详解机器视觉性能指标相关概念——混淆矩阵、IoU、ROC曲线、mAP等
目录
0. 前言
1. 图像分类性能指标
1.1 混淆矩阵(Confusion Matrix)
1.2 准确率(Precision)
1.3 召回率(Recall)
1.4 F1值(F1 score)
1.5 ROC曲线(接收者工作特征曲线,Receiver Operating Characteristic curve)
1.6 mAP(mean Average Precision)
2. 图像分割性能指标
2.1 交并比(IoU, Intersection over Union)
2.2 准确率(Precision)&召回率(Recall)&F1值(F1 score)
2.3 Dice系数(Dice coefficient)
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文将通过实例系统性说明机器视觉性能相关指标。关于这些指标内容我大体分为2类:图像分类性能指标和图像分割性能指标。
1. 图像分类性能指标
这类指标用于评估模型对图像分类的准确性:能将图像中的对象正确地划分到对应的分类中的比例、漏识别的比例、错误识别的比例等。
1.1 混淆矩阵(Confusion Matrix)
混淆矩阵是这类性能指标的基础。混淆矩阵是有监督学习中用来评估分类模型在测试数据集上的预测能力的一种评估方式。混淆矩阵是一个二维矩阵,其中每一行表示实际标签,每一列表示预测标签。
混淆矩阵的四个基本指标是真阳性(True Positive,TP)、假阳性(False Positive,FP)、真阴性(True Negative,TN)和假阴性(False Negative,FN),分别表示被正确分类的正例、被错误分类的正例、被正确分类的反例和被错误分类的反例的样本数。
下面通过实例来讲解混淆矩阵:假设我们有一个深度学习模型用来识别图像中是否有奥特曼,我们有下面9个测试样本,经过深度学习模型识别后输出如下:
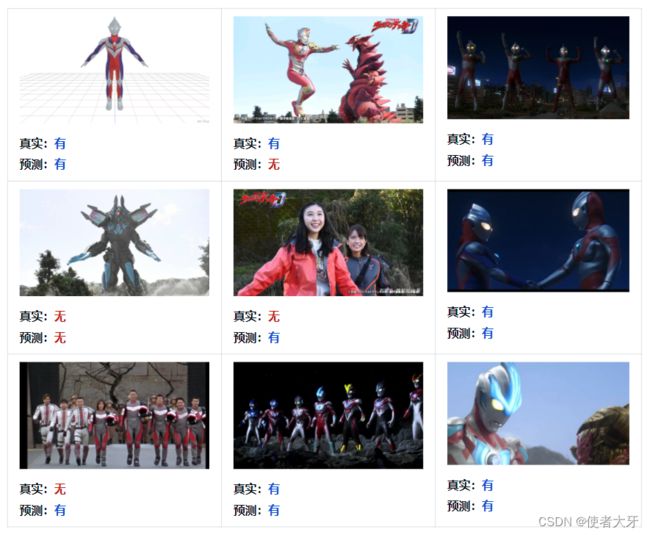
可见,上述4个指标的对应个数分别为:
- TP(模型预测有奥特曼,真实也有奥特曼):5
- TN(模型预测无奥特曼,真实也无奥特曼):1
- FP(模型预测有奥特曼,但实际无奥特曼):2
- FN(模型预测无奥特曼,但实际有奥特曼):1
这样对应混淆矩阵为:
| 判断奥特曼的混淆矩阵 | 真实类别 | ||
| 是 | 否 | ||
| 预测类别 | 是 | 5(TP) | 2(FP) |
| 否 | 1(FN) | 1(TN) | |
上面虽然是用二分类问题(是否问题、有无问题)来举例,但是混淆矩阵也可以扩展用于多分类问题,例如判断图像中的迪迦奥特曼、泰罗奥特曼、赛文奥特曼等。
| 判断奥特曼的混淆矩阵 | 真实类别 | ||||
| 迪迦 | 泰罗 | …… | 赛文 | ||
| 预测类别 | 迪迦 | ||||
| 泰罗 | |||||
| …… | |||||
| 赛文 | |||||
1.2 准确率(Precision)
准确率的数学定义为:
![]()
准确率描述的是:如果模型输出为“是”,实际有多少比例真实为“是”,即模型预测的准不准。
1.3 召回率(Recall)
召回率的数学定义为:
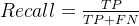
召回率描述的是:如果实际都为“是”,模型有多少比例能输出为“是”,即模型预测的全不全。
1.4 F1值(F1 score)
F1值的数学定义为:
![]()
代入上面Precision和Recall的公式可以化简为:
![]()
F1值是一种综合了模型的精度和召回率的评估指标。它是精度和召回率的调和平均值,因此在评估二元分类器时更加全面和准确。在模型选择、参数调优和结果解释等方面都具有重要的参考意义。同时,F1 score也可以用于比较不同模型或算法的性能,以便选择最优模型或算法。
1.5 ROC曲线(接收者工作特征曲线,Receiver Operating Characteristic curve)
这个指标有点复杂。。。
首先,ROC曲线横坐标为假阳性率FPR(False Positive Rate),FPR=FP/(FP+TN)。纵坐标为真阳性率TPR(True Positive Rate,即为Recall),TPR= Recall= TP/(TP+FN)。
然后再回到上面奥特曼的实例:我们需要知道,深度学习网络对于分类问题的输出并非“有”或“无”,而是一个0~1的置信概率。
如果我们设定一个阈值,比如模型计算输出有奥特曼的置信概率在0.6以上,我们才认为模型判断是“有”奥特曼,上面的示例应该变成这样:

显然,如果我们调整这个判断阈值,预测结果“有”或“无”就可能会发生变化,那么FPR和TPR就有可能都会变更,这样就有了一个新的点坐标(FPR,TPR)。
如果我们把所有的(FPR,TPR)都在坐标中描出来,并按顺序连接起来,就得到了ROC曲线。
特别地,如果我们把阈值设定为0,即模型输出的所有结果都为“有”,这时TN=FN=0,(FPR,TPR)=(1,1);如果把阈值设定为1,即模型输出的所有结果都为“无”,这是TP=FP=0,(FPR,TPR)=(0,0)。这样我们就知道ROC曲线肯定是在(0,0)和(1,1)这两点之间。例如下图:
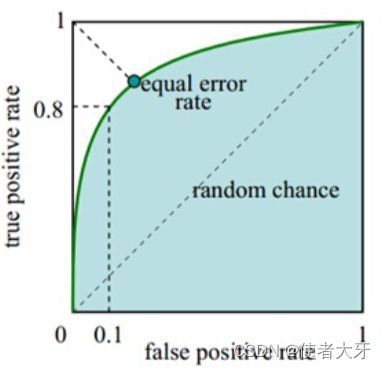
ROC曲线的斜率和凸度反映了分类器的预测性能,ROC曲线越靠近左上角则分类器的性能越好。此外,ROC曲线下的面积AUC(Area Under the ROC Curve)也是一个常用的指标,AUC值越大表示分类器的预测性能越好,AUC值为1表示分类器的预测完全准确。
1.6 mAP(mean Average Precision)
中文咋翻译。。。平均平均精度?
首先需要介绍一下AP。我们按上面ROC的制作思路再制作一条曲线:其横坐标为Recall,纵坐标为Precision。这次我们调整的阈值不再是置信概率,而是IoU(或者说IoU本身也可以算作一种置信概率,下面会有介绍)。
通过调整IoU由0到1,我们获得多个坐标点(Recall,Precision)并依次连线,得到下面的Precision-Recall曲线:
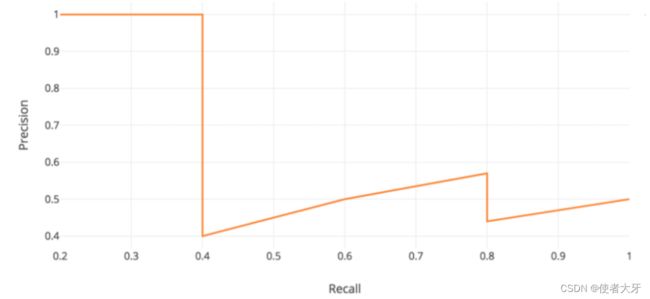
对这条曲线进行积分即为AP:
![]()
如果我们要识别的对象有多种(迪迦奥特曼、泰罗奥特曼、赛文奥特曼等),那我们就会有多个AP,对其求均值即为mAP。
ROC曲线用于评估二分类器的性能,而mAP(mean Average Precision)是目标检测任务中的一个重要指标,用于评估模型对多个类别目标检测的精度。
2. 图像分割性能指标
这类指标是用于评估图像分割的准确性:能准确分割目标图像,描述预测对象位置和实际位置的差距。
我们还举一个奥特曼的例子:
这里蓝色框A是奥特曼的真实位置,已事先标注出来。红色框B是模型给奥特曼分割的边界。
2.1 交并比(IoU, Intersection over Union)
IoU是预测区域和真实区域的交集和并集的比:
![]()
mIoU(Mean Intersection over Union)是对所有类别的IoU计算平均值,用于评估多分类分割模型的表现。
2.2 准确率(Precision)&召回率(Recall)&F1值(F1 score)
这3个指标和上面分类问题的定义思路一样,所以一起来讲,其数学定义为:
![]()
![]()
![]()
2.3 Dice系数(Dice coefficient)
Dice系数是预测区域和真实区域的交集与两者加和的比:
![]()