基于知识蒸馏的两阶段去雨去雪去雾模型学习记录(二)之知识收集阶段
前面学习了模型的构建与训练过程,然而在实验过程中,博主依旧对数据集与模型之间的关系有些疑惑,首先是论文说这是一个混合数据集,但事实上博主在实验时是将三个数据集分开的,那么在数据读取时是如何混合的呢,是每个epoch使用同一个数据集,下一个epoch再换数据集,还是再epoch中随机取数据集中的一部分。
此外,教师模型总共有三个,其模型构造是完全相同的,不同之处在于三个教师模型是在不同的数据集训练得到的,即其权重参数是固定的,那么在训练过程中,从代码来看,原始的教师网络权重是不改变的,那么说如何更新学生网络呢?带着这些疑问,开始今天的学习。
数据集加载
首先需要明确的是数据集加载时是将三个数据集进行了合并,只不过会按照三个数据集进行区别,即生成list形式。train_loader的相关参数设置如下:

模型训练
模型的训练分为两个阶段,分别是知识收集阶段与知识检验阶段,即knowlwdge collect(kc)与knowledge exam(ke)两阶段。
在开始前,需要声明必须要将batch-size设置为3以上,否则会无法加载数据集
首先是知识收集阶段:
声明损失函数,这里的损失函数有两个,分别是L1损失与通过VGG网络计算的软损失(SCRLoss)
criterion_l1, criterion_scr, _ = criterions

模型开启train与eval,关于两者的区别:
model.train()的作用是启用 Batch Normalization 和 Dropout。在train模式,Dropout层会按照设定的参数p设置保留激活单元的概率,如keep_prob=0.8,Batch Normalization层会继续计算数据的mean和var并进行更新。
model.eval()的作用是不启用 Batch Normalization 和 Dropout。在eval模式下,Dropout层会让所有的激活单元都通过,而Batch Normalization层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。在使用model.eval()时就是将模型切换到测试模式,在这里,模型就不会像在训练模式下一样去更新权重。
但是需要注意的是model.eval()不会影响各层的梯度计算行为,即会和训练模式一样进行梯度计算和存储,只是不进行反向传播。
model.train()# model开启train
ckt_modules.train()
for teacher_network in teacher_networks:#为教师网络开启eval()
teacher_network.eval()
随后便进入核心代码模块了:这里包含模型运算,特征映射,损失计算等过程
这里我们对应论文的创新点来看代码。
首先是进度条加载,这里是对数据集加载train_load的封装
pBar = tqdm(train_loader, desc='Training')
遍历数据,判断数据是否为空,这里曾经困扰过博主一段时间,因为每次遍历时target_image都为空,只要将batch-size设置为3以上即可。
for target_images, input_images in pBar:
if target_images is None: continue
target_images = target_images.cuda()
input_images = [images.cuda() for images in input_images]
preds_from_teachers = []
可以看到,此时已经将输入图像,目标图像转换为tensor格式,其中input_images为list形式,每张图像为torch.Size([1, 3, 224, 224])

而target_images为完全为tensor格式,shape为torch.Size([3, 3, 224, 224])

简要描述知识收集阶段
teacher_networks即为教师网络列表,单个的教师网络模型与学生网络是相同的,将数据输入教师网络时,由于需要使用教师网络的中间特征,因此return_feat为True,最终的输出结果为预测结果图与中间特征图,预测结果图会作为 “真值” 来训练学生网络,并计算软损失,中间特征图会与学生网络进行映射到同一特征域来进行特征转移,并将教师网络的预测结果与学生网络的预测结果求SCRLoss。
preds_from_teachers = []
features_from_each_teachers = []
with torch.no_grad():
for i in range(len(teacher_networks)):
preds, features = teacher_networks[i](input_images[i], return_feat=True)
preds_from_teachers.append(preds)
features_from_each_teachers.append(features)
随后将图像输入教师模型,教师模型不更新权重,只是用模型输出的特征来帮助学生网络来训练,称为软损失。核心代码如下:
preds, features = teacher_networks[i](input_images[i], return_feat=True)
将图像 i 输入对应的教师网络 i,这里的i指的是教师网络的索引,这里博主开始曾经有过疑惑,此时的batch_size为3,刚好与教师网络数量对应,因此可以使用该网络,那如果batch_size为6,9时呢,后面的岂不是都无法输入模型了吗,随后博主将batch_size改为6,发现此时的input_image依旧是list形式,但每个list中的内容已经发生了改变,可以看到其是按照不同的数据集类型做了区分,这就是为何input_image要使用list而target_image为tensor的原因了。现在之前的疑惑也就消失了。

随后获得输出结果pred,即预测结果,也就是恢复后的图像。可以看到其与输入图像的维度是一致的,对于第一个网络的第一组输入图像,都为:torch.Size([3, 3, 224, 224])

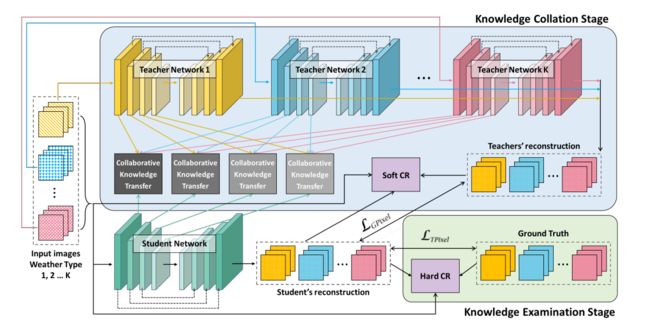
而返回的中间特征图像如图所示,可以看到输出的不同大小的特征图,总共有4组,即4组不同大小的特征图,每组3张图像,通道数,宽高则不相同。
第 1 组数据集(教师网络)的中间特征图:
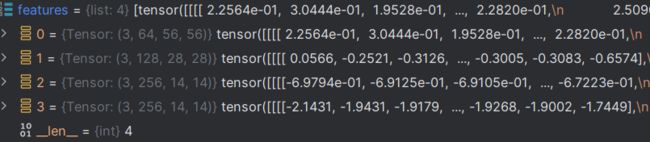
第 3 组数据集(教师网络)的中间特征图:
随后经过三个网络模型的运算,将结果加入列表:
preds_from_teachers.append(preds)
features_from_each_teachers.append(features)


随后将教师网络的预测值转换为tensor格式,因为在最终学生网络的输出是tensor的
preds_from_teachers = torch.cat(preds_from_teachers)
原本list变为tensor
![]()
接下来这段是对feature按照特征图大小进行分组,现在的特征图是按照数据集划分为3组,为方便后面做特征映射,将其按照特征图大小分为四组。
for layer in range(len(features_from_each_teachers[0])):
features_from_teachers.append([features_from_each_teachers[i][layer] for i in range(len(teacher_networks))])
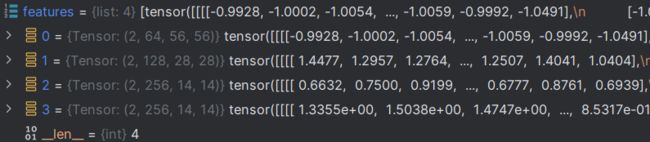
随后便是将输入图像输入学生网络输出结果与中间特征图,这里是不区分数据集的,完全是混合的
preds_from_student, features_from_student = model(torch.cat(input_images), return_feat=True)
由于博主将batch设置为6会报显存溢出,因此这里改为4,可以看到中间特征图依旧是四组,不过每组的第一个值由6变为了4,其余都没有改变。
可以看到list为4组,代表4组不同尺度特征图,每组里面又有一个list,每个list中包含不同数据集(教师网络的特征图)分别是2,1,1。

同理输出结果也是由6变4。

CKT模块(特征转移)
随后便是中间特征图映射了,其过程其实也很简单,即将教师网络特征如与学生网络特征图同时输入CKT模型中,并获得输出结果,将输出结果做损失即可。
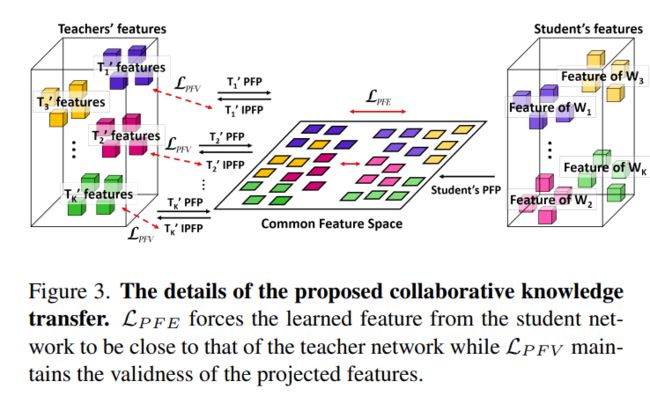
PFE_loss, PFV_loss = 0., 0.
for i, (s_features, t_features) in enumerate(zip(features_from_student, features_from_teachers)):
t_proj_features, t_recons_features, s_proj_features = ckt_modules[i](t_features, s_features)
PFE_loss += criterion_l1(s_proj_features, torch.cat(t_proj_features))
PFV_loss += 0.05 * criterion_l1(torch.cat(t_recons_features), torch.cat(t_features))
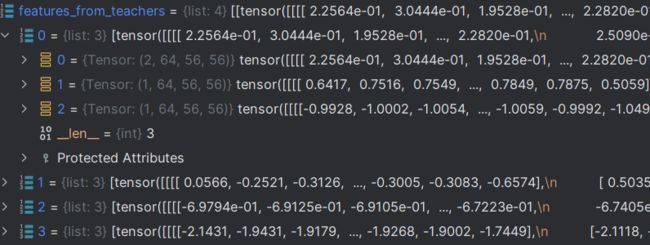
可以看到输入的教师网络特征与学生网络特征也不是相同格式的:
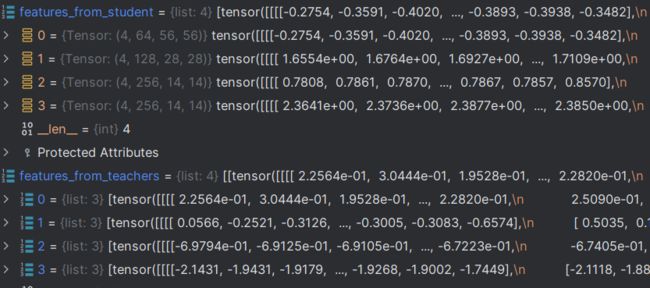
输入值:
经过遍历后,学生网络的特征图分为四组,分别对应不同尺度的特征图,但没有区分数据集,因为本身学生网络就是不区分数据集的。

而教师网络却是list形式,每个数据集分别对应2,1,1个图像数量

CKT网络定义:
class CKTModule(nn.Module):
def __init__(self, channel_t, channel_s, channel_h, n_teachers):
super().__init__()
self.teacher_projectors = TeacherProjectors(channel_t, channel_h, n_teachers)
self.student_projector = StudentProjector(channel_s, channel_h)
def forward(self, teacher_features, student_feature):
teacher_projected_feature, teacher_reconstructed_feature = self.teacher_projectors(teacher_features)
student_projected_feature = self.student_projector(student_feature)
return teacher_projected_feature, teacher_reconstructed_feature, student_projected_feature
具体结构如下,CKT模块共有4个,即对应不同尺度的特征图,注意功能便是进行一系列的特征映射与转换。
CKTModule(
(teacher_projectors): TeacherProjectors(
(PFPs): ModuleList(
(0): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(IPFPs): ModuleList(
(0): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(student_projector): StudentProjector(
(PFP): Sequential(
(0): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
特征转移实际上也是通过损失函数来进行的,即通过一个网学习特征,从而达到特征转移的效果。
最终获得三个结果,分别是教师网络结构特征,教师网络重构特征,学生网络结构特征。核心代码如下:
teacher_projected_feature, teacher_reconstructed_feature = self.teacher_projectors(teacher_features)
student_projected_feature = self.student_projector(student_feature)
return teacher_projected_feature, teacher_reconstructed_feature, student_projected_feature
输出值:
与输入值一样,学生网络结构特征的输出值为tensor形式
![]()
而教师网络特征与教师网络重构特征的输出值依旧为list形式。


随后求特征损失与重构损失即可。
PFE_loss += criterion_l1(s_proj_features, torch.cat(t_proj_features))
PFV_loss += 0.05 * criterion_l1(torch.cat(t_recons_features), torch.cat(t_features))


最终求总损失与SCR损失即可,值得注意的是SCR损失需要使用VGG网络做特征变换后再计算。
L1损失较为简单,输入为学生网络预测值与教师网络预测值
T_loss = criterion_l1(preds_from_student, preds_from_teachers)
SCR_loss = 0.1 * criterion_scr(preds_from_student, target_images, torch.cat(input_images))
关于criterion_l1函数,其实际上是首先使用VGG网络进行特征变换,其输入数据分别是学生网络预测值,目标图像以及输入图像。
SCRLoss定义如下:根据在forward中的代码可知,其首先将输入值分别输入VGG网络进行特征变换,随后在将输出值计算L1损失。
其中,detch方法是返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad。即使之后重新将它的requires_grad置为true,它也不会具有梯度grad
这样我们就会继续使用这个新的tensor进行计算,后面当我们进行反向传播时,到该调用detach()的tensor就会停止,不能再继续向前进行传播。
最终乘以对应的权重,返回最后的损失。
class SCRLoss(nn.Module):
def __init__(self):
super().__init__()
self.vgg = Vgg19().cuda()
self.l1 = nn.L1Loss()
self.weights = [1.0/32, 1.0/16, 1.0/8, 1.0/4, 1.0]
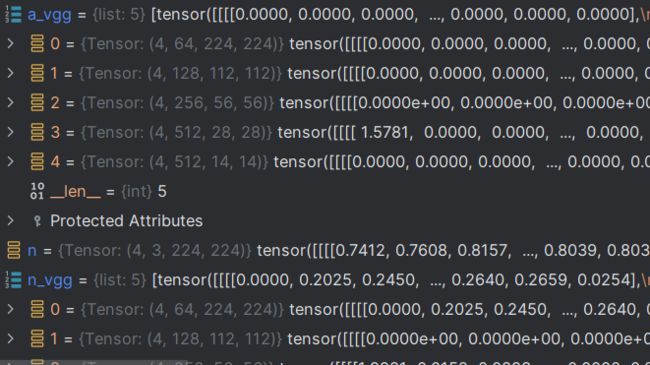
def forward(self, a, p, n):
a_vgg, p_vgg, n_vgg = self.vgg(a), self.vgg(p), self.vgg(n)
loss = 0
d_ap, d_an = 0, 0
for i in range(len(a_vgg)):
d_ap = self.l1(a_vgg[i], p_vgg[i].detach())
d_an = self.l1(a_vgg[i], n_vgg[i].detach())
contrastive = d_ap / (d_an + 1e-7)
loss += self.weights[i] * contrastive
return loss
可以看到最后的损失值是Tensor形式的。
中间生成的特征则有5个,除了4个中间特征图外,还有一个是最终输出结果,即恢复到224x224的,只是通道维度是64而非3。

至此,知识收集阶段便完成了。接下来便是知识测试阶段。