Pytorch之ConvNeXt图像分类
文章目录
- 前言
- 一、ConvNeXt设计决策
-
- 1.设计方案
- 2.Training Techniques
- 3.Macro Design
-
- Changing stage compute ratio
- Change stem to "Patchify"
- 4.ResNeXt-ify
- 5. Inverted Bottleneck
- 6.Large Kernel Size
- 7.Micro Design
-
- ✨Replacing ReLU with GELU
- ✨Fewer activation functions
- ✨Fewer normalization layers
- ✨Substituting BN with LN
- ✨Separate downsampling layers
- 二、ConvNeXt网络结构
-
- 1.网络配置参数
- 2.ConvNeXt-T 结构
- 三、ConvNeXt-T网络实现
-
- 1.构建ConvNeXt-T网络
- 2.训练和测试模型
- 四、实现图像分类
- 结束语
- 个人主页:风间琉璃
- 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
CNN自1989年以来一直存在,当时第一个多层CNN,称为ConvNet,由Yann LeCun开发。该模型可以执行视觉认知任务,例如识别手写数字。1998年,LeCun开发了一种改进的ConvNet模型,称为LeNet。由于其在光学识别任务中的高精度,LeNet在发明后不久就被工业使用。从那时起,CNN一直是工业界和学术界最成功的机器学习模型之一。下图显示了 CNN 生命周期中架构发展的简要时间表,从 1989 年一直到 2020 年,
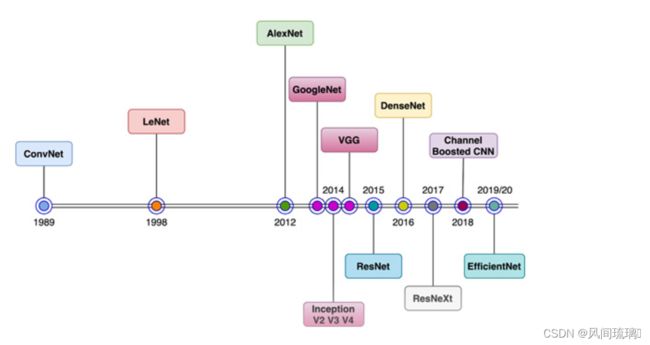
十年来,计算机视觉(CV)突飞猛进,VGGNet,GoogLeNet/Inception,ResNeXt,DenseNet,MobileNet 和 EfficientNet等一大批ImageNet竞赛的年度冠军等优秀模型蓬勃发展,你方唱罢我登场,精彩纷呈,卷积神经网络CNN作为图像处理的标配卷过了AI的大半边天。
在此之前,自然语言处理 (NLP) 和CV是像两条平行线,各自相对独立的发展。RNN和CNN是教科书中两个独立的章节,分别对应自然语言的序列(Sequence)和图像局部特征的特点。自从2017年,Google在NLP领域发表了Attention is all you need,提出基于自注意力(self-attention)的Transformer,随后ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱。
之后在CV领域发的文章绝大多数都是基于Transformer的,比如2021年ICCV 的best paper Swin Transformer,而卷积神经网络已经开始慢慢淡出舞台中央,难道卷积神经网络要被Transformer取代了吗?也许会在不久的将来。
在2022年1月,A ConvNet for the 2020s一论文提出ConvNeXt,借鉴了 Vision Transformer 和 CNN 的成功经验,构建一个纯卷积网络,其性能超越了高大上(复杂的) 基于Transformer 的先进的模型。
ConvNeXt的出现证明,并不一定需要Transformer那么复杂的结构,只对原有CNN的技术和参数优化也能达到SOTA,未来CV领域,CNN和Transformer谁主沉浮?
一、ConvNeXt设计决策
1.设计方案
作者将设计 vision Transformer(Swin) 的技巧应用到标准的卷积网络(ResNet-50)。纵坐标代表采取的操作,横坐标表示在ImageNet数据集上的top1准确率。星星表示网络的计算量。斜条纹(kernel size=9/11)表示不采取该操作。实验结果展示 在计算量相同的情况下,纯卷积网络(ConvNext)表现优于Swin Transformer。

作者首先利用训练vision Transformers的策略去训练原始的ResNet50模型,发现比原始效果要好很多,并将此结果作为后续实验的基准baseline。然后作者罗列了接下来实验包含哪些部分:
∙ \bullet ∙ macro design
∙ \bullet ∙ ResNeXt
∙ \bullet ∙ inverted bottleneck
∙ \bullet ∙ large kerner size
∙ \bullet ∙various layer-wise micro designs
依次从宏观设计,深度可分离卷积(ResNeXt),逆瓶颈层(MobileNet v2),大卷积核,细节设计这五个角度依次借鉴Swin Transformer的思想,然后在ImageNet-1K上进行训练和评估,得到ConvNeXt的核心结构。
ConvNeXt本质上没有提出新的创新点,ConvNeXt使用的全部都是现有的结构和方法,没有任何结构或者方法的创新。
2.Training Techniques
随着深度学习在各个领域上的不断探索,残差网络采用的原始策略已经不能充分的压榨残差结构的性能。Vision Transformers不仅带来新的模块和框架设计,同时也介绍了不同的训练技巧。
在ConvNeXt中,它的优化策略借鉴了Swin-Transformer。具体的优化策略包括:
∙ \bullet ∙ 将训练的epochs从原先的90增加到300。
∙ \bullet ∙ 优化器从SGD改为使用AdamW优化器。
∙ \bullet ∙ 更复杂的数据扩充策略,包括Mixup,CutMix,RandAugment,Random Erasing
∙ \bullet ∙ 增加正则策略,例如随机深度,标签平滑,EMA等
实验结果显示,ResNet-50在ImageNet数据集上的Top1准确率从 76.1%增到78.8%(+2.7%)。这表明,传统的卷积网络和vision Transformer的差异可能源于训练技巧(training techniques)的不同。
更具体的预训练和微调的超参数如下图

3.Macro Design
Swin Transformer使用multi-stage的设计,即每个stage有不同的特征图分辨率,主要包括stage compute ratio和stem cell结构。
Changing stage compute ratio
VGG提出了把骨干网络分成若干个网络块的结构,每个网络块通过池化操作将Feature Map降采样到不同的尺寸。在VGG中,每个网络块的网络层的数量基本是相同,当深层的网络块层数更多时,模型的表现更好。例如,ResNet-50中共有4个不同的网络块,它的每个网络块的层数是(3,4,6,3) ,比例大概是(1:1:2:1)。

在Swin-Transformer中,每个骨干网络被分成了4个不同的Stage,每个Stage又是由若干个Block组成,在Swin-Transformer中,这个Block的比例是**(1:1:3:1)**,而对于更大的模型来说,这个比例是(1:1:9:1) 。
ConvNeXt的改进是将ResNet-50的每个Stage的block的比例调整到(1:1:3:1) ,最终得到的block数是(3,3,9,3) ,进行调整后,准确率由78.8%提升到了79.4%。
Change stem to “Patchify”
对于ImageNet数据集,通常采用224x224的输入尺寸,该尺寸对于Transformer的模型来说是非常大的,在Transformer模型中一般都是通过一个 卷积核非常大且相邻窗口之间没有重叠的(即stride等于kernel_size)卷积层进行下采样。比如在Swin Transformer中采用的是一个卷积核大小为4x4步距为4的卷积层构成patchify(补丁化),同样是下采样4倍,这一部分在Swin-Transformer中叫做stem层,它是位于输入之后的一个降采样层。
“patchify”策略作为 stem cell使用:
∙ \bullet ∙ 使用一个大的卷积核
∙ \bullet ∙ non-overlapping卷积(stride=kernel size)
通常情况下,stem cell主要在网络的最前头用于处理输入图像。即下采样输入图像到合适的图像尺寸。
在标准的ResNet中,一般最初的下采样模块stem一般都是通过一个卷积核大小为7x7步距为2的卷积层以及一个步距为2的最大池化下采样共同组成,高和宽都下采样4倍。
在ConvNeXt中,作者将Stem层也换成和Swin Transformer一样的patchify,使用一个步长为4,大小为4的卷积操作,这一操作将准确率从79.4%提升至79.5%,GFLOPs从4.5降到4.4%。
4.ResNeXt-ify
作者采用ResNext的思想,它比普通的ResNet具有更好的FLOPs/accuracy权衡。核心部分是分组卷积(grouped convolution)即卷积核被分成不同的组,用来提升模型的计算速度。
作者使用depthwise convolution,这是分组卷积的一种特殊情况,即分组的数量等于通道的数量。如下图所示。
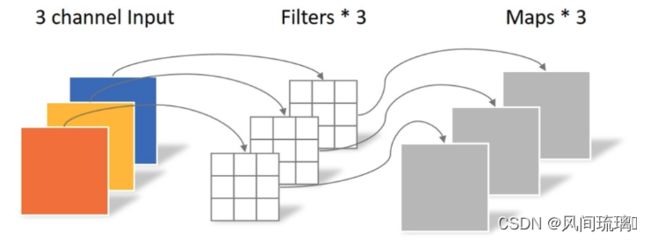
在Swin-Tranformer的Self-Attention也是以通道为单位的运算单元,不同的是可分离卷积是可学习的卷积核,Self-Attention是根据数据动态计算的权值。
在ConvNeXt中,也引入了分组卷积的思想,它将bottleneck中3x3卷积替换成了3x3 的分组卷积,这个操作将GFLOPs从4.4降到了2.4,但是它也将准确率从79.5%降到了78.3%。**为了弥补准确率的下降,它将ResNet-50的基础通道数从64增加至96。**这个操作将GFLOPs增加到了5.3,但是准确率提升到了80.5%。
5. Inverted Bottleneck
作者认为Transformer block中的MLP模块(中间层维度数是两端的4倍)非常像MobileNetV2中的Inverted Bottleneck模块,即两头细中间粗。下图a是ReNet中采用的Bottleneck模块(大维度-小维度-大维度),b是MobileNetV2采用的Inverted Botleneck模块(小维度-大维度-小维度),c是ConvNeXt采用的是Inverted Bottleneck模块。
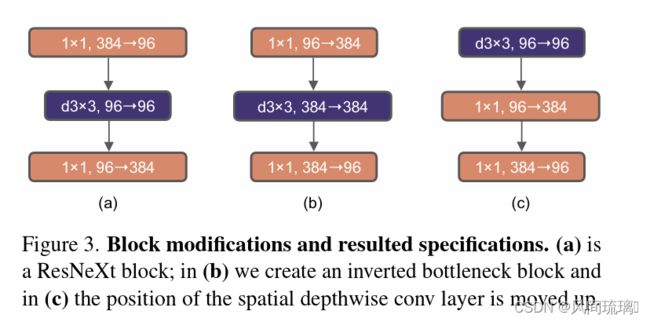
作者采用Inverted Bottleneck模块后,在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。
6.Large Kernel Size
Transformer中,non-local self-attention能够获得全局的感受野。研究者认为更大的感受野是ViT性能更好的可能原因之一,作者尝试增大卷积的kernel,使模型获得更大的感受野。
接着作者做了如下两个改动:
⋆ \star ⋆ Moving up depthwise conv layer,将depthwise conv提前到1x1 conv之前,之后用384个1x1x96的conv将模型宽度提升4倍,在用96个1x1x96的conv恢复模型宽度。
反映在上图中就是由(b)变为©,原来是1x1 conv -> depthwise conv -> 1x1 conv,现在变成了depthwise conv -> 1x1 conv -> 1x1 conv。这么做是因为在Transformer中,MSA模块是放在MLP模块之前的,所以这里进行效仿,将depthwise conv上移。由于3x3的conv数量减少,模型FLOPs由5.3G减少到4G,相应地性能暂时下降到79.9%。
⋆ \star ⋆ Increasing the kernel size,然后作者尝试增大depthwise conv的卷积核大小,证明7x7(Swin Transformer中也是7x7)大小的卷积核效果达到最佳,并且准确率从79.9% (3×3) 增长到 80.6% (7×7)。
7.Micro Design
接下来开始细节层面的讨论,主要体现在激活函数和归一化层的选择。
✨Replacing ReLU with GELU
ReLU是比较早期的激活函数,在卷积神经网络中比较常用。在Transformer中基本上选择使用GELU作为激活函数,如Swin Transformer。
GELU可以认为是ReLU的平滑版本。作者实验发现,在ConvNeXt将ReLu使用GELU代替,但是精度没有变化(80.6%)。但是为了对齐其它指标,ConvNeXt还是选择了GELU作为激活函数。
✨Fewer activation functions
在卷积神经网络中,一般会在每个卷积层或全连接后都接上一个激活函数。但在Transformer中并不是每个模块后都跟有激活函数。如下图所示,Swin Transformer block中只有MLP有一个激活函数(RELU)。
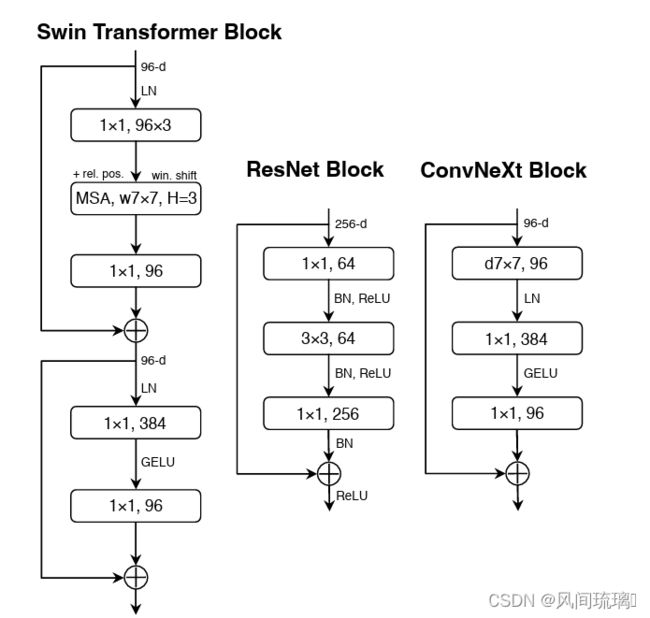
ConvNeXt也借鉴了Transformer的思想,它仅在两个1x1卷积之间添加了一个GELU激活函数。实验结果表明这个操作将准确率从80.6%提升至81.3%。
✨Fewer normalization layers
在Transformer中,Normalization使用的也比较少,接着作者也减少了ConvNeXt Block中的Normalization层,只保留了depthwise conv后的Normalization层。此时准确率已经达到了81.4%,已经超过了Swin-T。根据经验,作者发现,在block的开始添加一个额外的Normalization层并不能改善性能。
✨Substituting BN with LN
BatchNorm是卷积神经网络的重要组成部分,因为它提高了收敛性并减少了过拟合。虽然BN也有很多错综复杂的地方,会对模型的性能产生不利影响,但BN仍然是大多数视觉任务的首选方法。
但在Transformer中使用了更简单的Layer Normalization(LN),因为最开始Transformer是应用在NLP领域的,BN又不适用于NLP相关任务。接着作者将BN全部替换成了LN,发现准确率还有小幅提升达到了81.5%。
✨Separate downsampling layers
在ResNet网络中stage2-stage4的下采样都是通过将主分支上3x3的卷积层步距设置成2,short分支上1x1的卷积层步距设置成2进行下采样的。
但在Swin Transformer中是通过一个单独的Patch Merging实现的。接着作者就为ConvNext网络单独使用了一个下采样层,使用卷积核为2,步长为2的卷积层进行空间下采样操作,又因为这样会使训练不稳定,因此在每个下采样层前面增加了Laryer Normalization(LN)来稳定训练,更改后准确率就提升到了82.0%。
二、ConvNeXt网络结构
1.网络配置参数
对于ConvNeXt网络,作者提出了T/S/B/L/XL五个版本,这五个版本的配置如下:
∙ \bullet ∙ ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
∙ \bullet ∙ ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
其中C代表4个stage中输入的通道数,B代表每个stage重复堆叠block的次数,ConvNeXt-T版本如下图所示。

2.ConvNeXt-T 结构
ConvNeXt-T网络结构图如下,来自B站大佬的。

注意,ConvNeXt Block中还有一个Layer Scale操作,它就是将输入的特征层乘上一个可训练的参数,该参数就是一个向量,元素个数与特征层channel相同,即对每个channel的数据进行缩放。
三、ConvNeXt-T网络实现
1.构建ConvNeXt-T网络
2.训练和测试模型
四、实现图像分类
结束语
感谢阅读吾之文章,今已至此次旅程之终站 。
吾望斯文献能供尔以宝贵之信息与知识也 。
学习者之途,若藏于天际之星辰,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 。