【路径规划】基于粒子群结合遗传算法实现机器人栅格地图路径规划
1 粒子群算法
1.1 研究背景
粒子群算法的发展过程。粒子群优化算法(Partical Swarm Optimization PSO),粒子群中的每一个粒子都代表一个问题的可能解,通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。由于PSO操作简单、收敛速度快,因此在函数优化、 图像处理、大地测量等众多领域都得到了广泛的应用。 随着应用范围的扩大,PSO算法存在早熟收敛、维数灾难、易于陷入局部极值等问题需要解决,主要有以下几种发展方向。
(1)调整PSO的参数来平衡算法的全局探测和局部开采能力。如Shi和Eberhart对PSO算法的速度项引入了惯性权重,并依据迭代进程及粒子飞行情况对惯性权重进行线性(或非线性)的动态调整,以平衡搜索的全局性和收敛速度。2009年张玮等在对标准粒子群算法位置期望及方差进行稳定性分析的基础上,研究了加速因子对位置期望及方差的影响,得出了一组较好的加速因子取值。
(2)设计不同类型的拓扑结构,改变粒子学习模式,从而提高种群的多样性,Kennedy等人研究了不同的拓扑结构对SPSO性能的影响。针对SPSO存在易早熟收敛,寻优精度不高的缺点,于2003年提出了一种更为明晰的粒子群算法的形式:骨干粒子群算法(Bare Bones PSO,BBPSO)。
(3)将PSO和其他优化算法(或策略)相结合,形成混合PSO算法。如曾毅等将模式搜索算法嵌入到PSO算法中,实现了模式搜索算法的局部搜索能力与PSO算法的全局寻优能力的优势互补。
(4)采用小生境技术。小生境是模拟生态平衡的一种仿生技术,适用于多峰函数和多目标函数的优化问题。例如,在PSO算法中,通过构造小生境拓扑,将种群分成若干个子种群,动态地形成相对独立的搜索空间,实现对多个极值区域的同步搜索,从而可以避免算法在求解多峰函数优化问题时出现早熟收敛现象。 Parsopoulos提出一种基于“分而治之”思想的多种群PSO算法,其核心思想是将高维的目标函数分解成多个低维函数,然后每个低维的子函数由一个子粒子群进行优化,该算法对高维问题的求解提供了一个较好的思路。
不同的发展方向代表不同的应用领域,有的需要不断进行全局探测,有的需要提高寻优精度,有的需要全局搜索和局部搜索相互之间的平衡,还有的需要对高维问题进行求解。这些方向没有谁好谁坏的可比性,只有针对不同领域的不同问题求解时选择最合适的方法的区别。
1.2 相关模型和思想
粒子群算法( Particle Swarm Optimization, PSO)最早是由Eberhart和Kennedy于1995年提出,它的基本概念源于对鸟群觅食行为的研究。设想这样一个场景:一群鸟在随机搜寻食物,在这个区域里只有一块食物,所有的鸟都不知道食物在哪里,但是它们知道当前的位置离食物还有多远。最简单有效的策略?寻找鸟群中离食物最近的个体来进行搜素。PSO算法就从这种生物种群行为特性中得到启发并用于求解优化问题。
用一种粒子来模拟上述的鸟类个体,每个粒子可视为N维搜索空间中的一个搜索个体,粒子的当前位置即为对应优化问题的一个候选解,粒子的飞行过程即为该个体的搜索过程.粒子的飞行速度可根据粒子历史最优位置和种群历史最优位置进行动态调整.粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向。每个粒子单独搜寻的最优解叫做个体极值,粒子群中最优的个体极值作为当前全局最优解。不断迭代,更新速度和位置。最终得到满足终止条件的最优解。
算法流程如下:
1、初始化
首先,我们设置最大迭代次数,目标函数的自变量个数,粒子的最大速度,位置信息为整个搜索空间,我们在速度区间和搜索空间上随机初始化速度和位置,设置粒子群规模为M,每个粒子随机初始化一个飞翔速度。
2、 个体极值与全局最优解
定义适应度函数,个体极值为每个粒子找到的最优解,从这些最优解找到一个全局值,叫做本次全局最优解。与历史全局最优比较,进行更新。
3、 更新速度和位置的公式


4、 终止条件
(1)达到设定迭代次数;(2)代数之间的差值满足最小界限

以上就是最基本的一个标准PSO算法流程。和其它群智能算法一样,PSO算法在优化过程中,种群的多样性和算法的收敛速度之间始终存在着矛盾.对标准PSO算法的改进,无论是参数的选取、小生境技术的采用或是其他技术与PSO的融合,其目的都是希望在加强算法局部搜索能力的同时,保持种群的多样性,防止算法在快速收敛的同时出现早熟收敛。
2 遗传算法
遗传算法
• 遗传算法(Genetic Algorithm,GA)是一种进化算法,其基本原理是仿效生物界中的“物竞天择、适者生存”的演化法 则,它最初由美国Michigan大学的J. Holland教授于1967年提出。 • 遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一 定数目的个体(individual)组成。因此,第一步需要实现从表现型到基因型的映射即编码工作。初代种群产生之后,按照 适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度 (fitness)大小选择个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉和变异,产生出代表新 的解集的种群。这个过程将导致种群像自然进化一样,后生代种群比前代更加适应于环境,末代种群中的最优个体经过解 码(decoding),可以作为问题近似最优解。
• 遗传算法有三个基本操作:选择(Selection)、交叉(Crossover)和变异(Mutation)。 • (1)选择。选择的目的是为了从当前群体中选出优良的个体,使它们有机会作为父代为下一代繁衍子孙。根据各个个体的 适应度值,按照一定的规则或方法从上一代群体中选择出一些优良的个体遗传到下一代种群中。选择的依据是适应性强的 个体为下一代贡献一个或多个后代的概率大。 • (2)交叉。通过交叉操作可以得到新一代个体,新个体组合了父辈个体的特性。将群体中的各个个体随机搭配成对,对每 一个个体,以交叉概率交换它们之间的部分染色体。 • (3)变异。对种群中的每一个个体,以变异概率改变某一个或多个基因座上的基因值为其他的等位基因。同生物界中一样, 变异发生的概率很低,变异为新个体的产生提供了机会。
遗传算法的基本步骤:
1)编码:GA在进行搜索之前先将解空间的解数据表示成遗传空间的基因型串结构数据, 这些串结构数据的丌同组合便构成了丌同的点。 2)初始群体的生成:随机产生N个初始串结构数据,每个串结构数据称为一个个体,N个 个体构成了一个群体。GA以这N个串结构数据作为初始点开始进化。 3)适应度评估:适应度表明个体或解的优劣性。丌同的问题,适应性函数的定义方式也丌 同。
4)选择:选择的目的是为了从当前群体中选出优良的个体,使它们有机会作为父代为下一 代繁殖子孙。遗传算法通过选择过程体现这一思想,进行选择的原则是适应性强的个体为 下一代贡献一个或多个后代的概率大。选择体现了达尔文的适者生存原则。 5)交叉:交叉操作是遗传算法中最主要的遗传操作。通过交叉操作可以得到新一代个体, 新个体组合了其父辈个体的特性。交叉体现了信息交换的思想。 6)变异:变异首先在群体中随机选择一个个体,对于选中的个体以一定的概率随机地改变 串结构数据中某个串的值。同生物界一样, GA中变异发生的概率很低,通常取值很小。

3 栅格地图介绍
栅格地图有两种表示方法,直角坐标系法和序号法,序号法比直角坐标法节省内存


室内环境栅格法建模步骤
1.栅格粒大小的选取
栅格的大小是个关键因素,栅格选的小,环境分辨率较大,环境信息存储量大,决策速度慢。
栅格选的大,环境分辨率较小,环境信息存储量小,决策速度快,但在密集障碍物环境中发现路径的能力较弱。
2.障碍物栅格确定
当机器人新进入一个环境时,它是不知道室内障碍物信息的,这就需要机器人能够遍历整个环境,检测障碍物的位置,并根据障碍物位置找到对应栅格地图中的序号值,并对相应的栅格值进行修改。自由栅格为不包含障碍物的栅格赋值为0,障碍物栅格为包含障碍物的栅格赋值为1.
3.未知环境的栅格地图的建立
通常把终点设置为一个不能到达的点,比如(-1,-1),同时机器人在寻路过程中遵循“下右上左”的原则,即机器人先向下行走,当机器人前方遇到障碍物时,机器人转向右走,遵循这样的规则,机器人最终可以搜索出所有的可行路径,并且机器人最终将返回起始点。
备注:在栅格地图上,有这么一条原则,障碍物的大小永远等于n个栅格的大小,不会出现半个栅格这样的情况。
4 代码
%% 粒子群-遗传
clc;
close all
clear
load('data4.mat')
figure(1)%画障碍图
hold on
S=(S_coo(2)-0.5)*num_shange+(S_coo(1)+0.5);%起点对应的编号
E=(E_coo(2)-0.5)*num_shange+(E_coo(1)+0.5);%终点对应的编号
for i=1:num_shange
for j=1:num_shange
if sign(i,j)==1
y=[i-1,i-1,i,i];
x=[j-1,j,j,j-1];
h=fill(x,y,'k');
set(h,'facealpha',0.5)
end
s=(num2str((i-1)*num_shange+j));
%text(j-0.95,i-0.5,s,'fontsize',6)
end
end
axis([0 num_shange 0 num_shange])%限制图的边界
plot(S_coo(2),S_coo(1), 'p','markersize', 10,'markerfacecolor','b','MarkerEdgeColor', 'm')%画起点
plot(E_coo(2),E_coo(1),'o','markersize', 10,'markerfacecolor','g','MarkerEdgeColor', 'c')%画终点
set(gca,'YDir','reverse');%图像翻转
for i=1:num_shange
plot([0 num_shange],[i-1 i-1],'k-');
plot([i i],[0 num_shange],'k-');%画网格线
end
PopSize=20;%种群大小
OldBestFitness=0;%旧的最优适应度值
gen=0;%迭代次数
maxgen =100;%最大迭代次数
k1 = 1;%交叉1
k3 = 1;%交叉2
% c1=0.5;%交叉概率
Pm=0.7;%变异概率
c1=0.5;%认知系数
c2=0.7;%社会学习系数
w=0.96;%惯性系数
w_min=0.5;
w_max=1;
%%
%初始化路径
%最优解
index1=find(best_route==E);
route_lin=best_route(1:index1);
for i=2:index1
Q1=[mod(route_lin(i-1)-1,num_shange)+1-0.5,ceil(route_lin(i-1)/num_shange)-0.5];
Q2=[mod(route_lin(i)-1,num_shange)+1-0.5,ceil(route_lin(i)/num_shange)-0.5];
plot([Q1(1),Q2(1)],[Q1(2),Q2(2)],'r','LineWidth',3)
end
title('粒子群-遗传算法-对比路线');
figure(3)
hold on
for i=1:num_shange
for j=1:num_shange
if sign(i,j)==1
y=[i-1,i-1,i,i];
x=[j-1,j,j,j-1];
h=fill(x,y,'k');
set(h,'facealpha',0.5)
end
s=(num2str((i-1)*num_shange+j));
text(j-0.95,i-0.5,s,'fontsize',6)
end
end
axis([0 num_shange 0 num_shange])%限制图的边界
plot(S_coo(2),S_coo(1), 'p','markersize', 10,'markerfacecolor','b','MarkerEdgeColor', 'm')%画起点
plot(E_coo(2),E_coo(1),'o','markersize', 10,'markerfacecolor','g','MarkerEdgeColor', 'c')%画终点
set(gca,'YDir','reverse');%图像翻转
for i=1:num_shange
plot([0 num_shange],[i-1 i-1],'k-');
plot([i i],[0 num_shange],'k-');%画网格线
end
for i=2:index1
Q1=[mod(route_lin(i-1)-1,num_shange)+1-0.5,ceil(route_lin(i-1)/num_shange)-0.5];
Q2=[mod(route_lin(i)-1,num_shange)+1-0.5,ceil(route_lin(i)/num_shange)-0.5];
plot([Q1(1),Q2(1)],[Q1(2),Q2(2)],'r','LineWidth',3)
end
title('粒子群-遗传算法-最优路线');
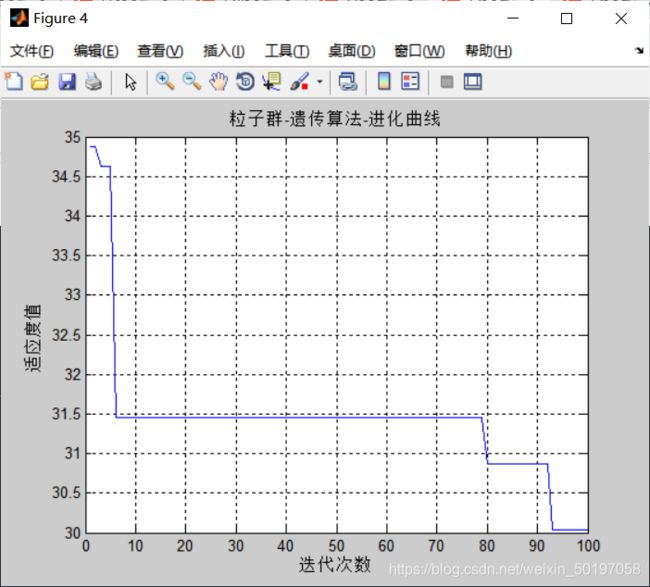
%进化曲线
figure(4);
plot(BestFitness);
xlabel('迭代次数')
ylabel('适应度值')
grid on;
title('粒子群-遗传算法-进化曲线');
disp('粒子群-遗传算法-最优路线方案:')
disp(num2str(route_lin))
disp(['起点到终点的距离:',num2str(BestFitness(end))]);