强化学习入门——以Q-Learning为实例
文章目录
- 1. 简介
-
- 1.1 机器学习分类
- 1.2 强化学习特点
- 1.3 组成部分
- 2. 学习过程
-
- 2.1 马尔科夫决策过程
- 2.2 强化学习算法归类
-
- 2.2.1 分类方法一
- 2.2.2 分类方法二
- 2.3 EE(Explore&Exploit)探索利用
- 2.5 强化学习实际开展中的难点
- 3 强化学习的应用
- 4 Q-Learning
-
- 4.1 Bellman方程
- 4.2 如何更新Q-Value
- 4.3 实例Flappy Bird
-
- 1)状态选择
- 2)动作选择
- 3)奖赏的选择
- 4)Q函数
- 5)伪代码
- Reference
1. 简介
1.1 机器学习分类
这里其他机器学习方法主要是监督学习和无监督学习,也是我们在理解强化学习的过程中最容易发生混淆的地方。
-
监督学习:已知训练数据的标签,指代正确结果。
任务:在训练集上按照对应的标签推断出反馈机制,从而在未知标签的样本上计算出尽可能正确的结果
应用:分类和回归问题 -
无监督学习:未知训练数据的标签
任务:从无标签的数据集中发现隐藏的结构
应用:聚类等,将相似度高的数据聚类在一起 -
强化学习:不需要数据标签,但需要每一步的反馈
基于环境的反馈而行动,通过不断与环境交互试错,使得整体行动收益最大化,每一步的反馈是奖励/惩罚,可以量化,基于反馈调整对象行为。
强化学习主要是指导训练对象每一步如何决策,采用什么样的行动可以完成特定的目的或者使收益最大化。
❗与无监督不同,不是为了寻找隐藏的数据集结构
因此如图所示,强化学习是除了监督学习和无监督学习之外的第三种机器学习范式。
1.2 强化学习特点
- 试错学习:强化学习需要训练对象不停地和环境进行交互,通过试错的方式总结出每一步的最佳行为决策,没有任何指导,所有的学习基于环境反馈,训练对象去调整行为决策。
- 延迟反馈:强化学习训练过程中,训练对象的“试错”行为→环境的反馈,一般一次完整的训练结束才能得到反馈,现在改进在训练过程一般都是进行拆解的,尽量将反馈分解到每一步。
- 时间是重要因素:强化学习的一系列环境状态的变化和环境反馈等都是和时间强挂钩,整个强化学习的训练过程是一个随着时间变化,而状态&反馈也在不停变化的,所以时间是强化学习的一个重要因素。
- 当前的行为影响后续接收到的数据:在监督学习&半监督学习中,每条训练数据都是独立的,相互之间没有任何关联。但在强化学习中,当前状态以及采取的行动,将会影响下一步接收到的状态。数据与数据之间存在一定的关联性
1.3 组成部分
Pacman吃豆人

Agent(智能体、机器人、代理):强化学习训练的主体。Pacman中就是这个黄色小人
Environment(环境):整个游戏的所有元素构成环境;Pacman中Agent、Ghost、豆子以及里面各个隔离板块组成了整个环境。
State(状态):当前 Environment和Agent所处的状态,因为Ghost位置移动,豆子数目变化,Agent的位置变化,所以整个State处于变化中;这里特别强调一点,State包含了Agent和Environment的状态。
Action(行动):基于当前的State,Agent可以采取哪些action,如本例中的移动方向;Action是和State强挂钩的,比如上图中很多位置都是有隔板的,很明显Agent在此State下是不能往上或者往下的,只能左右;
Reward(奖励):Agent在当前State下,采取了某个特定的action后,会获得环境的一定反馈就是Reward。这里面用Reward进行统称,虽然Reward翻译成中文是“奖励”的意思,但其实强化学习中Reward只是代表环境给予的“反馈”,可能是奖励也可能是惩罚。比如Pacman游戏中,Agent碰见了Ghost那环境给予的就是惩罚,吃到了豆环境给予的就是奖励
2. 学习过程
2.1 马尔科夫决策过程
整个训练过程都基于一个前提,我们认为整个过程都是符合马尔可夫决策过程(Markov Decision Process)的。
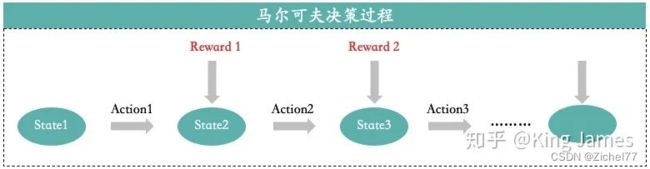
MDP核心思想:下一步的State只和当前的State以及当前State将要采取的Action有关,只回溯一步。比如上图State3只和State2以及Action2有关。我们已知当前的State和将要采取的Action,就可以推出下一步的State是什么,而不需要继续回溯上上步的State以及Action是什么,再结合当前的(State,Action)才能得出下一步State。比如AlphaGo下围棋,当前棋面是什么,当前棋子准备落在哪里,我们就可以清晰地知道下一步的棋面是什么了。
为什么我们要先定义好整个训练过程符合MDP了,因为只有符合MDP,我们才方便根据当前的State,以及要采取的Action,推理出下一步的State。方便在训练过程中清晰地推理出每一步的State变更,如果在训练过程中我们连每一步的State变化都推理不出,那么也无从训练。
2.2 强化学习算法归类
2.2.1 分类方法一
( 1 ) Value Based
说明: 基于每个状态下可以采取的所有动作,这些动作对应的价值 ,来选择当前状态如何行动。强调一点这里面的价值并不是环境给的Reward,Reward是价值组成的一部分。
如何选择Action:简单来说,选择当前State下对应Value最大的Action。

强调一点这里面的Value值,在强化学习训练开始时都是不知道的,我们一般都是设置为0。然后让Agent不断去尝试各类Action,不断与环境交互,不断获得Reward,然后根据我们计算Value的公式,不停地去更新Value,最终在训练N多轮以后,Value值会趋于一个稳定的数字,才能得出具体的State下,采取特定Action,对应的Value是多少
代表算法:Q-Learning
适用场景:Action空间离散的情况,比如吃豆人上下左右;有时每个State对应的最佳Action也是随机的,如剪刀石头布三个1/3
( 2 ) Policy Based
对Value-Based的补充
说明: 基于每个State可以采取的Action策略,针对Action策略进行建模,学习出具体State下可以采取的Action对应的概率,然后根据概率来选择Action。
如何选择Action:基于得出的Policy函数,输入State得到Action
代表算法:Policy Gradient
适用场景:Action空间是连续的&每个State对应的最佳Action并不一定是固定的,基本上Policy Based适用场景是对Value Based适用场景的补充。
(3 ) Actor Critic
AC分类就是将Value-Based和Policy-Based结合在一起
2.2.2 分类方法二
我们是否在agent在状态s下执行它的动作a之前,就已经可以准确对下一步的状态和回报做出预测,如果可以,那么就是Model-based,如果不能,即为Model-free。
(1)Model Based:对环境进行建模
agent已经学习出整个环境是如何运行的,当agent已知任何状态下执行任何动作获得的回报和到达的下一个状态都可以通过模型得出时,此时总的问题就变成了一个动态规划的问题,直接利用贪心算法即可了。
(2)Model Free:不需要对环境进行建模也能找到最优的策略
虽然我们无法知道确切的环境回报,但我们可以对它进行估计。Q-learning中的Q(s,a)就是对在状态s下,执行动作a后获得的未来收益总和进行的估计,经过很多轮训练后,Q(s,a)的估计值会越来越准,这时候同样利用贪心算法来决定agent在某个具体状态下采取什么行动
2.3 EE(Explore&Exploit)探索利用
在Value-Based中,如下图StateA的状态下,最开始Action1&2&3对应的Value都是0,因为训练前我们根本不知道,初始值均为0。如果第一次随机选择了Action1,这时候StateA转化为了StateB,得到了Value=2,系统记录在StateA下选择Action1对应的Value=2。如果下一次Agent又一次回到了StateA,此时如果我们选择可以返回最大Value的action,那么一定还是选择Action1。因为此时StateA下Action2&3对应的Value仍然为0。Agent根本没有尝试过Action2&3会带来怎样的Value。

所以在强化学习训练的时候,一开始会让Agent更偏向于探索Explore,而不是根据哪一个Action带来的Value最大就执行该Action,选择Action时具有一定的随机性,目的是为了覆盖更多的Action,尝试每一种可能性。等训练很多轮以后各种State下的各种Action基本尝试完以后,我们这时候会大幅降低探索的比例,尽量让Agent更偏向于利用Exploit,哪一个Action返回的Value最大,就选择哪一个Action。
2.5 强化学习实际开展中的难点
Reward的设置: 如何去设置Reward函数,如何将环境的反馈量化是一个非常棘手的问题。比如在AlphaGo里面,如何去衡量每一步棋下的“好”与“坏”,并且最终量化,这是一个非常棘手的问题。
采样训练耗时过长,实际工业届应用难: 强化学习需要对每一个State下的每一个Action都要尽量探索到,然后进行学习。实际应用时,部分场景这是一个十分庞大的数字,对于训练时长,算力开销是十分庞大的。很多时候使用其他的算法也会获得同样的效果,而训练时长,算力开销节约很多。强化学习的上限很高,但如果训练不到位,很多时候下限特别低。
容易陷入局部最优: 部分场景中Agent采取的行动可能是当前局部最优,而不是全局最优。网上经常有人截图爆出打游戏碰到了王者荣耀AI,明明此时推塔或者推水晶是最合理的行为,但是AI却去打小兵,因为AI采取的是一个局部最优的行为。再合理的Reward函数设置都可能陷入局部最优中。
3 强化学习的应用
自动驾驶/游戏/推荐系统
4 Q-Learning
Value-Based
Q-Value(State, Action): Q-value是由State和Action组合在一起决定的。实际的项目中我们会存储一张表,我们叫它Q表。key是(state, action), value就是对应的Q-value。每当agent进入到某个state下时,我们就会来这张表进行查询,选择当前State下对应Value最大的Action,执行这个action进入到下一个state,然后继续查表选择action,这样循环。Q-Value的价值就在于指导Agent在不同state下选择哪个action。
如何知道整个训练过程中,Agent会遇到哪些State,每个State下面可以采取哪些Action。最最重要的是,如何将每个(State, Action)对应的Q-value从训练中学习出来?
4.1 Bellman方程
核心思想是:当我们在特定时间点和状态下去考虑下一步的决策,要关注的不仅仅是当前决策立即产生的Reward,同时也要考虑当前的决策衍生产生未来持续性的Reward。
4.2 如何更新Q-Value

如上图的表达式,我们更新Q(s,a)时不仅关注当前收益也关注未来收益,当前收益就是状态变更环境立即反馈的reward,未来收益就是状态变更后新状态对应可以采取的action中最大的Value,同时乘以折扣率γ。学习率和折扣率的设置是希望学习更新过程缓慢一些,不希望某一步的学习跨度过大,从而对整个的学习结果造成比较大的偏差。因为Q(s,a)会更新迭代很多次,不能因为某一次的学习对最终的Q-value产生非常大的影响。
4.3 实例Flappy Bird
https://enhuiz.github.io/flappybird-ql/
1)状态选择
以游戏每一帧的画面为状态。但为了简化问题,取小鸟到下一组管子的水平距离和垂直距离差作为小鸟的状态。更准确地说, Δx与Δy的定义如图所示:

对每个状态(Δx,Δy)Δx为水平距离,Δy为垂直距离
2)动作选择
每一帧,小鸟只有两种动作可选:1.向上飞一下。2.什么都不做。
3)奖赏的选择
小鸟活着时,每一帧给予1的奖赏;若死亡,则给予-1000的奖赏。
4)Q函数
动作效用函数(action-utility function),用于评价特定状态下采取某个动作的优劣,是Agent的记忆
在这个问题中, 状态和动作的组合是有限的。所以我们可以把Q当做是一张表格。表中的每一行记录了状态(Δx,Δy),选择不同动作(飞或不飞)时的奖赏:

这张表一共mn行,表示mn个状态,每个状态所对应的动作都有一个效用值。
理想状态下,在完成训练后,我们会获得一张完美的Q表格。我们希望只要小鸟根据当前位置查找到对应的行,选择效用值较大的动作作为当前帧的动作,就可以无限地存活。
5)伪代码
初始化 Q = {};
while Q 未收敛:
初始化小鸟的位置S,开始新一轮游戏
while S != 死亡状态:
使用策略π,获得动作a=π(S)
使用动作a进行游戏,获得小鸟的新位置S',与奖励R(S,a)
Q[S,A] ← (1-α)*Q[S,A] + α*(R(S,a) + γ* max Q[S',a]) // 更新Q
//Q[S,A] ← Q[S,A] + α*(R(S,a) + γ* max Q[S',a]-Q[S,A])
S ← S'
1.使用策略π,获得动作a=π(S)
即使用Q表来选择效用最大的动作,当两个动作效用值相同的时候就选择第一个动作
但这样会陷入局部最优,改进策略就是上面讲到的E&E,先探索
改进的策略为ε-greedy方法:每个状态以ε的概率进行探索,此时将随机选取飞或不飞,而剩下的1-ε的概率则进行开发,即按上述方法,选取当前状态下效用值较大的动作。
2.更新Q

α为学习率,γ为折扣因子。α越大,保留之前训练的结果越少;γ越大,maxQ(S’,a)起到的作用越大
考虑小鸟在对状态进行更新时,会关心到眼前利益(R),和记忆中的利益(maxQ(S,a))。(maxQ(S,a))是记忆中的利益。它是小鸟记忆里,新位置S’能给出的最大效用值。如果小鸟在过去的游戏中于位置的某个动作S’上吃过甜头(例如选择了某个动作之后获得了50的奖赏),这个公式就可以让它提早地得知这个消息,以便使下回再通过位置时选择正确的动作继续进入这个吃甜头的位置。
可以看出,γ越大,小鸟就会越重视以往经验,越小,小鸟只重视眼前利益(R)。
Reference
策略产品经理必读系列—第二讲强化学习 - 知乎 (zhihu.com)
策略产品经理必读系列—第三讲强化学习实战 - 知乎 (zhihu.com)
https://www.zhihu.com/question/26408259