Docker学习一:Docker介绍
一、Docker是什么?
- Docker是一个开源的应用容器引擎,基于Go语言开发
- 应用开发者可以基于docker,将应用以及依赖打包到一个轻量级、可移植的容器中,然后部署到任意环境中
二、Docker的安装
这里仅介绍Docker在CentOS中的安装步骤。要安装Docker,需要CentOS 7及以上的版本。
1. 检查CentOS的版本
方法一:cat /etc/centos-release
方法二:cat /etc/system-release
方法三:cat /etc/redhat-release
2. 卸载旧版Docker
$ sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
3. 安装Docker
在线安装Docker
- 安装yum-config-manager工具和安装相关的存储驱动服务
$ sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
- 安装稳定版仓库
$ sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
- 安装最新版本的docker CE
sudo yum install -y docker-ce
- 安装制定版本的docker CE
# 先列出所有的版本
$ yum list docker-ce --showduplicates | sort -r
# 再安装指定版本,如:docker-ce-18.06.3.ce-3.el7
yum -y install docker-ce-18.06.3.ce-3.el7
- 启动docker
systemctl start docker
- 设置开机自启动
systemctl enable docker
- 检查docker是否安装成功
# 查看docker的版本
docker version
离线安装docker
- 下载二进制安装包,地址:https://download.docker.com/linux/static/stable/x86_64/
- 上传安装包到服务器上,执行解压命令
tar -zxvf docekr-xxx.tgz
- 进入docker目录复制所有文件到/usr/bin目录下,目的/user/bin是环境变量目录,在路径下都可以运行docker命令
cp docker/* /usr/bin
- 注册编辑docker服务
vim /etc/systemd/system/docker.service
# docker.service内容可参考:
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
LimitNOFILE=1048576
LimitNPROC=1048576
LimitCORE=infinity
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
#ExecStart=/usr/bin/dockerd --privileged=true --default-ulimit nofile=65536:65536 -H fd://
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
- 添加可执行权限
chmod +x /etc/systemd/system/docker.service
- 依次执行以下命令
systemctl daemon-reload #重新加载配置文件
systemctl start docker # 启动docker
systemctl enable docker.service # 设置开机自启动
- 检查docker是否安装成功
# 查看docker的版本
docker version
三、Docker核心概念
1. 镜像
镜像是一个只读的文件和文件夹组合,它包含了容器运行时所需要的所有基础文件和配置信息,是容器启动的基础。镜像是Docker容器启动的先决条件。
获取镜像的方式有两种:
- 自己制作镜像。通常情况下,一个镜像是基于一个基础镜像构建的(如:基于centos镜像),在基础镜像上可以添加一些用户自定义的内容,就可以做成自己所需求的镜像。
- 从镜像仓库拉取已有的镜像。可以在一些Docker仓库(如Docker Hub、Harbor等)拉取官方已经制作好的镜像,如:nginx、centos等。
2. 容器
容器是镜像的运行实体。镜像是静态的只读文件,而容器带有运行时需要的可写文件层,并且容器中的进出属于运行状态。容器是真正运行着的应用程序,它有初建、运行、停止、暂停和删除五种状态。
容器本质上是主机上运行着的一个进程,但容器有着自己独立的命名空间隔离和资源限制。容器内部无法看到主机上的进程、环境变量、网络等信息,这是容器与直接运行在主机上进程的本质区别。
3. 仓库
Docker镜像仓库类似于代码仓,用于存储和分发Docker镜像。镜像仓库分为公有镜像仓库和私有镜像仓库。
Docker Hub是Docker官方的公开镜像仓库,它不仅有很多应用或者操作系统的官方镜像,还有很多组织或者个人开发的镜像供我们免费存放、下载、研究和使用。
镜像、容器和仓库三者之间的关系可以参考以下图示:

镜像是容器的基石,容器是由镜像创建的。一个镜像可以创建多个容器,容器是镜像运行的实体。仓库是用来存放和分发镜像的。
四、Docker架构
容器技术随着Docker的出现变得炙手可热,除了Docker容器外,还出现啊了其他的容器技术,如:CoreOS的rkt、lxc等。随之而来的问题就是,容器技术的标准到底是什么?容器标准由谁来指定?
除了容器标准之争,当时的容器编排技术之争也是十分激烈。当时的三大容器编排技术:Docker Swarm、Kubernetes和Mesos围绕容器标准也产生了很大的矛盾。
这样的背景下,诞生了OCI(开放容器标准, Open Container Initiative),它是一个轻量级、开放的治理结构。OCI组织在 Linux 基金会的大力支持下,于 2015 年 6 月份正式注册成立。基金会旨在为用户围绕工业化容器的格式和镜像运行时,制定一个开放的容器标准。目前主要有两个标准文档:容器运行时标准 (runtime spec)和容器镜像标准(image spec)。
随着OCI标准的出现,Docker对自身的技术机构进行了改进,形成了下图所示的技术架构:

Docker 整体架构采用 C/S(客户端 / 服务器)模式,主要由客户端和服务端两大部分组成。客户端负责发送操作指令,服务端负责接收和处理指令。客户端和服务端通信有多种方式,既可以在同一台机器上通过UNIX套接字通信,也可以通过网络连接远程通信。
客户端
docker 命令是 Docker 用户与 Docker 服务端交互的主要方式。除了使用 docker 命令的方式,还可以使用直接请求 REST API 的方式与 Docker 服务端交互,甚至还可以使用各种语言的 SDK 与 Docker 服务端交互。目前社区维护着 Go、Java、Python、PHP 等数十种语言的 SDK,足以满足日常需求。
服务端
Docker 所有后台服务的统称。和一般的 C/S 架构系统一样,Docker 服务端模块负责和 Docker 客户端交互,并管理 Docker 的容器、镜像、网络等资源。
重要组件
Docker的组件非常多,这里只介绍几个关键的组件:dockerd、runC和containerd。
dockerd 是一个非常重要的后台管理进程,它负责响应和处理来自 Docker 客户端的请求,然后将客户端的请求转化为 Docker 的具体操作。例如镜像、容器、网络和挂载卷等具体对象的操作和管理。
runC是 Docker 官方按照 OCI 容器运行时标准的一个实现。通俗地讲,runC 是一个用来运行容器的轻量级工具,是真正用来运行容器的。
containerd是 Docker 服务端的一个核心组件,它是从dockerd中剥离出来的 ,它的诞生完全遵循 OCI 标准,是容器标准化后的产物。containerd通过 containerd-shim 启动并管理 runC,可以说containerd真正管理了容器的生命周期。
下图是三者之间的调用关系图

dockerd通过 gRPC 与containerd通信,由于dockerd与真正的容器运行时runC中间有了containerd这一OCI 标准层,使得dockerd可以确保接口向下兼容。containerd-shim 的意思是垫片,类似于拧螺丝时夹在螺丝和螺母之间的垫片。containerd-shim 的主要作用是将 containerd 和真正的容器进程解耦,使用 containerd-shim 作为容器进程的父进程,从而实现重启 dockerd 不影响已经启动的容器进程。
五、Docker实现原理
Docker是利用Linux的Namespace、Cgroups和联合文件系统三大机制来实现的,具体原理是:利用Namespace做主机名、网络、PID等资源的隔离,利用Cgroups对进程或者进程组做资源(如CPU、内存等)限制,利用联合文件系统做镜像构建和容器运行时环境。
1. Namespace
Linux内核的一项功能,该功能对内核资源进行隔离,使得容器中的进程都可以在单独的命名空间中运行,并且只可以访问当前容器命名空间的资源。Namespace 可以隔离进程 ID、主机名、用户 ID、文件名、网络访问和进程间通信等相关资源。
Docker 主要用到以下五种命名空间:
- pid namespace:用于隔离进程 ID。
- net namespace:隔离网络接口,在虚拟的 net namespace 内用户可以拥有自己独立的 IP、路由、端口等。
- mnt namespace:文件系统挂载点隔离。
- ipc namespace:信号量,消息队列和共享内存的隔离。
- uts namespace:主机名和域名的隔离。
2. Cgroups
Linux内核的一项功能,可以限制和隔离进程的资源使用情况(CPU、内存、磁盘 I/O、网络等)。在容器的实现中,Cgroups 通常用来限制容器的 CPU 和内存等资源的使用。
3. 联合文件系统
联合文件系统,又叫 UnionFS,是一种通过创建文件层进程操作的文件系统,因此,联合文件系统非常轻快。Docker 使用联合文件系统为容器提供构建层,使得容器可以实现写时复制以及镜像的分层构建和存储。常用的联合文件系统有 AUFS、Overlay 和 Devicemapper 等。
六、Docker vs 虚拟机
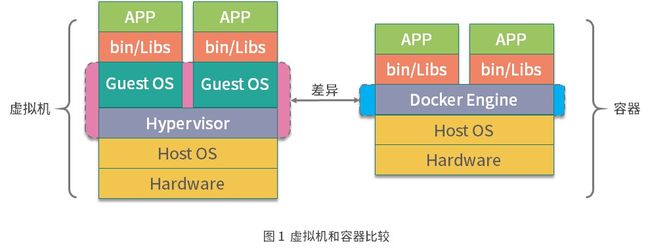
虚拟机是通过管理系统(Hypervisor)模拟出 CPU、内存、网络等硬件,然后在这些模拟的硬件上创建客户内核和操作系统。这样做的好处就是虚拟机有自己的内核和操作系统,并且硬件都是通过虚拟机管理系统模拟出来的,用户程序无法直接使用到主机的操作系统和硬件资源,因此虚拟机也对隔离性和安全性有着更好的保证。
Docker 容器则是通过 Linux 内核的 Namespace 技术实现了文件系统、进程、设备以及网络的隔离,然后再通过 Cgroups 对 CPU、 内存等资源进行限制,最终实现了容器之间相互不受影响,由于容器的隔离性仅仅依靠内核来提供,因此容器的隔离性也远弱于虚拟机。
容器与虚拟机相比,容器的性能损耗非常小,并且镜像也非常小,而且在业务快速开发和迭代的今天,容器秒级的启动等特性也非常匹配业务快速迭代的业务场景。