P25 现有网络模型的使用及修改
模型的默认下载位置:
![]()
一、看文档


找到这个数据集 在torch.datasets


二、Imagnet数据集与VGG16模型下载
1、先安装下scipy吧
2、下载数据集
import torch
import torchvision
train_data=torchvision.datasets.ImageNet("./P25_ImageNet_datasets",split='train',
transform=torchvision.transforms.ToTensor()
报错了:数据集未公开,让自己去下载

3、可以去百度搜索数据集名字,一般会有下载渠道,但是这玩意100多个G。。顶不住。
4、按住ctrl+左键点击ImageNet

5、看下VGG16 预训练分别为True和False有什么区别吧:
飘过一条弹幕,感觉应该挺重要
弹幕说:
最新版默认是没有预训练,需要使用预训练设置weights=‘DEFAULT’

pretrained=False 改为weight=None pretrained=True改weights=‘DEFAULT’
我们来看下:最新文档。要想用训练好的,这里需要输入 VGG16_Weights.DEFAULT或者weights=‘DEFAULT’ or weights=‘IMAGENET1K_V1’.
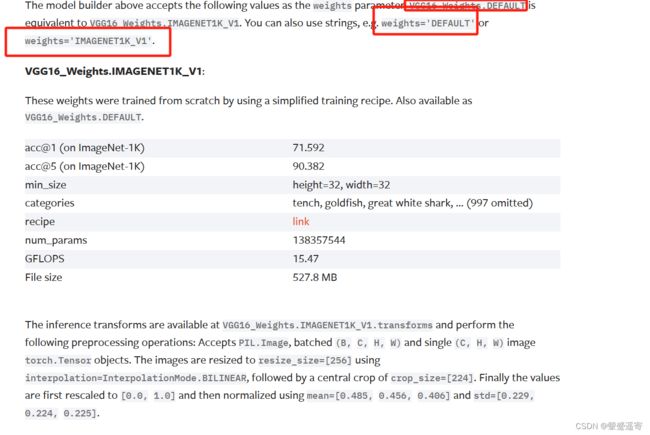 可以看到设置为Default时,会下载这些权重,他们就相当于我们之前写模型里的conv卷积数据,maxpool池化数据等等。
可以看到设置为Default时,会下载这些权重,他们就相当于我们之前写模型里的conv卷积数据,maxpool池化数据等等。

6、debug一下

来看参数:
未训练:

训练好的:

还是有差别的。
6、看下其训练好的结构
import torch
import torchvision
# train_data=torchvision.datasets.ImageNet("./P25_ImageNet_datasets",split='train',
# transform=torchvision.transforms.ToTensor()
# )
vgg16_false=torchvision.models.vgg16(weights=None)
vgg16_true=torchvision.models.vgg16(weights='DEFAULT')
print(vgg16_true)
步骤挺多的
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
能分出类别达到1000种

三、VGG16训练好的,应用在CIFAR10数据集,add_module的用法
问题来了,VGG16最后线性层输出为1000种,而我们的CIFAR10只有10类,如何利用现有的网络去改变结构。也就是迁移学习
1、我们可以加一个线性层,让他输入1000,输出为10
import torch
import torchvision
from torch import nn
# train_data=torchvision.datasets.ImageNet("./P25_ImageNet_datasets",split='train',
# transform=torchvision.transforms.ToTensor()
# )
vgg16_false=torchvision.models.vgg16(weights=None)
vgg16_true=torchvision.models.vgg16(weights='DEFAULT')
print(vgg16_true)
train_data=torchvision.datasets.CIFAR10("./P25_datasets_Cifar10",
train=True,transform=torchvision.transforms.ToTensor(),
download=True )
vgg16_true.add_module("add_linear",nn.Linear(1000,10))//这里加入新神经元。//
print(vgg16_true)


1、1我们想把add_linear加入classifier里呢?
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
进去了

2、我们不添加,想直接在原来的基础上修改最后一个线性层输入为4096,输出为10
print(vgg16_false)
vgg16_false.classifier[6]=nn.Linear(4096,10) //关键//
print(vgg16_false)
修改前:

修改后:
