Yu, Y.; Buchanan, S.; Pai, D.; Chu, T.; Wu, Z.; Tong, S.; Haeffele, B.D.; Ma, Y. White-Box Tra 阅读
文献阅读报告
论文题目: Yu, Y.; Buchanan, S.; Pai, D.; Chu, T.; Wu, Z.; Tong, S.; Haeffele, B.D.; Ma, Y. White-Box Transformers via Sparse Rate Reduction. arXiv preprint arXiv:2306.01129 2023.
- 文献概述
1、解决的问题
- 提出了一种具有数学上可解释性的White-Box Transformers架构,在数据的压缩和稀疏表示学习的研究中取得了进展;与传统Transformer模型类似,该框架可以通过堆叠多层以实现更好的性能,层数及其他参数设置随应用场景而定;提出的架构可以用于图像,自然语言处理,音频处理等多个领域,本文的实验部分在视觉数据的常用数据集上进行了模型性能评估,得到了近似ViT(Vision Transformer)的性能表现。
- 有助于弥合深度神经网络理论与实践之间的差距,并有助于统一看似独立的学习和表示数据分布的方法,为随后设计和证明新的、可能更强大的、深度的表示学习架构提供了理论指导。
2、怎么解决的

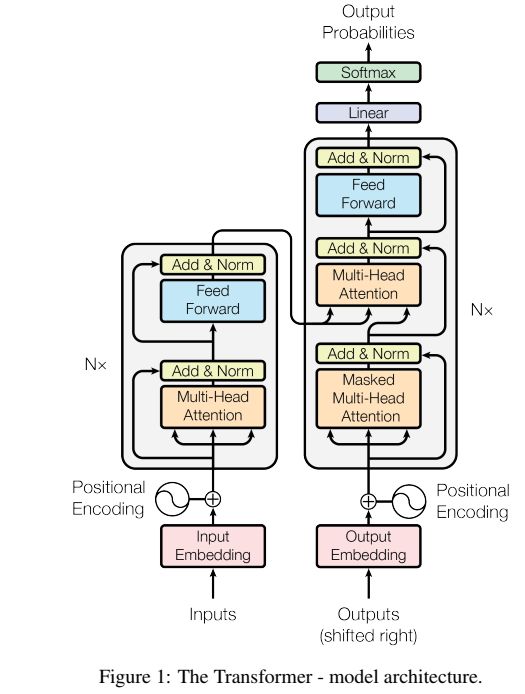
- 上面的第一张图即为提出的White-Box Transformer架构,右边为传统的Transformer架构。
- 从结构上来看,提出的新架构与Transformer相似,但区别在于新架构在设计时便充分考虑了模型的可解释性,所提出架构的各个模块在数学上都是解释的,在对各模块的介绍中在数学上也给出了可解释性。
3、解决的程度
- 作者详尽的解释了模型各个模块背后的数学原理,并在文章的附录部分进行了充分的补充说明,是一个完全可以在数学上解释的架构,这也是文章的主要关注点。
- 作者对所提出的新架构进行了充分的消融实验及不同规模大小的模型的表现,如下图:

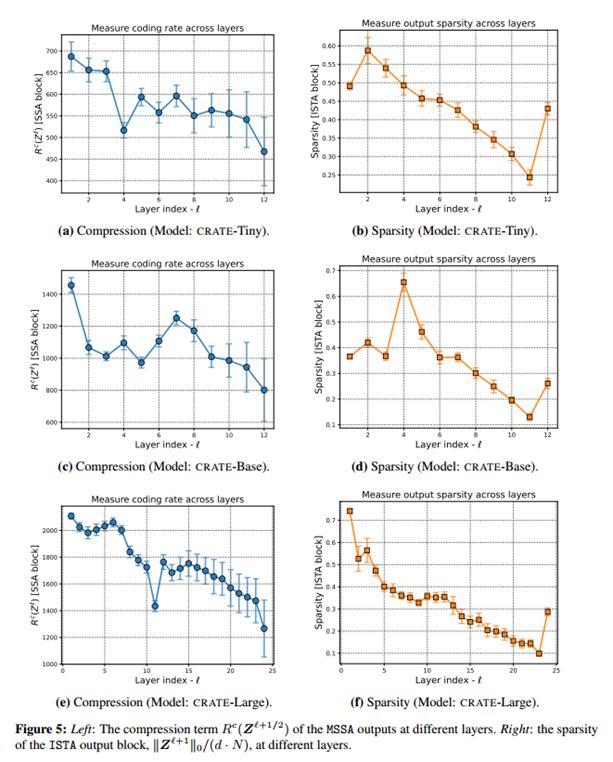
图五最后一层稀疏度度量的增加是由于额外的线性层用于分类性能。
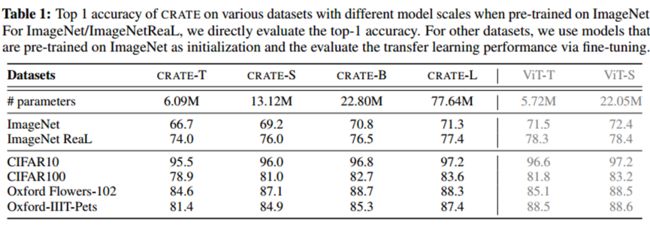
- 在论文的实验部分,作者通过实验表明该模型在逐层级别上与其设计目标一致,在视觉领域常用上的数据集上表明该模型取得了与进行精心设计的ViT相似的性能,如下图:
- 文献详细介绍
1、文章关注的问题的国内外研究现状
| 研究者/机构 |
观点 |
研究成果 |
| Ashish Vaswani Attention Is All You Need |
提出了Transformer,但并没有充分说明模型各个模块的可解释性。在文章的最后作者计划将 Transformer 扩展到涉及文本以外的输入和输出模式的问题上,并且研究局部受限注意力机制,以高效处理大型输入和输出如图像、音频和视频。另一个研究目标是降低生成的顺序性。 |
1引入了自注意力机制,提出了Transformer模型。 2实现了端到端的训练和推断:通过使用Transformer模型,论文实现了端到端的训练和推断,避免了传统的编码器-解码器框架中的复杂性和信息丢失问题。 3在多个自然语言处理任务中取得了优秀的性能。 |
| Alexey Dosovitskiy An image is worth 16x16 words: Transformers for image recognition at scale |
论文提出了一种使用 Transformer模型进行大规模图像识别的方法,也并未对Transformer的可解释性进行说明。实验表明将Transformer模型应用于图像识别任务是可行的,并且在大规模图像数据集上取得了优秀的性能。这为进一步研究和应用Transformer在计算机视觉领域提供了重要的启示。 |
1提出了Vision Transformer(ViT)模型。 2在大规模图像数据集上取得了优秀的性能。 3探索了不同的训练策略和模型结构。 |
| Rene Vidal Self-Expression Is All You Need |
本文认为使用稀疏正则化自动选择最相关的系数,是处理大量数据token的一种更具原则性的方法;而不是像criss-cross attention(2019)那样将注意力限制在任意的局部近邻。 |
本文证明了,注意力建立在流形学习和图像处理的长期历史上,包括基于核的回归、非局部均值、局部线性嵌入、子空间聚类和稀疏编码等方法。特别是,本文表明,注意力背后的许多关键思想,例如它捕捉全局远程交互的能力(这些互动是可学习的和适应输入的),已经出现在其它文献中。 |
| Hongkang Li A Theoretical Understanding of shallow Vision Transformers: Learning, Generalization, and Sample Complexity |
它探讨了浅层视觉 Transformer 模型的学习、泛化和样本复杂度的理论理解。 |
1理论分析浅层视觉Transformer模型的学习能力. 2研究浅层视觉Transformer模型的泛化能力. 3分析浅层视觉Transformer模型的样本复杂度. |
| Bradley Efron Tweedie’s Formula and Selection Bias |
该论文主要探讨了在统计学中的最优去噪问题,即如何通过去除噪声来获得最准确的估计结果。 |
作者引入了 Tweedie 公式,这是一种用于估计参数的数学公式,可以在去噪过程中考虑到选择偏差的影响。该论文通过使用 Tweedie 公式来解决选择偏差问题,并提出了一种基于 Tweedie 公式的最优去噪估计方法。通过考虑选择偏差,该方法可以更准确地估计参数,并提高去噪结果的质量。 |
| Yang Song Consistency models |
Consistency Models 作为一种生成模型,核心设计思想是支持 single-step 生成,同时仍然允许迭代生成,支持零样本(zero-shot)数据编辑,权衡了样本质量与计算量。没有在初始特征和数据样本之间建立任何明确的对应关系 |
1一致性模型的分类和定义:研究者们对一致性模型进行了分类和定义,例如强一致性、弱一致性、最终一致性等。 2一致性模型的性质和特点:研究者们研究了不同一致性模型的性质和特点,例如可线性化、可序列化、可并发等。 3一致性模型的实现和优化:研究者们提出了各种算法和技术来实现和优化一致性模型,例如分布式事务、副本控制、协议设计等。 |
| Bruno A Olshausen and David J Field Sparse coding with an overcomplete basis set: A strategy employed by V1 |
这篇论文主要讨论了V1区域(视觉皮层的一个区域)中的稀疏编码策略。论文指出,V1区域的神经元对于视觉输入的编码采用了一种稀疏编码策略,作者提出了一种基于过完备基函数集的稀疏编码方法。论文还讨论了V1区域中稀疏编码的优势和应用。稀疏编码可以提高对输入信号的表示能力和鲁棒性,并且可以适应不同的视觉任务和环境条件。 |
1提出了稀疏编码的概念:论文提出了稀疏编码的概念,即通过使用过完备基函数集合来表示输入信号,并通过最小化表示中的非零系数的数量来实现信号的稀疏表示。 2探索了V1区域的稀疏编码策略:论文研究了V1区域中神经元的响应特性,并发现V1神经元的响应可以通过稀疏编码的方式来解释。具体而言,V1神经元的响应可以通过选择适当的过完备基函数集合来实现信号的稀疏表示。 3分析了稀疏编码的优势:论文分析了稀疏编码的优势,包括对信号的冗余表示、鲁棒性和泛化能力等方面的优势。这些优势使得稀疏编码成为V1区域中的一种有效的信息处理策略。 |
| René Vidal Generalized Principal Component Analysis |
在这篇论文中,作者介绍了广义主成分分析(GPCA)作为对传统PCA的扩展。GPCA方法通过引入非线性变换和噪声模型,可以更好地处理非线性数据和噪声数据,并提取出更具有判别性的特征。论文详细介绍了GPCA的数学原理和算法,并提供了实验结果和应用案例。它展示了GPCA在图像处理、模式识别、信号处理等领域的应用,并与传统PCA方法进行了比较和分析。 |
1算法开发:研究者们提出了不同的GPCA算法,用于处理不同类型的数据。这些算法包括基于最大似然估计的GPCA、基于核方法的GPCA、基于稀疏表示的GPCA等。这些算法通过引入新的数学模型和优化方法,提高了GPCA的性能和效率。 2理论分析:研究者们对GPCA的理论进行了深入分析,探讨了其在数据降维和特征提取中的优势和限制。他们研究了GPCA的收敛性、稳定性和鲁棒性等方面的性质,为进一步改进和应用GPCA提供了理论指导。 3应用领域:GPCA在多个领域得到了广泛应用,包括计算机视觉、模式识别、信号处理等。研究者们将GPCA应用于图像处理、人脸识别、运动分析等问题,取得了一系列有价值的研究成果。 |
| Daniel A Spielman Exact Recovery of Sparsely-Used Dictionaries |
这篇论文主要讨论了在稀疏表示学习中,如何实现对稀疏字典的精确恢复。在这篇论文中,作者研究了在给定稀疏字典和一组稀疏表示的情况下,如何准确地恢复原始信号。具体而言,他们研究了在什么条件下,可以通过最小化稀疏表示的L0范数来实现对原始信号的精确恢复。论文提出了一种条件,称为稀疏恢复条件,该条件描述了在给定稀疏字典和稀疏表示的情况下,能够精确恢复原始信号的充分条件。作者还提出了一种算法,称为OMP(Orthogonal Matching Pursuit),用于实现稀疏恢复。 |
1. 提出了稀疏表示的问题:论文首先提出了稀疏表示的问题,即如何使用尽可能少的非零系数来表示信号。稀疏表示在信号处理、图像处理和机器学习等领域具有广泛的应用。 2. 探索了稀疏字典的恢复问题:论文研究了在已知稀疏字典的情况下,如何准确恢复使用该字典的信号。具体而言,论文提出了一些算法和理论分析,用于确保恢复过程的准确性和稳定性。 3. 分析了恢复条件和限制:论文分析了恢复稀疏字典的条件和限制。它研究了字典的稀疏性、信号的稀疏度和噪声水平等因素对恢复过程的影响,并提出了一些理论结果和算法改进来解决这些问题。 |
| Rémi Gribonval Sparse and spurious: dictionary learning with noise and outliers |
这篇论文主要讨论了在字典学习中处理噪声和异常值的问题。在这篇论文中,作者研究了在存在噪声和异常值的情况下,如何进行字典学习。他们提出了一种鲁棒的字典学习方法,旨在通过考虑噪声和异常值的影响,提高字典学习的鲁棒性和准确性。论文中介绍了一种基于稀疏表示和鲁棒统计估计的字典学习算法。该算法通过最小化稀疏表示的重构误差,并结合鲁棒统计估计方法,可以有效地处理噪声和异常值,从而提高字典学习的性能。 |
1. 提出了噪声和异常值对字典学习的影响:论文研究了在字典学习过程中,噪声和异常值对稀疏表示的影响。它探讨了噪声和异常值如何干扰字典学习的过程,导致生成的字典和稀疏表示出现偏差和错误。 2. 开发了鲁棒字典学习算法:为了应对噪声和异常值的影响,论文提出了一些鲁棒字典学习算法。这些算法通过引入稀疏正则化、鲁棒损失函数或异常值检测等技术,提高了字典学习的鲁棒性和稳定性。 3. 分析了算法的性能和限制:论文对鲁棒字典学习算法的性能和限制进行了分析。它研究了算法在不同噪声和异常值条件下的恢复能力和稳定性,并提出了一些改进策略和理论结果来解决这些问题。 |
| Yuexiang Zhai Complete dictionary learning via l 4-norm maximization over the orthogonal group |
这篇论文主要讨论了通过在正交群上最大化l4范数来实现完整字典学习的方法。字典学习是一种表示学习方法,旨在通过学习一组基向量(字典),以稀疏线性组合的方式来表示输入信号。传统的字典学习方法通常使用l1或l2范数来约束字典的稀疏性,但这些范数可能无法捕捉到字典中的高阶统计特性。 在这篇论文中,作者提出了一种新的字典学习方法,通过在正交群上最大化l4范数来实现完整字典学习。正交群是一组正交矩阵的集合,它可以表示字典的旋转和变换。通过最大化l4范数,可以促使字典的基向量具有更高的阶数,从而更好地捕捉输入信号的高阶统计特性。 |
1. 提出了基于正交群的字典学习方法:论文提出了一种基于正交群的字典学习方法,通过在正交群上最大化L4范数来学习完备的字典。这种方法可以有效地提取信号的稀疏表示,并具有较好的鲁棒性和泛化能力。 2. 分析了字典学习的优化问题:论文对字典学习的优化问题进行了深入分析,研究了在正交群上最大化L4范数的优化算法和理论性质。它探讨了算法的收敛性、稳定性和复杂性等方面的问题,并提出了一些改进策略和理论结果。 3. 验证了方法的有效性:论文通过在信号处理和图像处理等领域的实验验证了该方法的有效性。实验结果表明,基于正交群的字典学习方法在信号重构、图像压缩和模式识别等任务中取得了较好的性能。 |
| Yaodong Yu Learning Diverse and Discriminative Representations via the Principle of Maximal Coding Rate Reduction 46 |
这篇论文讨论了通过最大编码速率减少原则来学习表示的方法。论文提出了一种学习多样且有区分度的表示的框架。它引入了最大编码速率减少原则,旨在找到在最小化编码速率的同时最大化信息内容的表示。论文提出了一种结合自监督学习和信息论的方法来实现多样且有区分度的表示。它利用交互信息的概念来衡量表示不同部分之间共享的信息量。通过最大化交互信息同时最小化编码速率,该方法旨在学习既具有信息量又高效的表示。 |
1. 提出了最大编码率减少原则:论文提出了最大编码率减少原则,该原则旨在学习多样化和有区分性的表示。通过最大化表示的编码率减少,可以使得不同类别的样本在表示空间中更加分散和可区分。 2. 开发了相应的学习算法:论文开发了相应的学习算法来实现最大编码率减少原则。这些算法通过优化目标函数,使得表示的编码率减少最大化,并且能够学习到多样化和有区分性的表示。 3. 验证了方法的有效性:论文通过在图像分类、目标检测等任务上的实验验证了该方法的有效性。实验结果表明,基于最大编码率减少原则的学习方法能够获得更好的分类性能和目标检测准确率。 |
| Yi Ma Segmentation of multivariate mixed data via lossy data coding and compression 6 |
这篇论文讨论了一种通过损失数据编码和压缩的方法来进行多变量混合数据的分割。论文的目标是解决多变量混合数据分割的问题,其中数据包含多个不同类型的变量,如数值型、分类型和文本型数据。传统的分割方法往往难以处理这种混合数据,因为不同类型的变量具有不同的特征和分布。该论文提出了一种基于损失数据编码和压缩的分割方法。该方法首先将多变量混合数据进行编码和压缩,以减少数据的维度和冗余信息。然后,利用编码后的数据进行分割,通过对编码数据进行聚类或分类来识别不同的数据子集。通过损失数据编码和压缩,该方法可以在保留关键信息的同时减少数据的维度,从而提高分割的效果。此外,该方法还可以处理不同类型的变量,并充分利用它们之间的关联性。 |
1. 提出了基于有损数据编码和压缩的分割方法:论文提出了一种基于有损数据编码和压缩的分割方法,用于处理多变量混合数据。该方法通过对数据进行编码和压缩,从中提取出关键特征,然后利用这些特征进行数据分割。 2. 开发了相应的算法和模型:论文开发了相应的算法和模型来实现基于有损数据编码和压缩的分割方法。这些算法和模型可以根据数据的特点和需求进行定制,以实现更准确和高效的分割结果。 3. 验证了方法的有效性:论文通过在实际数据集上的实验验证了该方法的有效性。实验结果表明,基于有损数据编码和压缩的分割方法能够在多变量混合数据的分割任务中取得较好的性能,具有较高的准确度和鲁棒性。 |
| Kwan Ho Ryan Chan ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction |
这篇论文讨论了ReduNet框架,它是一种基于最大化速率减少原则的白盒深度网络架构。论文介绍了速率减少的概念,它指的是减少表示数据所需的信息量的过程。最大化速率减少原则旨在找到一种最优表示,既能最小化所需的信息量,又能保留关键信息。ReduNet框架旨在通过将速率减少作为指导原则来实现这一目标。它由多个层组成,每个层执行特定的操作来压缩和稀疏化数据表示。该框架利用梯度下降和迭代优化等技术,通过迭代改进表示并最大化速率减少。 |
1. 提出了最大化率减少原则:论文提出了最大化率减少原则,该原则旨在构建白盒深度网络。通过最大化输入和隐藏层之间的信息率减少,可以使得网络的表示更加紧凑和有区分性。 2. 构建了ReduNet网络结构:论文基于最大化率减少原则构建了ReduNet网络结构。该网络结构具有一定的灵活性,可以根据任务的需求进行定制,同时保持了较好的可解释性和可解读性。 3. 验证了方法的有效性:论文通过在多个数据集上的实验验证了ReduNet的有效性。实验结果表明,ReduNet在图像分类、目标检测等任务中取得了与其他深度网络相媲美甚至更好的性能。 |
| John Wright and Yi Ma High-Dimensional Data Analysis with Low-Dimensional Models: Principles, Computation, and Applications |
书中介绍了高维数据分析面临的挑战,包括维度灾难、过拟合、计算复杂度等问题。高维数据的特点使得传统的分析方法不再适用,因此需要引入低维模型来进行数据分析。 |
详细介绍了各种低维模型的原理,包括主成分分析(PCA)、流形学习、稀疏表示等。这些低维模型可以将高维数据映射到低维空间,并保留数据的重要特征。 讨论了低维模型的计算方法,包括降维算法、优化算法等。这些方法可以有效地计算低维模型,并处理大规模高维数据。 书中还介绍了低维模型在各个领域的应用,包括图像处理、文本分析、生物信息学等。通过使用低维模型,可以提取数据的关键特征,并实现数据的可视化、分类、聚类等任务。 |
2、本文章提出方法的主要思想
- 方法概述:
 上图介绍了CRATE白盒深度网络设计的“主循环”,新架构中的 Zℓ(Z0=X )可为任意类型的数据,对于语言转换器,token大致对应单词,而对于视觉转换器,token大致对应图像块。本文以图像为例,CRATE构建了一个深度网络,该网络通过对分布的局部模型进行连续压缩(生成Z ℓ+1/2)和对全局字典进行稀疏化(生成Z ℓ +1),将数据转换为低维子空间的规范配置。反复堆叠这些块,并通过反向传播训练模型参数,产生强大且可解释的数据表示。
上图介绍了CRATE白盒深度网络设计的“主循环”,新架构中的 Zℓ(Z0=X )可为任意类型的数据,对于语言转换器,token大致对应单词,而对于视觉转换器,token大致对应图像块。本文以图像为例,CRATE构建了一个深度网络,该网络通过对分布的局部模型进行连续压缩(生成Z ℓ+1/2)和对全局字典进行稀疏化(生成Z ℓ +1),将数据转换为低维子空间的规范配置。反复堆叠这些块,并通过反向传播训练模型参数,产生强大且可解释的数据表示。
新架构中各块所对应的数学方程已在下图中进行补充。 其中U[K]为所有高斯基的集合。D∈R d×d是一个(完全)非相干或正交字典,字典D是全局的,即用于同时稀疏所有令牌。
提出的模型架构与对应的数学方法

在新架构中与Transform对应的Q,K,V 由Uk*表示。
新架构的目标函数如下图所示:
![]()
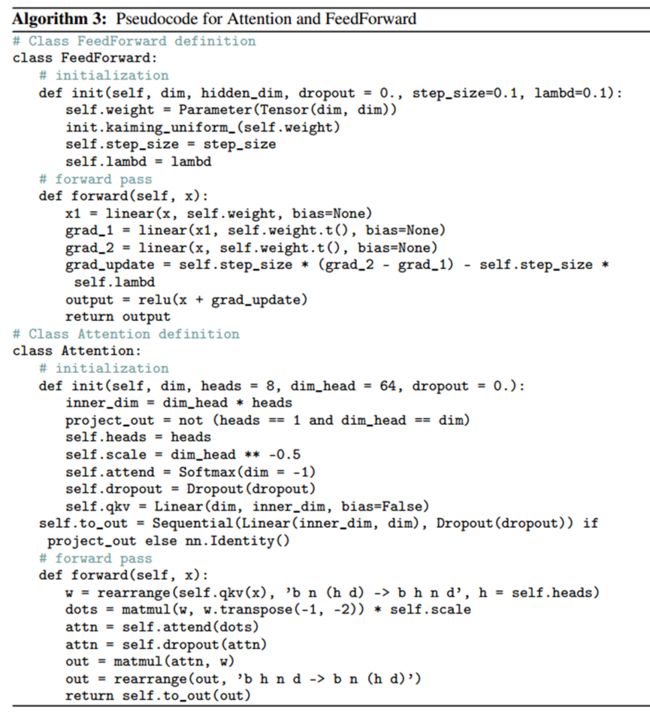
- 算法


- 实验
- 数据集
1.ImageNer 2.ImageNet Real 3.CIPARIO 4.CIFARI0O 5.Oxford Flowers-102 6.Oxford-IIT Pets
本文用到了六个数据集,进行图像分类任务。
-
- 实验设置
-
- 实验结果与分析

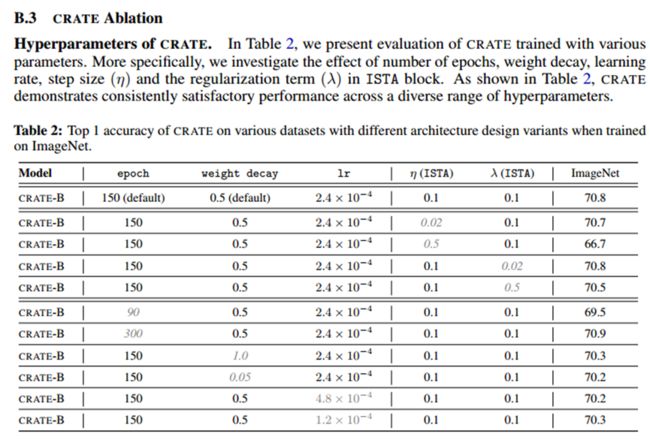
- 结论
本文提出了一个新的理论框架,该框架允许我们推导出深度变压器式网络架构作为增量优化方案,以学习输入数据(或令牌集)的压缩和稀疏表示。如此推导和学习的深度架构不仅在数学上完全可解释,而且在逐层的级别上与其设计目标一致。尽管可以说是所有可能的设计中最简单的,但这些网络已经在大规模的现实世界数据集和接近经验丰富的变压器的任务上展示了性能。我们相信这项工作确实有助于弥合深度神经网络理论与实践之间的差距,并有助于统一看似独立的学习和表示数据分布的方法。也许对从业者来说更重要的是,我们的框架为设计和证明新的、可能更强大的、深度的表示学习架构提供了理论指导。