BERT入门教程学习心得 word embedding
来源Youtube上一个BERT Tutorial的视频
https://www.youtube.com/channel/UCoRX98PLOsaN8PtekB9kWrw
Word Embedding

将word变成一组特征向量。
对word的编码实际表示了word之间的关联程度。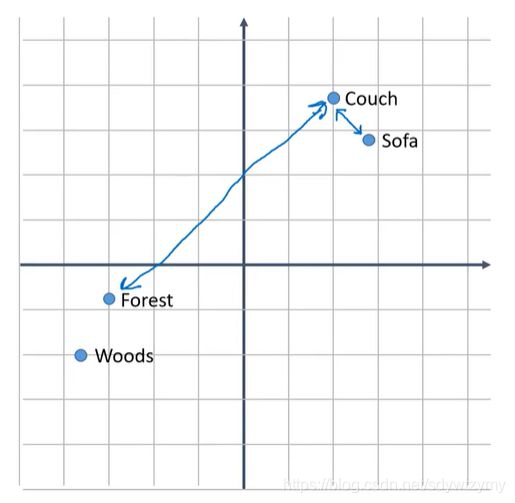

Bert是预训练好的 => Bert中的单词编码是固定的
Bert拥有自己的LUT去查找对应的编码
![]()
对于不在这个表里的单词:Bert将未知的单词分成多个subword进行处理
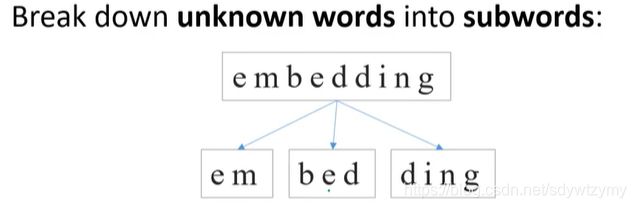
FastText采用了类似的办法,但与FastText不同的是,FastText采用combine的方式,算出均值作为新单词的vector。但Bert直接独立的使用每个subword作为一个新word。意味着如果有一句话,有十个单词,包含embedding,那处理完后它将有12个单词。
那遇到一个非常全新且不由其他单词组成的单词时,

在Bert中,所有的中间subword前面都加 ##

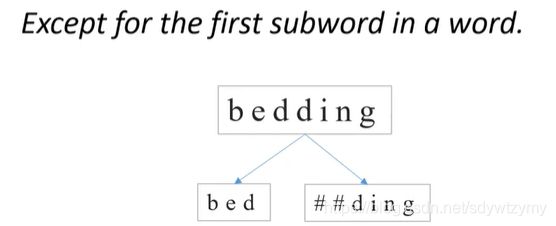
而且这个 ## 是直接加在subword前作为subword的一部分的,因此比如 ding 和 ##ding 都会存在,这是一个redundant
Bert的vocabulary list:

(注意:这里这个作者用的是1-indexed,实际上Bert使用的是0-indexed,所以UNK是100,CLS是101,以此类推)
其中individual character那儿包含了中文英文阿拉伯文等各种character


在做attention mask和token type id操作时,它们实际上是根据input id来的,所以需要加上[CLS] 和 [SEP]
例子来源于Transformer的一个官方案例:
sequence_a = "This is a short sequence." sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
encoded_sequence_b == [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]
mask_attention_b == [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
sequence_a = "HuggingFace is based in NYC" sequence_b = "Where is HuggingFace based?"
encoded_sequence = tokenizer.encode(sequence_a, sequence_b) assert tokenizer.decode(encoded_sequence) == "[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]"
assert encoded_dict['input_ids'] == [101, 20164, 10932, 2271, 7954, 1110, 1359, 1107, 17520, 102, 2777, 1110, 20164, 10932, 2271, 7954, 1359, 136, 102] assert encoded_dict['token_type_ids'] == [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]