最优化 - 信赖域和直接搜索
Trust Region Methods 信赖域方法
- Problem Description 问题描述
- Optimality Conditions 最优化条件
- Line Search Methods 线搜索方法
- Trust Region Methods 信赖域方法
- Direct Search Methods 直接搜索法
- Nonlinear Least Squares(NLS) 非线性最小二乘法 – LMA
文章目录
-
- Trust Region Methods 信赖域方法
-
- 信赖域算法介绍
- 数学模型
- 信赖域算法流程
- [关于子问题的最优解]
- ⭕折线算法 Dog-Leg Method
-
- 定义完全步(Full Step)
- 折线算法
- Direct Search Methods 直接搜索法
-
- 介绍
- 1. Box Search
- 2. Section 坐标搜索算法 (属于线搜索算法)
- 3. ⭕Nelder Mead
-
- 1. reflection
- 2. Explansion
- 3. outer contraction
- 4. inner contraction
- 5. shinking
- 总结 Nelder Mead 算法流程:
- Nonlinear Least Squares(NLS) 非线性最小二乘法 -- LMA
-
- 一
- 二:问题定义
- 三:问题的解
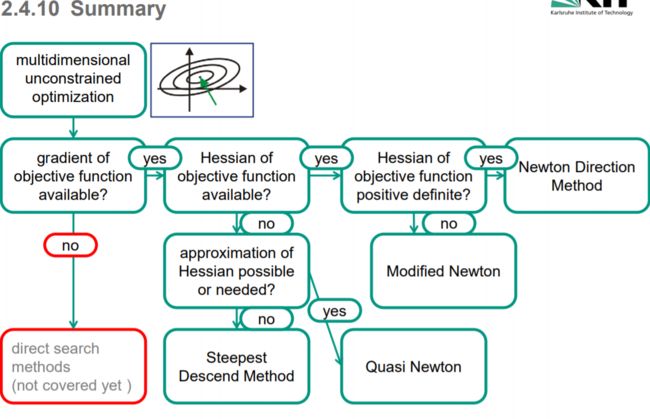
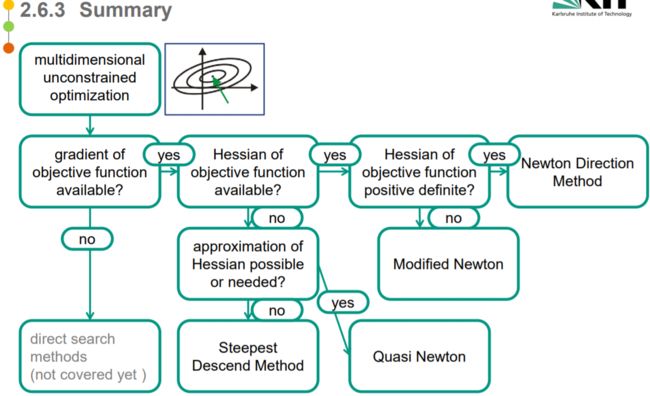
- 非约束优化总结
-
- 线搜索&信赖域
- 直接搜索
- 直接搜索
信赖域算法介绍
最优化的目标是找到极小值点,在这个过程中,我们需要从一个初始点开始,先确定一个搜索方向 p ,在这个方向上做线搜索(line search),找到此方向上的可接受点(例如,按两个准则的判定)之后,通过一定的策略调整搜索方向,然后继续在新的方向上进行一维搜索,依此类推,直到我们认为目标函数已经收敛到了极小值点。
信赖域算法与一维搜索算法的区别、联系
在Jorge Nocedal和Stephen J. Wright的《Numerical Optimization》一书的第2.2节介绍了解优化问题的两种策略-line search和trust region。本质上它们的作用都是在优化迭代过程中从当前点找寻下一点。它们的最大区别是先确定步长还是先确定方向。
-
信赖域方法与线搜索算法不同之处其一在于, 后者先产生搜索方向 p ‾ ( k ) \underline p^{(k)} p(k), 再求一合适的步长 α ( k ) \alpha^{(k)} α(k), 迭代依照的如下形式进行
-
θ ‾ ( k + 1 ) = θ ‾ ( k ) + α ( k ) p ‾ ( k ) \underline\theta^{(k+1)} =\underline\theta^{(k)}+\alpha^{(k)} \underline p^{(k)} θ(k+1)=θ(k)+α(k)p(k)
-
而trust region方法则先把搜索范围缩小到一个小的范围,小到能够用另一个函数(Model function)去近似目标函数(Objective function),然后通过优化这个model function来得到参数更新的方向及步长。
同时选取搜索方向与步长 (或者说, 先划定步长的范围, 再选取搜索方向) . 迭代的方式为 $\underline\theta^{(k+1)} =\underline\theta^{(k)}+ \underline p^{(k)} $ (可以认为此时步长融于 p ‾ ( k ) \underline p^{(k)} p(k) 中)
线搜索方法用得比信赖域方法广泛,是不是说明信赖域方法没有优点呢?
举个简单的例子,求解:
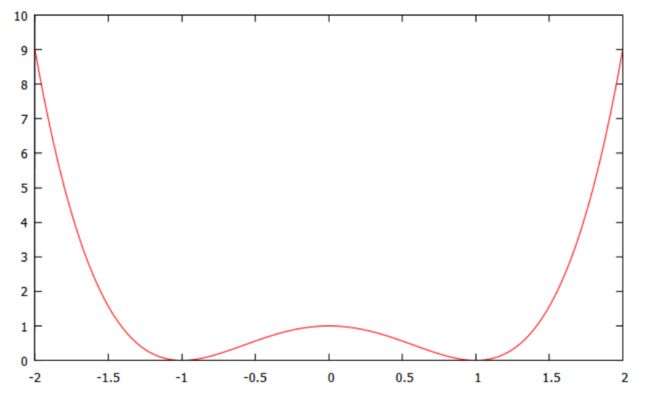
如果直接用线搜索,初始点在 0 处无法进行下一步的搜索,因为梯度为0. 而使用TR:,显然可以往最优方向进行搜索。
https://blog.csdn.net/purgle/article/details/73800186
信赖域算法的基本思想
下面是线搜索算法与信赖域算法的一个图例.
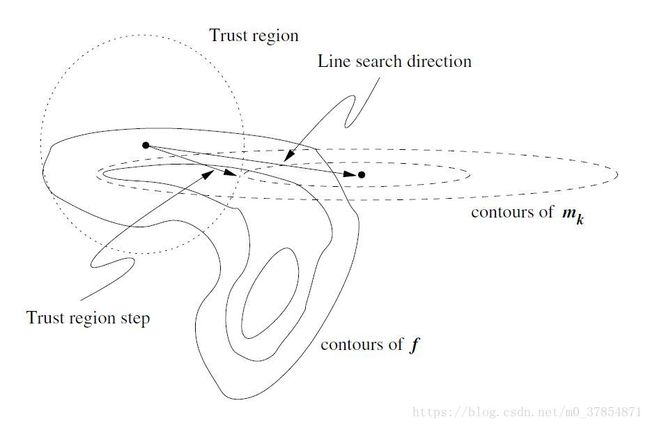
- 图中, 椭圆虚线为建立的模型(model function) m ( k ) m^{(k)} m(k) 的等高线, 而圆形虚线为信赖域的边界.
- 从图中可以看到, 线搜索得到的函数值下降并不客观 (当然这可能与 m ( k ) m^{(k)} m(k) 对目标函数的近似程度有关) ,
- 而信赖域方法得到的下一迭代点被牢牢地锁在信赖域中, 反而带来了较大的下降.
trust region方法则先把搜索范围缩小到一个小的范围,小到能够用另一个函数(Model function)去近似目标函数(Objective function),然后通过优化这个model function来得到参数更新的方向及步长。
由上面的表述我们可以得到信赖域方法的几个要素
- 近似模型函数 m ( k ) ( p ‾ ) m^{(k)}(\underline p) m(k)(p)
- 可信赖域 region of trust T Δ \mathcal T_\Delta TΔ
- 迭代增量 p ‾ \underline p p (包括步长和方向)
-
近似目标函数的 model fuction 为:
J ( θ ‾ ( k ) ) ≈ m ( k ) ( 0 ‾ ) J(\underline\theta^{(k)}) \approx m^{(k)}(\underline 0) J(θ(k))≈m(k)(0) -
代替最小化目标函数,TR 方法最小化 model function
min p ‾ ( J ( θ ‾ ( k ) + p ‾ ) ) ≈ min p ‾ ( m ( k ) ( 0 ‾ + p ‾ ) ) \min_{\underline p}\left(J(\underline\theta^{(k)}+\underline p)\right) \approx \min_{\underline p}\left(m^{(k)}(\underline 0 + \underline p)\right) pmin(J(θ(k)+p))≈pmin(m(k)(0+p)) -
信任域(TR)方法还计算当前迭代 的 region of trust T Δ \mathcal T_\Delta TΔ 。 如果下一个迭代点 θ ‾ ( k + 1 ) = θ ‾ ( k ) + p ‾ \underline\theta ^{(k + 1)} = \underline\theta ^{(k)} + \underline p θ(k+1)=θ(k)+p 还在这个信任域内,则该 model function 将很好地近似于原始目标函数。
-
很可能,这个近似在信任域之外不成立
-
近似模型的quality计算指标:(分子表示函数实际减小的值;分母表示近似模型减少的值)
ρ ( k ) = J ( θ ‾ ( k ) ) − J ( θ ‾ ( k ) + p ‾ ) m ( k ) ( 0 ‾ ) − m ( k ) ( p ‾ ) \rho^{(k)} = \frac{J(\underline\theta ^{(k)})-J(\underline\theta ^{(k)}+\underline p)}{m^{(k)}(\underline 0)-m^{(k)}(\underline p)} ρ(k)=m(k)(0)−m(k)(p)J(θ(k))−J(θ(k)+p)- ρ ( k ) < 1 \rho ^{(k)} < 1 ρ(k)<1 表示模型函数下降速度快于原始函数
- ρ ( k ) = 1 \rho ^{(k)} = 1 ρ(k)=1 表示完美契合
- ρ ( k ) > 1 \rho ^{(k)} > 1 ρ(k)>1 表示原始函数的下降速度比模型函数的下降速度快
因此,近似模型函数 m ( k ) ( p ‾ ) m^{(k)}(\underline p) m(k)(p) 进行了优化 w.r.t 迭代增量 p ‾ \underline p p ,且该解限制其在信赖域范围内
min p ‾ { m ( k ) ( p ‾ ) } w . r . t p ‾ ∈ T Δ \min_{\underline p}\left\{m^{(k)}(\underline p)\right\}\quad w.r.t \quad\underline p\in\mathcal T_{\Delta} pmin{m(k)(p)}w.r.tp∈TΔ
-
信赖域算法同时优化步长和搜索方向,而线搜索算法有一个顺序的方法
Trust region methods optimize the step length and the search direction simultaneously ;Line search algorithms have a sequential approach
数学模型
基本形式
-
信赖域算法:通常选取二次函数(quadratic model function)逼近真实模型的
J ( θ ‾ ( k ) + p ‾ ) = J ( θ ‾ ( k ) ) + [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] T p ‾ + 1 2 p ‾ T B ‾ ( k ) p ‾ ⏟ m ( k ) ( p ‾ ) J(\underline \theta^{(k)} + \underline p) = \underbrace{J(\underline\theta^{(k)}) +\left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}} \right]^T\underline p + \frac12\underline p^T\underline B^{(k)}\underline p }_{m^{(k)}(\underline p)} J(θ(k)+p)=m(k)(p) J(θ(k))+⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤Tp+21pTB(k)p和拟牛顿法法的近似“损失函数”一样
如果 B ‾ ( k ) \underline B^{(k)} B(k) 选择为Hessian,则为TR的牛顿方法。一般情况下会(比如 Hessian非正定的时候)用对称非奇异矩阵 B ‾ ( k ) \underline B^{(k)} B(k) 去近似Hessian矩阵;
-
在每次迭代中半径为 Δ ( k ) \Delta^{(k)} Δ(k) 的球用来定义信赖域的范围 T Δ \mathcal T_\Delta TΔ
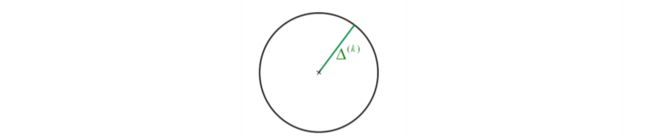
-
因此,我们必须解决下面的优化子问题:关于 $p $ 的带约束的最优化问题,
min p ‾ { m ( k ) ( p ‾ ) } = min p ‾ { J ( θ ‾ ( k ) ) + [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] T p ‾ + 1 2 p ‾ T B ‾ ( k ) p ‾ } \min_{\underline p}\left\{m^{(k)}(\underline p)\right\} =\min_{\underline p} \left\{ J(\underline\theta^{(k)}) +\left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}} \right]^T\underline p + \frac12\underline p^T\underline B^{(k)}\underline p \right\} pmin{m(k)(p)}=pmin⎩⎪⎨⎪⎧J(θ(k))+⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤Tp+21pTB(k)p⎭⎪⎬⎪⎫
要求:参数 p p p 被限制在一个球形区域内
∣ ∣ p ‾ ∣ ∣ 2 ≤ Δ ( k ) \left|\left| \underline p\right| \right|_2 \le \Delta^{(k)} ∣∣∣∣p∣∣∣∣2≤Δ(k)
Δ ( k ) \Delta^{(k)} Δ(k) 的选择
近似模型的quality计算指标:
ρ ( k ) = J ( θ ‾ ( k ) ) − J ( θ ‾ ( k ) + p ‾ ) m ( k ) ( 0 ‾ ) − m ( k ) ( p ‾ ) \rho^{(k)} = \frac{J(\underline\theta ^{(k)})-J(\underline\theta ^{(k)}+\underline p)}{m^{(k)}(\underline 0)-m^{(k)}(\underline p)} ρ(k)=m(k)(0)−m(k)(p)J(θ(k))−J(θ(k)+p)
其中分子表示函数实际减小的值;分母表示近似模型减少的值。
- 如果 ρ ( k ) < 0 \rho ^{(k)} < 0 ρ(k)<0,一般情况下分母不可能小于0,因为目标函数求解的是最小值;此时说明分子小于0,即下一个目标点比上一步大,此时需要舍弃。
- 如果 0 < ρ ( k ) ≈ 0 0<\rho ^{(k)} \approx 0 0<ρ(k)≈0 大于0,但是接近0,说明模型(分母)变化范围比较大,但是实际(分子)改变比较小,此时应该减少信赖域范围Δk
- 0 < ρ ( k ) < 1 0< \rho ^{(k)} < 1 0<ρ(k)<1 大于0但是明显小于1,表示模型函数下降速度快于原始函数,此时可以不用调整
- 0 < ρ ( k ) ≈ 1 0< \rho ^{(k)} \approx 1 0<ρ(k)≈1 大于0并且接近1,表明近似效果好,可以适当增加信赖域半径Δk
- ρ ( k ) > 1 \rho ^{(k)} > 1 ρ(k)>1 表示原始函数的下降速度比模型函数的下降速度快
信赖域的大小对于每步的效果直观重要. 若信赖域过小, 则算法可能就会错过充分下降的机会; 若过大, 信赖域中模型m**k的极小点可能就与目标函数f的极小点相距甚远, 从而又得增大信赖域.
而信赖域算法是根据一定的原则,直接确定位移 sk ,同时,与一维搜索不同的是,它并没有先确定搜索方向 dk 。如果根据“某种原则”确定的位移能使目标函数值充分下降,则扩大信赖域;若不能使目标函数值充分下降,则缩小信赖域。如此迭代下去,直到收敛
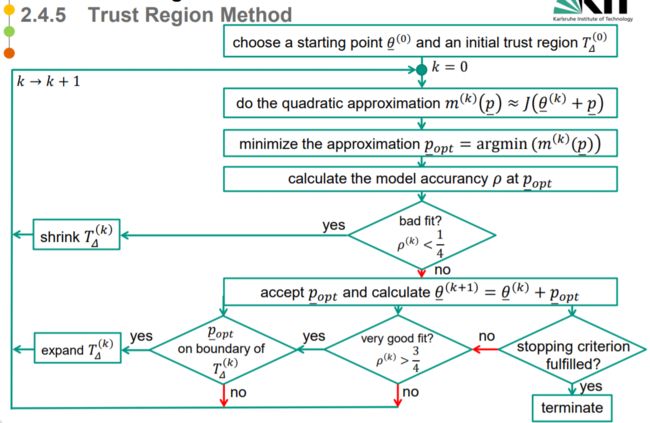
信赖域算法流程
由此我们得到信赖域算法的步骤
-
给出初始点 θ ‾ ( 0 ) \underline\theta^{(0)} θ(0) 和初始信赖域半径 Δ ( 0 ) \Delta^{(0)} Δ(0),开始迭代 k
-
计算模型在第k步的近似 m ( k ) m^{{(k)}} m(k):求解最优化子问题,得到试探步长 p ‾ \underline p p。
-
求解 model accurancy ρ \rho ρ at p ‾ \underline p p
-
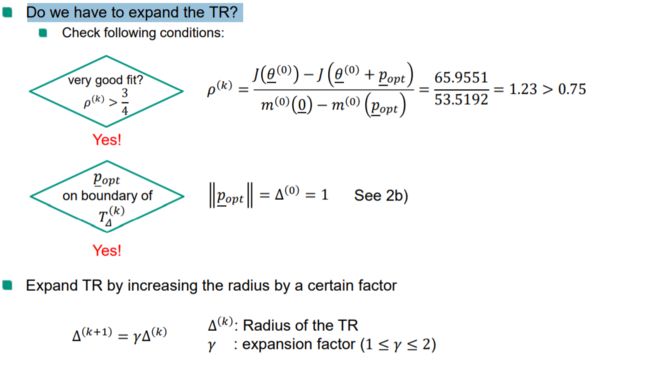
若 ρ ( k ) ≤ 1 4 \rho^{(k)}≤\frac14 ρ(k)≤41,缩小(shrink)信赖域半径,令
Δ ( k + 1 ) = 1 4 Δ ( k ) \Delta^{(k+1)} = \frac14 \Delta^{(k)} Δ(k+1)=41Δ(k)
k = k + 1 返回第一步 -
else:
- 若 ρ ( k ) > 0.75 \rho^{(k)}>0.75 ρ(k)>0.75,扩大信赖域半径,使得 Δk+1=2Δ\Delta_{k+1}=2\DeltaΔk+1=2Δ。
- 若0.25
- 若rk<0r_k<0r**k<0,缩小信赖域重新计算当前试探步长。

[关于子问题的最优解]
https://blog.csdn.net/fangqingan_java/article/details/46956643
信赖域问题的子问题表示为:
min p ‾ { m ( k ) ( p ‾ ) } = min p ‾ { J ( θ ‾ ( k ) ) + [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] T p ‾ + 1 2 p ‾ T B ‾ ( k ) p ‾ } \min_{\underline p}\left\{m^{(k)}(\underline p)\right\} =\min_{\underline p} \left\{ J(\underline\theta^{(k)}) +\left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}} \right]^T\underline p + \frac12\underline p^T\underline B^{(k)}\underline p \right\} pmin{m(k)(p)}=pmin⎩⎪⎨⎪⎧J(θ(k))+⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤Tp+21pTB(k)p⎭⎪⎬⎪⎫
该问题为标准的带不等式约束的二次优化问题,可以根据KKT条件(后面会深入介绍)得到该问题的最优解
定理 1
向量 p ‾ ∗ \underline p^* p∗ 为信赖域子问题的最优解,仅当 p ‾ ∗ \underline p^* p∗ 是可行解,且存在标量 λ ≥ 0 \lambda \ge 0 λ≥0 使得下面的三个条件成立:
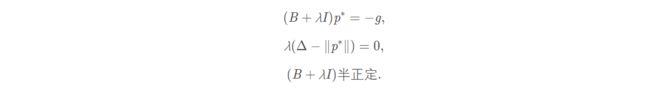
其中第二个条件又称为互补条件. 此定理揭示了信赖域方法的优势: 就算B**k是不定的, 我们仍然有子问题达到全局极小的充要条件. 相比之下, 其他方法往往至多有充分条件.
从下图中可以看出最优解 p ‾ ∗ \underline p^* p∗ 和参数 λ \lambda λ 的关系
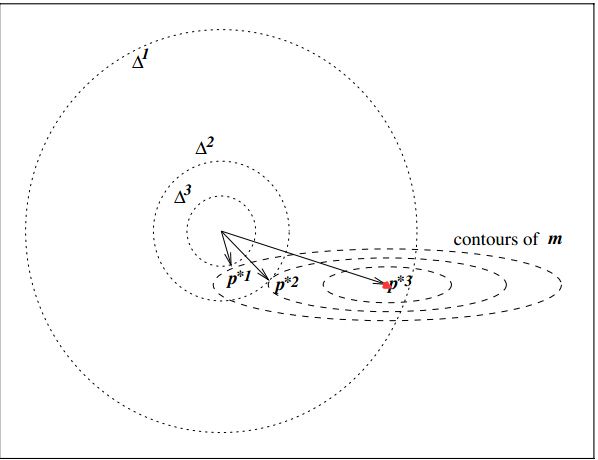
-
当半径参数 Δ = Δ 1 \Delta = \Delta _1 Δ=Δ1 时,最优解为 p 3 p^3 p3 此时相当于没有约束,此时 λ = 0 \lambda= 0 λ=0
-
当半径参数 Δ = Δ 2 \Delta = \Delta _2 Δ=Δ2 时,最优解被球形约束限制,此时满足 Δ = ∣ ∣ p ∗ ∣ ∣ Δ=||p^∗|| Δ=∣∣p∗∣∣,根据上面条件(a)有
λ p ∗ = − B p ∗ − g \lambda p^* = -Bp^*-g λp∗=−Bp∗−g
如果能够找到这样的p满足这些条件就能找到最优解。
⭕折线算法 Dog-Leg Method
目的:找到最小化问题的近似解
折线算法可用于 B ‾ ( k ) \underline B^{(k)} B(k)为正定的情形
定义完全步(Full Step)
我们在线搜索牛顿法时有:

对于TR子优化问题
min p ‾ { m ( k ) ( p ‾ ) } = min p ‾ { J ( θ ‾ ( k ) ) + [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] T p ‾ + 1 2 p ‾ T B ‾ ( k ) p ‾ } \min_{\underline p}\left\{m^{(k)}(\underline p)\right\} =\min_{\underline p} \left\{ J(\underline\theta^{(k)}) +\left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}} \right]^T\underline p + \frac12\underline p^T\underline B^{(k)}\underline p \right\} pmin{m(k)(p)}=pmin⎩⎪⎨⎪⎧J(θ(k))+⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤Tp+21pTB(k)p⎭⎪⎬⎪⎫
求TR中的位移 p ‾ \underline p p
折线算法
折线算法可用于 B ‾ ( k ) \underline B^{(k)} B(k) 为正定的情形。寻找信赖域半径 Δ ( k ) \Delta^{(k)} Δ(k) 和最优解 p ‾ ∗ ( k ) ( Δ ) \underline p^{*(k)}(\Delta) p∗(k)(Δ) 之间的关系。
以下省去上标k, 并以 p ‾ ( Δ ) \underline p (\Delta) p(Δ) 表示解以强调其对 $\Delta $ 的依赖性.
-
使用高斯牛顿法得到迭代步长:当 p ‾ ( k ) ≤ Δ ( k ) \underline p^{(k)}\le \Delta^{(k)} p(k)≤Δ(k)时 (信赖域非常大), 显然应当有 p ‾ ∗ ( k ) ( Δ ) \underline p^{*(k)}(\Delta) p∗(k)(Δ)

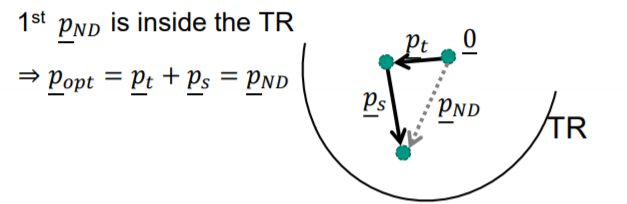
若计算出 p ‾ N D < Δ \underline p_{ND}<\Delta pND<Δ 已经不用继续计算下去 – case 1
-
【 p ‾ t \underline p_{t} pt】当 p ‾ ( k ) > > Δ ( k ) \underline p^{(k)} >> \Delta^{(k)} p(k)>>Δ(k) 时(信赖域非常小), 可认为 m ( k ) ( p ‾ ) m^{(k)}(\underline p) m(k)(p) 问题中的中的二次项(梯度)对子问题的求解影响较小, 从而忽略二次项,即:
m ( k ) ( p ‾ ) = J ( θ ‾ ( k ) ) + [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] T ⏟ g T p ‾ t m^{(k)}(\underline p) =J(\underline\theta^{(k)}) +\underbrace{\left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}}\right]^T}_{g^T}\underline p_{t} m(k)(p)=J(θ(k))+gT ⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤Tpt
calculate the exact minimum of quadratic function along the stepest descent function is equal to 求二次函数的精确最小值沿最小步下降函数等于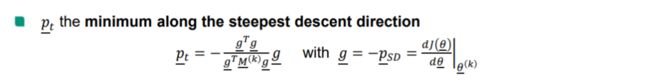
-
ps【 p ‾ s \underline p_s ps】
p ‾ s = p ‾ N D − p ‾ t = − [ B ‾ ( k ) ] − 1 [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] + [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] = [ I − [ B ‾ ( k ) ] − 1 ] [ d J ( θ ‾ ) d θ ‾ ∣ θ ‾ ( k ) ] \underline p_s =\underline p_{ND} -\underline p_t =- [\underline B^{(k)}]^{-1} \left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}} \right] + \left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}} \right]=\left[I-[\underline B^{(k)}]^{-1}\right]\left[\frac{dJ(\underline\theta)}{d\underline\theta}\Bigg|_{\underline\theta^{(k)}} \right] ps=pND−pt=−[B(k)]−1⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤+⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤=[I−[B(k)]−1]⎣⎡dθdJ(θ)∣∣∣∣∣θ(k)⎦⎤
我们用 p ‾ ( τ ) ; τ ∈ [ 0 , 2 ] \underline p(\tau);\tau\in[0,2] p(τ);τ∈[0,2] 表示折线轨迹, 其严格的数学表达为
KaTeX parse error: No such environment: equation at position 30: …\tau) = \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ \left\{ \begin…
根据折线算法得到的就是折线轨迹与信赖域边界的交点
对半径为 Δ \Delta Δ 的信赖域使用DogLeg方法计算出来的步长为
KaTeX parse error: No such environment: equation at position 30: …\tau) = \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ \left\{ \begin…
可以看到,DogLeg方法实际上使用了如下策略:
-
如果高斯牛顿法的步长小于信赖域半径,则等同于高斯牛顿法
-
如果高斯牛顿法和梯度下降法步长都大于信赖域半径,则将梯度下降法的步长缩放到信赖域半径。

求$\tau $ 归一法
-
如果不满足以上条件,则以连接二条轨迹,与信赖域边界相交于某一点d,从原点指向d的向量即为本次迭代的步长。


Direct Search Methods 直接搜索法
- Box Search
- Section 坐标搜索算法
- Nelder Mead 单纯形
有时候目标函数的梯度不可用
介绍
- 首先,直接搜索方法在实践中效果很好
- 不需要梯度信息
- 一些方法只使用目标函数 J J J在特定搜索点的排名信息, 比当 J J J 不存在数值分析性
缺点:
- 有时直接搜索方法不收敛,不幸的是,收敛性很难证明。
- 在许多情况下,它们在收敛速度方面表现不佳
类型介绍:
https://blog.csdn.net/m0_37854871/article/details/84969300
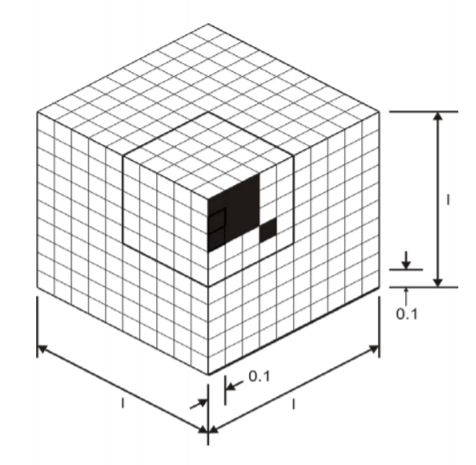
1. Box Search
- 将搜索空间分割成等距的box
- 计算box边缘的所有目标函数值并取最小值
- 缺点:存在维度灾难
- 因此,有一些方法可以使用生物原理(遗传算法)来生成一个boxes子集。
2. Section 坐标搜索算法 (属于线搜索算法)
坐标搜索和模式搜索方法并不从函数值中显式地构建目标函数的模型, 而是从当前迭代点出发沿着特定的方向寻找具有更小函数值的点. 若找到了这样的点, 它们就步进并重复之前的过程, 当然此前可能会对之前的搜索方向做一些改动. 当没有满意的点存在时, 算法就可能会调整沿着当前搜索方向前进的步长, 或直接产生新的搜索方向.
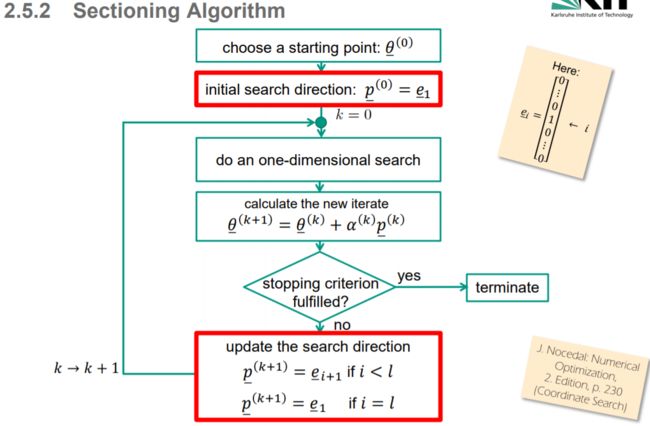
The process of finding a solution might be inefficient or will be even impossible if there are valleys or ridges
坐标搜索方法(也称为坐标下降法或交替变量法) 循环遍历 n 个坐标方向 e 1 , e 2 , … , e n e_1,e_2,\ldots,e_n e1,e2,…,en, 在每个方向上均以线搜索获取新的迭代点.
一定是先从 θ ‾ 1 \underline\theta_1 θ1 方向开始的
具体说来, 第一次迭代中, 我们仅改变xxx的第一个分量x1x_1x1并寻找极小(或至少减小)目标函数的这一分量的新值. 下一步迭代中, 则对第二个分量 x2x_2x2进行同样的操作. 在nnn步迭代后, 我们又回到第一个变量重复遍历.
尽管简单直观, 但此法在实际操作中却可能十分低效, 就比如下图中表示的, 我们将坐标搜索方法应用于带两个变量的二次函数上.图中显示, 经几步迭代后, x1,x2x_1,x_2x1,x2向解的行进都明显变慢.
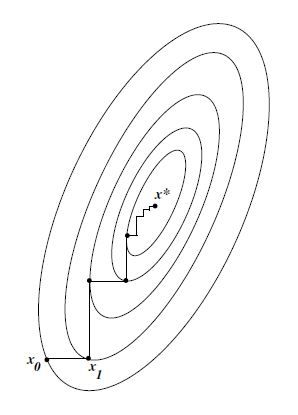
就算坐标搜索收敛于一解, 一般来说它也要比最速下降法慢得多, 并且这一差距随着变量数的增加而越变越大. 不过由于坐标搜索不需要计算梯度∇fk\nabla f_k∇f**k, 且它在变量耦合程度不高时的效果还不错, 因此它仍是优化目标函数的有效方法.
a sectioning algorithm would never reach the real minimum at [ ] * 0 0 T θ = exactly. (Or it would need an infinite number of iterations).
https://blog.csdn.net/m0_37854871/article/details/84969300#3__114
3. ⭕Nelder Mead
-
目的:使用更复杂的方法确定搜索方向
-
记住:没有可用的梯度信息
-
想法:评估几个点,对它们进行排名,试图通过把最坏的点向最好的点移动来改善结果
Idea: Evaluate several points, rank them, try to improve the result by shifting the worst point in the direction of the best point(s)
定义:Simplex 单纯形
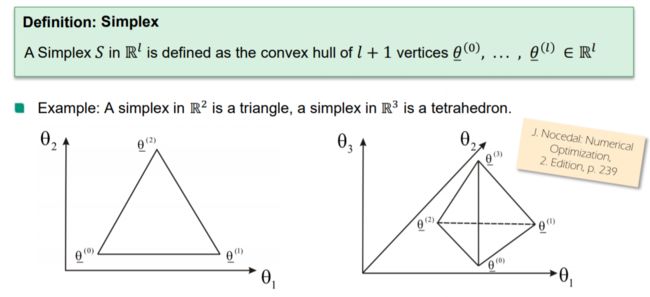
3 个越是 4个顶点
Nelder-Mead单纯形反射方法自其1965年被发明以来一直是广受欢迎的DFO算法。其名称来源于在算法的任意阶段, 我们都保持对单纯形 S S S 的空间 R l \R^l Rl 中的 l + 1 l+1 l+1 个顶点(vertices)追索,它们形成的凸腔构成单纯形. (这一方法与线性规划中的单纯形法没有任何关联)。 给定有顶点 的单纯 θ ‾ ( 0 ) , . . . , θ ‾ ( l ) \underline\theta^{(0)},...,\underline\theta^{(l)} θ(0),...,θ(l) 的单纯形 S S S , 我们可定义关联矩阵
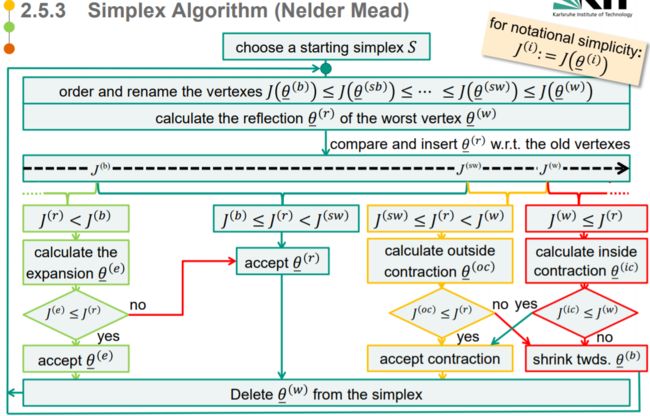
算法
Nelder-Mead算法中的单次迭代中, 我们移除具有最差函数值的顶点并代之以具更好值的点. 而新点则是通过沿着连接最差顶点与剩余顶点中心的线反射、扩张或收缩单纯形得到。若以这种方式我们无法找到更好的点, 我们就仅保持具最好函数值的点不动,,而令其他的顶点向该值移动以收缩单纯形.
下面我们来详细描述算法的一次迭代过程.
-
该方法生成初始工作单纯形。
-
先定义一些符号: 当前单纯形的 l + 1 l+1 l+1 个顶点 θ ‾ ( 0 ) , . . . , θ ‾ ( l ) ∈ R l \underline\theta_{(0)},...,\underline\theta_{(l)}\in\R^l θ(0),...,θ(l)∈Rl,计算每个点的目标函数值,并对他们进行排序,满足目标函数值从小到大:
J ( θ ‾ ( 1 ) ) ≤ J ( θ ‾ ( 2 ) ) ≤ ⋯ ≤ J ( θ ‾ ( l + 1 ) ) J(\underline\theta_{(1)})\le J(\underline\theta_{(2)})\le\cdots \le J(\underline\theta_{(l+1)}) J(θ(1))≤J(θ(2))≤⋯≤J(θ(l+1))
另外对这些点进行命名:- “best vertex” θ ‾ ( 1 ) = θ ‾ ( b ) \underline \theta{(1)} = \underline\theta^{(b)} θ(1)=θ(b)
- “second best vertex” θ ‾ ( 2 ) = θ ‾ ( s b ) \underline\theta_{(2)} = \underline\theta^{(sb)} θ(2)=θ(sb)
- “second worst vertex” θ ‾ ( l ) = θ ‾ ( s w ) \underline\theta_{(l)} = \underline\theta^{(sw)} θ(l)=θ(sw)
- “worst vertex” θ ‾ ( l + 1 ) = θ ‾ ( w ) \underline\theta_{(l+1)} = \underline\theta^{(w)} θ(l+1)=θ(w)
Remark
in R 2 \R^2 R2 we denote θ ‾ ( s b ) = θ ‾ ( s w ) = θ ‾ ( m ) \underline\theta^{(sb)} = \underline\theta^{(sw)} = \underline\theta^{(m)} θ(sb)=θ(sw)=θ(m) as “middle vertex”
-
通过执行一系列由基本转换组成的转换(transformation),尝试沿着顶点的方向移动(shift)最坏的顶点
- Reflection 反射
- Expansion 扩张
- (inner/outer) Contraction
- Shrinking
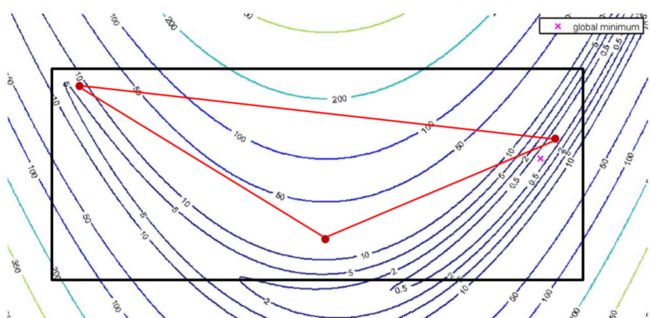
1. reflection
每个转换的performance取决于目标函数的局部属性/形状。例如在如下区域进行reflection反射
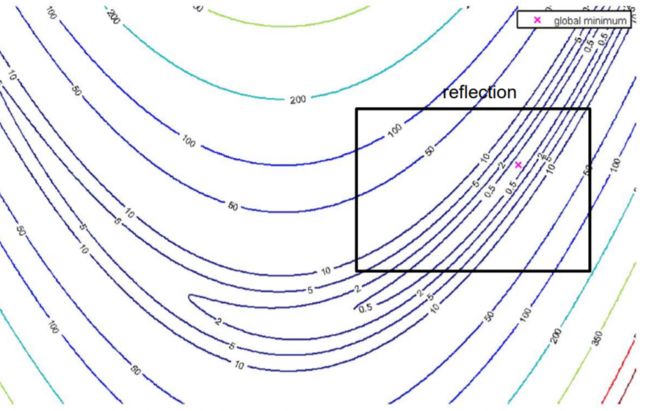
-
将 the worst vertex θ ‾ ( w ) \underline\theta ^{(w)} θ(w) 绕 centroid c ‾ \underline c c reflect 转换:
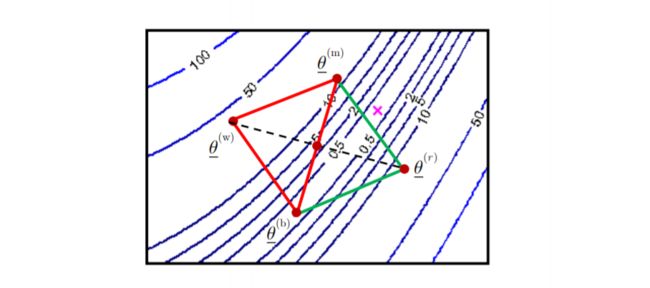
-
计算新点的坐标:
θ ‾ ( r ) = c ‾ + α ( c ‾ − θ ‾ ( w ) ) α ∈ R \underline\theta^{(r)} = \underline c + \alpha\left(\underline c - \underline\theta^{(w)}\right)\quad \alpha\in \R θ(r)=c+α(c−θ(w))α∈R
记个点的目标函数值为:
J ( θ ‾ ( r ) ) = J ( r ) J(\underline\theta^{(r)}) = J^{(r)} J(θ(r))=J(r)中心点 c ‾ \underline c c 怎么计算的?
c c c is the centroid of all vertices other than the worst, the centroid of n arbitrary points is given by
c ‾ = 1 n ∑ i = 1 n θ ‾ ( i ) \underline c = \frac1n\sum_{i=1}^ n\underline\theta_{(i)} c=n1i=1∑nθ(i)
-
反射变换的结果:如果新的点的函数值小于倒数第二差的点,则将最差的点舍弃,将此新点加入

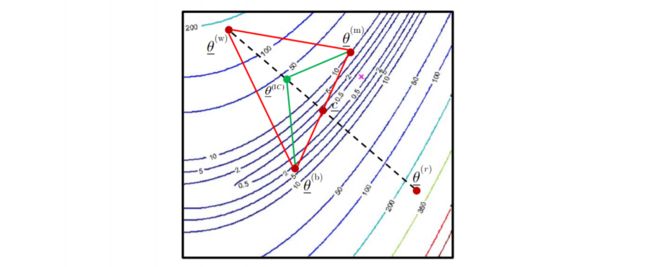
2. Explansion
例如在如下区域进行 explansion
-
假设经过 reflection 得到的新点 θ ‾ ( r ) \underline\theta^{(r)} θ(r) 的目标函数值比最优点还低: J ( r ) < J ( b ) J^{(r)}
-
计算扩展的新点 θ ‾ ( e ) \underline\theta^{(e)} θ(e)的新坐标
θ ‾ ( e ) = c ‾ + γ ( c ‾ − θ ‾ ( w ) ) γ ∈ R \underline\theta^{(e)} = \underline c + \gamma(\underline c - \underline\theta^{(w)}) \quad \gamma \in\R θ(e)=c+γ(c−θ(w))γ∈R -
扩张变换的结果:如果新的点的函数值小于被扩张的点,将此新点加入替换被扩张的点

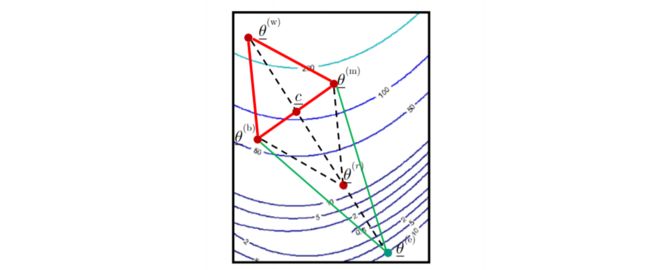
3. outer contraction
例如在如下区域进行 outer contraction
尝试对 reflect 后的点进行 outer contraction
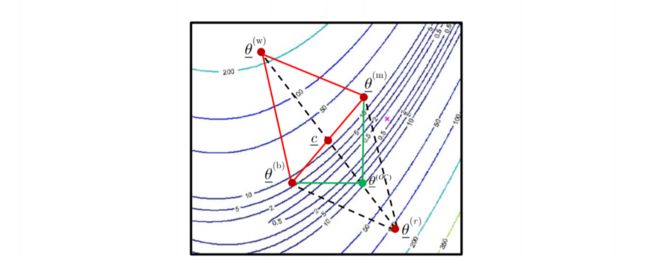
-
由 θ ‾ ( r ) \underline\theta^{(r)} θ(r) outer contraction 到点 θ ‾ ( o c ) \underline\theta^{(oc)} θ(oc)
θ ‾ ( o c ) = c ‾ + β ( θ ‾ ( r ) − c ‾ ) β ∈ R \underline\theta^{(oc)} = \underline c + \beta(\underline\theta^{(r)} - \underline c) \quad \beta \in \R θ(oc)=c+β(θ(r)−c)β∈R -
outer contraction 变换的结果:如果新的点的函数值小于 θ ‾ ( r ) \underline\theta^{(r)} θ(r) 的目标函数值,将此新点加入替换原来的点

4. inner contraction
例如在如下区域进行 inner contraction
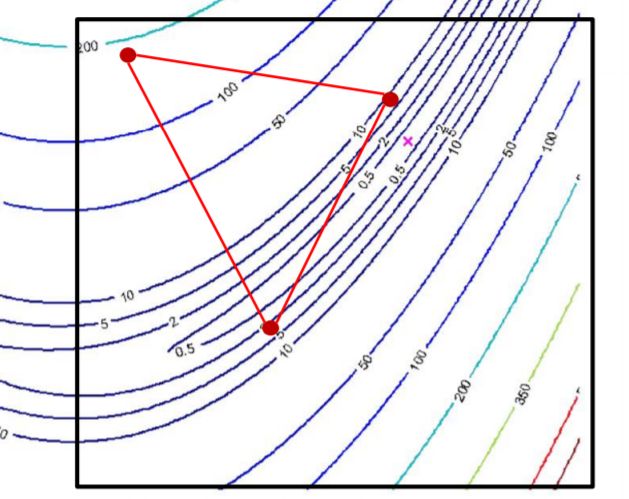
尝试对 the original simplex 进行 inner contraction,即不将 最差的点先进行 反射操作,再 contraction,而直接对最差的点进行 contraction
-
由 θ ‾ ( w ) \underline\theta^{(w)} θ(w) outer contraction 到点 θ ‾ ( i c ) \underline\theta^{(ic)} θ(ic)
θ ‾ ( i c ) = c ‾ + β ( θ ‾ ( w ) − c ‾ ) β ∈ R \underline\theta^{(ic)} = \underline c + \beta(\underline\theta^{(w)} - \underline c) \quad \beta \in \R θ(ic)=c+β(θ(w)−c)β∈R -
inner contraction 变换的结果:如果新的点的函数值小于 θ ‾ ( w ) \underline\theta^{(w)} θ(w) 的目标函数值,将此新点加入替换原来的点

5. shinking
例如在如下区域进行 shinking
保留最忧点不动,其它点按比例缩放
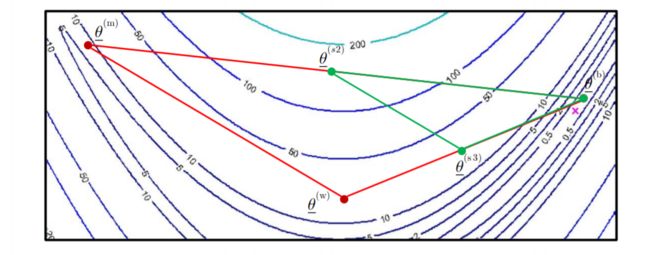
shrinking的结果为:

总结 Nelder Mead 算法流程:
Final remarks:
- 尽管在1998年已经推导出了一组目标函数和初始simplexe且具有可证明的收敛性,但对该算法的严格分析仍是困难的。然而,即使在简单的情况下,算法也可能失败。
- 单纯形算法(Nelder Mead)与数值数学和以前的ODS术语中涉及的线性规划的数值单纯形算法无关。
Nonlinear Least Squares(NLS) 非线性最小二乘法 – LMA
一

二:问题定义
【非线性最小二乘法】
-
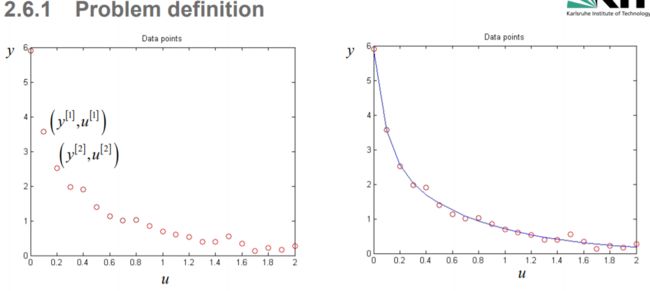
目的:找到适合给定输入()和最佳输出数据()的最佳曲线(二次)参数(parameterization)
-
例子:找到下面曲线的参数 θ 1 , θ 2 , θ 3 , θ 4 \theta_1,\theta_2,\theta_3,\theta_4 θ1,θ2,θ3,θ4,使它能够最优拟合数据
f ( u ) = θ 1 e ( θ 2 u ) + θ 3 e ( − θ 4 u ) f(u) = \theta_1e^{(\theta_2 u)}+\theta_3e^{(-\theta_4 u)} f(u)=θ1e(θ2u)+θ3e(−θ4u)
-
假设我们有一组给定的(测量的)数据 y ‾ [ 1 ] , y ‾ [ 2 ] , . . . , y ‾ [ N ] \underline y^{[1]},\underline y^{[2]},...,\underline y^{[N]} y[1],y[2],...,y[N] , 以及对应的输入点 u ‾ [ 1 ] , u ‾ [ 2 ] , . . . , u [ N ] \underline u^{[1]},\underline u^{[2]},..., u^{[N]} u[1],u[2],...,u[N]
-
定义一个模型函数(moderl function),以最优拟合这些测量值
y ‾ = m ‾ ( u ‾ , θ ‾ ) \underline y = \underline m(\underline u,\underline \theta) y=m(u,θ) -
定义一个目标函数(objectivefunction):使用测量曲线和参数化曲线的平方和
Using the sum of squares between measurement and parameterized curve
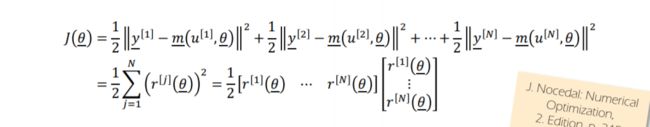
-
使用第2章的搜索技术来最小化目标函数 求解

J ( θ ‾ ) = 1 2 ∣ ∣ 3 − θ 1 e θ 2 ∣ ∣ 2 + 1 2 ∣ ∣ 11 − 2 θ 2 e θ 3 ∣ ∣ 2 + 1 2 ∣ ∣ 26 − 3 θ 3 e θ 4 ∣ ∣ 2 J(\underline\theta)=\frac12||3-\theta_1e^{\theta_2}||^2+\frac12||11-2\theta_2e^{\theta_3}||^2 + \frac12||26-3\theta_3e^{\theta_4}||^2 J(θ)=21∣∣3−θ1eθ2∣∣2+21∣∣11−2θ2eθ3∣∣2+21∣∣26−3θ3eθ4∣∣2
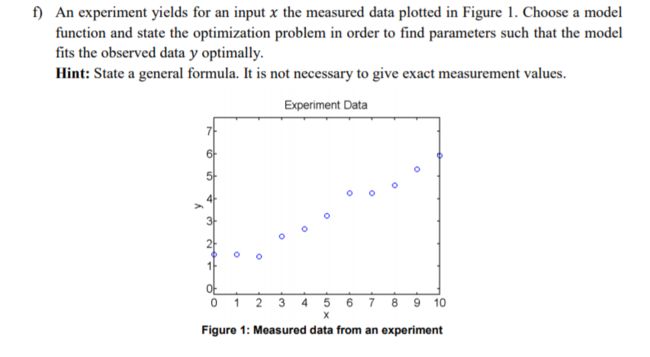
线性 model function为:
y = a x + b y = ax+b y=ax+b
则优化问题为:
min a , b J = ∑ i = 0 10 ( y i − ( a x i + b ) ) 2 \min_{a,b} J=\sum_{i=0}^{10} (y_i-(ax_i+b))^2 a,bminJ=i=0∑10(yi−(axi+b))2
三:问题的解
NLS问题的有趣特性是目标函数的 梯度 和 Hessian 矩阵的近似容易求得:
-
Gradient of J ( θ ) J(\theta) J(θ)
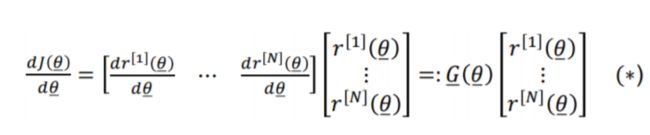
-
The approximation of the Hessian of J ( θ ‾ ) J(\underline\theta) J(θ)
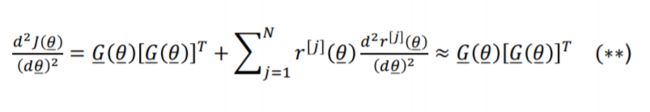
由高斯牛顿法
-
如果我们现在应用牛顿法得到高斯牛顿搜索方向 p ‾ G N \underline p_{GN} pGN (参见Ch.2幻灯片47)
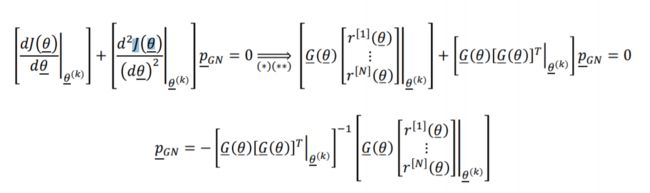
-
在改进的牛顿法中插入(∗)和(∗∗)会得到Levenberg Marquardt搜索方向
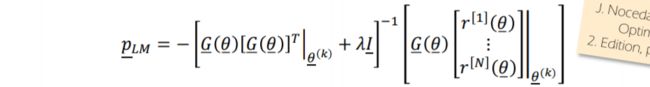
非约束优化总结
线搜索&信赖域
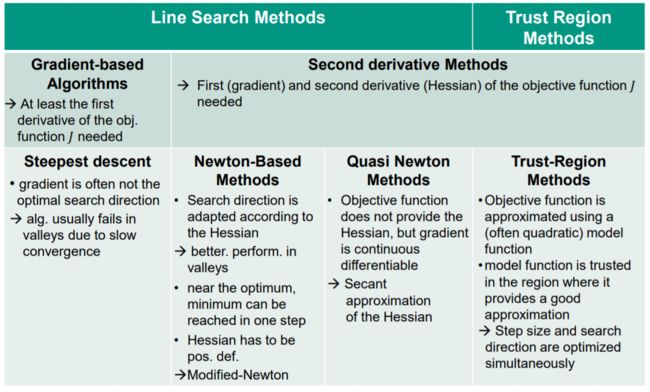
基于梯度的方法
需要目标函数的一次导数信息
Steepest descent 最速梯度下降法
- 梯度往往不是最优搜索方向
- [代数] 由于收敛速度慢,通常在谷中失败
基于Hessian的方法
需要目标函数的梯度信息和二次 Hessian 信息
牛顿法
- 搜索方向根据Hessian 调整
- better. perform. in valleys
- 在最优值附近,可以一步达到最小值
- Hessian has to be pos. def.
- 如果非正定:Modified-Newton
拟牛顿法
- 目标函数不提供Hessian,但梯度是连续可微的
- Secant approximation of the Hessian
信赖域法
- 目标函数用一个(通常是二次的)模型函数逼近
- 模型函数在信赖域提供了一个很好的近似
- Step size and search direction are optimized simultaneously
直接搜索

无梯度信息
Box Search:维度灾难
Sectioning:
- 沿着坐标轴方向使用线搜索技术确定最小值
- 如果函数包含谷底(例如香蕉函数),则此算法会失效
- 不是所有问题可以由独立优化参数解决
Simplex Algorithm
- 单纯形算法自动适应问题
- 对含有 valleys的问题表现较好
于收敛速度慢,通常在谷中失败
基于Hessian的方法
需要目标函数的梯度信息和二次 Hessian 信息
牛顿法
- 搜索方向根据Hessian 调整
- better. perform. in valleys
- 在最优值附近,可以一步达到最小值
- Hessian has to be pos. def.
- 如果非正定:Modified-Newton
拟牛顿法
- 目标函数不提供Hessian,但梯度是连续可微的
- Secant approximation of the Hessian
信赖域法
- 目标函数用一个(通常是二次的)模型函数逼近
- 模型函数在信赖域提供了一个很好的近似
- Step size and search direction are optimized simultaneously
直接搜索
[外链图片转存中…(img-3UpmtI1z-1603197799950)]
无梯度信息
Box Search:维度灾难
Sectioning:
- 沿着坐标轴方向使用线搜索技术确定最小值
- 如果函数包含谷底(例如香蕉函数),则此算法会失效
- 不是所有问题可以由独立优化参数解决
Simplex Algorithm
- 单纯形算法自动适应问题
- 对含有 valleys的问题表现较好