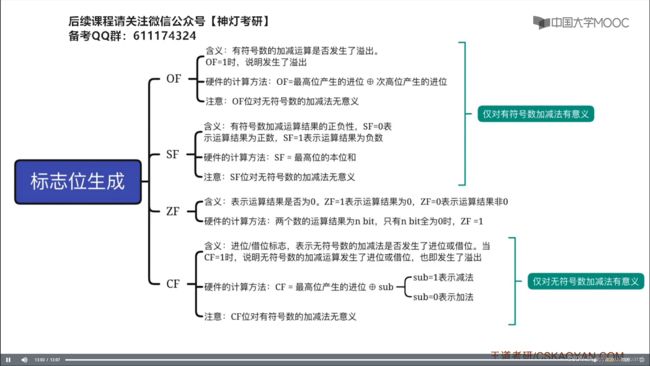
用人话总结:标志位仅仅在加减运算中才生成,在乘除运算或移位运算中不生成(可这么理解),并且四种标志位的计算生成和有无符号、加法还是减法没有关系,但是表示的含义和这些有关
OF:当且仅当最高位产生进位和次高位产生进位不同时才发生溢出(带符号数),溢出时OF=1
SF:最高位本位和,用以判断有符号数的正负性
ZF:当且仅当运算结果全0时结果运算结果才为0,此时ZF为1
CF:若为减法,则最高位不产生进位就溢出;若为加法,则最高位产生进位就溢出(无符号数)(这里的加法和减法指的是原来的计算逻辑,因为变换过后进入加法器的肯定是加法)
6.
| 数据类型 | 操作类型 | 溢出条件 | |
| 常规方法 | 双符号位法 | ||
| 不带符号 | 加减 | (运算后)CF=1 | / |
| 左移 | (运算前)最高位=1 | / | |
| 带符号 | 加减 | (运算后)OF=1 | (运算后)两符号位不等 |
| 左移 | (运算前)数值最高位≠符号位 | ||
有关溢出检测的总结:
(1)什么是溢出?
答:溢出是在符合规则进行机器操作以后得到的真值与正确的真值不符的现象。逻辑本质是计算后的真值落在了表示区间以外,物理本质是高位截断。
(2)溢出可以解除吗?
答:不可以,溢出是由于输入的操作数不合法导致的,和机器算法无关,想要得到正确的结果只能扩充数据表示范围,即增加为结果分配的位宽(部分乘除法电路就是这么做的)
(3)溢出如何检测?
答:
(4)对上表的补充解释:
1)可以看到溢出条件的判断分为“运算前”和“运算后”两种方式,其中机器只会使用“运算后”判断的方式,而“运算前”就判断的方式一般是人眼去识别,在做题的时候可以用到
2)双符号位判断法背后的原理本质上使用的还是常规方法,只不过由于这种实现方式在硬件上有着诸多的好处,所以计算机可以采用这种方式判断溢出
3)在加减法中使用双符号位是为了溢出检测,但在乘除法中使用双符号位就纯粹是因为寄存器正好有一位多出来不用而已(至少在目前的知识下是这样)
4)暂时不讨论乘除法和右移,因为乘除有时候会通过扩充位宽来表示数据,右移相当于除以2,真值不可能溢出,只有可能丢失精度
5)我目前觉得移位操作没有“进位”这个概念
7. 原码除法从恢复余数法到加减交替法的演化过程可用流程图表示如下:
8. 小心强制类型转换中的补码,因为强转后数据类型变了(有符号变无符号或无符号变有符号),那么不止是真值的解释方式变了,还有补码和原码之间的转换方式也就变了,因此,发生强转前后只有补码是一定不变的,但是原码是可能会发生改变的
9. “地址”和“首地址”指该元素在地址空间中的最低地址的地址值,两个概念都和大端存储还是小端存储无关
10. “小端”指基本数据类型的各部分之间为小端(即低位低址),最小编址单元内(一般是按字节编址)始终是正常的大端排序;“大端”则不过多解释
11. 不同机器数算术移位后的空位填补规则:
| 码制 | 添加代码 | |
| 正数 | 原码、补码、反码 | 0 |
| 负数 | 原码 | 0 |
| 补码 | 左移添0 | |
| 右移添1 | ||
| 反码 | 1 |
12. 字节对应位数技巧:
二进制下8位对应1个字节,如:1011 1011
十六进制下2位对应1个字节,如:FC
2,4,8,16进制快速转换技巧:
十六进制转二进制:每1个十六进制位对应4个二进制位,如D=1101
二进制转十六进制:每4个二进制位对应1个十六进制位,如1111=F
13. 强转问题中的坑:

注意点:1.强制类型转换只能在补码间直接发生;2.在不同类型下,原码和补码的转换规则可能不同,这是最常考察的一个点,在真题中反复出现;3.在不同类型下,真值和原码的转换,也即解释规则可能不同,但这个不太容易出错
14. 字长,机器字长,存储字长,编址,寻址,边界对齐
机器字长:CPU进行一次整数运算所能处理的二进制数据的位数
存储字长:一个存储单元中二进制代码的位数(通常和MDR位数相同)
机器字长是相对于CPU来说的,存储字长是相对于内存对其存储单元(也即编址单元,这两是同义词)包含有多少个bit的划分,如32位存储字长表示一个存储单元有32位,但是每个地址依然是对应一个字节也即8位bit
机器字长≥存储字长,可以这么理解:CPU希望自己一次取出来的数据可以有冗余,但不要有缺少,其中冗余和缺少的标准是存储字长
编址:按XX编址指内存把XX大的空间作为一个编址单元(非存储单元),即连续地址空间中每个值的唯一对应项,如按字节编址是指地址号0001H到地址号0002H之间有1个字节即8bit的空间,再如按字编址(假设存储字是32位)指的是地址号0001H到地址号0002H之间有1个存储字即32位的空间。现代计算机一般都采用按字节编址
寻址:指CPU
边界对齐指的是对齐存储字
15.
16. 在浮点数中时刻保持对真值和机器数的区分
规格化的结果:让尾数部分最高位为非0的有效数字
规格化的目的:尽可能的压缩浮点数的存储,使其能表示更大范围的数据
规格化:规格化本质上是对尾数的真值进行的调整
| 已规格化的标志(r=2) | |
| 真值 | 小数点后第1位=1 |
| 原码 | 小数点后第1位=1 |
| 反码 | 小数点后第1位≠符号位 |
| 补码 | 小数点后第1位≠符号位 |
IEEE754标准:一种特殊的规格化标准,隐藏1的说法就是来源于此标准,float和double的格式也由这个标准定义,牢记float的1/8/23和double的1/11/52
17. N=M*r^E
这是浮点数真值的普遍计算公式,不是IEEE754特有,在这个公式中,N,E,M皆为真值,N为浮点数表示的真值,E为阶码(无关用什么进制的什么码表示)对应的真值,M是尾数(无关用什么进制的什么码表示)对应的真值,而在王道书给出的IEEE754题目的相关计算中,E和M的意义会有所不同,这点需要注意。
18. IEEE754标准下,float、double浮点数(规定里都是E为补码,M为原码)在机器数、二进制真值、十进制真值之间的转换方法:
首先辨析一个概念“尾数”,对同一个真值+1.10111,在IEEE754中,真值概念下的尾数指的是1.10111,而“尾数”如果指的是机器码(也即“尾数”等价于M),那尾数仅仅指10111这五个二进制数,也就是实际存到机器里面的数M
下面说明IEEE754机器数、二进制真值、十进制真值之间的转换方法:
(核心)二进制真值转机器数:
以+0.0101为例
Step1:先把真值写成1.M的形式(即所谓“规格化”),与此同时为后面加上合适的2^E,本例中原真值+0.0101修改为新的真值形式+1.01*2^-2
Step2:表示阶码移码,首先阶码真值E=-2,则阶码移码=(阶码真值E+偏置值)->看做无符号数转成二进制,这是最快的求阶码移码的方法,普通方法还有阶码真值E->阶码原码->阶码补码->阶码移码,本例中阶码移码=01111101
Step3:表示尾数原码,截取小数点后面部分即可,本例中尾数原码=01
Step4:表示数符位并合并,原数是正数,数符位=0,本例中最终形式为0 01111101 01……再补21个0
十进制真值转机器数:
先把十进制真值写成二进制真值,再按上面方法转
Step1:转二进制真值,整数部分和小数部分分开转,整数部分采用除基取余法(或拼凑法),小数部分采用乘基取整法(有可能取不尽,最后还要考虑舍入方法,常见的舍入方法有“1进0丢”法和“恒置1”法)
Step2:按二进制真值转机器数的方法即可
(核心)机器数转二进制真值:
以0 01111101 01……再补21个0为例,二进制真值应为+/- 1.M *2^E ,所以问题变成了由机器码求符号还有M和E
Step1:求E,根据公式阶码移码=(阶码真值E+偏置值)->看做无符号数转成二进制,先把阶码移码部分看做无符号整数,写出对应真值,如01111101看做unsigned int对应的真值应该是125,然后让该真值-偏置值即可得到E,如125-127=-2,则E=-2
Step2:求M,后面的部分就是M,即01……再补21个0
Step3:求真值符号并合并,显然真值符号为+,于是最终得到转换后的二进制真值+1.01*2^-2
机器数转十进制真值:先把机器数转成二进制真值,再按上面方法转
补充:
- 偏置值的求法:偏置值=2^(阶码位数-1)-1,其中“阶码位数”含符号位
- 一般浮点数的转换和上述方法类似,不同的是一般浮点数不默认有隐藏位,由此导致转换方法会有一丢丢的区别:
- 真值转机器数时,先把真值写成0.M*2^E(区别于IEEE754中写成1.M*2^E),然后偏置值=2^(阶码位数-1)
- 机器数转真值时,偏置值也是用2^(阶码位数-1)反求出阶码真值E,最后再写成0.M*2^E的形式
19. 定点数和浮点数的概念的相对辨析:
定点数的“定”是确定的定,指的是小数点位置“确定,就在符号位后面紧跟着”,浮点数的“浮”指的是不确定,是说仅凭尾数的信息不足以确定小数点位置。对一个确定的浮点数来说,它的小数点位置是唯一的而非可变的。
20. 舍入是相对浮点数右移的概念,定点数中没有舍入这个概念。而浮点数右移又包括右规和对阶这两种情况
21. 强制类型转换中的溢出和舍入和精度丢失问题的总结:
先贴两条绝对不会有任何问题的转换链(32位机器):char->int->long->double和float->double,可以越级转,如char->long,int->double
int->float:不会溢出
| 溢出 | 舍入 | 丢失精度 | 不出问题所需的条件 | |
| int->float | 不可能 | 不可能 | 可能 | int的有效区间不超过24位(防丢失精度) |
| int->double | 不可能 | 不可能 | 不可能 | / |
| float->int | 可能 | 可能 | 可能 | 没有小数部分(防舍入即丢失精度) 并且真值在[-(2^31-1),+(2^32-1)]内(防溢出) |
| float->double | 不可能 | 不可能 | 不可能 | / |
| double->int | 可能 | 可能 | 可能 | 没有小数部分(防舍入即丢失精度) 并且真值在[-(2^31-1),+(2^32-1)]内(防溢出) |
| double->float | 可能 | 可能 | 可能 | 尾数的有效区间不超过24位(防舍入即丢失精度) 真值不超出float能表示的范围(防溢出) |
总结:(1)任何数转double都是100%安全,double转任何数都可能发生溢出或舍入
(2)无论int转float还是float转int都不是一定安全
(3)int->double->int和float->double->float也是安全的,因为由int而来的double再转回int不会因为表示范围不够而溢出,也不会因为有效位数截断而丢失精度,float同理
22. 对于浮点数的加减运算(其实各种码的加减运算和乘除运算也一样),在选择题中有一个技巧就是——全部转成真值后计算,最后再转回对应格式的码
23.
| 尾数 阶码 |
全0 | 非全0 |
| 全0 | +0和-0,+/-取决于符号位 | 非规格化数 需要看做一般浮点数求真值 (用第18条补充里的方法) |
| 全1 | 正无穷或负无穷,取决于符号位 | 非数NaN |
| 非全0非全1 | 规格化非0数 | |
24. 0b前缀是说明这段数字是二进制
25. 原码和反码仅用于表示,不能实际操作,因为在计算机内部所有带符号数都是以补码的形式存放的,但是补码转原反码的过程中并不是完全对应的(存在+/-0和1000转不过去的现象),因此所以对带符号数的操作最好先转成补码实现,算完了再转回去
26.