java中什么是 伪共享_【Java】聊聊多线程中的伪共享现象
首页
专栏
java
文章详情
0
聊聊多线程中的伪共享现象
小强大人发布于 1 月 27 日
什么是伪共享?
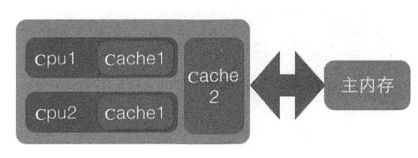
讲伪共享之前,让我们先乘坐时光机,回到大学课堂,来重温下计算机组成原理的基础知识。我们知道,CPU和内存的运行速度相差很大,为了解决这个问题,在CPU和内存之间会加一级或多级高速缓存(Cache)。这个Cache一般是集成在CPU内部的,所以也叫CPU Cache。下图是一个两级Cache的CPU-Cache-内存架构。
数据在Cache中是按行存储的,其中每一行称为一个Cache行,如下图所示。它是CPU与内存数据交换的基本单位。Cache行的大小一般为2的幂次字节数。

CPU-Cache-内存架构的工作原理是这样的:当CPU访问某个变量时,首先会从CPU Cache里查看是否有该变量,如果有直接获取并返回,否则从内存中获取,然后把该变量所在内存区域的一个Cache行大小的内存数据复制到Cache中,这就是我们所说的局部性原理。由于存放到Cache行的不是单个变量,而是一个内存块数据,所以会出现多个变量放在一个Cache行中。当多个线程同时修改同一个缓存行里面的不同变量时,由于同一时刻只允许一个线程操作缓存行,一个线程成功获取缓存行的修改权时,其他线程会互斥等待,并且由于缓存一致性协议,其他线程相应的缓存行会失效,需要重新从内存获取数据,这无疑耗费了更多时间。所以相比把每个变量放在不同的缓存行,性能反而有所下降,这就是伪共享现象。
如下图所示,变量x,y放在同一个缓存行中,线程1操作缓存行的x变量,线程2操作y变量。

如何避免伪共享呢?
在JDK1.8之前,通常是通过字节填充的方式。什么意思呢?就是用到一个变量时,补充额外的若干辅助变量,使得这些变量刚好填充满一个缓存行,这样就避免了多个变量存放在一个缓存行中。具体看下面示例代码:
static final class PaddedLongField {
public volatile long value = 0L;
public long p1,p2,p3,p4,p5,p6;
}
假如CPU Cache行大小为64字节,那么我们这里填充了6个long型的变量,每个long型变量占8个字节,加上value一共7*8=56字节,另外,别忘了PaddedLongField是一个类对象,对象头还要占用8个字节,所以一个PaddedLongField对象占用64个字节,刚好填充满一个缓存行。
在JDK1.8之后,提供了一个@sun.misc.Contended注解,用来解决伪共享问题。此时,我们上面的代码就可以简化了:
@sun.misc.Contended
static final class PaddedLongField {
public volatile long value = 0L;
}
@Contended注解不仅可以修饰类,也可以修饰变量:

JUC源码里很多使用这个注解的,比如Thread类里threadLocalRandom相关的变量:

再比如LongAdder内部用到的Cell也用了这个注解:

再比如ForkJoinPool类上面也修饰了:

最后需要注意下,@Contended注解默认只用于Java核心类,比如rt.jar下的类。如果我们应用程序中想使用这个注解,需要添加一个JVM参数:-XX:-RestrictContended,填充的默认宽度为128字节,若需自定义宽度则可以用另一个参数:-XX:ContendedPaddingWidth=xxx
本文就到这里啦,若这篇文章对你有所帮助的话,点个赞再走叭!谢谢支持!
参考资料:
《Java并发编程之美》
java
阅读 53更新于 1 月 27 日
赞收藏
分享
本作品系原创,采用《署名-非商业性使用-禁止演绎 4.0 国际》许可协议
小强大人
9声望
1粉丝
关注作者
0 条评论
得票时间
提交评论
小强大人
9声望
1粉丝
关注作者
宣传栏
▲
什么是伪共享?
讲伪共享之前,让我们先乘坐时光机,回到大学课堂,来重温下计算机组成原理的基础知识。我们知道,CPU和内存的运行速度相差很大,为了解决这个问题,在CPU和内存之间会加一级或多级高速缓存(Cache)。这个Cache一般是集成在CPU内部的,所以也叫CPU Cache。下图是一个两级Cache的CPU-Cache-内存架构。
数据在Cache中是按行存储的,其中每一行称为一个Cache行,如下图所示。它是CPU与内存数据交换的基本单位。Cache行的大小一般为2的幂次字节数。
CPU-Cache-内存架构的工作原理是这样的:当CPU访问某个变量时,首先会从CPU Cache里查看是否有该变量,如果有直接获取并返回,否则从内存中获取,然后把该变量所在内存区域的一个Cache行大小的内存数据复制到Cache中,这就是我们所说的局部性原理。由于存放到Cache行的不是单个变量,而是一个内存块数据,所以会出现多个变量放在一个Cache行中。当多个线程同时修改同一个缓存行里面的不同变量时,由于同一时刻只允许一个线程操作缓存行,一个线程成功获取缓存行的修改权时,其他线程会互斥等待,并且由于缓存一致性协议,其他线程相应的缓存行会失效,需要重新从内存获取数据,这无疑耗费了更多时间。所以相比把每个变量放在不同的缓存行,性能反而有所下降,这就是伪共享现象。
如下图所示,变量x,y放在同一个缓存行中,线程1操作缓存行的x变量,线程2操作y变量。
如何避免伪共享呢?
在JDK1.8之前,通常是通过字节填充的方式。什么意思呢?就是用到一个变量时,补充额外的若干辅助变量,使得这些变量刚好填充满一个缓存行,这样就避免了多个变量存放在一个缓存行中。具体看下面示例代码:
static final class PaddedLongField {
public volatile long value = 0L;
public long p1,p2,p3,p4,p5,p6;
}
假如CPU Cache行大小为64字节,那么我们这里填充了6个long型的变量,每个long型变量占8个字节,加上value一共7*8=56字节,另外,别忘了PaddedLongField是一个类对象,对象头还要占用8个字节,所以一个PaddedLongField对象占用64个字节,刚好填充满一个缓存行。
在JDK1.8之后,提供了一个@sun.misc.Contended注解,用来解决伪共享问题。此时,我们上面的代码就可以简化了:
@sun.misc.Contended
static final class PaddedLongField {
public volatile long value = 0L;
}
@Contended注解不仅可以修饰类,也可以修饰变量:
JUC源码里很多使用这个注解的,比如Thread类里threadLocalRandom相关的变量:
再比如LongAdder内部用到的Cell也用了这个注解:
再比如ForkJoinPool类上面也修饰了:
最后需要注意下,@Contended注解默认只用于Java核心类,比如rt.jar下的类。如果我们应用程序中想使用这个注解,需要添加一个JVM参数:-XX:-RestrictContended,填充的默认宽度为128字节,若需自定义宽度则可以用另一个参数:-XX:ContendedPaddingWidth=xxx
本文就到这里啦,若这篇文章对你有所帮助的话,点个赞再走叭!谢谢支持!
参考资料:
《Java并发编程之美》