四川大学网安计算机组成和体系结构期末整理
个人整理,错误见谅。
目录
Chapter 1(教材第一章):Introduction
1.3 The Common Measures
1.5 Historical Development
1.6 The Computer Level Hierarchy
1.8 The Von Neumann Model
Chapter 2(教材第二、三章):Data Representation in Computer Systems & Boolean Algebra and Digital Logic
2.2 Positional Numbering Systems
2.3 Converting Between Bases
2.4 Signed Integer Representation
2.5 Floating-Point Representation
Floating-Point Arithmetic
2.7 Error Detection and Correction
Cyclic Redundancy Check
3.2 Boolean Algebra
3.3 Logic Gates
Chapter 3(教材第四章):MARIE: An Introduction to a Simple Computer
4.2 CPU Basics and Organization
4.3 The Bus
Bus Arbitration
4.4 Clocks
CPU Time
4.6 Memory Organization and Addressing(大题)
4.7 Interrupts
The Cause of the Interruption
4.8 MARIE
Characteristics, Architecture, 7 Registers, and ISA
Register Transfer Notation
4.9 Instruction Processing
The Fetch–Decode–Execute Cycle
4.10 A Simple Program(大题)
Trace the Program
4.11 Assembler
4.12 Extending MARIE Instruction Set
Trace the Program
Chapter 3(教材第五章):A Closer Look at Instruction Set Architectures 指令集架构
5.2 Instruction Formats
Factors involved in the Instruction Set Architecture (ISA) design
Byte ordering
Stack architecture, accumulator architecture, and general purpose register architecture
5.3 Instruction Types
Infix notation and postfix notation (reverse Polish notation)
Expanding opcodes扩展操作码(大题):
Instruction types
5.4 Addressing
Memory addressing modes
5.5 Instruction Pipelining
Instruction-level pipelining
Chapter 4(教材第六章):Memory存储器
6.2 Types of Memory
Types of Memory
6.3 The Memory Hierarchy
6.4 Cache Memory
The concepts of hierarchical memory organization
Principle of locality
Cache mapping schemes(大题)
Replacement policy
Effective Access Time (EAT)
Cache Write Policies
Virtual memory & TLB
Page memory management and segment memory management
Chapter 5(教材第七章):I/O Subsystem 输入输出子系统
7.2 Amdahl’s Law
7.4 I/O Architecture
Programmed I/O
Interrupt-driven I/O
Memory mapped I/O
7.6 Hard Drive Disk
7.7 CD/DVD/Blueray
7.9 RAID
RAID-0
RAID-1
RAID-2
RAID-3
RAID-4
RAID-5
RAID-DP
Chapter 6(教材第八章):System Software 系统软件
8.2 Operating System
Process scheduling: FCFS, priority first, shortest job first
8.3 Protected Environment
Virtual machine
Subsystem
Logical Partition
8.4 Programming Tools
Linker
Assembler
8.5 Database Tools
Transaction management
Chapter 7(教材第九章):Alternative Architectures 可选体系结构
9.2 RISC and CISC
Register window
9.3 Flynn’s taxonomy
SISD
SIMD
MISD
MIMD
9.4 Parallel Processors
Superscalar
VLIW
Vector machine
Chapter 8(教材第十章):Embedded System 嵌入式系统
10.2 Hardware for Embedded Systems
Standard processor
Watchdog Timer
Programmable array logic
Programmable logic array
Field Programmable Gate Array
10.3 Software for Embedded Systems
Priority inheritance
Interrupt nesting
Chapter 1(教材第一章):Introduction
1.3 The Common Measures
Kilo (千) - (K) = 1 thousand = 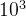 and
and 
Mega (兆) - (M) = 1 million =  and
and 
Giga (吉) - (G) = 1 billion =  and
and 
Tera (太) - (T) = 1 trillion =  and
and 
Peta (拍) - (P) = 1 quadrillion = ![]() and
and ![]()
Exa (艾) - (E) = 1 quintillion =  and
and ![]()
Zetta (泽) - (Z) = 1 sextillion = ![]() and
and ![]()
Milli (毫) - (m) = 1 thousandth = 
Micro (微) - (μ) = 1 millionth = 
Nano (纳) - (n) = 1 billionth = ![]()
Pico (皮) - (p) = 1 trillionth = ![]()
Femto (飞) - (f) = 1 quadrillionth = ![]()
Atto (阿) - (a) = 1 quintillionth = ![]()
Zepto (仄)- (z) = 1 sextillionth = ![]()
Yocto (幺) - (y) = 1 septillionth = ![]()
硬盘访问时间 ms
主存读取时间 ns
电路芯片 mm
处理器运行速度 MHz/GHz
RAM的大小 GB
磁盘存储 GB/TB
RAM是随机访问存储器:访问任意位置
串行:经过一条或者两条数据线以脉冲方式发送数据
并行:沿至少八条数据线作为单个脉冲发送数据。
USB:通用串行总线,可以自我配置的只能串行接口,支持即插即用。
1.5 Historical Development
电子管 ➡ 晶体管 ➡ 集成电路 ➡ 超大规模集成电路
摩尔定律:芯片密度每18个月增长一倍。
罗克定律:芯片制造成本将每4年翻一番。
为了保持摩尔定律,罗克定律必须倒下,反之亦然。 但是没有人能说会先给出。
1.6 The Computer Level Hierarchy
Level 6: The User Level (用户层)
程序在用户层执行
最熟悉
面向终端用户
Level 5: High-Level Language Level (高级语言层)
写程序的语言C等
Level 4: Assembly Language Level (汇编语言层)
5层的程序编译得到
汇编语言编写得到
汇编语言:对底层硬件的直接翻译
Level 3: System Software Level (系统软件层)
控制系统上的执行进程。
调度和保护系统资源。
汇编语言指令通常不经过修改就通过3级。
Level 2: Machine Level (机器层)
也称为指令集架构层(ISA)层。底层芯片指令集。
包含特定于机器体系结构的指令。
用机器语言编写的程序不需要编译器,解释器或汇编程序
Level 1: Control Level (控制层)
控制指令的解码、执行和数据的移动。
控制单元可以是微程序(microprogram’s)或硬连线(hardwired)(hard接线)。
微程序控制单元则更适应变化,而硬连线控制单元具有更好的性能
microprogram是用低级语言编写的程序 ,放在ROM中硬连线由直接执行机器指令的硬件组成
Level 0: Digital Logic Level (数字逻辑层)
由数字电路组成。
数字电路由门和导线组成。
这些组件实现所有其他层次的数学逻辑
1.8 The Von Neumann Model
核心思想:在内存中存储指令
过程:程序的执行过程称为“取译码执行”周期(Fetch-Decode-Execute)
·取(Fetch):CPU的控制单元根据程序计数器(Program Counter,PC)从主存中读取下一条需要执行的指令
·译码(Decode):获取的指令被译码成为算数逻辑单元(Arithmetic-Logic Unit,ALU)可以理解的形式
·执行(Execute)第一阶段:根据译码的结果,CPU控制单元从主存中读取操作数对应的数据,并存入适当的寄存器(register)中
·执行(Execute)第二阶段:ALU执行指令之后,将结果写回寄存器或主存
3种硬件:CPU,主存,IO
特征:
由CPU、存储器和I/O设备构成
指令和数据放在同一个存储器中
读取指令和传送数据采用同一个总线
顺序执行指令
冯诺依曼瓶颈:CPU与主存之间的一条数据链路。
CPU=PC程序计数器+寄存器+ALU算数逻辑单元+control unit 控制单元
PC存储下一条指令的地址
非冯诺依曼模型:
扩展冯诺依曼模型*
系统总线模型中采用三条总线:数据总线、地址总线和控制总线
哈佛架构(Harvard Architecture)及其变体:指令和数据分开存储;采用两个总线分别传输指令和数据
并行处理器:SISD, SIMD, MISD, MIMD
领域专用计算芯片:GPU(图形处理器)、DSP、NPU、APU
Chapter 2(教材第二、三章):Data Representation in Computer Systems & Boolean Algebra and Digital Logic
2.2 Positional Numbering Systems
按位计数法
![]() 或者
或者![]() 表示一个以整数b为基的数字
表示一个以整数b为基的数字

字:连续的字节。16,32,64位
半字节:4个bit
2.3 Converting Between Bases
进制转换:
整数部分 短除法:余数自下而上
小数部分 短乘法:进位数自上而下
2.4 Signed Integer Representation
原码:最高位符号位,0非负,1负数,剩余位绝对值的二进制表示
反码:数值位按位取反
补码:
1’s complement: 非负数原码;负数反码(diminished radio xomplenment)
2’s complement: 非负数源码,负数反码+1 表示唯一
移码:偏移值bias为M的移码 将数字表示范围偏移到非负数范围后原码表示
溢出
2.5 Floating-Point Representation
-
Floating-Point Arithmetic

浮点数:符号位1-bit + 指数位 + 有效数位
符号位同之前;
有效数位在小数位根据要求取
指数位转化为整数部分为1的二进制二进制表示,取指数,移码(加上偏移值)表示
偏移值 = ![]()
2.7 Error Detection and Correction
-
Cyclic Redundancy Check
CRC校验
补齐位数(被除数后面补上 除数位数-1 位 0)
补位后数除以除数,所得余数为CRC
3.2 Boolean Algebra
布尔代数 NOT>AND>OR
3.3 Logic Gates
逻辑门
半加器
全加器(考虑进位)
译码器(n输入, 输出)
输出)
多路复用器(MUX,n个控制信号可以从个输入中选择)
移位器
触发器
Chapter 3(教材第四章):MARIE: An Introduction to a Simple Computer
4.2 CPU Basics and Organization
CPU:取指令;解译指令、执行指令。由数据通道datapath与控制单元control unit组成。
数据通路datapath:ALU、寄存器等等,数据总线连接。
寄存器register:CPU内部的数据存储单元
通用寄存器:保存不同类型的内容
专用寄存器:仅保存数据、地址和控制信息
寄存器很容易,随时地被CPU访问。(能够由D触发器实现。D触发器就是一个1位寄存器。)
算术逻辑单元ALU:执行实际运算,由控制单元控制
多输入,1输出
总线Bus:连接
Datapath里面的部件是通过控制单元发送响应信号进行执行。
控制单元control unit:执行的操作是程序计数器(PC)和状态寄存器(SR)完成
硬连线控制(hardwired);微程序控制(microprogamming)
4.3 The Bus
若干电线连接的集合
连接方式:
点到点(CPU 到 ALU)
多点总线(由于多点总线是一种共享资源,因此对它的访问是通过内置于硬件中的协议来控制的)
传输内容:
数据总线:
CPU通过地址总线共享数据
一根线同时传送1 bit
地址总线:地址线确定数据源或目标的位置。
控制总线:当数据线将位从一个设备传送到另一设备时,控制线确定数据流的方向,以及每个设备何时可以访问总线。
-
Bus Arbitration
总线仲裁方式 应对总线冲突:多个设备同时向总线写入不同值
Daisy chain (菊链、串级联):
共用一个控制线发送请求;根据优先级(从高到低)决定访问顺序;优先级高的得到控制许可并清除
Centralized parallel (集中式并行仲裁):
由一个中央仲裁机构根据优先级仲裁;每个设备与仲裁机构有两个控制线用来请求和接受许可;优先级可确定也可编程实现
Distributed using self-detection (基于自检测的分布式仲裁):
不需要中央仲裁器;每个设备有一个独立的控制线发送请求
优先级从高到低排列;第i+1个设备监听前i个设备的请求控制线;当前i个设备没有发送请求且第i+1个设备发送了请求时该设备获得许可
Distributed using collision-detection (基于冲突检测的分布式仲裁):
不要中央仲裁器;共享一个控制线;如果冲突则重发请求
4.4 Clocks
-
CPU Time

时钟定期产生电子脉冲(pulse)
CPU利用时钟脉冲同步各组件之间的数据传输
时钟频率代表了时钟脉冲信号产生的频率
时钟频率是时钟周期的倒数
时钟频率并不能完全决定CPU的性能
一台计算机至少包含一个用于同步其组件活动的时钟。
执行每个数据移动或计算操作需要固定数量的时钟周期。
以MHz为单位的时钟频率或GHz,确定执行所有操作的速度.
提高CPU的吞吐量:
减少程序中的指令数
减少每条指令的周期数
减少每个时钟周期的纳秒数
4.6 Memory Organization and Addressing(大题)
计算机内存由类似于寄存器的可寻址存储单元的线性阵列组成。
L x W的矩阵,一行一个存储位置(一个可寻址单元) 每个长W
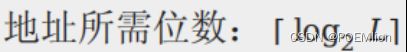
寻址方式:
按字寻址word-addressable 16/32/64bit
按字节寻址byte-addressable 8bit
内存由RAM芯片构成,通常长度*宽度衡量
交叉存储:
当将内存组织到芯片组中并且地址在芯片间交错时,访问效率更高。
每个芯片称为一个模块(Module),内存大小KLW

少位分别补0
列出编号计算
4.7 Interrupts
中断的作用:改变或停止系统中程序执行的事件
-
The Cause of the Interruption
中断既可以由硬件触发也可以由软件触发。由软件触发的中断一般也称为陷阱(trap)或异常(exception)
中断的触发条件
高优先级事件出现
I/ O请求
算术错误(例如零除)
遇到无效指令
中断的处理是通过对应的中断处理程序(Interrupt Service Routine, ISR)来实现的
中断号以及对应的中断处理程序存储在中断向量表(Interrupt Vector Table)中
中断处理过程:
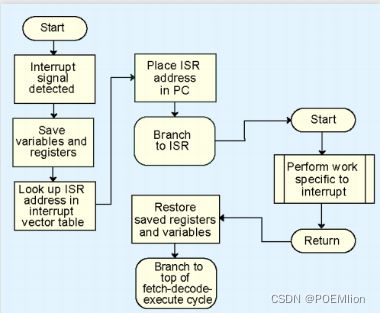
中断的屏蔽(Mask):在有些程序执行过程中(例如一个中断处理程序)不希望被中断, 因此可以屏蔽掉另外的一些中断
4.8 MARIE
指令集架构(Instruction Set Architecture, ISA)
①指令组成的集合②指令编码格式③计算机软硬件的接口
MARIE ISA仅包含13条指令
RISC 复杂指令集架构 微程序
CISC 精简指令集架构 通常硬连线
-
Characteristics, Architecture, 7 Registers, and ISA
目标:为初学者介绍计算机系统组成
特点:
1) 二进制:2的补码数据表示。
2) 存储程序架构,16位固定的字长数据和指令
3) 按字寻址。可寻址字的主存储器的4K字。
4) 16位指令,其中4位操作码(opcode)和12作为地址。
5) 16位数据字。
6) 一个16位算术逻辑单元(ALU)
7) 7个用于控制和数据移动的寄存器
a) 累加器AC:16 bit。存储CPU正在使用的数据。
b) 存储器地址寄存器MAR:12 bit。保存指令或者操作数的地址。
c) 存储器数据缓冲寄存器MBR:16 bit。存储即将放入内存/刚从内存中取出去的数据
d) 程序计数器PC:12 bit。存储下一条将要执行的指令的地址
e) 指令寄存器IR:16 bit。存储正在执行的指令的地址。
f) 输入寄存器InREG:8 bit。存储从输入设备读取到的数据。
g) 输出寄存器OutREG:8 bit。存储将送往输出设备的数据。
Architecture:

寄存器共享16-bit总线连接;每个总线上的设备有一个独一无二的编号。
AC和MBR之间单独的链接。
允许数据传输不经过总线。

MARIE的指令集
指令的编码:16位指令,4位操作码(Opcode),12位地址
操作码为0x1-0x9的指令属于基本指令
操作码为0x0、0xA-0xE的指令属于扩展指令,扩展指令实现了间接寻址(指针)
-
Register Transfer Notation
RTN 寄存器传输表示
Or寄存器传输语言RTL:指定由一条指令执行的微操作的确切顺序。
M [X]表示存储在存储位置X中的实际数据值
A <- B表示将字节传输到寄存器或存储器位置
变量A、B包括下面几类:寄存器,用M[y]表示地址为y的值所对应的存储单元,操作数,变量中的特定位,常数,某些变量的运算结果(一定放右边)
4.9 Instruction Processing
-
The Fetch–Decode–Execute Cycle
RTN:执行过程、执行周期
fetch-decode-execute(取指-解码-执行)周期是计算机在运行程序时执行的一系列步骤。
从内存取指令,放入IR
IR解码,决定下一步操作
如果指令涉及内存值(操作数),则将其找到并放入MBR中。
指令执行
中断处理:MARIE不支持
I/O:inreg和outreg实现
4.10 A Simple Program(大题)
-
Trace the Program
描述程序的运行状态
第一行写出运行前各寄存器与内存中的值
后每一步都写出
4.11 Assembler
采用二进制表示的指令称为机器指令:(0001 0000 0000 0011)
采用符号表示的指令称为汇编语言指令(Assembly):LOAD 3
对应表示操作码的符号称为助记符(Mnemonic Instruction):LOAD
汇编程序Assemblers:将人类可以理解的指令翻译成计算机可以理解的机器语言
简化指令操作码:采用助记符。
简化地址和数据定位:采用标记符号。
简化数据表示:采用特定的汇编指令。仅在编译时使用,不会编译成机器指令
编译过程:
第一次通读(Pass):建立符号表,翻译操作码;
第二次通读:将符号替换为对应的值,生成二进制指令
指令译码和执行:控制单元的实现
4.12 Extending MARIE Instruction Set
-
Trace the Program
Chapter 3(教材第五章):A Closer Look at Instruction Set Architectures 指令集架构
5.2 Instruction Formats
-
Factors involved in the Instruction Set Architecture (ISA) design
指令集设计的时候的考量因素:
指令长度
操作数数目
可寻址寄存器的数目
内存组织:字节/字寻址
寻址方式:直接,间接,索引
指令集特征上的差异:
指令长度
基于堆栈还是寄存器的
每一条指令的显式操作数个数
操作数地址
操作类型
操作数类型与指令集大小
指令集衡量因素:
程序执行的时候占用内存空间的大小
指令系统的复杂程度
指令的长度
指令系统中指令的总数目
-
Byte ordering
大端:低位高地址
更加自然
符号位在最高位
不允许在前面的位置读写。
Adobe PS,JPEG,Microsoft WAV
小端:低位低地址
在最低位符号位。
GIF,Microsoft RTF,Microsoft WAV
-
Stack architecture, accumulator architecture, and general purpose register architecture
指令类型:
1) 堆栈型stack
操作数隐式放置在一个堆栈中
坏处:不能随机访问
所有的运算都是零地址指令
单地址指令只包括PUSH和POP
2) 累加器型accumulator
当指令对应的运算包含两个操作数时,其中一个操作数隐式放置在累加器寄存器中
操作数中存在于内存,导致总线流量变大
3) 通用寄存器型General purpose register操作数可以保存在寄存器中
寄存器代替了内存;比AC架构速度快;编译器的实现简单;导致长指令(因为所有指令都必须命名)
存储器-存储器型:可以有多个操作数存放在内存,允许实现任何操作数都不在寄存器的指令
寄存器-存储器型:至少一个操作数在寄存器中,另一个操作数在内存中
取-存型:除了存取指令外所有操作数都在寄存器中
5.3 Instruction Types
按照操作数的数量分类:
零地址指令:仅有操作码
单地址指令:操作码+一个操作数(通常是一个内存地址)
双地址指令:操作码+两个操作数(通常是两个寄存器,或者是一个寄存器一个地址)
三地址指令:操作码+三个操作数(三个寄存器地址,或者是寄存器地址和内存地址的组合)
-
Infix notation and postfix notation (reverse Polish notation)
反向波兰表示法(选择题) 三种转换方法
-
Expanding opcodes扩展操作码(大题):
对空间充分利用
扩展操作码(Expanding Opcodes):在定长的指令中,通过变长的操作码,表示更多的指令类型
区别操作码的长度:采用转义操作码(Escape Opcode)


-
Instruction types
指令分类:
数据传输 实现数据的传输的功能LOAD, PUSH
算术运算 实现算术运算的功能ADD, MULT
布尔逻辑 实现布尔逻辑运算的功能AND, OR,XOR
位操作 将数据看作01数列进行按位操作的运算SHIFT, ROTATE
I/O操作 直接对I/O设备进行控制的指令INPUT, OUTPUT§
传送控制指令实现改变程序执行顺序的功能(branch,jump,call,return SKIPCOND,)
专用指令实现一些特殊的功能(string processing,flag) HALT, CLEAR, NOP
5.4 Addressing
-
Memory addressing modes
立即寻址(Immediate Addressing) AC
直接寻址(Direct Addressing) ➡AC
寄存器直接寻址 AC
间接寻址(Indirect Addressing) ➡➡AC
寄存器间接寻址 ➡AC
变址寻址(Indexed Addressing) 地址+offset ➡AC
基址寻址(Based Addressing) 基址+offset ➡AC
堆栈寻址(Stack Addressing)
5.5 Instruction Pipelining
-
Instruction-level pipelining
指令流水线:指令的并行执行。提供指令级并行(ILP)
N指令k流水线的 时间。(k+n-1)tp,tp是时钟周期
加速比
流水线可能刷新或者停止:软硬件都可以解决
Resource conflicts (资源冲突):e.g., access to the memory
Data dependencies (数据依赖):e.g., control the same data
Conditional branching (条件转移语句):e.g., comprising branching or jumping instructions
Chapter 4(教材第六章):Memory存储器
6.2 Types of Memory
-
Types of Memory
存储器类型:
随机存储器RAM:通电使用
动态RAM(DRAM):电容器构成,有充放电的过程。每个一段时间(几个msecond)充电防止数据丢失。由于设计简单->便宜
静态RAM(SRAM):类似于D触发器的变种构成。速度很快,不用充电。用来cache/高速缓存。
只读存储器ROM:不用充电,类似于D触发器构造。需要一点点电保持memory。ROM用来存储永久性或者半永久性数据,保证断电之后数据也存在,比如BIOS菜单。
6.3 The Memory Hierarchy
存储器的层次架构:
目的:根据不同的需求在可控成本下达到最优效率
越快的,越贵,离CPU越近(磁盘磁带一般最远),容量越小。
6.4 Cache Memory
-
The concepts of hierarchical memory organization
-
Principle of locality
命中后将复制整个数据块,因为局部性原理告诉我们,一旦访问了一个字节,很可能很快就会需要附近的数据元素。
局部性的三类:
时间局部性Temporal locality:刚刚访问的数据及其邻近数据可能被再次访问
空间局部性Spatial locality:在存储空间相邻的数据会被访问
顺序局部性Sequential locality:指令被顺序执行
Cache的目的:通过存储最近使用或将很快使用的数据来加快访问速度。按照内容寻址的寄存器
-
Cache mapping schemes(大题)
Direct Mapped Cache (直接映射的缓存):便宜。每个块有具体的位置。块可以在cache的任意位置
Fully Associative Cache (全相联映射的缓存)
Set Associative Cache (组相联映射的缓存)
-
Replacement policy
最优置换策略optimal replacement policy:未来最长时间不被使用的。时间局部性
最近最少使用算法least recently used (LRU) algorithm:缺点CPU必须维护每个块的访问历史记录
先进先出First-in, first-out (FIFO)。缺点:最早进来的可能多次使用,也会被剔除。
随机选择random replacement policy:没有抖动,但是可能会将未来使用的数据丢失
-
Effective Access Time (EAT)
Effective Access Time (EAT) (有效存取时间):衡量计算机或者CPU对数据存取的时候消耗的时间。
H是缓存命中率。Access_c是缓存访问时间;Access_MM是主存访问时间。
-
Cache Write Policies
脏块:缓存中被更新的数据。
直写write through:cache变化,主存立马变化。拖慢CPU速度,拖慢的速度可以被忽略,对数据的访问以读操作为主,写操作相对少得多。
回写write back:要丢弃或者置换的时候才对主存更新。
优点:对主存的访问最小化;
缺点:主存的数据与cache数据不同,多个用户同时使用的时候,可能出错。系统崩溃会让信息丢失。
-
Virtual memory & TLB
-
Page memory management and segment memory management
Chapter 5(教材第七章):I/O Subsystem 输入输出子系统
7.2 Amdahl’s Law
S加速比;f部件工作时间的百分比;k单个组件加速的比例。
阿姆达尔定律为我们提供了一种方便的方法来估算升级系统组件时可以预期的性能改进
I / O子系统包括:
专门用于I / O功能的主存块。
总线:将数据移入和移出系统的总线(Bus)。
控制模块:主机和外围设备中的控制模块Ÿ
接口:键盘和磁盘等外部组件的外部接口
电缆:电缆或主机系统与其外围设备之间的通信链接。
7.4 I/O Architecture
-
Programmed I/O
程序控制的I/O Programmed I/O:每一个I/O设备有一个寄存器。每个寄存器会轮询检测有没有输入输出需求。
-
Interrupt-driven I/O
中断控制的I/O Interrupt-driven I/O:允许计算机做其他的事情,直到I/O被请求
取码译码一个周期执行完的时候会检测是否有中断信号。
检测一系列地址(中断向量)。
先存储系统状态,然后执行ISR(中断服务程序)。
-
Memory mapped I/O
内存映射IO Memory mapped I/O:I/O设备与主存储器共享相同的空间
主存里面为I/O预留有block。
从CPU的角度来说,内存映射I/O就是内存访问
数据存取与指令存取架构相同,简化系统设计
直接存储器存储(DMA):使用一个专门芯片处理。
和CPU共享总线->CPU和DMA是互斥的。
DMA优先级更高,抢占CPU
通道控制的I/O:专用的I/O控制器
大型系统使用
一个或者多个I/O处理器构成,控制通路
一些比较慢的设备复用到一个快速同道中
大型机有多路复用通道
总线宽度:数据总线的条数
7.6 Hard Drive Disk
磁盘是随机/直接存储设备:因为可以根据块在磁盘上的位置访问数据块。
访问时间=寻道时间+旋转延迟
寻道时间:arm定位到track上面
旋转延迟:定位到track上的扇区sector(磁盘旋转到sector被磁头读取的时间)。算法上的时间。
平均反应时间:物理上对数据访问的衡量。对转速有关系。
平均失效时间:实验中统计生命周期的平均值
SSD固态硬盘:
非易失性闪存
MP3,U盘
磨损均衡
规格与指标:
不可恢复的误码率UBER:稳定性衡量,错了多少。模仿整个生命周期工作,多少个数据量发生错误。错误/总共的=UBER
写入的兆字节TBW:对生命周期衡量。一直重写,多久的时候不再正常工作。
7.7 CD/DVD/Blueray
CD-ROM只读;
从中间开始螺旋track,展开5英里
0,1存储。表面的高低凹凸。
2层数据校验,容错率较高。
逻辑存储格式比磁盘复杂。
DVD光碟;
存储密度是CD的4倍
单个17GB
波长比CD短。
蓝紫光DVD:
数据中心比较多,长期存储和恢复。
蓝光:单层对多25GB,最多可以6层。
7.9 RAID
-
RAID-0
磁盘跨区
stipe
没有冗余
数据写在entire arry上面的block和strip上面。
缺点:稳定性比较低,没有检错纠错功能。
-
RAID-1
disk mirroring (磁盘镜像)
strip
100%数据冗余,较好performance
两个对应的磁盘组存储相同数据
缺点:成本高
-
RAID-2
一个set存储数据,另一个存储汉明码。
特点:
bit存储
汉明码校验
优点:稳定性
缺点:不高效
-
RAID-3
bit存储,奇偶校验
不适合商用,适合私人系统
-
RAID-4
strip存储,奇偶校验
需要所有块大小相同。
-
RAID-5
strip分布式,奇偶校验。并行处理
商用系统
-
RAID-DP
strip重叠,两个奇偶校验。容忍两个磁盘数据丢失,可以找回。
Chapter 6(教材第八章):System Software 系统软件
8.2 Operating System
操作系统的发展与计算机硬件的发展平行。
主存计量单位再以前KB,磁带是唯一的磁存储设备,操作系统就是简单的 常驻监控程序。只能载入,执行,终止任务。
在1960年代,硬件已经变得足够强大,可以容纳多道程序,并发执行多个任务。通过将每个进程分配给定的CPU时间来实现多道程序设计。 交互式多道程序系统称为分时共享系统。
多处理器系统:挑战:处理器的同步方式以及如何防止其活动相互干扰。
紧密耦合多处理器系统(Tightly coupled multiprocessor systems):共享一个内存和一组相同的I / O设备。
松散耦合多处理器系统(Loosely coupled multiprocessor systems):在物理上具有独立的内存。Ÿ这些系统通常称为分布式系统。Ÿ另一种类型的分布式系统是联网系统(networking system),它由互连的,协作的工作站组成。
实时操作系统Real time operating systems :控制响应其环境的计算机。硬实时系统具有严格的时序约束(timing Constraints),软实时系统则没有
操作系统的设计:
作为操作系统的核心,内核执行调度(进程调度),同步,内存管理,中断处理,并提供安全性和保护。
微内核系统(Microkernel system)提供最少的功能。大多数服务由外部程序执行
优点:
可移植性高
安全性高
维护较好
缺点:
拖慢速度
宏/单内核系统(Monolithic systems):在单个操作系统程序中提供大多数服务
速度很快
移植性差
混合内核(Hybrid kernel systems):微软使用的。
操作系统提供的服务
进程管理:OS的核心任务。操作系统创建进程,安排它们对资源的访问,删除进程以及取消分配在进程执行期间分配的资源。
操作系统监视每个进程的活动,以避免在进程使用共享资源时可能发生的同步问题。
提供进程间通信
-
Process scheduling: FCFS, priority first, shortest job first
First-come, first-served (先到先服务):到达序列执行。
Shortest job first (最短作业优先):最短执行的任务优先执行。缺点:无法确定哪个最短。
Round robin scheduling (循环调度):每个任务分配一定量时间。超时之后:上下文切换。
Priority scheduling (优先级调度):优先级,抢占。
8.3 Protected Environment
作为资源管理者和保护者,许多操作系统提供了将进程或进程组彼此隔离的受保护环境。
建立受保护环境的3种方法:
-
Virtual machine
虚拟机:是一种受保护的环境,向环境中运行的进程提供自身的映像或完全不同的体系结构的映像。是一个虚假的机器。底层的真实计算机在内核的控制之下。 内核接收并管理从虚拟环境中运行的进程发出的所有资源请求。
-
Subsystem
子系统:它们提供了逻辑上不同的环境,可以独立控制和管理。 它们可以彼此独立地停止和启动。子系统可以具有特殊目的,例如控制I / O或虚拟机。 其他子系统则对大型应用程序系统进行分区(分割),以使其更易于管理。在许多情况下,资源要对子系统可见,然后子系统中运行的进程才能对其进行访问。在超大型计算机中,子系统的作用范围不足以建立受保护的环境。
-
Logical Partition
逻辑分区(LPAR)提供了更高的障碍:在逻辑分区中运行的进程无法访问在另一个分区中运行的进程,除非显式建立了它们之间的连接(eg. FTP)
8.4 Programming Tools
编程工具在操作系统和硬件环境的限制内执行软件创建任务.
绑定binding:将物理地址分配给程序变量的过程
编译时绑定:绝对代码
装载时绑定:分配物理地址
运行时绑定:需要基址寄存器来执行地址映射
动态链接:当程序在装在或者运行的时候链接。外部模块是从动态链接库(DLL)加载的。
-
Linker
加载时动态链接:会降低程序的加载速度,但对DLL的调用会更快。
运行时动态链接:发生在首次调用外部模块时,导致执行速度较慢
动态链接使程序模块更小,但存在程序员可能无法控制DLL的风险。
-
Assembler
汇编器(Assemblers)是所有编程工具中最简单的。 它们将助记符指令转换为机器代码。
大多数汇编器会在源代码上进行两次翻译。
第一遍:部分地汇编代码并构建符号表。
第二遍:通过提供存储在符号表中的值来完成指令创建。
汇编语言:第二代程序设计语言。
编译程序语言:C C++等是第三代。
逐渐像人类一样思考。
8.5 Database Tools
-
Transaction management
Chapter 7(教材第九章):Alternative Architectures 可选体系结构
9.2 RISC and CISC
RISC(精简指令集计算机)机器的基本原理是,当程序仅由几条长度相同且需要相同数量的时钟周期进行解码和执行的指令组成时,该系统可以更好地管理程序执行。 RISC系统仅通过显式的load and store指令访问内存。
CISC(复杂指令集计算机)系统中
程序由许多不同类型的指令组成
这些指令的长度是可变的
并且获取-解码-执行时间是不可预测的。
许多指令都可以访问存储器
精简指令集系统可以降低每个指令的时钟周期数量完成CPU time降低。
复杂指令集降低一个程序里面指令的数量。
精简指令集花费时间相比复杂指令集较短。
本质上这两种区别变模糊了。现在精简指令集中的指令可能会比复杂指令集还要复杂。
RISC:
多个寄存器组
每条指令三个操作数
通过寄存器窗口传递参数
单周期指令
硬件控制
高度流水线
简单的指令,数量很少
固定长度的指令
编译器复杂
仅LOAD / STORE指令访问存储器
很少的寻址模式
CISC:
单寄存器组
每条指令一个或两个寄存器操作数
通过内存传递的参数
多周期指令
微编程
流水线较少
许多复杂的指令
可变长度的指令
微代码的复杂性
许多指令可以访问存储器
许多寻址模式
-
Register window
9.3 Flynn’s taxonomy
-
SISD
SISD单指令单数据流:经典单处理器系统
-
SIMD
SIMD单指令多数据流:多个数据流上只能执行相同指令。
-
MISD
MISD多指令单数据流:很少使用
-
MIMD
MIMD多指令多数据流:现在并行计算的方式
SMP对称多处理:处理器数量比较少+共同使用主存+存储器上通信
MPP大量信息并行处理:多个处理器+分布式存储+网络通信
分布式处理:
NOW工作站网络:使用闲置的系统来解决问题
COW工作站集合:一个工作站协调
DCPC专用群集式并行计算机:做成一组工作站,没单独工作站协调工作。
PC机群:群集式,并行计算。异构计算机。
SPMD单程序多数据流:每个处理器单独分配数据集和程序存储。每个node可以对指令分段执行。超级计算机。
富林分类法缺点:
不需要MISD机器
并行执行不是同构
没有区分MIMD类别的体系结构。根据是否共享内存:基于总线连接;基于交换开关链接。
9.4 Parallel Processors
并行处理
好处:
提升通量:同时处理多个任务,多路数据流处理
保持较高容错率:并行计算执行的时候如果出现错误不影响整个流程
不足:
必须有些任务顺序执行。没有办法100%发挥性能。处理器性能提高n倍,最后通量提升小于n倍。
缓存一致性问题:当更改主内存数据而未改变缓存时
snoopy cache controllers (窥视高速缓存控制器):监视系统的高速缓存。
写策略:
写直通:cache和memory的数据同步更新
写直通更新协议:消息进行更新就要进行广播,对数据更新.
写直通无效协议:消息改变就广播不要用这个数据.
回写协议:cache被丢弃才回写到主存中.
分布式系统由非常松耦合的处理单元组成
云服务使用者甚至对硬件位置都不了解
-
Superscalar
流水线:能够将取码译码分为多个周期进行执行。
理论上每过一个时钟周期,有一个指令就会被执行完。
超流水线:不到一个时钟周期就能完成。单独配备一个系统时钟,频率高于原来的。是超标量的一个实现。
超标量:
包含多个执行单元:专用加法乘法器
取指单元:同时从主存取出多个指令
译码单元:哪些指令可以并行执行。协调作用。
-
VLIW
-
Vector machine
矢量计算机:也叫作超级计算机。同时在一个完整向量和矩阵上操作。能够支持超高流水线技术。根据操作数分类:
RRVP寄存器式Register-register vector processors:所有的操作数都在寄存器中
MMVP主存式Memory-memory vector processors:数据都在主存中,直接进入AU算数逻辑单元
紧密耦合多处理器/共享存储器的多处理器:使用同一个主存。不一定共享物理内存。每个处理器可以有自己主存,但是要与其他处理器共享。
Chapter 8(教材第十章):Embedded System 嵌入式系统
10.2 Hardware for Embedded Systems
嵌入式系统:
Off-the-shelf (现成的)
Configurable (可配置的)
Fully-Customized (完全定制的)
资源受限
开发者要完全了解硬件功能
-
Standard processor
微控制器:旧的电脑技术中衍生。几千种。属于现成的(Off-the-shelf)。
微处理器
-
Watchdog Timer
通过定期检查系统活动性来防止系统挂起(挂起)和无限循环
看门狗定时器并非在所有微控制器中都使用
半定制:只要没有合适的现成SOCs(片上系统),就可以制造(半定制)片上系统。
芯片掩膜:使用预先设计的模块创建,以及有知识产权电路创建。
半定制方法的成本很高。 为了节省金钱,首选现成的SOC,即使其功能不完全适合该应用程序。
SOCS:处理器不用共享时钟周期
需要单独的芯片来提供相同的服务。
附加芯片很昂贵,并且消耗功率和空间。
-
Programmable array logic
PAL, 可编程阵列逻辑:芯片由连接到一组可编程与门与固定或门
-
Programmable logic array
PLA, 可编程序逻辑阵列:芯片由通过可编程或门连接的可编程与门组成
-
Field Programmable Gate Array
FPGAs, 现场可编程门阵列,由存储单元和多路复用器(MUX)组成。逻辑门链接:交换设备和复用器,岛屿式分布
10.3 Software for Embedded Systems
软件开发受到难题,受限制的硬件条件:
内存限制
虚拟内存不适用
存储器共享同样的地址空间。内存泄露问题。
嵌入式系统有区分性的是响应能力。
时序要求
硬实时系统(Hard Real-Time Systems)具有严格的时序约束。
软实时系统(Soft Real-Time Systems),时序很重要,但并不关键
中断延迟时间:是指从发生中断到执行中断服务程序(ISR)的第一条指令之间经过的时间。延迟越短,响应越快。中断嵌套只可能在高质量的系统中。
内存占用:软件本身对于内存使用的情况。最关注的
1. 操作系统占用很多内存,额外的存储空间
2. 存储消耗资源
3. 操作系统越小越好
事务处理是最核心的因素。
大型软件项目通常划分为大块(组块)
事件处理是嵌入式程序员的主要挑战,是嵌入式系统的核心功能。事件异步执行,测试要周全。
硬件定义语言Verilog,VHDL指定了全定制芯片的功能和布局。
硬件代码编码减少了错误并更快地将产品推向市场。
嵌入式操作系统在时序和内存占用方面与通用操作系统有所不同。
嵌入式系统开发需要准确规格和严格开发实践。
-
Priority inheritance
-
Interrupt nesting