- Python 进阶学习之全栈开发学习路线
Microi风闲
【胶水语言】Pythonpython学习开发语言
文章目录前言一、Python全栈开发技术栈1.前端技术选型2.后端框架选择3.数据库访问二、开发环境配置1.工具链推荐2.VSCode终极配置3.项目依赖管理三、现代Python工程实践1.项目结构规范2.自动化测试策略3.CI/CD流水线四、部署策略大全1.传统服务器部署2.容器化部署3.无服务器部署五、性能优化技巧1.数据库优化2.异步处理3.静态资源优化结语前言Python作为当今最流行的编
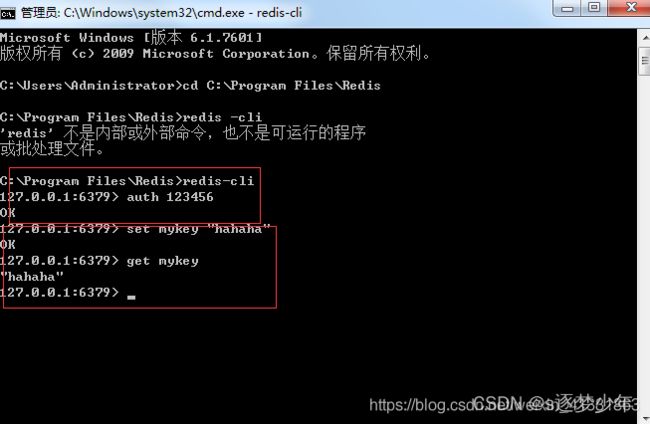
- Java学习----Redis集群
典孝赢麻崩乐急
java学习redis
在分布式系统开发中,Redis作为高性能的键值存储数据库,被广泛用于缓存、会话存储、消息队列等场景。当单节点Redis无法满足高并发、大容量的需求时,Redis集群成为解决性能瓶颈和数据可靠性问题的关键方案。Redis集群是Redis提供的分布式解决方案,通过将数据分片存储在多个节点上,实现数据的分布式存储和负载均衡。它由多个Redis节点组成,节点之间通过gossip协议进行通信,共同承担数据存
- Shader编写指南(六十一):使用 Visual Studio 调试 Unity 着色器(Windows 平台)
小李也疯狂
visualstudiounity着色器shader
在Windows平台上,可通过VisualStudio结合DirectX11/12对Unity着色器进行调试。以下是详细步骤及注意事项:一、准备工作:启用调试符号在需要调试的着色器中添加编译指令,确保生成包含调试符号的代码:hlsl#pragmaenable_d3d11_debug_symbols//启用DirectX11调试符号//或针对DirectX12(需配合PIX调试)注意:该指令会导致性
- Mysql主从复制
技术栈壳
mysql数据库
一、什么是主从复制1、Master(主数据库)将用户的操作命令以二进制的方式保存到bin-log下。2、Slave(从数据库)通过io进程,连接到主数据库,请求主数据库当中指定日志文件中的指定位置后的内容。3、Master接收到io的请求后,负责将IO所需要指定请求信息,发送给Slave的IO进程。4、Slave的IO进程收到信息后,将日志信息发添加Slave到中继日志relay-log的最末端。
- Linux-Mysql 日志
文章目录(一)二进制日志(二)错误日志(三)慢查询日志此处主要记录关于常用日志的作用和用法(一)二进制日志主要用于数据备份1)登入数据库,查看二进制日志是否打开,默认是OFF状态showvariableslike'%log_bin%'2)进入配置文件vim/etc/my.cnf添加以下参数log-bin=mysql-binserver_id=2#id必须唯一binlog_format=ROWexp
- linux-日志服务
Code Rhythm
Linuxlinux运维服务器
linux-日志服务一、rsyslog1.配置文件2.消息级别3.设备类型二、日志轮转1.主配置文件2.配置日志轮转功能3.结合cron使用总结一、rsyslogrsyslog是Linux/Unix系统上的一款高性能、模块化的日志管理服务,用于收集、处理、过滤和转发系统日志及应用程序日志。支持多种协议(如TCP/UDP/TLS)、数据库存储(MySQL/PostgreSQL)、远程日志转发等高级功
- Java 性能调优实战:JVM 参数配置与 GC 日志分析
Java性能调优实战:JVM参数配置与GC日志分析(10000字)一、Java性能调优的核心概念在现代企业级应用中,Java应用的性能直接影响用户体验、系统吞吐量以及资源利用率。因此,Java性能调优成为开发和运维团队的重要任务。性能调优的核心目标是提升应用的响应速度、减少延迟、优化资源使用,并确保系统在高并发环境下保持稳定。Java应用的性能优化涉及多个层面,包括代码优化、数据库访问优化、网络通
- MySQL索引机制解析:B+树、索引类型与优化策略
hdzw20
mysql复习mysqlb树数据库
MySQL索引机制解析:B+树、索引类型与优化策略索引是MySQL数据库中提高查询效率的关键。深入理解索引的底层机制、不同类型及其优化策略,对于数据库性能调优和面试准备都至关重要。本文将围绕B+树、聚簇索引与非聚簇索引、索引下推、覆盖索引以及自适应哈希索引等核心概念进行阐述。1.B+树vsB树:为何MySQL选择B+树?B树(B-tree)和B+树(B±tree)都是常用的多路平衡查找树,它们旨在
- MySQL存储引擎核心:了解Buffer Pool与Page管理机制
hdzw20
mysql数据库
MySQL存储引擎核心:了解BufferPool与Page管理机制1.BufferPool:数据库的高速缓存1.1基本概念作用:缓存表数据与索引数据,减少磁盘IO组成:缓存数据页(Page,默认16KB)控制块(约800字节,记录表空间、页号、缓存页地址等)默认大小:128MB(控制块额外占用约5%内存)1.2工作流程查询过程:通过哈希表(Key=表空间号+页号)判断页是否在BufferPool缓
- MySQL新建用户与授权
守优
方法一:mysql>insertintomysql.user(Host,User,Password)values("localhost","zhangs",password("123456"));mysql>flushprivileges;解释:这样就创建了一个用户名为zhangs,密码为123456的数据库用户;此处的"localhost",是指该用户只能在本地登录,不能在另外一台机器上远程登录
- Redis Copy-on-Write机制:
SHENKEM
redis数据库缓存
Copy-on-Write机制:父子进程共享内存页当父进程修改数据时,内核会复制被修改的页这可能导致内存使用量暂时增加通俗的话描述一下可以用一个生活中的例子来通俗解释Copy-on-Write(写时复制)机制:比喻:父子共用一本作业本假设有一对父子(父进程和子进程)要完成以下任务:初始状态:父亲有一本写满数据的作业本(Redis内存数据),现在孩子需要做一份完全相同的作业(RDB持久化)。传统方式
- 【无标题】
PyQt5相关论文方向扩充及技术特性解析PyQt5的核心优势PyQt5作为基于Qt框架的Python绑定库,在科研与工程应用中具备显著优势。其跨平台兼容性极强,可在Windows、macOS、Linux等主流操作系统上稳定运行,且能保持界面风格的一致性,这对开发多场景应用系统至关重要。在界面设计方面,PyQt5提供了丰富的UI组件库,从基础的按钮、文本框到高级的图表、3D控件应有尽有,同时支持Qt
- 抽象文档模式
hello 早上好
设计模式开发语言java
抽象文档模式在软件开发中,我们经常需要处理半结构化数据(如JSON、XML、文档数据库中的文档)。这类数据的特点是结构灵活,可能存在嵌套关系,且字段可能动态变化。传统的面向对象设计可能需要为每种数据结构定义大量类,导致代码冗余和维护困难。这时候,抽象文档模式(AbstractDocumentPattern)就能派上用场。本文将通过一个完整的Java案例,详细讲解抽象文档模式的实现原理、设计思路和实
- Mysql 数据库结构优化
Mysql数据库结构优化✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨数据库结构优化数据库结构优化是提升系统性能的关键环节,需结合业务场景、数据特征及访问模式,从数据组织、存储效率、查询逻辑等多维度进行设计。以下是系统化的优化策略及实践建议:一、垂直拆分:分解大表,降低单表复杂度当单表字段过多(如超过50个)或包含大量低频字段时,垂直拆分是最直接的优化手段。核心思路:将表按字段使用频率或业务功能拆分为主表与扩展表
- Apache Ignite 的并发控制:实现高性能事务处理的关键
AI天才研究院
AI实战AI人工智能与大数据LLM大模型落地实战指南大数据人工智能语言模型AILLMJavaPython架构设计AgentRPA
1.背景介绍随着大数据时代的到来,数据量的增长和计算能力的提升使得传统的数据库和计算模型已经无法满足业务需求。为了应对这些挑战,分布式计算和存储技术得到了广泛的研究和应用。ApacheIgnite是一款高性能的分布式数据库和计算平台,它可以提供实时性能和高可用性,同时支持事务处理和并发控制。在这篇文章中,我们将深入探讨ApacheIgnite的并发控制机制,以及如何实现高性能事务处理。我们将从以下
- Apache Ignite SQL索引全面指南
吕曦耘George
ApacheIgniteSQL索引全面指南索引概述在ApacheIgnite分布式数据库中,索引是优化SQL查询性能的核心机制。Ignite提供了多种索引类型和配置方式,帮助开发者根据不同的业务场景构建高效的查询系统。索引类型与创建方式1.自动创建索引Ignite会自动为以下字段创建索引:主键字段(PrimaryKey)亲和键字段(AffinityKey)这些基础索引为分布式查询提供了基本支持。2
- Apache Ignite SQLLine工具使用指南
侯霆垣
ApacheIgniteSQLLine工具使用指南概述ApacheIgnite作为一个分布式内存计算平台,提供了完整的SQL功能支持。SQLLine是Ignite内置的一个命令行工具,它允许开发者和数据库管理员通过交互式方式执行SQL查询和管理Ignite集群。本文将详细介绍如何使用SQLLine工具与Ignite集群进行交互。SQLLine工具简介SQLLine是一个基于控制台的JDBC客户端工
- nodejs、nvm、npm的使用
1.nvm的下载进入nvmgithub地址,下载最新版本:Releases·coreybutler/nvm-windows·GitHub2.傻瓜式安装。安装完成后,路径到C盘,安装路径有两个。NVM_SYMLINK:C:\ProgramFiles\nodejsNVM_HOME:C:\Users\Administrator\AppData\Roaming\nvm3.nvm使用命令查看nodejs安装
- 开源短链接工具 Sink 无需服务器 轻松部署到 Workers / Pages
本文首发于只抄博客,欢迎点击原文链接了解更多内容。前言Sink是一款开源免费的短链接生成工具,支持自定义短链接Slug以及设置到期时间,并且还可以借助Cloudflare的AnalyticsEngine功能分析短链接的统计数据。最重要的是实现以上这些功能并不需要有自己的服务器,Sink可以100%运行在Cloudflare上,主程序部署在CF的Workers或者Pages上,数据库存储在CF的KV
- Python文件路径操作全面指南:从基础到高级应用
Monkey的自我迭代
python开发语言
文件路径操作是Python编程中不可或缺的核心技能,无论是数据科学、Web开发还是自动化办公,都离不开对文件路径的有效管理。本文将系统性地介绍Python中文件路径操作的各类方法,帮助您掌握这一关键技术。一、文件路径基础概念1.1路径类型解析文件路径主要分为两种类型,理解它们的区别是路径操作的基础:绝对路径:从文件系统根目录开始的完整路径,如Windows系统中的C:\Users\Username
- QT系统托盘应用程序
weixin_30532987
操作系统游戏
在QT中QSystemTrayIcon类提供了创建系统托盘程序的功能。QSystemTrayIcon类为系统托盘中的应用程序提供图标。现代操作系统通常会在桌面上提供一个称为系统托盘(systemtray)或通知(notification)区域的特殊区域,其中长时间运行的应用程序可以显示图标和短消息。QSystemTrayIcon类可以在以下平台上使用:所有受支持的Windows版本。X11的所有窗
- Android Room使用方法与底层原理详解
你过来啊你
androidroom
Room是一个强大的SQLite对象映射库,旨在提供更健壮、更简洁、更符合现代开发模式的数据库访问方式。核心价值:消除大量样板代码,提供编译时SQL验证,强制结构化数据访问,并流畅集成LiveData、Flow和RxJava以实现响应式UI。一、使用流程(Step-by-StepWorkflow)Room的使用遵循一个清晰的结构化流程:添加依赖://build.gradle(Module)depe
- Redis——BigKey
A2274
Java面试#RedisredisjavaBigKey
BigKey1多大算BigKey?阿里云Redis开发规范:string类型的数据控制在10KB以内,hash,list,set,zset元素数量不要超过5000。非字符串的BigKey,不要使用del删除,而是使用hsacn,sscan,zscan方式渐进式删除。同时,要防止BigKey过期时自动删除,因为自动删除会使用del指令。2.BigKey有什么危害?如果没有配置Redis非阻塞删除,则
- 【MoodVine】DeepSeek聊天持久化(2):Spring AI + Redis实现对话记忆管理
一只鱼吖
【西瓜和晚霞】MoodVinespringredisjava
在上一篇文章中,我们介绍了如何引入SpringAI,本文将深入探讨如何实现聊天记录的持久化存储。一、初始方案:内存存储的局限性在项目初期,我们使用简单的内存存储实现聊天记录管理:创建ChatController@RestController@RequestMapping("/chat")publicclassChatController{privatefinalOllamaChatModeloll
- 查询一天时间unixtime时间戳的数据
亚林瓜子
sql
问题数据库库里面用的unix时间戳存的数据。需要查询出这一天的数据。解决SELECT*FROMyour_tableWHEREcreated_at>=UNIX_TIMESTAMP(CURDATE())-28800--减去8小时(8*3600秒)ANDcreated_at<UNIX_TIMESTAMP(CURDATE()+INTERVAL1DAY)-28800;
- 【大模型记忆实战Demo】基于SpringAIAlibaba通过内存和Redis两种方式实现多轮记忆对话
Sao_E
redis数据库缓存ai语言模型
文章目录多轮对话记忆管理——基于Memory的对话记忆基于内存存储历史对话基于Redis存储历史对话多轮对话记忆管理——基于Memory的对话记忆SpringAIAlibaba共实现了三种方式:基于内存的方式基于jdbc(数据库)的方式基于redis的方式下文主要演示基于内存和redis的方式基于内存存储历史对话代码首先定义大模型的角色,一个旅游规划师设置增强拦截器接着接口传入prompt和cha
- redis-plus-plus安装与使用
Yu_Lijing
redis数据库缓存
目录一.安装hiredis二.接口三.使用四.总结C++操作redis的库有很多.咱们使用redis-plus-plus.这个库的功能强大,使用简单.Github地址:https://github.com/sewenew/redis-plus-plus一.安装hiredisredis-plus-plus是基于hiredis实现的.hiredis是一个C语言实现的redis客户端.因此需要先安装hi
- Git小白 的正确使用姿势与最佳实践
-睡到自然醒~
gitelasticsearch大数据golang开发语言后端python
Git是由Linux之父LinusTorvalds在2005年创造的,目的是为了管理Linux内核的开发。Git的设计目标是实现高效的分支和合并,以及对大型项目的快速处理。1.安装Git要开始使用Git,你需要先安装Git的客户端软件。你可以从官方网站下载适合你的操作系统的安装包,或者使用你的包管理器来安装。例如,在Windows系统上,你可以下载并运行GitforWindows的安装程序。安装完
- 时序数据库主流产品概览
时序数据说
时序数据库数据库物联网iotdb大数据
时序数据库(TimeSeriesDatabase,TSDB)是专为处理时间序列数据优化的数据库系统,近年来随着物联网(IoT)、金融科技、工业互联网等领域的快速发展而备受关注。本文将介绍当前主流的时序数据库产品。一、时序数据库概述时序数据是带时间戳记录的数据点序列,具有以下特点:数据时间属性强数据通常为追加写入近期数据访问频率高于历史数据数据量通常非常庞大,需要高效的压缩技术时序数据库针对这些特点
- TDengine时序数据库数据写入操作详解
沈宝彤
TDengine时序数据库数据写入操作详解引言TDengine作为一款高性能的时序数据库,其数据写入方式与传统关系型数据库有所不同。本文将详细介绍TDengine中各种数据写入方式的特点和使用场景,帮助开发者更好地理解和应用TDengine的数据写入功能。基础写入操作单条数据写入在TDengine中,最基本的写入方式是使用INSERT语句向单个子表写入一条数据。以智能电表场景为例:--指定列名写入
- 插入表主键冲突做更新
a-john
有以下场景:
用户下了一个订单,订单内的内容较多,且来自多表,首次下单的时候,内容可能会不全(部分内容不是必须,出现有些表根本就没有没有该订单的值)。在以后更改订单时,有些内容会更改,有些内容会新增。
问题:
如果在sql语句中执行update操作,在没有数据的表中会出错。如果在逻辑代码中先做查询,查询结果有做更新,没有做插入,这样会将代码复杂化。
解决:
mysql中提供了一个sql语
- Android xml资源文件中@、@android:type、@*、?、@+含义和区别
Cb123456
@+@?@*
一.@代表引用资源
1.引用自定义资源。格式:@[package:]type/name
android:text="@string/hello"
2.引用系统资源。格式:@android:type/name
android:textColor="@android:color/opaque_red"
- 数据结构的基本介绍
天子之骄
数据结构散列表树、图线性结构价格标签
数据结构的基本介绍
数据结构就是数据的组织形式,用一种提前设计好的框架去存取数据,以便更方便,高效的对数据进行增删查改。正确选择合适的数据结构,对软件程序的高效执行的影响作用不亚于算法的设计。此外,在计算机系统中数据结构的作用也是非同小可。例如常常在编程语言中听到的栈,堆等,就是经典的数据结构。
经典的数据结构大致如下:
一:线性数据结构
(1):列表
a
- 通过二维码开放平台的API快速生成二维码
一炮送你回车库
api
现在很多网站都有通过扫二维码用手机连接的功能,联图网(http://www.liantu.com/pingtai/)的二维码开放平台开放了一个生成二维码图片的Api,挺方便使用的。闲着无聊,写了个前台快速生成二维码的方法。
html代码如下:(二维码将生成在这div下)
? 1
&nbs
- ImageIO读取一张图片改变大小
3213213333332132
javaIOimageBufferedImage
package com.demo;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
/**
* @Description 读取一张图片改变大小
* @author FuJianyon
- myeclipse集成svn(一针见血)
7454103
eclipseSVNMyEclipse
&n
- 装箱与拆箱----autoboxing和unboxing
darkranger
J2SE
4.2 自动装箱和拆箱
基本数据(Primitive)类型的自动装箱(autoboxing)、拆箱(unboxing)是自J2SE 5.0开始提供的功能。虽然为您打包基本数据类型提供了方便,但提供方便的同时表示隐藏了细节,建议在能够区分基本数据类型与对象的差别时再使用。
4.2.1 autoboxing和unboxing
在Java中,所有要处理的东西几乎都是对象(Object)
- ajax传统的方式制作ajax
aijuans
Ajax
//这是前台的代码
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <% String path = request.getContextPath(); String basePath = request.getScheme()+
- 只用jre的eclipse是怎么编译java源文件的?
avords
javaeclipsejdktomcat
eclipse只需要jre就可以运行开发java程序了,也能自动 编译java源代码,但是jre不是java的运行环境么,难道jre中也带有编译工具? 还是eclipse自己实现的?谁能给解释一下呢问题补充:假设系统中没有安装jdk or jre,只在eclipse的目录中有一个jre,那么eclipse会采用该jre,问题是eclipse照样可以编译java源文件,为什么呢?
&nb
- 前端模块化
bee1314
模块化
背景: 前端JavaScript模块化,其实已经不是什么新鲜事了。但是很多的项目还没有真正的使用起来,还处于刀耕火种的野蛮生长阶段。 JavaScript一直缺乏有效的包管理机制,造成了大量的全局变量,大量的方法冲突。我们多么渴望有天能像Java(import),Python (import),Ruby(require)那样写代码。在没有包管理机制的年代,我们是怎么避免所
- 处理百万级以上的数据处理
bijian1013
oraclesql数据库大数据查询
一.处理百万级以上的数据提高查询速度的方法: 1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 o
- mac 卸载 java 1.7 或更高版本
征客丶
javaOS
卸载 java 1.7 或更高
sudo rm -rf /Library/Internet\ Plug-Ins/JavaAppletPlugin.plugin
成功执行此命令后,还可以执行 java 与 javac 命令
sudo rm -rf /Library/PreferencePanes/JavaControlPanel.prefPane
成功执行此命令后,还可以执行 java
- 【Spark六十一】Spark Streaming结合Flume、Kafka进行日志分析
bit1129
Stream
第一步,Flume和Kakfa对接,Flume抓取日志,写到Kafka中
第二部,Spark Streaming读取Kafka中的数据,进行实时分析
本文首先使用Kakfa自带的消息处理(脚本)来获取消息,走通Flume和Kafka的对接 1. Flume配置
1. 下载Flume和Kafka集成的插件,下载地址:https://github.com/beyondj2ee/f
- Erlang vs TNSDL
bookjovi
erlang
TNSDL是Nokia内部用于开发电信交换软件的私有语言,是在SDL语言的基础上加以修改而成,TNSDL需翻译成C语言得以编译执行,TNSDL语言中实现了异步并行的特点,当然要完整实现异步并行还需要运行时动态库的支持,异步并行类似于Erlang的process(轻量级进程),TNSDL中则称之为hand,Erlang是基于vm(beam)开发,
- 非常希望有一个预防疲劳的java软件, 预防过劳死和眼睛疲劳,大家一起努力搞一个
ljy325
企业应用
非常希望有一个预防疲劳的java软件,我看新闻和网站,国防科技大学的科学家累死了,太疲劳,老是加班,不休息,经常吃药,吃药根本就没用,根本原因是疲劳过度。我以前做java,那会公司垃圾,老想赶快学习到东西跳槽离开,搞得超负荷,不明理。深圳做软件开发经常累死人,总有不明理的人,有个软件提醒限制很好,可以挽救很多人的生命。
相关新闻:
(1)IT行业成五大疾病重灾区:过劳死平均37.9岁
- 读《研磨设计模式》-代码笔记-原型模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* Effective Java 建议使用copy constructor or copy factory来代替clone()方法:
* 1.public Product copy(Product p){}
* 2.publi
- 配置管理---svn工具之权限配置
chenyu19891124
SVN
今天花了大半天的功夫,终于弄懂svn权限配置。下面是今天收获的战绩。
安装完svn后就是在svn中建立版本库,比如我本地的是版本库路径是C:\Repositories\pepos。pepos是我的版本库。在pepos的目录结构
pepos
component
webapps
在conf里面的auth里赋予的权限配置为
[groups]
- 浅谈程序员的数学修养
comsci
设计模式编程算法面试招聘
浅谈程序员的数学修养
- 批量执行 bulk collect与forall用法
daizj
oraclesqlbulk collectforall
BULK COLLECT 子句会批量检索结果,即一次性将结果集绑定到一个集合变量中,并从SQL引擎发送到PL/SQL引擎。通常可以在SELECT INTO、
FETCH INTO以及RETURNING INTO子句中使用BULK COLLECT。本文将逐一描述BULK COLLECT在这几种情形下的用法。
有关FORALL语句的用法请参考:批量SQL之 F
- Linux下使用rsync最快速删除海量文件的方法
dongwei_6688
OS
1、先安装rsync:yum install rsync
2、建立一个空的文件夹:mkdir /tmp/test
3、用rsync删除目标目录:rsync --delete-before -a -H -v --progress --stats /tmp/test/ log/这样我们要删除的log目录就会被清空了,删除的速度会非常快。rsync实际上用的是替换原理,处理数十万个文件也是秒删。
- Yii CModel中rules验证规格
dcj3sjt126com
rulesyiivalidate
Yii cValidator主要用法分析:
yii验证rulesit 分类: Yii yii的rules验证 cValidator主要属性 attributes ,builtInValidators,enableClientValidation,message,on,safe,skipOnError
- 基于vagrant的redis主从实验
dcj3sjt126com
vagrant
平台: Mac
工具: Vagrant
系统: Centos6.5
实验目的: Redis主从
实现思路
制作一个基于sentos6.5, 已经安装好reids的box, 添加一个脚本配置从机, 然后作为后面主机从机的基础box
制作sentos6.5+redis的box
mkdir vagrant_redis
cd vagrant_
- Memcached(二)、Centos安装Memcached服务器
frank1234
centosmemcached
一、安装gcc
rpm和yum安装memcached服务器连接没有找到,所以我使用的是make的方式安装,由于make依赖于gcc,所以要先安装gcc
开始安装,命令如下,[color=red][b]顺序一定不能出错[/b][/color]:
建议可以先切换到root用户,不然可能会遇到权限问题:su root 输入密码......
rpm -ivh kernel-head
- Remove Duplicates from Sorted List
hcx2013
remove
Given a sorted linked list, delete all duplicates such that each element appear only once.
For example,Given 1->1->2, return 1->2.Given 1->1->2->3->3, return&
- Spring4新特性——JSR310日期时间API的支持
jinnianshilongnian
spring4
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- 浅谈enum与单例设计模式
247687009
java单例
在JDK1.5之前的单例实现方式有两种(懒汉式和饿汉式并无设计上的区别故看做一种),两者同是私有构
造器,导出静态成员变量,以便调用者访问。
第一种
package singleton;
public class Singleton {
//导出全局成员
public final static Singleton INSTANCE = new S
- 使用switch条件语句需要注意的几点
openwrt
cbreakswitch
1. 当满足条件的case中没有break,程序将依次执行其后的每种条件(包括default)直到遇到break跳出
int main()
{
int n = 1;
switch(n) {
case 1:
printf("--1--\n");
default:
printf("defa
- 配置Spring Mybatis JUnit测试环境的应用上下文
schnell18
springmybatisJUnit
Spring-test模块中的应用上下文和web及spring boot的有很大差异。主要试下来差异有:
单元测试的app context不支持从外部properties文件注入属性
@Value注解不能解析带通配符的路径字符串
解决第一个问题可以配置一个PropertyPlaceholderConfigurer的bean。
第二个问题的具体实例是:
- Java 定时任务总结一
tuoni
javaspringtimerquartztimertask
Java定时任务总结 一.从技术上分类大概分为以下三种方式: 1.Java自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务; 说明: java.util.Timer定时器,实际上是个线程,定时执行TimerTask类 &
- 一种防止用户生成内容站点出现商业广告以及非法有害等垃圾信息的方法
yangshangchuan
rank相似度计算文本相似度词袋模型余弦相似度
本文描述了一种在ITEYE博客频道上面出现的新型的商业广告形式及其应对方法,对于其他的用户生成内容站点类型也具有同样的适用性。
最近在ITEYE博客频道上面出现了一种新型的商业广告形式,方法如下:
1、注册多个账号(一般10个以上)。
2、从多个账号中选择一个账号,发表1-2篇博文