Transformer 系列 Interpret Vision Transformers as ConvNets with Dynamic Convolutions 论文阅读笔记
Transformer 系列 Interpret Vision Transformers as ConvNets with Dynamic Convolutions 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- Vision Transformers
- 动态卷积
- Transformer 和 CNN 的联系
- 四、统一的视角
-
- 4.1 基础:自注意力
- 4.2 将 Self-Attention 视为动态卷积
- 4.3 统一的框架
-
- Kernel bank
- kernel 选择
- Kernel 类型
- Kernel size
- 五、重新思考 Vision Transformers 的设计
-
- 5.1 实验设置
- 5.2 Softmax 的作用
- 5.3 逐深度 Vision Transformers
- 六、讨论
-
- 将来的工作
- A、更多的收敛曲线
- B、实施细节
写在前面
朋友们,国庆快乐呀~,
这是一篇结合 CNN 和 Transformer 的理念文章,可惜没有代码。
- 论文地址: Interpret Vision Transformers as ConvNets with Dynamic Convolutions
- 代码地址:原文未提供
- 预计投稿于:CVPR 2024
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
在 Vision Transformer 和 CNNs 间总存在争论:哪个网络好。而本文将 Vision Transformer 视为带动态卷积的 CNNs,这能够将现有的 Transformer 和动态 CNNs 统一为一个框架并逐点比较它们的设计。从两个方面来论证上述的研究:检查了 vision Transformer 中 softmax 结构,发现其能够被广泛使用的 CNNs 模块代替,例如 ReLU,Layer Normalization,收敛速度更快,性能更高;建立一个对应的视觉 Transformer,效率更高,性能更好。
二、引言
前面是一些基础 CNN 和 Transformer 网络的介绍,略过。承上启下的一句:基于 CNNs 的方法和 Transformer 的方法,孰优孰劣仍存在争论。于是本文提出将 vision Transformer 转化为 CNNs,并建立一个统一框架。

如上图所示,在 self-attention 中,将 query-key 和 attention-value 的矩阵乘法视为两个 1 × 1 1\times1 1×1 的动态卷积,并将 softmax 操作视为一个激活函数。于是 self-attention 中相应的卷积块为 static conv. → dynamic conv. → activation → dynamic conv. → static conv. 这一改造适用于 ViT 及其变体,例如 Swin Transformer。
通过比较 CNN 和 Transformer,现在可以重新设计一个框架,于是进行两方面的研究:首先调查 softmax 在 sekf-attention 中作为激活函数的作用;另一方面,一些类似 “S” 形状的激活函数,已经很少采用,反而一些非 “S” 形状的激活函数,例如 ReLU,潜力很足,而 Softmax 同样也可以在输入的特征上进行归一化和通道的通信。于是本文通过消融实验探索 Softmax 能够被现有的技术代替。
此外,self-attention 中的动态卷积机制非常独特,通过一个全局的 kernel bank,从一个空间位置上生成的核能够在其他位置上共享。这比为每个空间位置上生成一组新核更有效。于是本文结合动态卷积的特性,在保持 Transformer 中的 kenerl bank 机制的同时,采用单个逐深度卷积代替两个动态卷积。
三、相关工作
Vision Transformers
Transformer 源于 NLP,而后引入 Vision Tranformer (ViT)。也有一些方法尝试整合 ViT 和 CNN,但是仍将其考虑为两种异构结构。
动态卷积
动态卷积指的是其卷积核权基于输入而生成。有一些方法从输入的特征图中生成一组卷积核,而非空间位置。在本文的发现中,Vision Transformer 不仅共享动态卷积,且包含独特的设计用于提升效率。
Transformer 和 CNN 的联系
本文的工作不同于以往的工作,主要有三点:不假设注意力的值或者位置 embedding 的形式;转化等价且双向;转化不局限于特定的 Vision Transformer 及其变体。
四、统一的视角
4.1 基础:自注意力
首先将图像送入一个卷积 stem,从而将图像划分为一些块,之后送入 vision Transformer 的第一个自注意力 block,其输入表示为 x ∈ R N × C x\in \mathbb{R}^{N\times C} x∈RN×C, N N N 和 C C C 分别为 tokens 的数量及 embedding 的维度。然后自注意力机制将 x x x 投影为 query q q q,、key k k k、value v v v:
q = W q x + b q , k = W k x + b k , v = W v x + b v q=W_qx+b_q,k=W_kx+b_k,v=W_vx+b_v q=Wqx+bq,k=Wkx+bk,v=Wvx+bv之后:
o i = s o f t m a x ( q i k T C h ) v o_i=\mathrm{softmax}(\frac{q_ik^\mathsf{T}}{\sqrt{C_h}})v oi=softmax(ChqikT)v其中 C h C_h Ch 为每个头的 embedding 维度。
4.2 将 Self-Attention 视为动态卷积
从一般的视觉的视角来看,self-attention 可以划分为两个线性的矩阵乘法,其中又包含一个非线性激活函数(softmax)。更深入一点来看,每个 token 的输出都是每个 query 和所有 keys 和 values 的函数。换句话说,不同空间位置处的 keys 和 values 是被 queries 共享的。于是可以设计一个线性操作使得 kernel 在不同的空间位置上共享。
标准的卷积核定义为 u ∈ R H × W × C i n × C o u t u\in \mathbb{R}^{H\times W\times C_{in}\times C_{out}} u∈RH×W×Cin×Cout,其中 H H H、 W W W、 C i n C_{in} Cin 和 C o u t C_{out} Cout 分别表示核的高、宽,输入和输出的通道。在每个滑动窗口上沿着输入特征图的空间维度滑动,kernel 执行一个线性投影操作 H × W × C i n → C o u t H\times W \times C_{in} → C_{out} H×W×Cin→Cout。
自注意力中的两个矩阵乘法,本质上与 1 × 1 1\times1 1×1 卷积相同。首先,query-key 的乘法可以视为一个卷积核 k ∈ R 1 × 1 × C i n × N k\in \mathbb{R}^{1\times1\times C_{in}\times N} k∈R1×1×Cin×N,在 qeury 的特征图上滑动,其中 N N N 表示 tokens 的数量。类似的,attention-value 乘法也是一个 1 × 1 1\times1 1×1 卷积,卷积核为 v ∈ R 1 × 1 × C o u t × N v\in \mathbb{R}^{1\times1\times C_{out}\times N} v∈R1×1×Cout×N,注意力图作为输入。
与标准卷积不同的是,核 k k k、 v v v 的权重是基于输入生成的,因此视为动态卷积。
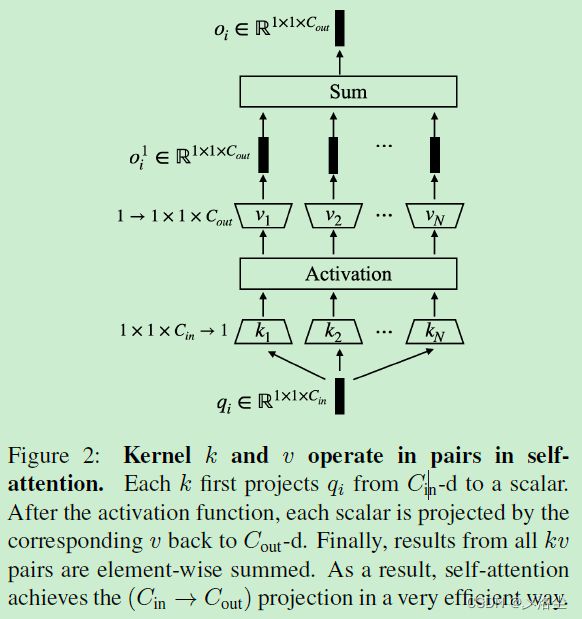
此外,如上图所示,在每个滑动窗口上, k k k 执行 N × ( 1 × 1 × C i n → 1 ) N\times(1\times1\times C_{in}→1) N×(1×1×Cin→1) 的线性操作,接着是一个 N N N 维的向量经过 softmax 函数。最后,核 v v v 将每个向量投影到 C o u t C_{out} Cout 的向量维度。后面再对所有 N N N 维度的向量求和得到 C o u t C_{out} Cout 的向量。于是总体上,自注意力实现了从 C i n C_{in} Cin 到 C o u t C_{out} Cout 的映射。
4.3 统一的框架

如上图和上表所示,将从四个方面分析 ViT、Swin Tranfromer、Linformer、Dynamic Convolution (D-Conv)、Dynamic Depth-wise Convolution (D-DWConv)。
Kernel bank
在空间维度共享相同的 kernels 有助于卷积的效率。然而当前的动态卷积并未采用共享核的方法,例如 DDW-Conv 在每个空间位置上生成一个单独的卷积核。相比之下,vision Transformers 和 D-Conv 在 kernel bank 的辅助下,重新复用这些 kernels。具体来说,D-Conv 在训练过程中维持一个可学习的 kernel bank,其中的 kernels 作为 basis 或 prototypes,线性组合为一个 kernel 用于每个输入图像。在推理过程中,kernel bank 保持不变,且在所有测试图像中共享。
而 Vision Transformers 以更细粒度的方式在单个图像的空间位置上共享 kernel。具体来说,对每个图像,kernel bank 中的核由所有空间位置生成。为了取出 bank 中的 kernel,不同的 Transformer 应用不同的规则。由于 Transformer 中的 kernel bank 是基于输入的图像,于是将其视为动态的 kernel bank,这与 D-Conv 中的静态 kernel bank 不同。
kernel 选择
如图 3 所示,ViT、Swin Transformer、Linformer 分别作为全局、局部、线性 Transformer 的代表,区别在于从 bank 中选择 kernels 的方式。具体来说,ViT 从 bank 中选择所有的 kernels 而不管输入的位置。Swin Transformer 在局部窗口内选择生成的 kernels。相比之下,Linformer 执行 soft 选择,其中所有的 kernels 送入一个轻量化的网络来生成一组少量的核。因此每组 kernel 本质上是输入 kernels 的线性组合。
除 Transformer 外,D-Conv 也采用 kernel bank 和 soft 规则。不同于 Linformer,D-Conv 显式地从输入的特征中预测线性组合的系数。此外,self-attention 中的 softmax 也隐式地影响着 kernel 的选择,因为在余弦相似性方面更偏向于更接近输入特征的核(不懂)。
Kernel 类型
直接生成标准卷积核的权重的成本很高。例如从 C C C 维度的向量中生成 kernel 权重,需要单层的权重参数为 C × H × W × C i n × C o u t C\times H\times W\times C_{\mathrm{in}}\times C_{\mathrm{out}} C×H×W×Cin×Cout,于是所有表 1 上的 Transformers 和 CNNs 均采用不同的方式来避免直接生成权重。D-DW-Conv 采用直接的方式:用一个逐深度卷积(稀疏的通道连接)来代替标准卷积。D-Conv 在静态 bank 中将权重的生成变为核的线性组合,其中仅在输入上采用轻量化的系数。
不同于动态 CNN,vision Transformers 中的自注意力实现了逐通道连接和动态 kernel bank。首先自注意力仅采用 1 × 1 1\times1 1×1 卷积,因为其不依赖于大尺度 kernel size 来聚合不同位置上的信息,而是使用彼此生成的 kernel 实现逐空间位置交互。其次,并非执行一次 C i n → C o u t C_{in} → C_{out} Cin→Cout,self-attention 将这一过程分为两步: C i n → 1 C_{in} → 1 Cin→1 和 1 → C o u t 1 → C_{out} 1→Cout。于是自注意力截断了需要的权重生成器,参数量变为 C C i n + C C o u t CC_{in}+CC_{out} CCin+CCout。
Kernel size
self-attention 中的 1 × 1 1\times1 1×1 卷积是把双刃剑,提升性能的同时并未嵌入任何空间先验,而这对大多数视觉任务有利。因此 vision Transformers 通常用位置 embedding 弥补这一缺陷。但是否可以让 self-attention 中的核变大,例如 3 × 3 3\times3 3×3,仍然值得探索。
五、重新思考 Vision Transformers 的设计
这一部分主要考虑两个实际的例子:研究 softmax 作为激活函数的作用;将逐深度的设计引入到 Vision Transformers 中。
5.1 实验设置
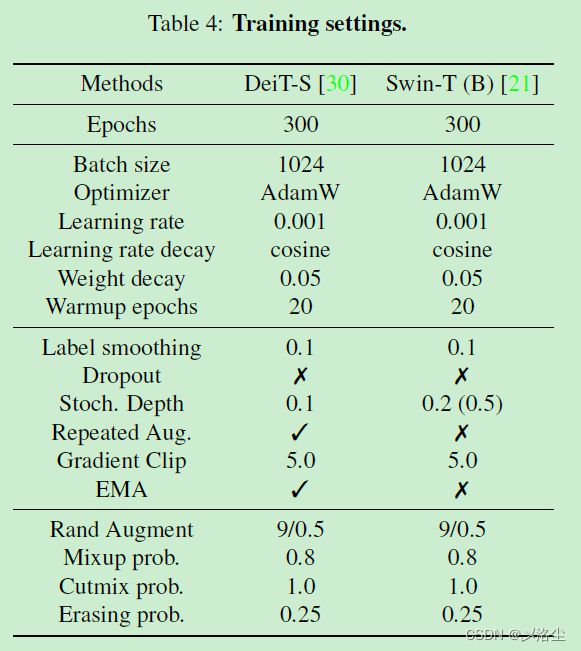
采用 MMClassification 代码库,在 ViT 和 Swin Transformer 上进行实验。ImageNet-1K 数据集,top-1 精度指标。采用 DeiT 的训练策略用于 ViT,具体来说,每张图像随机调整和裁剪到 224 × 224 224\times224 224×224,采用随机水平翻转、随机擦除。归一化方法包含 Mixup、Cutmix 、stochastic
depth、repeated augmentation、Exponential Moving Average (EMA)。AdamW 优化器,学习率 0.001,采用余弦方式衰减。300 epochs,batch_size 1024。对于 Swin Transformer,沿用其原始设定。
5.2 Softmax 的作用
s o f t m a x ( x ) i = exp ( x i / τ ) ∑ j exp ( x j / τ ) \mathrm{softmax}(x)_i=\frac{\exp{(x_i/\tau)}}{\sum_j\exp{(x_j/\tau)}} softmax(x)i=∑jexp(xj/τ)exp(xi/τ)其中 τ \tau τ 为温度常数。Softmax 有三个作用:归一化,通道通信,非线性。
实验结果如下表所示:

依据上表得出结论:归一化是重要的但不限于 Softmax。ReLU 对于 DeiT 和 Swin 而言还是更重要些。
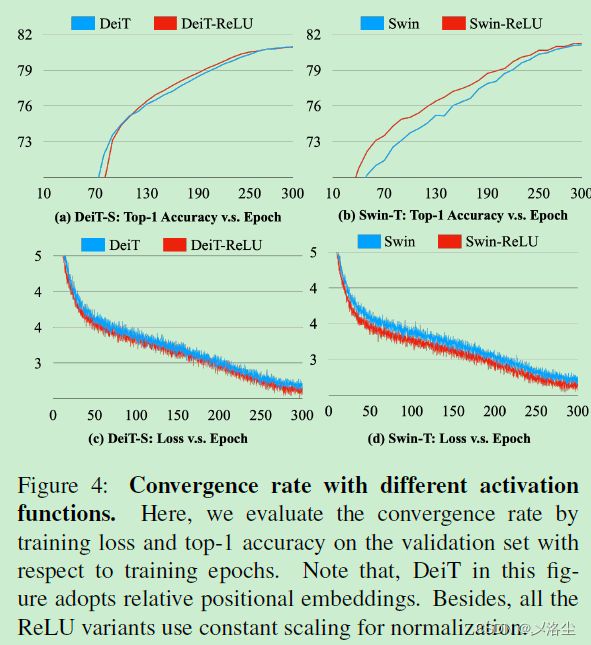
采用相对位置 embedding,ViT 和 Swin Transformer 中的 softmax 能够用 ReLU 代替,从而实现更快收敛。
5.3 逐深度 Vision Transformers

如上图所示,在 self-attention 中,利用矩阵乘法,所选的核 k ∈ R 1 × 1 × C i n × N k\mathrm{~}\in\mathbb{R}^{1\times1\times C_{\mathrm{in}}\times N} k ∈R1×1×Cin×N 和 v ∈ R 1 × 1 × N × C o u t v\in\mathbb{R}^{1\times1\times N\times C_{\mathrm{out}}} v∈R1×1×N×Cout 能够融合为一个新核 g ∈ R 1 × 1 × C i n × C o u t g\in\mathbb{R}^{1\times1\times C_{\mathrm{in}}\times C_{\mathrm{out}}} g∈R1×1×Cin×Cout,而这实际上是一个标准 1 × 1 1\times1 1×1 的核。
接下来修改原始的 self-attention。首先,去除 value kernel bank,仅保留 key kernel bank。接下来在每个空间位置上从 bank 中选择 N N N 个核(ViT 选择所有的核,Swin Transformer 选择局部核),然后将所选的核均分到单个核里。最后执行逐元素乘法,以保持输入的通道维度不变。将修改后的 self-attention 命名为 depth-wise self-attention,因为它有着自注意力中的 kernel bank 机制以及逐深度卷积中的逐元素乘法。

在没有 softmax 的情况下,self-attention 中的相对位置 embedding 可以直接应用在 values 上:
o i = ( q i k T C h + p i ) v = q i k T C h v + p i v o_i=(\frac{q_ik^\mathsf{T}}{\sqrt{C_h}}+p_i)v=\frac{q_ik^\mathsf{T}}{\sqrt{C_h}}v+p_iv oi=(ChqikT+pi)v=ChqikTv+piv然而 value kernel bank 在逐深度 self-attention 中被移除,遂采用 p p p 到 k k k 代替:
o i = q i ⊙ k ˉ + p i k o_{i}=q_{i}\odot\bar{k}+p_{i}k oi=qi⊙kˉ+pik表 3 表明了相对位置 embedding 的效果比较好,且能够减少计算成本与参数量。
六、讨论
本文提出一种新的视角,利用动态卷积将 vision Transformers 解释为 CNNs。此外,选择了一些代表性的 vision Transformer 和 CNN 方法,并将其拟合到提出的框架中。具体来说,从四个维度:kernel bank,kernel selcetion,kernel type,kernel size 进行分析。为了论证本文提出方法的潜力,提供了两个实验样本,包含 softmax 作为激活函数的作用,以及将逐深度设计引入自注意力中。
将来的工作
将空间先验通过 3 × 3 3\times3 3×3 的动态卷积注入,而非 1 × 1 1\times1 1×1;利用层级关系提升自注意力风格的动态卷积;去除自注意力中的 FFN 等等。
A、更多的收敛曲线

B、实施细节
写在后面
这篇文章偏实验一点呀,可惜代码没有放出来,但是论文的新颖性还是非常足的。要吐槽的地方在于写作逻辑作者好像有点混乱,自己提出的框架那部分没有详细说明。
回学校了,继续凎论文~