5分钟入门卷积算法
大家好啊,我是董董灿。
深度学习算法中,尤其是计算机视觉,卷积是无论如何都绕不过去的槛。
初学者看到这个算法后,很多是知其然不知其所以然,甚至不知道这个算法是做什么的,或者很疑惑,为什么在处理图像任务的神经网络中需要卷积算法?
1、 为什么需要卷积
在说卷积之前,先说一说一个神经网络(或者叫一个AI模型),是如何完成一张图片的推理的。
你肯定听说过大名鼎鼎的阿尔法狗大战柯洁的故事,但是,你有没有想过一个问题:阿尔法狗学会了下棋,但是它下棋的记忆到什么样的?存在什么地方呢?
高中生物老师教过我们,人脑中有大量的脑神经元。每个脑神经元都可以看做是一个小的记忆体,神经元之间通过树突连接起来,整个大脑的神经元,可以说是一张十分复杂的网络。
人脑处理信息,就是利用这个复杂的网络处理信息,并最终得到一个结果。通过神经元网络,我们才能知道,眼睛看到的是一只猫,还是是一只狗。
稍微简化一下大脑神经元的复杂结构成如下的网络。
每个黑点代表一个神经元脑细胞,每个神经元都有自己负责记忆的东西。
当我们看到一张画着猫的图片的时候,图片信息通过视神经传给大脑神经元,于是,信息到达了最左边一排竖着的黑点(神经元)。
神经元的激活
假如一个黑点(神经元)之前见过猫,那么这个黑点就会把信息往后传,此时神经元处于激活状态。
假如一个黑点从来没见过猫,那么这个黑点(神经元)就啥也不知道,啥也不做,此时神经元处于静止状态。
一张画着猫的图片的信息,就这样一层一层地通过“见过猫且确信它是一只猫的”神经元往后传递,直到在最后输出一个结果。
这是一只猫。

这个过程叫做大脑的推理。
整个推理过程你应该注意到了一件事,所有的黑点都可能是有记忆的,只不过记得东西各有不同,有的认识猫,有的认识狗,就像下面这样。
所有认识猫的神经元都会让信息通过,其他不认识猫的神经元都静止了。但是只要信息能传到最后,人脑最终就可以得出一个结论,这就是一只猫。
那神经元的这些记忆是怎么获取的呢?
训练,人们在日常生活中不断地训练大脑,时刻观察着周围的事物,见得多了,就会了。
训练获取记忆
人工智能计算机是怎么模拟这个记忆过程呢?
答案很简单:计算机只会计算,那就让它计算好了。
如果某个黑点认识猫,有什么办法可以把“这是一只猫”这一信息传递到后面呢?乘以1,任何数乘以1都是它自己,一只猫乘以1也还是他自己。
如果某个黑点压根没见过猫,有什么办法可以什么都不做呢?乘以0,任何数乘以0都是0,信息也就没了,一只猫乘以零,猫也就没了。
于是,在深度学习的网络中,每个黑点(神经元)都有一个与之对应的数字(实际的网络中,不是0或者1这样简单的数字,而是一些复杂的数字,这里仅仅是为了说明),这些数字,在深度学习中,我们称之为权值。
神经元通过权值的加权计算来判断是否让某一信息经过神经元,到达下一层。
权值乘以输入的信息(猫),然后经过激活函数去激活(类似于人脑神经元的激活)。
如果能成功激活,那么信息就往下传。
如果没有成功激活,信息就在此丢失。
当然神经网络中的权值不是简单的0或1,所以经过激活函数计算出来的只是一个概率值,也就是说黑点(神经元)觉得它是一只猫的概率。最终如果得到95%的概率觉的它是一只猫,那基本就是一只猫。
人脑看多了,就认识猫了,同样AI被训练的“看”多了,也会逐渐“认识”猫了。
AI的权值就是这么被训练出来的!
说到这,就说会今天的主角——卷积算法之所以重要,就是因为这个算法存在一个天然的记忆体,或者是权值矩阵,那就是卷积核。
2、卷积算法
深度学习中的卷积算法,模拟的就是人眼看物体的过程。
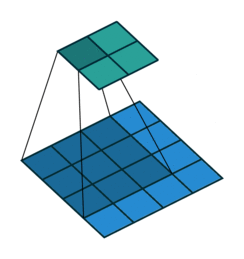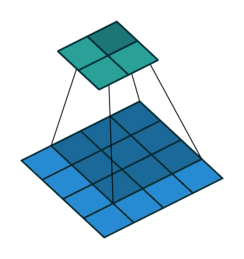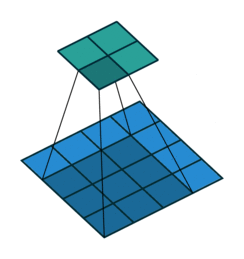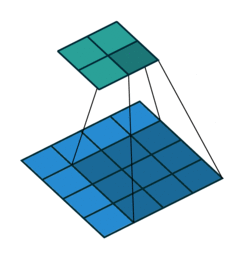
上图是深度学习中卷积的示意图,还记得之前说过的么,图片是由像素组成的(查看要学计算机视觉,先了解图像和像素)。
示意图下方的 4x4 的像素方格就是卷积算法需要处理的图片(类比于人眼观看的图片)。
示意图上方的 2x2 的像素方格就是卷积算法的输出(类比于人眼看完一张图片后的结果信息)。
4x4的方格上移动的灰色阴影,那个3x3的像素方格就是卷积核,可以把它理解为人眼此时聚焦看到的区域(称之为感受野,人眼的视野),只不过,这个示意图中每次看到的都是一个3x3的像素方格!
而卷积过程,就是用一个3x3的卷积核,去逐步扫描图片:横着扫完竖着扫,每扫一次,就将逐个像素点的值相乘然后加一起,得到一个输出,就像下面这样:
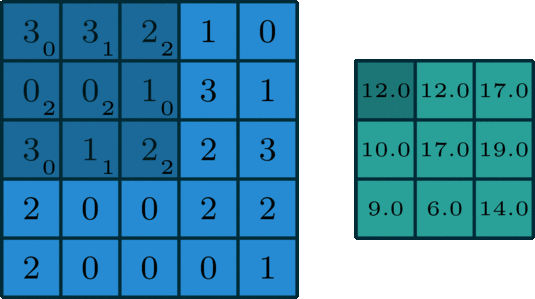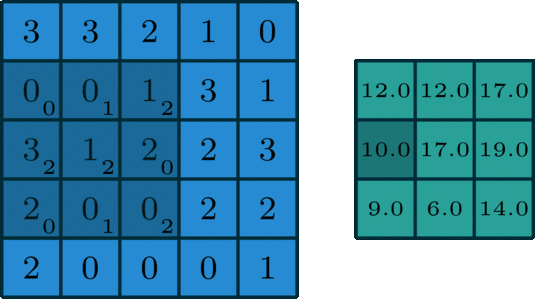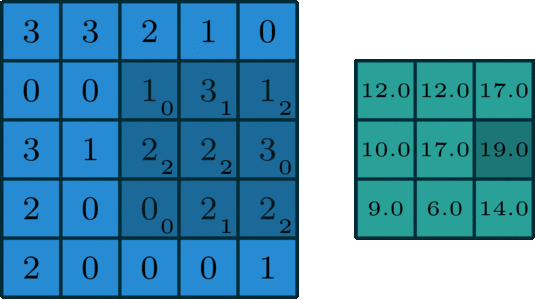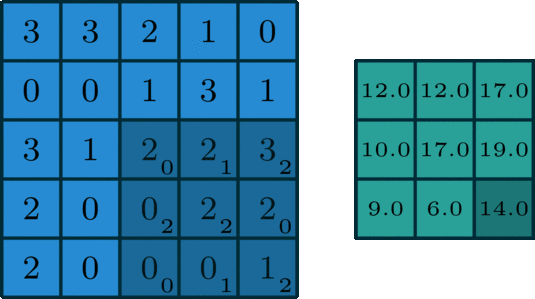
再换个更直观的角度看一眼。
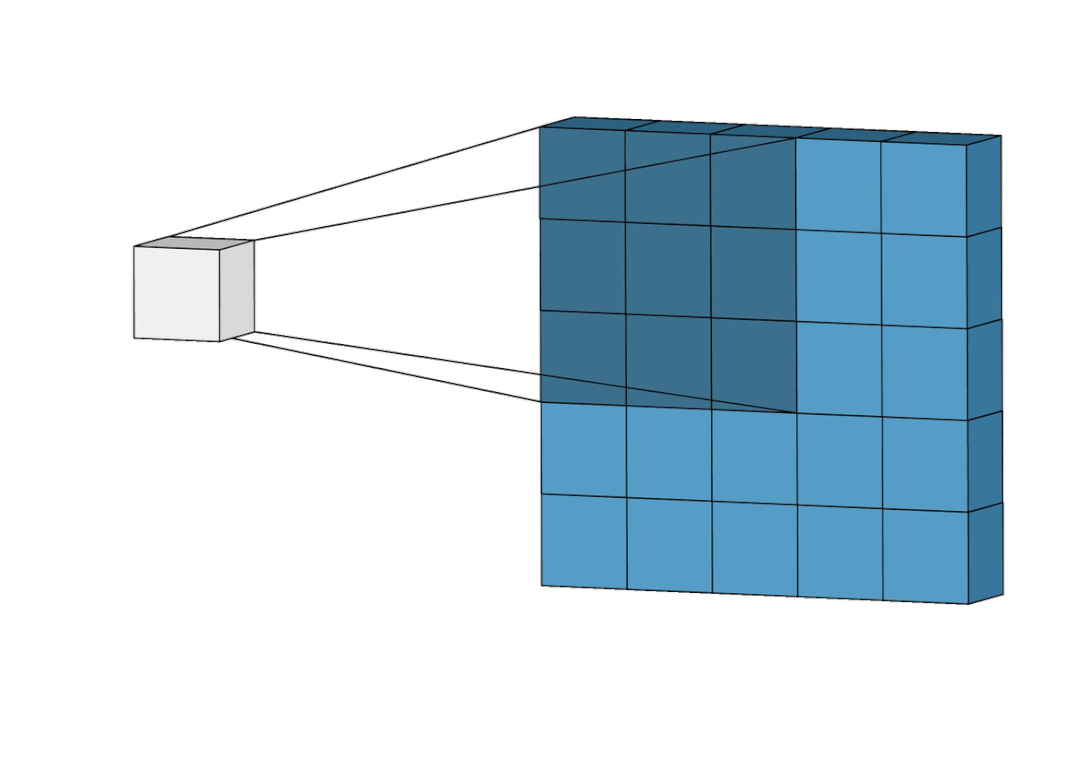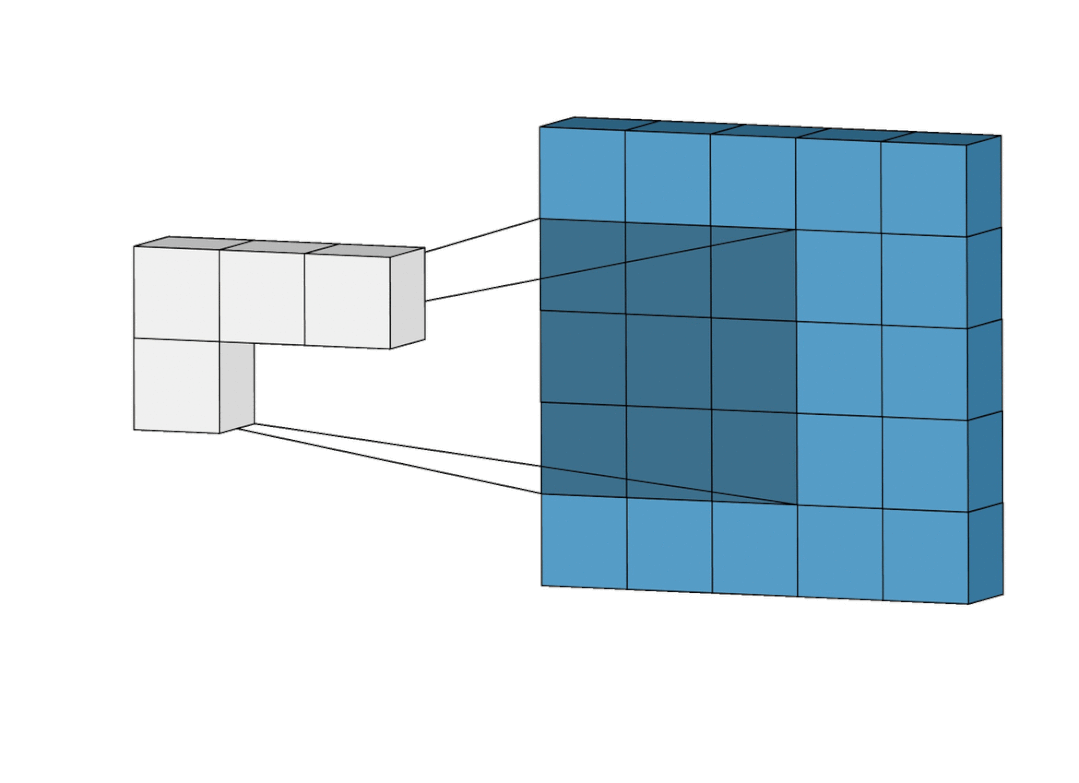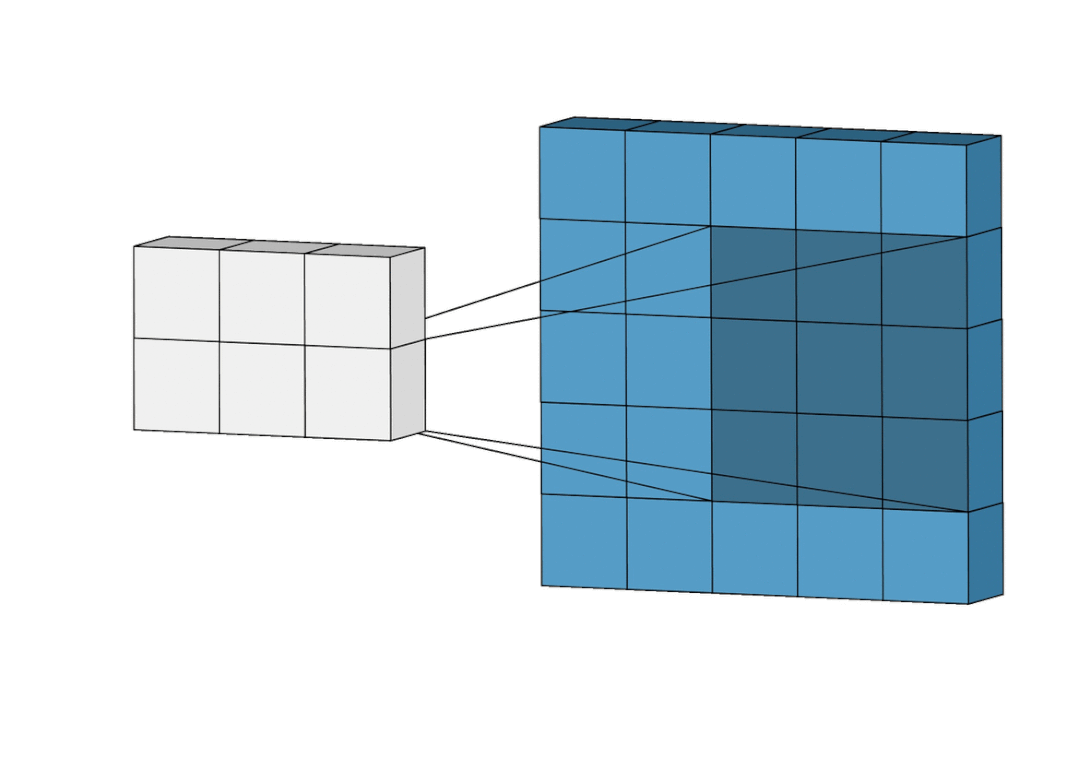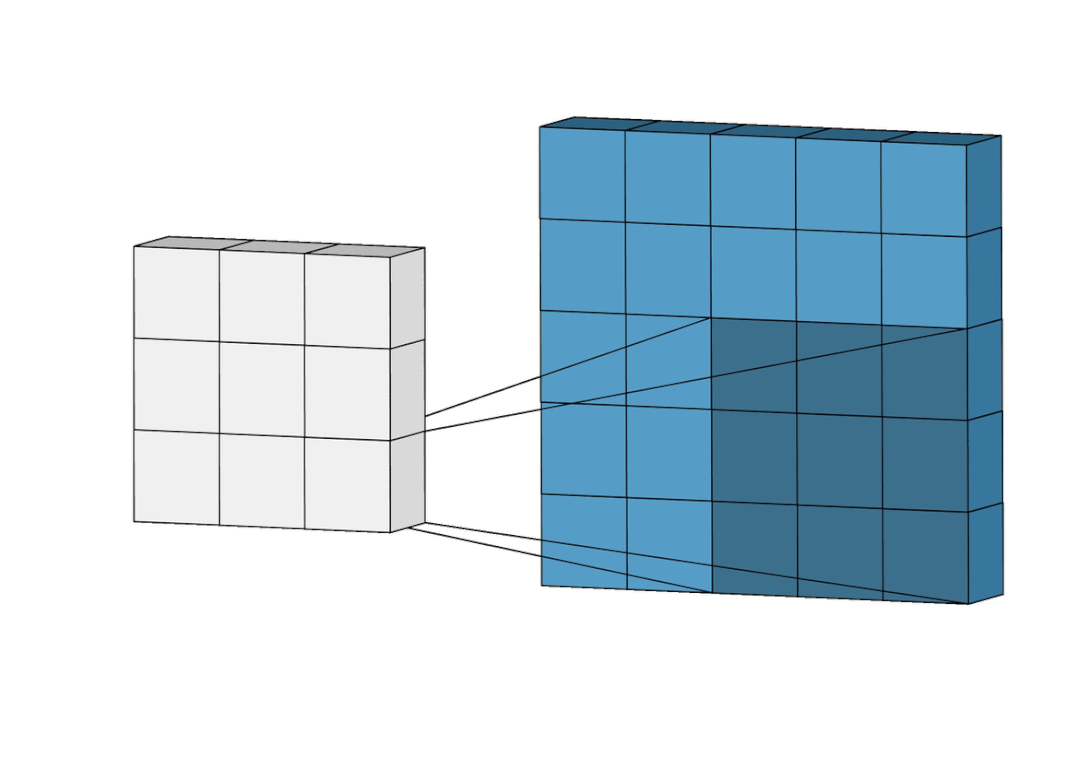
卷积,就是这么简单的过程。
我们可以通过调整卷积核的大小,比如把上图3x3的卷积核扩大到5x5,来控制 “人眼” 看到的图片范围,从而获取到不同尺度下的图片信息。
比如在一些检测车道线的神经网络中,由于车道线是长实线,车道线的存在趋近于长方形,因此在这类神经网络中,很多卷积核被设计成1x5或1x7的卷积核,用来更好的识别车道线的形状。
当然,在不同图像处理任务中,会设计不同大小的卷积核,以适应不同的场景序需求,但万变不离其宗,卷积的计算,就是一些模拟的人眼看物体扫描像素点的过程。
说到这,大概对卷积这一算法有一个初步印象了吧。